

Codage de caractères pour une introduction de base à Java
1. ASII
Code américain (national) d'échange d'informations (code).
Il n'y a que des chiffres dans l'ordinateur. Tout est représenté par des chiffres, et les caractères affichés à l'écran ne font pas exception.
Le nombre qui peut être représenté par un octet est 0-255, ce qui est suffisant pour afficher tous les caractères du clavier. Par exemple, a vaut 97 et b vaut 98. Cette règle de codage correspondant aux nombres et aux caractères est appelée code Asc11. Les bits les plus élevés du code ASC11 sont tous à 0, c'est-à-dire que les valeurs du code ASC11 sont comprises entre 0 et 127.
2. GB2312 et GBK (jeu de caractères local de la Chine)
La Chine continentale utilise 2 octets pour représenter chaque caractère chinois, et le premier caractère chinois Les bits les plus élevés de chacun les sections sont toutes 1. Ce format de codage est appelé (gb2312) code standard national. Ensuite, les nombres correspondant au code gb2312 sont des nombres négatifs.
Sur la base de gb2312, d'autres sont ajoutés, comme les caractères chinois traditionnels, appelés GBK
Pièce jointe :
L'encodage GB18030 est une extension basée sur l'encodage GBK, car Il y a plus de caractères chinois, et seul l'utilisation d'un codage sur deux bits ne peut plus prendre en charge les caractères chinois requis, c'est pourquoi une méthode hybride de 24 bits est adoptée pour prendre en charge davantage de codages de caractères chinois.
3. ANSI
Afin d'étendre le codage ASCII pour afficher la langue nationale, différents pays et régions ont formulé différentes normes, ce qui a donné naissance à GB2312, BIG5, JIS et d'autres normes de codage respectives. Ces différentes méthodes de codage chinois étendu qui utilisent 2 octets pour représenter un caractère sont appelées codage ANSI, également connu sous le nom de « MBCS (Muilti-Bytes Charecter Set, jeu de caractères multi-octets) ». Sous le système chinois simplifié, le codage ANSI représente le codage GB2312. Sous le système d'exploitation japonais, le codage ANSI représente le codage JIS. Par conséquent, pour transcoder en gb2312 sous Windows chinois, gbk n'a besoin que d'enregistrer le texte en tant que codage ANSI. Différents codages ANSI sont incompatibles les uns avec les autres.
4. Jeu de caractères locaux
Sur les systèmes informatiques utilisés en Chine continentale, GBK et GB2312 sont appelés les jeux de caractères locaux du système.
Le caractère chinois pour "中国", l'encodage en Chine continentale est hexadécimal D6D0, et à Taiwan, il est A4A4. L'encodage à Taiwan est appelé BIG5 big five code. Lorsqu'un caractère apparaît dans le système de localisation d'un pays et est transmis par courrier électronique au système de localisation d'un autre pays, ce que vous voyez n'est pas le caractère original, mais les caractères ou les caractères tronqués d'un autre pays.
5. Codage Unicode
L'organisation ISO a unifié les symboles à travers le monde et appelle cela le codage Unicode.
Le symbole "中" est l'hexadécimal 4e2d partout dans le monde. Si tous les ordinateurs utilisent le codage Unicode, le mot « 中 » sera affiché sous la forme « 中 » sur les ordinateurs du monde entier. Les caractères codés Unicode occupent deux octets, ce qui est représenté par le code AC11. avec tous les bits égaux à 0 devant l'octet initialement occupé par le code AS11. Le nombre de caractères qu'il représente ne dépassera pas 65535. En fait, il conserve toujours plus de 2 000 valeurs qui ne sont pas utilisées pour l'encodage.
Unicode n'a pas encore formé un monde unifié. Pendant longtemps, le codage de caractères localisé coexistera avec le codage Unicode.
Les caractères en Java sont tous un codage Unicode.
Java prend également en charge les jeux de caractères de plate-forme locale dans le but de garantir des fonctionnalités multiplateformes via Unicode.
6. UTF-8
Dans le processus de développement du langage Java et d'autres programmes, notamment XML, UTF-8 UTF-16 est également impliqué. Unicode au sens large inclut également UTF8 et utf-16
UTF-8
--Les caractères de code ASC11 restent intacts et n'occupent qu'un octet.
--Pour les caractères d'autres pays, UTF-8 utilise 2 ou trois octets pour les représenter.
--En utilisant des fichiers codés en UTF-8, utilisez généralement EF BB BF comme trois octets de données au début du fichier.
7. Règles de conversion entre l'encodage UTF-8 et Unicode
-- 0001-007f (un octet)
0xxxxxx
-- 0000 ou ses caractères entre 0080 et 07ff,
110xxxxx 10xxxxxx (11 bits valides) (entre 0080-07ff) Un unicode a 16 bits, en fait Il n'y a que 11 bits valides, le reste sont des drapeaux.
--Caractères entre 0800 et ffff, 1110xxxx 10xxxxxx 10xxxxxx (16 bits significatifs), le logiciel peut facilement déterminer ce qu'occupe un caractère en fonction des valeurs de bits fixes dans le codage UTF-8 Un octet, deux octets , ou trois octets.
8. Avantages de l'UTF-8
-- ox00 n'apparaît pas (en langage C,
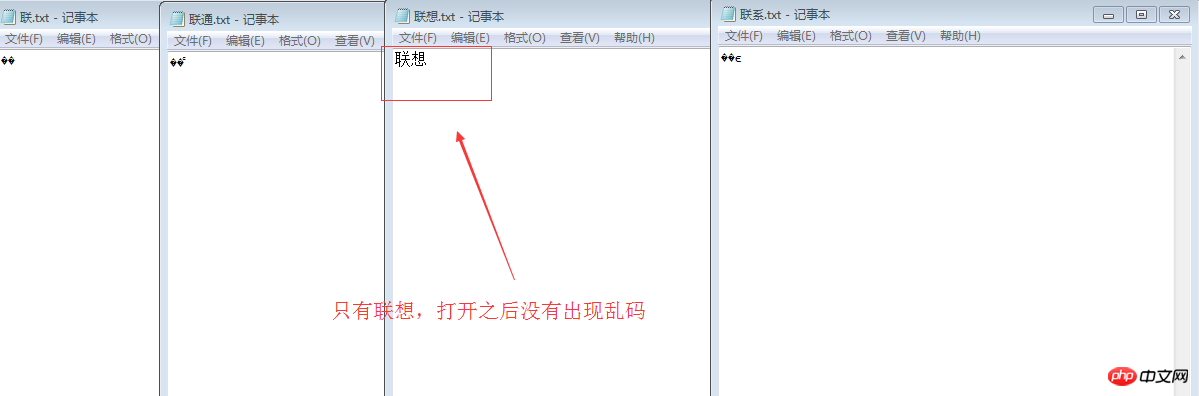
Ouvrez avec ue, vérifiez l'hexadécimal, ce sont C1AA CDA8 C1AA CFE8 //Ceux-ci utilisent tous l'encodage GB2312 Si c'est moyen, c'est D6D0, c'est-à-dire C1AA est le. le lien CDA8 est le même que CFE8. La représentation binaire de celui-ci peut être obtenue de la manière suivante :
int x=0xCDA8; System.out.println(Integer.toBinaryString(x) );
//11000001 10101010 Lien 11001101 10101000 Via le fichier dans
Bloc-notes, la valeur par défaut est Chinois Le jeu de caractères GB2312 est utilisé pour stocker les caractères, de sorte que le caractère « Lian » est analysé en 1100 0001 1010 1010 et le caractère « 通 » est stocké en 1100 1101 1010 1000. Lorsque le document Bloc-notes est ouvert, ces formes binaires correspondent les uns aux autres. Les règles de l'UTF-8 sont suivies, donc le système pense qu'il s'agit d'un fichier codé en UTF-8 et l'interprète comme des caractères tronqués apparaissent. La solution : lors de l'enregistrement, appuyez sur UTF-. 8 directement pour sauvegarder est apparu.
10. Utilisez le programme pour vérifier l'encodage des caractères
Affichez le code GB2312 des caractères chinois
Vérifiez le code UTF-8 des caractères chinois
Afficher le code Unicode des caractères chinois
public static void main(String[] args) throws UnsupportedEncodingException {
String str="中国"; //查看字符的unicode码,将一个字符转成整数,得到的就是unicode值/* for(int i=0;i<str.length();i++){
int unicodeCode=str.charAt(i);
System.out.println(unicodeCode); // 20013,22269
System.out.println(Integer.toHexString(unicodeCode)); //对应的16进制 4e2d,56fd
}*///查看字符的gb2312码byte [] buff =str.getBytes("gb2312"); for(int i=0;i<buff.length;i++){
System.out.println(buff[i]); // -42,-48, -71,-6System.out.println(Integer.toHexString(buff[i])); //ffffffd6 ,ffffffd0 ffffffb9,fffffffa }
}
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Spring Boot simplifie la création d'applications Java robustes, évolutives et prêtes à la production, révolutionnant le développement de Java. Son approche "Convention sur la configuration", inhérente à l'écosystème de ressort, minimise la configuration manuelle, allo
