

Tout d’abord, comprenons brièvement les robots d’exploration. Il s'agit d'un processus consistant à demander un site Web et à extraire les données dont vous avez besoin. Quant à savoir comment grimper et comment grimper, ce sera le contenu de l'apprentissage plus tard, il n'est donc pas nécessaire d'y revenir pour l'instant. Grâce à notre programme, nous pouvons envoyer des requêtes au serveur en notre nom, puis télécharger de grandes quantités de données par lots.
Lancer une requête : lancer une requête au serveur via l'URL, les demandes peuvent contenir des informations d'en-tête supplémentaires.
Obtenir le contenu de la réponse : si le serveur répond normalement, nous recevrons une réponse. La réponse est le contenu de la page Web que nous avons demandée, qui peut. inclure une chaîne Json ou des données binaires (vidéo, image), etc.
Analyser le contenu : s'il s'agit de code HTML, il peut être analysé à l'aide d'un analyseur de page Web. S'il s'agit de données Json, elles peuvent être converties en Json. objet pour l'analyse. S'il s'agit de données binaires, elles peuvent être enregistrées dans un fichier pour un traitement ultérieur.
Enregistrer les données : vous pouvez les enregistrer dans un fichier local ou dans une base de données (MySQL, Redis, Mongodb, etc.)
Lorsque nous envoyons un demande au serveur via le navigateur Lors d'une demande, quelles informations cette demande contient-elle ? Nous pouvons l'expliquer via les outils de développement de Chrome (si vous ne savez pas comment l'utiliser, lisez les notes dans cet article).
Méthode de demande : les méthodes de demande les plus couramment utilisées incluent la demande d'obtention et la demande de publication. La demande de publication la plus courante en développement consiste à la soumettre via un formulaire. Du point de vue de l'utilisateur, la plus courante est la vérification de la connexion. Lorsque vous devez saisir certaines informations pour vous connecter, cette demande est une demande de publication.
url Uniform Resource Locator : une URL, une image, une vidéo, etc. peuvent toutes être définies à l'aide d'une URL. Lorsque nous demandons une page Web, nous pouvons afficher la balise réseau. La première est généralement un document, ce qui signifie que ce document est un code HTML qui n'est pas rendu avec des images externes, css, js, etc. Sous ce document, nous le ferons. voir Pour une série de jpg, js, etc., il s'agit d'une requête lancée encore et encore par le navigateur basée sur le code html, et l'adresse demandée est l'adresse url de l'image, js, etc. dans le document html
en-têtes de requête : en-têtes de requête, comprenant le type de requête, les informations sur les cookies et le type de navigateur de cette requête. Cet en-tête de requête est toujours utile lorsque nous explorons des pages Web. Le serveur examinera les informations en analysant l'en-tête de requête pour déterminer si la requête est légitime. Ainsi, lorsque nous faisons une demande via un programme qui masque le navigateur, nous pouvons définir les informations d'en-tête de la demande.
Corps de la requête : la demande de publication encapsulera les informations de l'utilisateur dans les données du formulaire pour la soumission, donc par rapport à la demande d'obtention, le contenu de la balise Headers de la demande de publication est là sera un package d’informations supplémentaires appelé Form Data. La requête get peut être simplement comprise comme un retour chariot de recherche ordinaire, et les informations seront ajoutées à la fin de l'URL à des intervalles ?
Statut de la réponse : le code d'état peut être consulté via Général dans les en-têtes. 200 indique un succès, 301 saut, 404 page Web introuvable, 502 erreur de serveur, etc.
En-tête de réponse : inclut le type de contenu, les informations sur les cookies, etc.
Corps de la réponse : le but de la requête est d'obtenir le corps de la réponse, comprenant le code html, le Json et les données binaires.
Effectuer des requêtes de pages Web via la bibliothèque de requêtes de Python :

Le résultat de sortie est le code de la page Web qui n'a pas encore été rendu, c'est-à-dire le contenu du corps de la requête. Vous pouvez afficher les informations d'en-tête de réponse :
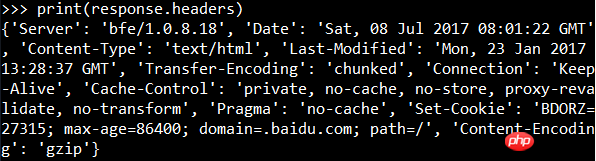
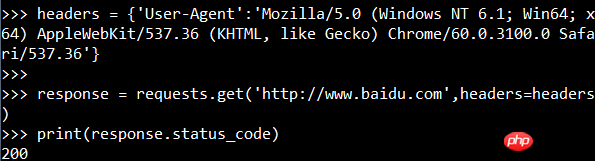
Vous pouvez également ajouter des en-têtes de demande aux informations de demande :

Prendre des photos (logo Baidu) : 🎜>
6. Comment résoudre les problèmes de rendu JavaScript

Entrez print(driver.page_source ) et vous pouvez voir que cette fois le code est le code après rendu.
[Remarques] Utilisation du navigateur Chrome
Code HTML. 
Tag réseau
Tag réseau Là Ce sont des données demandées par le navigateur. Cliquez dessus pour afficher des informations détaillées, telles que les en-têtes de demande, les en-têtes de réponse, etc. mentionnés ci-dessus.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



