
 base de données
tutoriel mysql
Partagez un exemple de surveillance des données à l'aide du mécanisme oplog dans MongoDB
base de données
tutoriel mysql
Partagez un exemple de surveillance des données à l'aide du mécanisme oplog dans MongoDB
Partagez un exemple de surveillance des données à l'aide du mécanisme oplog dans MongoDB

La réplication de MongoDB stocke les opérations d'écriture via un journal. Ce journal est appelé oplog L'article suivant vous présente principalement les informations pertinentes sur l'utilisation du mécanisme oplog dans MongoDB pour réaliser une surveillance des opérations de données en temps quasi réel. peut s'y référer, jetons un coup d'œil ci-dessous.
Avant-propos
Récemment, il est devenu nécessaire d'obtenir les données nouvellement insérées dans MongoDB en temps réel, et le programme d'insertion lui-même dispose déjà d'un ensemble de logique de traitement, il n'est donc pas pratique d'écrire des programmes associés directement dans le programme d'insertion. La plupart des bases de données traditionnelles sont livrées avec ce mécanisme de déclencheur, mais Mongo n'a pas de fonctions associées à utiliser (peut-être que je ne le sais pas non plus). beaucoup, s'il vous plaît Correction), bien sûr, il y a un autre point qui doit être implémenté en python, j'ai donc collecté et compilé une méthode d'implémentation correspondante.
1. Introduction
Tout d'abord, on peut penser que cette exigence est en réalité très similaire au maître-esclave. mécanisme de sauvegarde de la base de données. Par conséquent, la base de données principale peut être synchronisée car il existe certains indicateurs de contrôle. Nous savons que bien que MongoDB n'ait pas de déclencheurs prêts à l'emploi, il peut réaliser une sauvegarde maître-esclave, nous commençons donc par son maître-esclave. mécanisme de sauvegarde esclave.
2. OPLOG
Tout d'abord, vous devez ouvrir le démon mongod en mode maître, utilisez –master sur la ligne de commande. , ou Fichier de configurationAjouter la clé principale à true.
À ce moment, nous pouvons voir la nouvelle collection-oplog dans la bibliothèque système locale de Mongo. À ce moment, les informations d'oplog seront stockées dans oplog.$main S'il existe encore une base de données esclave à ce moment-là. Mongo existe, il y aura aussi des informations sur les esclaves Comme nous ne sommes pas ici en synchronisation maître-esclave, ces ensembles n'existent pas.
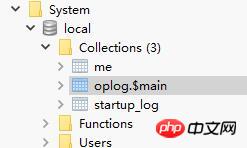
Jetons un coup d'œil à la structure de l'oplog :
"ts" : Timestamp(6417682881216249, 1), 时间戳
"h" : NumberLong(0), 长度
"v" : 2,
"op" : "n", 操作类型
"ns" : "", 操作的库和集合
"o2" : "_id" update条件
"o" : {} 操作值,即documentObligatoire ici Connaître plusieurs attributs de op :
insert,'i' update, 'u' remove(delete), 'd' cmd, 'c' noop, 'n' 空操作
Comme le montrent les informations ci-dessus, nous n'avons besoin que de lire en permanence ts à des fins de comparaison, et puis en fonction de l'opération, vous pouvez déterminer quelle opération est en cours, ce qui équivaut à utiliser un programme pour implémenter une extrémité réceptrice de la base de données.
3. CODE
J'ai trouvé l'implémentation d'autres personnes sur Github, mais sa bibliothèque de fonctions est trop ancienne, alors apportez des modifications en fonction sur son travail.
L'adresse Github : github.com/RedBeard0531/mongo-oplog-watcher
mongo_oplog_watcher.py est la suivante :
#!/usr/bin/python
import pymongo
import re
import time
from pprint import pprint # pretty printer
from pymongo.errors import AutoReconnect
class OplogWatcher(object):
def init(self, db=None, collection=None, poll_time=1.0, connection=None, start_now=True):
if collection is not None:
if db is None:
raise ValueError('must specify db if you specify a collection')
self._ns_filter = db + '.' + collection
elif db is not None:
self._ns_filter = re.compile(r'^%s\.' % db)
else:
self._ns_filter = None
self.poll_time = poll_time
self.connection = connection or pymongo.Connection()
if start_now:
self.start()
@staticmethod
def get_id(op):
id = None
o2 = op.get('o2')
if o2 is not None:
id = o2.get('_id')
if id is None:
id = op['o'].get('_id')
return id
def start(self):
oplog = self.connection.local['oplog.$main']
ts = oplog.find().sort('$natural', -1)[0]['ts']
while True:
if self._ns_filter is None:
filter = {}
else:
filter = {'ns': self._ns_filter}
filter['ts'] = {'$gt': ts}
try:
cursor = oplog.find(filter, tailable=True)
while True:
for op in cursor:
ts = op['ts']
id = self.get_id(op)
self.all_with_noop(ns=op['ns'], ts=ts, op=op['op'], id=id, raw=op)
time.sleep(self.poll_time)
if not cursor.alive:
break
except AutoReconnect:
time.sleep(self.poll_time)
def all_with_noop(self, ns, ts, op, id, raw):
if op == 'n':
self.noop(ts=ts)
else:
self.all(ns=ns, ts=ts, op=op, id=id, raw=raw)
def all(self, ns, ts, op, id, raw):
if op == 'i':
self.insert(ns=ns, ts=ts, id=id, obj=raw['o'], raw=raw)
elif op == 'u':
self.update(ns=ns, ts=ts, id=id, mod=raw['o'], raw=raw)
elif op == 'd':
self.delete(ns=ns, ts=ts, id=id, raw=raw)
elif op == 'c':
self.command(ns=ns, ts=ts, cmd=raw['o'], raw=raw)
elif op == 'db':
self.db_declare(ns=ns, ts=ts, raw=raw)
def noop(self, ts):
pass
def insert(self, ns, ts, id, obj, raw, **kw):
pass
def update(self, ns, ts, id, mod, raw, **kw):
pass
def delete(self, ns, ts, id, raw, **kw):
pass
def command(self, ns, ts, cmd, raw, **kw):
pass
def db_declare(self, ns, ts, **kw):
pass
class OplogPrinter(OplogWatcher):
def all(self, **kw):
pprint (kw)
print #newline
if name == 'main':
OplogPrinter()Tout d'abord, implémenter une initialisation de la base de données, définir un temps de retard (quasi temps réel) :
self.poll_time = poll_time self.connection = connection or pymongo.MongoClient()
La fonction principale est start() , qui implémente une comparaison de temps et effectue les champs correspondants Traitement :
def start(self):
oplog = self.connection.local['oplog.$main']
#读取之前提到的库
ts = oplog.find().sort('$natural', -1)[0]['ts']
#获取一个时间边际
while True:
if self._ns_filter is None:
filter = {}
else:
filter = {'ns': self._ns_filter}
filter['ts'] = {'$gt': ts}
try:
cursor = oplog.find(filter)
#对此时间之后的进行处理
while True:
for op in cursor:
ts = op['ts']
id = self.get_id(op)
self.all_with_noop(ns=op['ns'], ts=ts, op=op['op'], id=id, raw=op)
#可以指定处理插入监控,更新监控或者删除监控等
time.sleep(self.poll_time)
if not cursor.alive:
break
except AutoReconnect:
time.sleep(self.poll_time)bouclez cette fonction de démarrage, et vous pouvez écrire la logique de surveillance et de traitement correspondante ici dans all_with_noop.
De cette manière, un simple moniteur Mongoopération de base de donnéesen quasi-temps réel peut être mis en œuvre à l'étape suivante, le programme nouvellement entré peut être traité en conséquence en conjonction avec d'autres opérations.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Que faire si Navicat expire
Apr 23, 2024 pm 12:12 PM
Que faire si Navicat expire
Apr 23, 2024 pm 12:12 PM
Les solutions pour résoudre les problèmes d'expiration de Navicat incluent : renouveler la licence ; désinstaller et réinstaller ; désactiver les mises à jour automatiques ; utiliser la version gratuite de Navicat Premium ; contacter le support client de Navicat.
 Comment connecter Navicat à MongoDB
Apr 24, 2024 am 11:27 AM
Comment connecter Navicat à MongoDB
Apr 24, 2024 am 11:27 AM
Pour vous connecter à MongoDB à l'aide de Navicat, vous devez : Installer Navicat Créer une connexion MongoDB : a. Entrez le nom de connexion, l'adresse de l'hôte et le port b. Entrez les informations d'authentification (si nécessaire) Ajoutez un certificat SSL (si nécessaire) Vérifiez la connexion. Enregistrez la connexion
 A quoi sert net4.0
May 10, 2024 am 01:09 AM
A quoi sert net4.0
May 10, 2024 am 01:09 AM
.NET 4.0 est utilisé pour créer une variété d'applications et offre aux développeurs d'applications des fonctionnalités riches, notamment : programmation orientée objet, flexibilité, architecture puissante, intégration du cloud computing, optimisation des performances, bibliothèques étendues, sécurité, évolutivité, accès aux données et mobile. soutien au développement.
 Intégration de fonctions et bases de données Java dans une architecture sans serveur
Apr 28, 2024 am 08:57 AM
Intégration de fonctions et bases de données Java dans une architecture sans serveur
Apr 28, 2024 am 08:57 AM
Dans une architecture sans serveur, les fonctions Java peuvent être intégrées à la base de données pour accéder et manipuler les données de la base de données. Les étapes clés comprennent : la création de fonctions Java, la configuration des variables d'environnement, le déploiement de fonctions et le test des fonctions. En suivant ces étapes, les développeurs peuvent créer des applications complexes qui accèdent de manière transparente aux données stockées dans les bases de données.
 Comment configurer l'expansion automatique de MongoDB sur Debian
Apr 02, 2025 am 07:36 AM
Comment configurer l'expansion automatique de MongoDB sur Debian
Apr 02, 2025 am 07:36 AM
Cet article présente comment configurer MongoDB sur Debian System pour réaliser une expansion automatique. Les étapes principales incluent la configuration de l'ensemble de répliques MongoDB et de la surveillance de l'espace disque. 1. Installation de MongoDB Tout d'abord, assurez-vous que MongoDB est installé sur le système Debian. Installez à l'aide de la commande suivante: SudoaptupDaSudoaptInstall-myongoDB-Org 2. Configuration de la réplique MongoDB Ensemble de répliques MongoDB assure la haute disponibilité et la redondance des données, ce qui est la base de la réalisation d'une expansion de capacité automatique. Démarrer le service MongoDB: Sudosystemctlstartmongodsudosys
 Comment assurer la haute disponibilité de MongoDB sur Debian
Apr 02, 2025 am 07:21 AM
Comment assurer la haute disponibilité de MongoDB sur Debian
Apr 02, 2025 am 07:21 AM
Cet article décrit comment construire une base de données MongoDB hautement disponible sur un système Debian. Nous explorerons plusieurs façons de garantir que la sécurité des données et les services continueront de fonctionner. Stratégie clé: réplicaset: réplicaset: Utilisez des répliques pour obtenir la redondance des données et le basculement automatique. Lorsqu'un nœud maître échoue, l'ensemble de répliques élise automatiquement un nouveau nœud maître pour assurer la disponibilité continue du service. Sauvegarde et récupération des données: utilisez régulièrement la commande Mongodump pour sauvegarder la base de données et formuler des stratégies de récupération efficaces pour faire face au risque de perte de données. Surveillance et alarmes: déploier les outils de surveillance (tels que Prometheus, Grafana) pour surveiller l'état de course de MongoDB en temps réel, et
 Navicat peut-il se connecter à mongodb ?
Apr 23, 2024 pm 05:15 PM
Navicat peut-il se connecter à mongodb ?
Apr 23, 2024 pm 05:15 PM
Oui, Navicat peut se connecter à la base de données MongoDB. Les étapes spécifiques incluent : Ouvrez Navicat et créez une nouvelle connexion. Sélectionnez le type de base de données comme MongoDB. Entrez l'adresse de l'hôte MongoDB, le port et le nom de la base de données. Entrez votre nom d'utilisateur et votre mot de passe MongoDB (si nécessaire). Cliquez sur le bouton "Connecter".
 Mise à jour majeure de Pi Coin: PI Bank arrive!
Mar 03, 2025 pm 06:18 PM
Mise à jour majeure de Pi Coin: PI Bank arrive!
Mar 03, 2025 pm 06:18 PM
Pinetwork est sur le point de lancer Pibank, une plate-forme bancaire mobile révolutionnaire! Pinetwork a publié aujourd'hui une mise à jour majeure sur Elmahrosa (face) Pimisrbank, appelée Pibank, qui intègre parfaitement les services bancaires traditionnels avec des fonctions de crypto-monnaie de pignon (prend en charge l'échange entre les Fiat Currency tels que le Dollar, l'Euro, Usdt, Usdc, Ripiah avec des crypto-monnaies. Quel est le charme de Pibank? Découvrons! Les principales fonctions de Pibank: gestion unique des comptes bancaires et des actifs de crypto-monnaie. Soutenez les transactions en temps réel et adoptez les biospécies
