
 base de données
tutoriel mysql
Exemple détaillé de la façon dont MySQL implémente le processus de réplication maître-esclave (image)
base de données
tutoriel mysql
Exemple détaillé de la façon dont MySQL implémente le processus de réplication maître-esclave (image)
Exemple détaillé de la façon dont MySQL implémente le processus de réplication maître-esclave (image)

Cet article présente principalement en détail le processus de mise en œuvre de la réplication maître-esclave MySQL, qui a une certaine valeur de référence. Les amis intéressés peuvent s'y référer
1. Qu'est-ce que la réplication maître-esclave
transmet les opérations DDL et DML de la base de données maître à la base de données esclave via des journaux binaires (BINLOG), puis réexécute (refait) ces journaux rendant ainsi les données de la base de données esclave cohérentes avec celles du maître ; base de données La base de données reste cohérente.2. Le rôle de la réplication maître-esclave
1. S'il y a un problème avec la base de données maître, vous pouvez passer à la base de données esclave. 2. La séparation en lecture et en écriture peut être effectuée au niveau de la base de données 3. Une sauvegarde quotidienne peut être effectuée sur la base de données secondaire3.
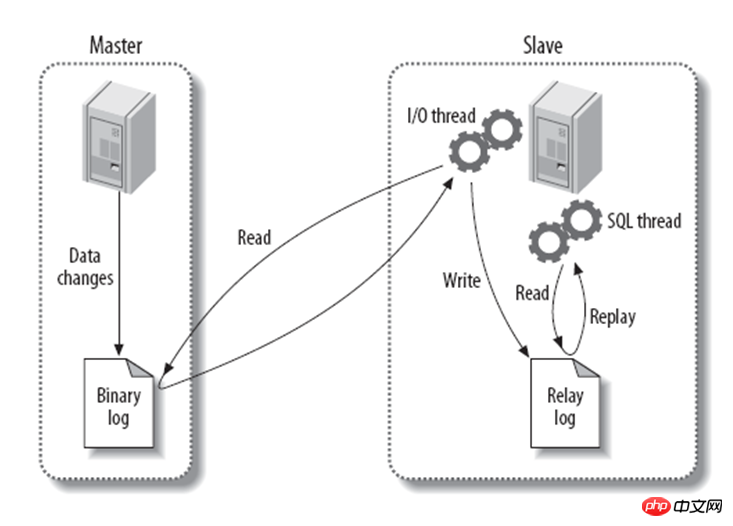
Non. Étape : Le maître écrit l'enregistrement de l'opération en série dans le fichier binlog avant que chaque donnée de mise à jour de transaction ne soit terminée.
Étape 2 : salve ouvre un thread d'E/S Ce thread ouvre une connexion normale sur le maître et sa tâche principale est le processus de vidage du journal binaire. Si la progression de la lecture a rattrapé le maître, il entre en état de veille et attend que le maître génère de nouveaux événements. Le but ultime du thread d'E/S est d'écrire ces événements dans le journal du relais.
Étape 3 : SQL Thread lira le journal de relais et exécutera les événements SQL dans le journal de manière séquentielle pour être cohérent avec les données de la base de données principale.
4. Opérations spécifiques de réplication maître-esclave
J'ai installé deux instances msyql dans des chemins différents sur les mêmes fenêtres. Il est recommandé que les versions installées de MySQL entre le maître et l'esclave ici soient cohérentes, bien que la mienne soit incohérente.
maître
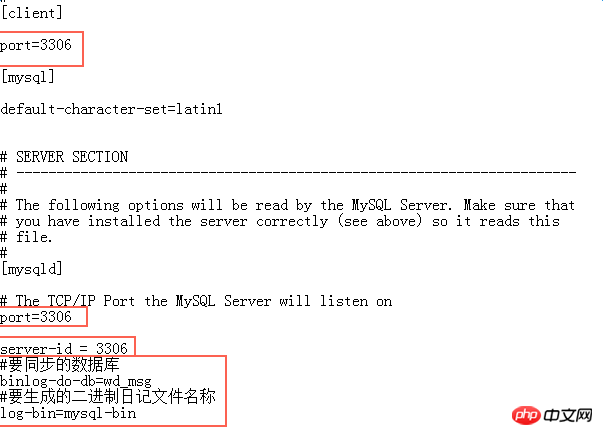
salve
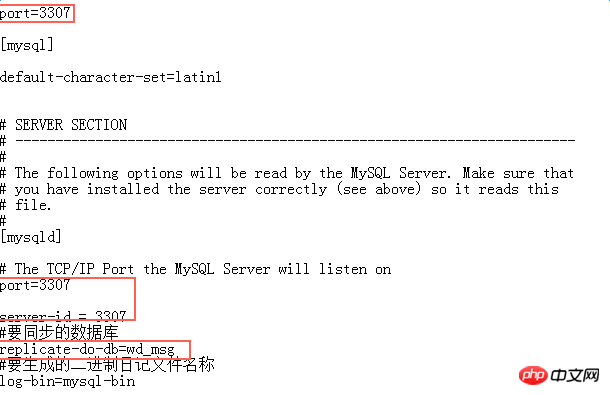

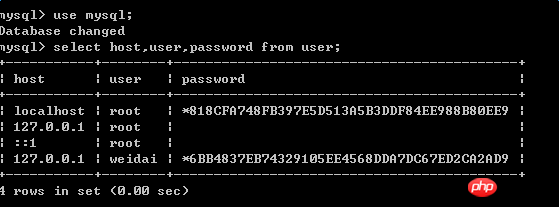
Lorsque j'ai fait la première opération, j'ai terminé la création de ce compte ici, mais lorsque je l'ai effectivement copié, j'ai constaté qu'il n'y avait pas de copie . Avec succès, lors du dépannage de l'erreur, j'ai constaté qu'il n'y avait aucun problème avec le binlong généré par le maître, puis j'ai vérifié l'état de l'esclave :



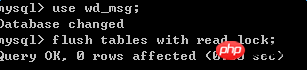

4. La base de données principale effectue une sauvegarde des données. Il existe de nombreuses méthodes de sauvegarde, je ne les présenterai pas ici. Une fois la sauvegarde terminée, le verrou de lecture peut être libéré, ainsi que la principale. la base de données peut effectuer des opérations d'écriture

5. Démarrez la base de données esclave et restaurez les données qui viennent d'être sauvegardées. À ce moment, les données des bases de données maître et esclave au moment de la sauvegarde. point sont cohérents.
6. Configuration liée au comportement de réplication sur la base de données esclave
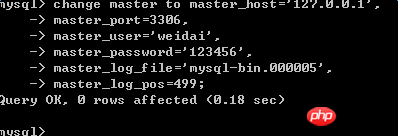
7. À ce stade, la configuration est terminée, mais la base de données esclave ne peut pas être synchronisée. encore et doit être démarré. le fil esclave
8 Créez une table et ajoutez des données dans le maître, et observez-la dans l'esclave :
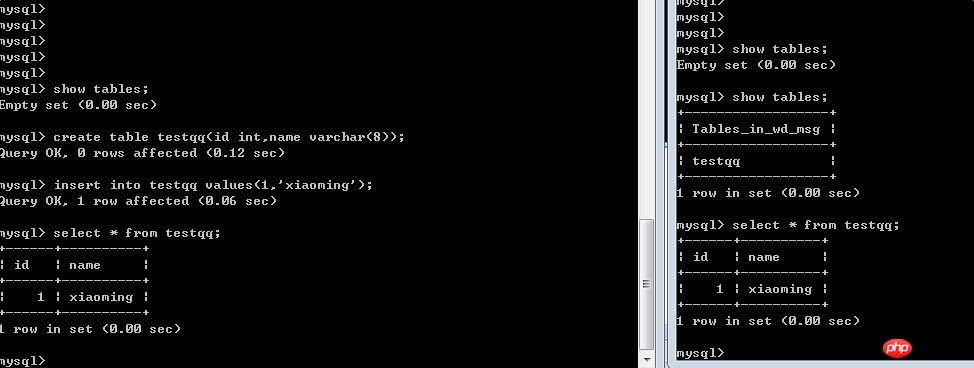
Oui On voit que les opérations que j'effectue chez le maître peuvent se refléter chez l'esclave A cette époque, l'esclave est comme un miroir du maître.
5. Interprétation de l'état de synchronisation maître-esclave
Utilisez la commande sur l'esclave pour afficher :
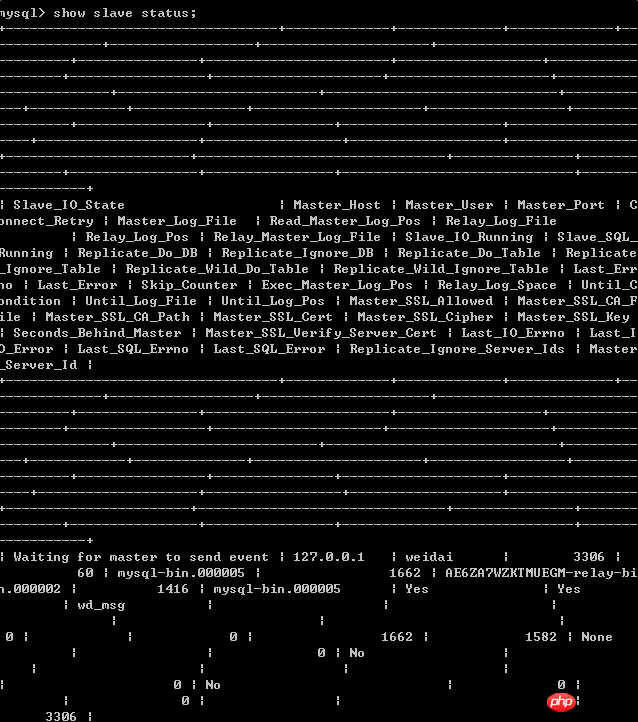
À cause de la composition, c'est trop moche, j'ai donc réglé le problème comme suit :
Slave_IO_STATE:Waiting for master to send event Master_host:127.0.0.1 Master_user:weidai Master_port:3306 connnect_retry:60 Master_log_file:mysql-bin.000005 Read_Master_log_pos:1662 Relay_log_file:AE6Z*****-relay-bin.000002 Relay_log_pos:1415 Slave_IO_Running:yes Slave_SQL_Running:yes
----------------------- ---------- --------------------------Magnifique ligne de démarcation--------------- --------------- -----------------------
Slave_IO_Running : oui
Slave_SQL_Running : oui
Ces deux threads Comme mentionné précédemment, ce sont deux threads très importants sur l'esclave qui participent au processus de réplication. OUI signifie normal, NON signifie anormal.
Le thread Slave_IO copie principalement le contenu du journal binlong sur le maître dans le journal de relais de l'esclave (Relay_log). Généralement, la probabilité de problèmes est faible. La plupart des problèmes sont causés par des autorisations ou des problèmes de réseau. maître. Tout comme l'erreur mentionnée précédemment.
Le thread Slave_SQL est responsable de l'exécution du SQL dans le journal de relais, et la probabilité d'erreurs est relativement élevée. Si quelqu'un insère manuellement certains enregistrements dans la base de données esclave, un conflit de clé primaire se produira lors de la synchronisation maître-esclave.
Slave_IO_STATE : En attente que le maître envoie l'événement
Cet état indique que la synchronisation du journal du relais est terminée et en attente de nouveaux événements générés par le maître.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
La surveillance efficace des bases de données Redis est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Le service Redis Exporter est un utilitaire puissant conçu pour surveiller les bases de données Redis à l'aide de Prometheus. Ce didacticiel vous guidera à travers la configuration et la configuration complètes du service Redis Exportateur, en vous garantissant de créer des solutions de surveillance de manière transparente. En étudiant ce tutoriel, vous réaliserez les paramètres de surveillance entièrement opérationnels
 Comment afficher l'erreur de base de données SQL
Apr 10, 2025 pm 12:09 PM
Comment afficher l'erreur de base de données SQL
Apr 10, 2025 pm 12:09 PM
Les méthodes de visualisation des erreurs de base de données SQL sont: 1. Afficher directement les messages d'erreur; 2. Utilisez des erreurs d'affichage et des commandes d'avertissement Show; 3. Accédez au journal d'erreur; 4. Utiliser les codes d'erreur pour trouver la cause de l'erreur; 5. Vérifiez la connexion de la base de données et la syntaxe de requête; 6. Utilisez des outils de débogage.
