
 développement back-end
Tutoriel Python
Partagez un cas de la façon dont Python utilise plotly pour dessiner des graphiques de données (images et textes)
développement back-end
Tutoriel Python
Partagez un cas de la façon dont Python utilise plotly pour dessiner des graphiques de données (images et textes)
Partagez un cas de la façon dont Python utilise plotly pour dessiner des graphiques de données (images et textes)

Cet article présente principalement la méthode d'utilisation de plotly pour dessiner des graphiques de données en Python. Il analyse les techniques de dessin de plotly avec des exemples. Il a une certaine valeur de référence.
Introduction : Utilisation Le module python-plotly est utilisé pour dessiner des données de tests de résistance et générer des résultats de page HTML statiques à afficher.
De nombreux amis ont l'expérience des modules de tests de stress pendant le processus de développement. Après le test de stress, tout le monde aime souvent utiliser Excel pour traiter les données du test de stress et dessiner des vues de visualisation des données, mais ce n'est pas très pratique à réaliser. utilisation. Affichage des données sur la page Web. Cet article présentera l'utilisation du module python-plotly pour dessiner des données de tests de résistance et générer une page HTML statique pour faciliter l'affichage des résultats.
Introduction à Plotly
Plotly est un outil de création de graphiques développé à l'aide de JavaScript et fournit une API pour interagir avec les langages d'analyse de données traditionnels (tels comme : Python, R, MATLAB). Vous pouvez vous rendre sur le site officiel https://plot.ly/ pour des informations plus détaillées. Plotly est capable de dessiner de superbes graphiques avec l'interaction de l'utilisateur.
Installation Python-Plotly
Ce document présente principalement l'utilisation de l'API Python de plotly pour effectuer plusieurs Un simple dessin de graphique. Pour plus d'utilisation de Plotly, veuillez vous référer à https://plot.ly/python/
Python-Plotly peut être installé en utilisant pip, et il est préférable de l'installer et de l'utiliser en Python. version 2.7 et supérieure. Si vous utilisez la version Python2.6, veuillez installer Python2.7 et le pip correspondant vous-même.
Exemple de dessin de tracé
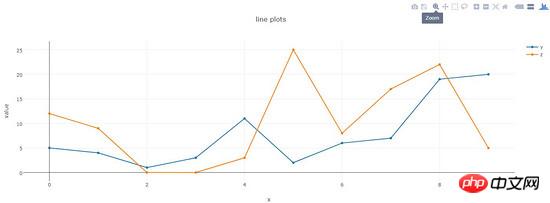
tracés linéaires
Effet de tracé :
La page HTML générée fournit de riches outils interactifs dans le coin supérieur droit.
Code :
def line_plots(name):
'''
绘制普通线图
'''
#数据,x为横坐标,y,z为纵坐标的两项指标,三个array长度相同
dataset = {'x':[0,1,2,3,4,5,6,7,8,9],
'y':[5,4,1,3,11,2,6,7,19,20],
'z':[12,9,0,0,3,25,8,17,22,5]}
data_g = []
#分别插入 y, z
tr_x = Scatter(
x = dataset['x'],
y = dataset['y'],
name = 'y'
)
data_g.append(tr_x)
tr_z = Scatter(
x = dataset['x'],
y = dataset['z'],
name = 'z'
)
data_g.append(tr_z)
#设置layout,指定图表title,x轴和y轴名称
layout = Layout(title="line plots", xaxis={'title':'x'}, yaxis={'title':'value'})
#将layout设置到图表
fig = Figure(data=data_g, layout=layout)
#绘图,输出路径为name参数指定
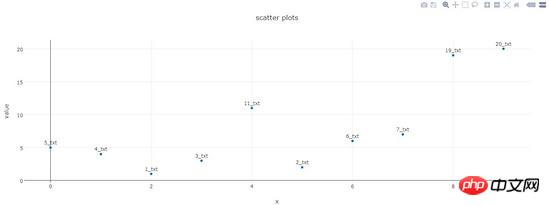
pltoff.plot(fig, filename=name)nuages de points
Effet de dessin :
Code :
def scatter_plots(name):
'''
绘制散点图
'''
dataset = {'x':[0,1,2,3,4,5,6,7,8,9],
'y':[5,4,1,3,11,2,6,7,19,20],
'text':['5_txt','4_txt','1_txt','3_txt','11_txt','2_txt','6_txt','7_txt','19_txt','20_txt']}
data_g = []
tr_x = Scatter(
x = dataset['x'],
y = dataset['y'],
text = dataset['text'],
textposition='top center',
mode='markers+text',
name = 'y'
)
data_g.append(tr_x)
layout = Layout(title="scatter plots", xaxis={'title':'x'}, yaxis={'title':'value'})
fig = Figure(data=data_g, layout=layout)
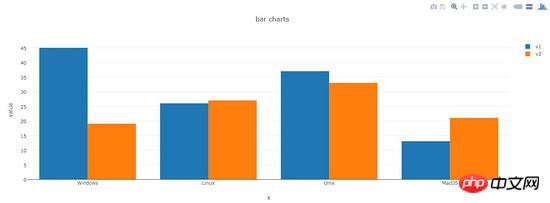
pltoff.plot(fig, filename=name)graphiques à barres
Effet de dessin :
Code :
def bar_charts(name):
'''
绘制柱状图
'''
dataset = {'x':['Windows', 'Linux', 'Unix', 'MacOS'],
'y1':[45, 26, 37, 13],
'y2':[19, 27, 33, 21]}
data_g = []
tr_y1 = Bar(
x = dataset['x'],
y = dataset['y1'],
name = 'v1'
)
data_g.append(tr_y1)
tr_y2 = Bar(
x = dataset['x'],
y = dataset['y2'],
name = 'v2'
)
data_g.append(tr_y2)
layout = Layout(title="bar charts", xaxis={'title':'x'}, yaxis={'title':'value'})
fig = Figure(data=data_g, layout=layout)
pltoff.plot(fig, filename=name)camemberts
Effet de dessin :
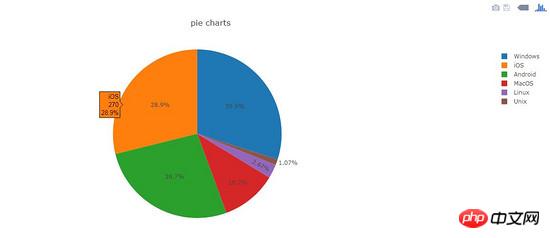
Code :
def pie_charts(name):
'''
绘制饼图
'''
dataset = {'labels':['Windows', 'Linux', 'Unix', 'MacOS', 'Android', 'iOS'],
'values':[280, 25, 10, 100, 250, 270]}
data_g = []
tr_p = Pie(
labels = dataset['labels'],
values = dataset['values']
)
data_g.append(tr_p)
layout = Layout(title="pie charts")
fig = Figure(data=data_g, layout=layout)
pltoff.plot(fig, filename=name)zone remplie -plots
Cet exemple consiste à dessiner un graphique linéaire empilé avec effet de remplissage, adapté à l'analyse de données avec des attributs de pourcentage empilés
Effet de dessin :
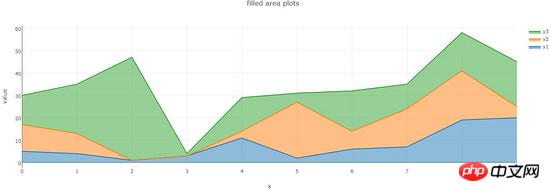
Code :
def filled_area_plots(name):
'''
绘制堆叠填充的线图
'''
dataset = {'x':[0,1,2,3,4,5,6,7,8,9],
'y1':[5,4,1,3,11,2,6,7,19,20],
'y2':[12,9,0,0,3,25,8,17,22,5],
'y3':[13,22,46,1,15,4,18,11,17,20]}
#计算y1,y2,y3的堆叠占比
dataset['y1_stack'] = dataset['y1']
dataset['y2_stack'] = [y1+y2 for y1, y2 in zip(dataset['y1'], dataset['y2'])]
dataset['y3_stack'] = [y1+y2+y3 for y1, y2, y3 in zip(dataset['y1'], dataset['y2'], dataset['y3'])]
dataset['y1_text'] = ['%s(%s%%)'%(y1, y1*100/y3_s) for y1, y3_s in zip(dataset['y1'], dataset['y3_stack'])]
dataset['y2_text'] = ['%s(%s%%)'%(y2, y2*100/y3_s) for y2, y3_s in zip(dataset['y2'], dataset['y3_stack'])]
dataset['y3_text'] = ['%s(%s%%)'%(y3, y3*100/y3_s) for y3, y3_s in zip(dataset['y3'], dataset['y3_stack'])]
data_g = []
tr_1 = Scatter(
x = dataset['x'],
y = dataset['y1_stack'],
text = dataset['y1_text'],
hoverinfo = 'x+text',
mode = 'lines',
name = 'y1',
fill = 'tozeroy' #填充方式: 到x轴
)
data_g.append(tr_1)
tr_2 = Scatter(
x = dataset['x'],
y = dataset['y2_stack'],
text = dataset['y2_text'],
hoverinfo = 'x+text',
mode = 'lines',
name = 'y2',
fill = 'tonexty' #填充方式:到下方的另一条线
)
data_g.append(tr_2)
tr_3 = Scatter(
x = dataset['x'],
y = dataset['y3_stack'],
text = dataset['y3_text'],
hoverinfo = 'x+text',
mode = 'lines',
name = 'y3',
fill = 'tonexty'
)
data_g.append(tr_3)
layout = Layout(title="field area plots", xaxis={'title':'x'}, yaxis={'title':'value'})
fig = Figure(data=data_g, layout=layout)
pltoff.plot(fig, filename=name)Résumé
Cet article présente comment dessiner des graphiques de données à l'aide de python- plotly , les exemples incluent des tracés linéaires, des nuages de points, des graphiques à barres, des diagrammes circulaires et des tracés à zones remplies, qui couvrent essentiellement les cinq graphiques typiques. Pour la plupart des types de données de test, vous pouvez les déformer et dessiner de plus belles icônes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: Une base de données Python évolutive de haut niveau légère HaDIDB (HaDIDB) est une base de données légère écrite en Python, avec un niveau élevé d'évolutivité. Installez HaDIDB à l'aide de l'installation PIP: PiPinStallHaDIDB User Management Créer un utilisateur: CreateUser () pour créer un nouvel utilisateur. La méthode Authentication () authentifie l'identité de l'utilisateur. FromHadidb.OperationMportUserUser_OBJ = User ("Admin", "Admin") User_OBJ.
 MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL peut s'exécuter sans connexions réseau pour le stockage et la gestion des données de base. Cependant, la connexion réseau est requise pour l'interaction avec d'autres systèmes, l'accès à distance ou l'utilisation de fonctionnalités avancées telles que la réplication et le clustering. De plus, les mesures de sécurité (telles que les pare-feu), l'optimisation des performances (choisissez la bonne connexion réseau) et la sauvegarde des données sont essentielles pour se connecter à Internet.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 MySQL Workbench peut-il se connecter à MariaDB
Apr 08, 2025 pm 02:33 PM
MySQL Workbench peut-il se connecter à MariaDB
Apr 08, 2025 pm 02:33 PM
MySQL Workbench peut se connecter à MARIADB, à condition que la configuration soit correcte. Sélectionnez d'abord "MariADB" comme type de connecteur. Dans la configuration de la connexion, définissez correctement l'hôte, le port, l'utilisateur, le mot de passe et la base de données. Lorsque vous testez la connexion, vérifiez que le service MARIADB est démarré, si le nom d'utilisateur et le mot de passe sont corrects, si le numéro de port est correct, si le pare-feu autorise les connexions et si la base de données existe. Dans une utilisation avancée, utilisez la technologie de mise en commun des connexions pour optimiser les performances. Les erreurs courantes incluent des autorisations insuffisantes, des problèmes de connexion réseau, etc. Lors des erreurs de débogage, analysez soigneusement les informations d'erreur et utilisez des outils de débogage. L'optimisation de la configuration du réseau peut améliorer les performances
 MySQL a-t-il besoin d'un serveur
Apr 08, 2025 pm 02:12 PM
MySQL a-t-il besoin d'un serveur
Apr 08, 2025 pm 02:12 PM
Pour les environnements de production, un serveur est généralement nécessaire pour exécuter MySQL, pour des raisons, notamment les performances, la fiabilité, la sécurité et l'évolutivité. Les serveurs ont généralement un matériel plus puissant, des configurations redondantes et des mesures de sécurité plus strictes. Pour les petites applications à faible charge, MySQL peut être exécutée sur des machines locales, mais la consommation de ressources, les risques de sécurité et les coûts de maintenance doivent être soigneusement pris en considération. Pour une plus grande fiabilité et sécurité, MySQL doit être déployé sur le cloud ou d'autres serveurs. Le choix de la configuration du serveur approprié nécessite une évaluation en fonction de la charge d'application et du volume de données.
