
 Java
javaDidacticiel
Résumer et partager plusieurs structures de données couramment utilisées en Java
Java
javaDidacticiel
Résumer et partager plusieurs structures de données couramment utilisées en Java
Résumer et partager plusieurs structures de données couramment utilisées en Java
Structures de données couramment utilisées en JAVA (java.util.)
Il existe plusieurs structures de données couramment utilisées en Java, principalement divisées en Collection et map. Il existe deux interfaces principales (les interfaces fournissent uniquement des méthodes, pas des implémentations), et les structures de données finalement utilisées dans le programme sont des classes de structures de données héritées de ces interfaces. Les principales relations (relations d'héritage) sont : (----Voir la documentation de l'API Java pour plus de détails !) GT ;TreeMap
Collection---->Liste----->(Vector ArryList LinkedIn 🎜>
Collection---->Set------>(HashSet LinkedHashSet SortedSet)
--------------Collection----------------
1. Collections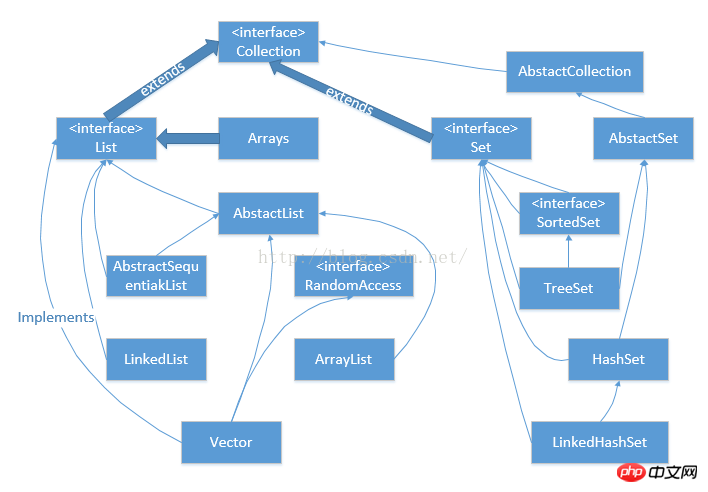
 API--- -Cette classe se compose exclusivement de méthodes statiques qui opèrent sur ou renvoient des collections. Elle contient des algorithmes polymorphes qui opèrent sur des collections, des "wrappers", qui renvoient une nouvelle collection soutenue par une collection spécifiée, et quelques autres.
bric-à-brac.
API--- -Cette classe se compose exclusivement de méthodes statiques qui opèrent sur ou renvoient des collections. Elle contient des algorithmes polymorphes qui opèrent sur des collections, des "wrappers", qui renvoient une nouvelle collection soutenue par une collection spécifiée, et quelques autres.
bric-à-brac.
Les méthodes de cette classe lèvent toutes une
NullPointerExceptionsi les collections ou les objets de classe qui leur sont fournis sont nuls
2、List
<.> API----Cette classe se compose exclusivement de méthodes statiques qui opèrent sur ou renvoient des collections. Elle contient des algorithmes polymorphes qui opèrent sur des collections, des « wrappers », qui renvoient une nouvelle collection soutenue par une collection spécifiée, et quelques autres cotes. et se termine.Les méthodes de cette classe lèvent toutes une NullPointerException
si les collections ou les objets de classe qui leur sont fournis sont nulsList est ordonné Collection, utilisez cette interface pour contrôler précisément la position d’insertion de chaque élément. Les utilisateurs peuvent utiliser l'index (la position de l'élément dans la liste, similaire à l'indice du tableau) pour accéder aux éléments de la liste, ce qui est similaire aux tableaux Java.
3. Vecteur
API---- La classe
implémente un tableau d'objets extensible. Comme un tableau, elle contient des composants accessibles à l'aide d'un index entier. Cependant, la taille de a peut augmenter ou diminuer selon les besoins pour permettre l'ajout et la suppression d'éléments après. the a été créé.Utilisation, il est donc difficile d'éviter les limitations des tableaux, et en même temps, les performances ne peuvent pas dépasser les tableaux. Par conséquent, lorsque cela est possible, nous devrions utiliser davantage les tableaux. Un autre point très important est que Vector est synchronisé avec les threads (synchronisé), c'est pourquoi Vector et ArrayList une différence importante.
VectorVectorVector
API ---- Implémentation de tableau redimensionnable de l'API. Interface List. Implémente toutes les opérations de liste facultatives et autorise tous les éléments, y comprisnull
. En plus d'implémenter l'interfaceList, cette classe fournit des méthodes de manipulation.
la taille du tableau utilisé en interne pour stocker la liste. (Cette classe est à peu près équivalente à
, sauf qu'elle n'est pas synchronisée.) Comme Vector, il s'agit d'une liste chaînée basée sur un tableau, mais la différence est qu'ArrayList n'est pas synchronisé. Par conséquent, il est meilleur que Vector en termes de performances, mais lors de l'exécution dans un environnement multithread, vous devez gérer vous-même la synchronisation des threads.
API ---- Implémentation de liste chaînée de l'interface List. Implémente toutes les opérations de liste facultatives et autorise tous les éléments (y comprisnull En plus d'implémenter l'interfaceList, le. La classe LinkedList fournit des méthodes nommées de manière uniforme pourobtenir, supprimer etinsérer un élément au début et à la fin de la liste. Ces opérations permettent de créer des listes chaînées. être utilisé comme pile, file d'attente,
ou une file d'attente double. LinkedList est différente des deux listes précédentes en ce sens qu'elle n'est pas basée sur des tableaux, elle n'est donc pas limitée par les performances des tableaux. Toutes les listes ne peuvent contenir que des tables composées d'un seul objet de différents types, et non de paires clé-valeur. Par exemple : [ tom,1,c ] Toutes les listes peuvent avoir les mêmes éléments, par exemple, Vector peut avoir [ tom ,koo,too,koo ] Toutes les listes peuvent avoir des éléments nuls, tels que [ tom,null,1 ] La liste basée sur un tableau (Vector, ArrayList) convient aux requêtes, tandis que LinkedList convient aux opérations d'ajout et de suppression API -----Une collection qui ne contient aucun élément en double Plus formellement, les ensembles ne contiennent aucune paire d'éléments Set est une collection API -----Cette classe implémente l'interfaceSet, soutenue par une table de hachage (en fait une instanceHashMap. Elle ne donne aucune garantie quant à l'itération).
l'ordre de l'ensemble ; en particulier, cela ne garantit pas que l'ordre restera constant dans le temps. Cette classe autorise l'élément null Bien que Set et List implémentent tous deux l'interface Collection, leurs méthodes d'implémentation sont. bien différent. La liste est essentiellement basée sur Array. Mais Set est implémenté sur la base de HashMap. C'est la différence fondamentale entre Set et List. La méthode de stockage de HashSet consiste à utiliser la clé dans HashMap comme élément de stockage correspondant de Set. jetez un oeil
L'implémentation de la méthode add(Object obj) de HashSet est visible en un coup d'œil. 8. LinkedHashSet List, la classeLinkedList fournit des méthodes nommées de manière uniforme. pourobtenir, supprimer etinsérer un élément en début et en fin de liste. Ces opérations permettent d'utiliser des listes chaînées comme pile, file d'attente,
ou une file d'attente double Une sous-classe de HashSet, une liste chaînée. 9. >API---A qui fournit en outre unordre total Résumé de l'ensemble : La carte est un objet clé Un conteneur associé avec un objet de valeur, et un objet de valeur peut être une carte, et ainsi de suite, formant ainsi une carte à plusieurs niveaux. Pour les objets clés, comme Set, les objets clés d'un conteneur Map ne peuvent pas être répétés afin de maintenir la cohérence des résultats de la recherche. S'il y a deux objets clés identiques, vous souhaitez obtenir la valeur. objet correspondant à cet objet clé. Il y aura un problème. Peut-être que ce que vous obtiendrez n'est pas l'objet de valeur que vous pensiez, et le résultat sera une confusion. Par conséquent, le caractère unique de la clé est très important et correspond à la nature de. l'ensemble. Bien entendu, lors de l'utilisation, l'objet valeur correspondant à une certaine clé peut changer. Dans ce cas, le dernier objet valeur modifié correspondra à la clé. Il n'y a aucune exigence d'unicité pour les objets de valeur. Vous pouvez mapper n'importe quel nombre de clés à un objet de valeur sans aucun problème (mais cela peut gêner votre utilisation. Vous ne savez pas ce que vous obtenez. L'objet de valeur correspond-il à cela ? clé). API ---- Implémentation basée sur une table de hachage de l'interfaceMap. Cette implémentation fournit toutes les opérations cartographiques facultatives et permetnull
valeurs et la clé null. (La classe HashMap est à peu près équivalente àHashtable, sauf qu'elle n'est pas synchronisée et autorise les valeurs nulles.) Cette classe ne fait aucune valeur. garantit quant à l'ordre de la carte notamment, il ne garantit pas que
l'ordre restera constant dans le temps. API ----Une implémentation TreeMap stocke les clés dans l'ordre, par conséquent, il possède des méthodes étendues, telles que firstKey(), lastKey(), etc. Vous pouvez également spécifier une plage de TreeMap pour obtenir sa sous-carte. ------------Description---------- 1. Différences entre plusieurs catégories couramment utilisées 5. LinkedList
Chaque nœud (Node) contient deux aspects de contenu :
1 Les données du nœud lui-même
2. informations sur le nœud (nextNode).
Ainsi, lors de l'ajout et de la suppression d'actions dans LinkedList, il n'est pas nécessaire de déplacer beaucoup de données comme ArrayList basé sur un tableau. Ceci peut être réalisé en modifiant simplement les informations pertinentes de nextNode. C'est l'avantage de LinkedList. Résumé de la liste :
6. Set (Interface)
e1 et tel que e2, et au plus un élément nul. Comme son nom l'indique, cette interface modélise l'abstraction mathématiquee1.equals(e2)set
7. HashSet
List interface. Implémente toutes les opérations de liste facultatives et autorise tous les éléments (y comprisnull
). En plus d'implémenter l'interface généralement fourni au moment de la création de l'ensemble trié. L'itérateur de l'ensemble parcourra.
l'ensemble dans l'ordre croissant des éléments. Plusieurs opérations supplémentaires sont fournies pour profiter de l'ordre (Cette interface est l'analogue de l'ensemble de.)
Set. Ordered Set, est implémenté via SortedMap. ComparatorSortedMap
La base de l'implémentation de Set est Map (HashMap) (2)Les éléments de Set ne peuvent pas être répétés si vous utilisez add(Object.
obj) la méthode pour ajouter un objet existant écrasera l'objet précédent
------------Carte----------------
1. HashMap
2. TreeMap
NavigableMap basée sur un arbre rouge-noir. .La carte est triée selon
à l'ordre naturel de ses clés, ou par unComparator fourni au moment de la création de la carte, selon le constructeur utilisé
L'association entre clés et valeurs est très simple. Utilisez la méthode put(Object key, Object value) pour associer une clé à un objet valeur. Utilisez get(Object key) pour obtenir l'objet valeur correspondant à cet objet clé.
1. Liste de tableaux :
Élément unique, haute efficacité, principalement utilisé pour la requête
2. Vecteur:
Élément unique, thread-safe, principalement utilisé pour la requête
3. LinkedList : élément unique, principalement utilisé pour l'insertion et la suppression
4. Carte de hachage :
Les éléments sont par paires, et les éléments peuvent être vides
5. Table de hachage :
Les éléments sont appariés, thread-safe et les éléments ne peuvent pas être nuls 2 Vector, ArrayList et LinkedList
Dans la plupart des cas. , ArrayList est le meilleur en termes de performances, mais en ce qui concerne les collections, LinkedList fonctionnera mieux lorsque les éléments qu'il contient doivent être fréquemment insérés et supprimés, mais les performances des trois d'entre eux ne sont pas aussi bonnes que celles des tableaux. De plus, Vector est synchronisé avec les threads. Donc :
Si vous pouvez utiliser un tableau (le type d'élément est fixe, la longueur du tableau est fixe), veuillez essayer d'utiliser un tableau au lieu de List ;
S'il n'y a pas d'opérations de suppression et d'insertion fréquentes et qu'il n'est pas nécessaire de prendre en compte les problèmes de multithread, ArrayList est préféré ; >Si utilisé dans des conditions multithread, vous pouvez envisager Vector
Si vous devez supprimer et insérer fréquemment, LinkedList est pratique
Si vous ne savez rien, il n'y a rien de mal à utiliser ; Liste de tableaux.
3.
dans
Il existe deux classes dans le framework de classes de collection Java appelées Collections (attention, pas Collection !) et Arrays. Ce sont des outils puissants dans JCF, mais les débutants les ignorent souvent. Selon le document JCF, ces deux classes fournissent des implémentations de wrapper (Wrapper Implementations), des algorithmes de structure de données et des applications liées aux tableaux.
Je suis sûr que vous n'oublierez pas les algorithmes classiques tels que la "demi-recherche" et le "tri" mentionnés ci-dessus. de méthodes statiques nous aident à accomplir facilement ces tâches ennuyeuses dans les classes de structure de données :
binarySearch : recherche binaire.
tri : Tri, voici une méthode similaire au tri rapide, l'efficacité est toujours est O(n
* log n), mais c'est une méthode de tri stable. reverse : Faire fonctionner un tableau linéaire dans l'ordre inverse. C'est une question de test classique sur les structures de données du passé !
faire pivoter : "Faire pivoter" la table linéaire autour d'un certain élément comme axe.
échange : échangez les positions de deux éléments dans une liste linéaire.
…
Les collections ont aussi une fonction importante. est le "Wrapper", qui fournit quelques méthodes pour convertir une collection en une collection spéciale, comme suit :
unmodifiableXXX : convertissez en une collection en lecture seule, où XXX représente six interfaces de collection de base : Collection, List, Map, Set, SortedMap et SortedSet. Si vous insérez ou supprimez une collection en lecture seule, une UnsupportedOperationException sera levée.
synchronizedXXX : Convertir en collection synchronisée.
singleton : créez un ensemble avec un seul élément. Ici, singleton génère un seul ensemble d'éléments. ,
singletonList et singletonMap génèrent respectivement une liste et une carte à élément unique.
Ensemble vide : représenté par les propriétés statiques EMPTY_SET, EMPTY_LIST et EMPTY_MAP de Collections.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Guide du générateur de nombres aléatoires en Java. Nous discutons ici des fonctions en Java avec des exemples et de deux générateurs différents avec d'autres exemples.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 15 Analyse de la technologie de l'indice d'échappement du cercle de monnaie couramment utilisé
Mar 03, 2025 pm 05:48 PM
15 Analyse de la technologie de l'indice d'échappement du cercle de monnaie couramment utilisé
Mar 03, 2025 pm 05:48 PM
Analyse approfondie de l'indice d'évasion des 15 premiers Bitcoin: Perspectives du marché pour 2025 Cet article analyse profondément l'indice de bitcoin d'échappement couramment utilisé, parmi lequel le ratio Bitcoin Rhodl, l'USDT actuel de la gestion de patrimoine et le indice saisonnier d'Altcoin ont atteint l'indice d'évasion en 2024, attirant l'attention du marché. Comment les investisseurs devraient-ils faire face aux risques potentiels? Interprétons ces indicateurs un par un et explorons des stratégies de réponse raisonnables. 1. Explication détaillée des indicateurs clés AHR999 Indicateur de thésaurisation de pièces: créé par AHR999, aidant la stratégie d'investissement fixe Bitcoin. La valeur actuelle est de 1,21, qui se trouve dans la plage d'attente, donc il est recommandé d'être prudent. Lien vers AHR999 Escape Top Indicateur: Un supplément à l'indicateur de thésaurisation de monnaie AHR999, utilisé pour identifier le haut du marché. La valeur actuelle est de 2,48, cette semaine
