

Installation et utilisation de Redis

Avec Membercache et diverses bases de données, pourquoi Redis a-t-il été créé ? Redis est uniquement destiné aux applications. Il s'agit d'une base de données clé-valeur hautes performances.
L'émergence de Redis a largement compensé les lacunes du stockage de valeurs clés tel que Memcached, et a résolu la situation de perte complète de données après une panne de courant, dans certains cas, il peut jouer un très bon rôle supplémentaire à la base de données relationnelle ; Les résultats des tests de performances indiquent que les opérations SET peuvent atteindre 110 000 fois par seconde et que les opérations GET peuvent atteindre 81 000 fois par seconde (bien entendu, différentes configurations de serveur ont des performances différentes).
Redis est un système de base de données NoSQL distribué pour les données de type paire "clé/valeur". Il se caractérise par des performances élevées, un stockage persistant et une adaptabilité élevée. scénarios d’applications simultanées. Semblable à Memcached, il prend en charge le stockage de relativement plus de types de valeurs, notamment string (string), list (liste chaînée), set (set) et zset (ensemble ordonné). Ces types de données prennent en charge le push/pop, l'ajout/suppression, l'union et la différence d'intersection, ainsi que des opérations plus riches, et ces opérations sont atomiques et prennent en charge différentes méthodes de tri. Comme Redis et Memcached, afin de garantir l'efficacité, les données sont mises en cache en mémoire. La différence est que Redis écrira périodiquement les données mises à jour sur le disque ou écrira les opérations de modification dans des fichiers d'enregistrement supplémentaires, et sur cette base, la synchronisation maître-esclave (maître-esclave) est obtenue.
redis fournit actuellement quatre types de données : chaîne, liste, ensemble et zset (ensemble trié). Le stockage Redis est divisé en trois parties : le stockage mémoire, le stockage sur disque et les fichiers journaux. Il y a trois paramètres dans le fichier de configuration pour le configurer.
enregistrer les mises à jour en secondes : indiquez le nombre d'opérations de mise à jour sur une longue période de temps, puis synchronisez les données avec le fichier de données.
appendonly oui/non : s'il faut se connecter après chaque opération de mise à jour. S'il n'est pas allumé, il peut entraîner une perte de données pendant un certain temps lors d'une panne de courant. Étant donné que Redis synchronise lui-même les fichiers de données selon les conditions de sauvegarde ci-dessus, certaines données n'existeront en mémoire que pendant un certain temps.
appendfsync no/always/everysec : Comment le cache de données est synchronisé avec le disque. aucun moyen d'attendre que le système d'exploitation synchronise le cache de données sur le disque, signifie toujours appeler manuellement fsync() pour écrire les données sur le disque après chaque opération de mise à jour, et chaque seconde signifie se synchroniser une fois par seconde.
🎜>
Redis-Server.exe Programme de démarrage du démon du serveur Redis fichier de configuration redis.conf redis
redis Redis -cli.exe outil d'opération de ligne de commande redis. Bien sûr, vous pouvez également utiliser telnet pour fonctionner selon son protocole de texte brut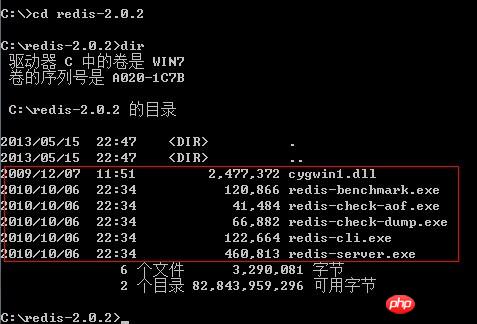 redis-check-dump.exe Vérification de la base de données locale
redis-check-dump.exe Vérification de la base de données locale
redis-benchmark.exe Test de performances, utilisé pour simuler l'envoi de requêtes M SETs/GETs par N clients en même temps (similaire à l'outil ab d'Apache)
informations sur le test de l'outil de référence : Envoyer 100 000 requêtes au serveur Redis, chaque requête est accompagnée 60 clients simultanés
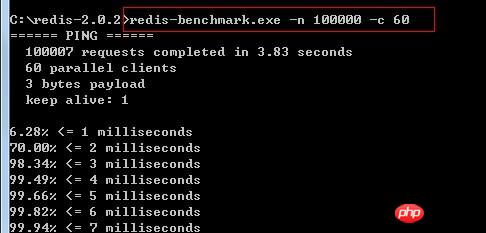
Oups, mon ordinateur était un peu débordé, mais il a finalement montré que le test des 100 000 requêtes s'était réalisé en 4,03 secondes,
Quelques captures d'écran des résultats sont les suivantes :

Démarrez le service Redis (fichier de conf pour créer le fichier de configuration (redis-server.exe redis.conf ), par défaut si non spécifié :
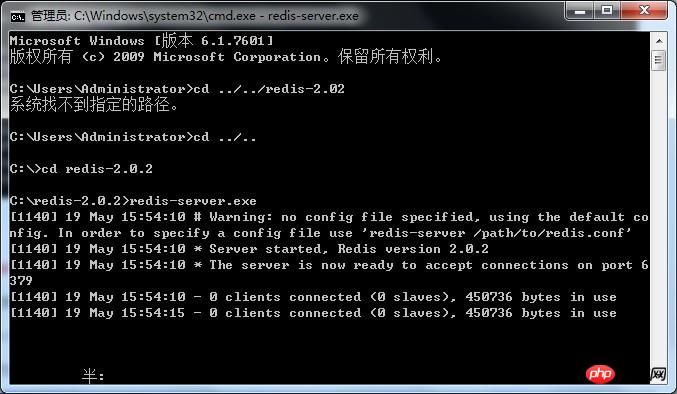
La fenêtre cmd de démarrage doit toujours être ouvert. Après la fermeture, le service Redis est arrêté.
Le service est maintenant ouvert. Ouvrez une autre fenêtre cmd pour configurer le client :
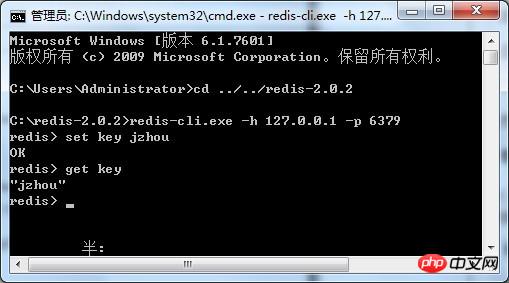
C:redis-2.0.2>redis - cli.exe -h 127.0.0.1 -p 6379
Ensuite, nous pouvons saisir la commande que nous voulons saisir ici. Une opération très importante de redis est set et get
Le client est le suivant :
À ce moment, le côté serveur (voici également la machine locale) est affiché comme suit (il y a un Le client est connecté) :

La clé définie ci-dessus sur le client est résidente en mémoire , ce qui signifie fermer la fenêtre. La prochaine fois que vous ouvrirez la fenêtre et obtiendrez la valeur clé, ce sera toujours "jzhou", haha.
(Notez que pendant le fonctionnement, le serveur doit activer le service, sinon le client ne peut pas se connecter.)
Redis fournit des clients multilingues, y compris Java, C++, python.
>
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Tutoriel de désinstallation de la base de données Oracle
Apr 11, 2025 pm 06:24 PM
Tutoriel de désinstallation de la base de données Oracle
Apr 11, 2025 pm 06:24 PM
Pour désinstaller une base de données Oracle: arrêtez le service Oracle, supprimez l'instance Oracle, supprimez le répertoire d'Oracle Home, effacez la touche de registre (Windows uniquement) et supprimez les variables d'environnement (Windows uniquement). Veuillez sauvegarder les données avant de désinstaller.
 Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Utilisez l'outil de ligne de commande redis (Redis-CLI) pour gérer et utiliser Redis via les étapes suivantes: Connectez-vous au serveur, spécifiez l'adresse et le port. Envoyez des commandes au serveur à l'aide du nom et des paramètres de commande. Utilisez la commande d'aide pour afficher les informations d'aide pour une commande spécifique. Utilisez la commande QUIT pour quitter l'outil de ligne de commande.
 Comment définir la politique d'expiration redis
Apr 10, 2025 pm 10:03 PM
Comment définir la politique d'expiration redis
Apr 10, 2025 pm 10:03 PM
Il existe deux types de stratégies d'expiration de données redis: la suppression périodique: analyse périodique pour supprimer la clé expirée, qui peut être définie via des paramètres d'expiration-temps-transport et des paramètres d'expiration-temps-transparence. Suppression paresseuse: vérifiez les clés expirées de suppression uniquement lorsque les clés sont lues ou écrites. Ils peuvent être définis à travers des paramètres Lazyfree-Lazy-Deviction, Lazyfree-Lazy-Expire, Lazyfree-Lazy-User-Del.
 Optimisation des performances postgresql sous Debian
Apr 12, 2025 pm 08:18 PM
Optimisation des performances postgresql sous Debian
Apr 12, 2025 pm 08:18 PM
Pour améliorer les performances de la base de données PostgreSQL dans Debian Systems, il est nécessaire de considérer de manière approfondie le matériel, la configuration, l'indexation, la requête et d'autres aspects. Les stratégies suivantes peuvent optimiser efficacement les performances de la base de données: 1. Extension de mémoire d'optimisation des ressources matérielles: la mémoire adéquate est cruciale pour cacher les données et les index. Stockage à grande vitesse: l'utilisation de disques SSD SSD peut considérablement améliorer les performances d'E / S. Processeur multi-core: utilisez pleinement les processeurs multi-core pour implémenter le traitement des requêtes parallèles. 2. Paramètre de base de données Tuning Shared_Buffers: Selon le réglage de la taille de la mémoire du système, il est recommandé de le définir à 25% -40% de la mémoire système. work_mem: contrôle la mémoire des opérations de tri et de hachage, généralement définies sur 64 Mo à 256m
 Comment utiliser redis cluster zset
Apr 10, 2025 pm 10:09 PM
Comment utiliser redis cluster zset
Apr 10, 2025 pm 10:09 PM
Utilisation de Zset dans le cluster Redis: ZSET est une collection ordonnée qui associe les éléments aux scores. Stratégie de rupture: a. Cusage de hachage: distribuez la valeur de hachage en fonction de la touche Zset. né Plage de percussion: diviser en plages en fonction des scores des éléments et attribuer chaque plage à différents nœuds. Opérations de lecture et d'écriture: a. Opérations de lecture: Si la clé ZSET appartient à l'éclat du nœud actuel, il sera traité localement; Sinon, il sera acheminé vers l'éclat correspondant. né Opération d'écriture: toujours acheminé vers des éclats de maintien de la touche Zset.
