

Exemple de concurrence PHP pour interroger MySQL (image)

Cet article présente principalement l'exemple de code de requête simultanée PHP de MySQL. L'éditeur pense que c'est assez bon, je vais donc le partager avec vous maintenant et le donner comme référence. Suivons l'éditeur et jetons un coup d'œil.
J'ai étudié PHP récemment et je l'aime beaucoup. Je suis tombé sur le problème des requêtes simultanées de MySQL en PHP, je l'ai étudié et j'ai laissé une note par le. manière :
Requête de synchronisation
Il s'agit de notre mode d'appel le plus courant. Le client appelle Query[function], lance une commande de requête, attend que le résultat soit renvoyé. , lit le résultat ; puis envoie la deuxième commande de requête et attend que le résultat soit renvoyé, lit le résultat. Le temps total pris sera la somme du temps des deux requêtes. Simplifiez le processus, par exemple, comme indiqué ci-dessous :
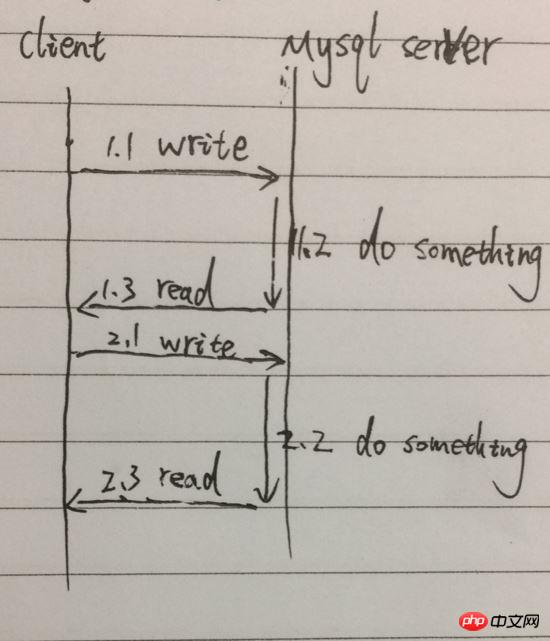
À titre d'exemple, de 1.1 à 1.3 sont les appels d'une requête [fonction]. , 1.2, 1.3, 2.1, 2.2, 2.3, en particulier 1.2 et 2.2 bloqueront l'attente et le processus ne pourra pas faire autre chose.
L'avantage des appels synchrones est qu'ils sont conformes à notre pensée intuitive et sont simples à appeler et à traiter. L'inconvénient est que le processus est bloqué en attendant le retour du résultat, ce qui ajoute du temps d'exécution supplémentaire.
S'il y a plusieurs demandes de requêtes, ou si le processus a d'autres choses à gérer, le temps d'attente peut-il être raisonnablement utilisé pour améliorer la capacité de traitement du processus ? C'est évidemment possible ?
Split
Maintenant, nous divisons la requête [fonction] en morceaux Le client revient immédiatement après 1.1, le client ignore 1.2 et il y a des données dans 1.3 Read. les données après les avoir atteintes. De cette façon, le processus est libéré de l'étape 1.2 d'origine et peut faire plus de choses, comme... lancer une autre requête SQL [2.1], avez-vous vu le prototype de requête simultanée ?
Requête simultanée
Par rapport à la requête synchrone, la requête suivante est lancée une fois la requête précédente terminée. La requête simultanée peut être lancée immédiatement après le lancement de la requête de requête précédente. . Initiez la requête de requête suivante. Simplifiez le processus, comme indiqué ci-dessous :
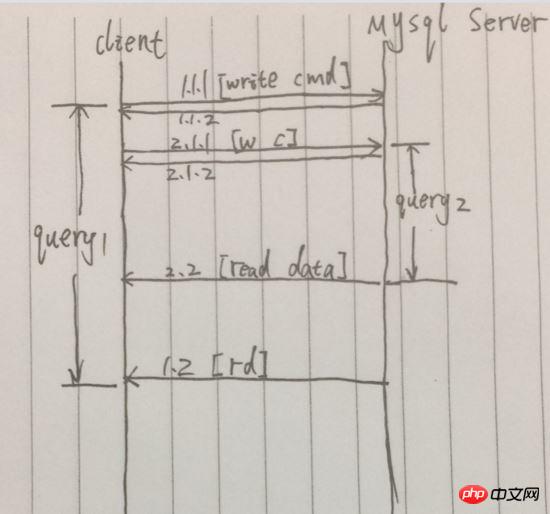
Exemple : Après avoir envoyé avec succès la requête en 1.1.1, [1.1.2] est renvoyé immédiatement et le résultat final de la requête est retourné dans Distant 1.2. Cependant, entre 1.1.1 et 1.2, une autre requête de requête a été lancée. Pendant cette période, deux requêtes de requête ont été lancées en même temps. La 2.2 est arrivée avant la 1.2, de sorte que la consommation totale de temps des deux requêtes n'était que égale au temps. de la première requête.
L'avantage des requêtes simultanées est qu'elles peuvent améliorer le taux d'utilisation du processus, éviter de bloquer l'attente que le serveur traite la requête et raccourcir la durée de plusieurs requêtes. Mais les inconvénients sont également évidents : pour lancer N requêtes simultanées, vous devez établir N liens de bases de données. Pour les applications disposant de pools de connexions à des bases de données, cette situation peut être évitée.
Dégénéré
Idéalement, nous souhaitons exécuter N requêtes simultanément, et la consommation de temps totale est égale à la requête avec la durée de requête la plus longue. Mais il est également possible que des requêtes concurrentes [dégénérent] en [requêtes synchrones]. Quoi? Dans l'image d'exemple, si 1.2 est renvoyé avant 2.1.1, alors la requête simultanée [dégénérera] en [requête synchrone], mais le coût sera supérieur à celui d'une requête synchrone.
Multiplexage
Lancer la requête1
Lancer la requête2
-
Lancer la requête3
......
En attente de la requête1, de la requête2, de la requête3
-
Lire les résultats de la requête2
Lire les résultats de la requête1
Lire les résultats de la requête3
Donc , comment attendre et savoir quand les résultats de la requête sont renvoyés et quels résultats de la requête sont renvoyés ?
Appel read à chaque requête IO ? S'il rencontre un blocage d'E/S, il sera bloqué sur une E/S et les autres E/S verront leurs résultats renvoyés et ne pourront pas être traités. Ainsi, s'il s'agit d'E/S non bloquantes, il n'y a pas lieu de s'inquiéter d'être bloqué sur l'une des E/S. C'est effectivement le cas, mais cela entraînera une interrogation et un jugement continus et un gaspillage des ressources CPU.
Dans cette situation, vous pouvez utiliser le multiplexage pour interroger plusieurs IO.
PHP implémente la requête simultanée MySQL
mysqli de PHP (pilote mysqlnd) fournit des E/S d'interrogation multiplexées (mysqli_poll) et une requête asynchrone (MYSQLI_ASYNC, mysqli_reap_async_query), utilisez ces deux fonctionnalités pour implémenter des requêtes simultanées, exemple de code :
<?php
$sqls = array(
'SELECT * FROM `mz_table_1` LIMIT 1000,10',
'SELECT * FROM `mz_table_1` LIMIT 1010,10',
'SELECT * FROM `mz_table_1` LIMIT 1020,10',
'SELECT * FROM `mz_table_1` LIMIT 10000,10',
'SELECT * FROM `mz_table_2` LIMIT 1',
'SELECT * FROM `mz_table_2` LIMIT 5,1'
);
$links = [];
$tvs = microtime();
$tv = explode(' ', $tvs);
$start = $tv[1] * 1000 + (int)($tv[0] * 1000);
// 链接数据库,并发起异步查询
foreach ($sqls as $sql) {
$link = mysqli_connect('127.0.0.1', 'root', 'root', 'dbname', '3306');
$link->query($sql, MYSQLI_ASYNC); // 发起异步查询,立即返回
$links[$link->thread_id] = $link;
}
$llen = count($links);
$process = 0;
do {
$r_array = $e_array = $reject = $links;
// 多路复用轮询IO
if(!($ret = mysqli_poll($r_array, $e_array, $reject, 2))) {
continue;
}
// 读取有结果返回的查询,处理结果
foreach ($r_array as $link) {
if ($result = $link->reap_async_query()) {
print_r($result->fetch_row());
if (is_object($result))
mysqli_free_result($result);
} else {
}
// 操作完后,把当前数据链接从待轮询集合中删除
unset($links[$link->thread_id]);
$link->close();
$process++;
}
foreach ($e_array as $link) {
die;
}
foreach ($reject as $link) {
die;
}
}while($process < $llen);
$tvs = microtime();
$tv = explode(' ', $tvs);
$end = $tv[1] * 1000 + (int)($tv[0] * 1000);
echo $end - $start,PHP_EOL;Code source mysqli_poll :
#ifndef PHP_WIN32
#define php_select(m, r, w, e, t) select(m, r, w, e, t)
#else
#include "win32/select.h"
#endif
/* {{{ mysqlnd_poll */
PHPAPI enum_func_status
mysqlnd_poll(MYSQLND **r_array, MYSQLND **e_array, MYSQLND ***dont_poll, long sec, long usec, int * desc_num)
{
struct timeval tv;
struct timeval *tv_p = NULL;
fd_set rfds, wfds, efds;
php_socket_t max_fd = 0;
int retval, sets = 0;
int set_count, max_set_count = 0;
DBG_ENTER("_mysqlnd_poll");
if (sec < 0 || usec < 0) {
php_error_docref(NULL, E_WARNING, "Negative values passed for sec and/or usec");
DBG_RETURN(FAIL);
}
FD_ZERO(&rfds);
FD_ZERO(&wfds);
FD_ZERO(&efds);
// 从所有mysqli链接中获取socket链接描述符
if (r_array != NULL) {
*dont_poll = mysqlnd_stream_array_check_for_readiness(r_array);
set_count = mysqlnd_stream_array_to_fd_set(r_array, &rfds, &max_fd);
if (set_count > max_set_count) {
max_set_count = set_count;
}
sets += set_count;
}
// 从所有mysqli链接中获取socket链接描述符
if (e_array != NULL) {
set_count = mysqlnd_stream_array_to_fd_set(e_array, &efds, &max_fd);
if (set_count > max_set_count) {
max_set_count = set_count;
}
sets += set_count;
}
if (!sets) {
php_error_docref(NULL, E_WARNING, *dont_poll ? "All arrays passed are clear":"No stream arrays were passed");
DBG_ERR_FMT(*dont_poll ? "All arrays passed are clear":"No stream arrays were passed");
DBG_RETURN(FAIL);
}
PHP_SAFE_MAX_FD(max_fd, max_set_count);
// select轮询阻塞时间
if (usec > 999999) {
tv.tv_sec = sec + (usec / 1000000);
tv.tv_usec = usec % 1000000;
} else {
tv.tv_sec = sec;
tv.tv_usec = usec;
}
tv_p = &tv;
// 轮询,等待多个IO可读,php_select是select的宏定义
retval = php_select(max_fd + 1, &rfds, &wfds, &efds, tv_p);
if (retval == -1) {
php_error_docref(NULL, E_WARNING, "unable to select [%d]: %s (max_fd=%d)",
errno, strerror(errno), max_fd);
DBG_RETURN(FAIL);
}
if (r_array != NULL) {
mysqlnd_stream_array_from_fd_set(r_array, &rfds);
}
if (e_array != NULL) {
mysqlnd_stream_array_from_fd_set(e_array, &efds);
}
// 返回可操作的IO数量
*desc_num = retval;
DBG_RETURN(PASS);
}Résultats de l'opération de requête simultanée
Afin de voir le effet plus intuitif, j'ai trouvé une table avec un volume de données de 130 millions et n'a pas été optimisée pour le fonctionnement.
Résultats de requêtes simultanées :

Résultats de requêtes synchrones :

De Depuis le résultats, la consommation de temps totale de la requête synchrone est l'accumulation du temps de toutes les requêtes ; et la consommation de temps totale de la requête simultanée est en fait la requête avec la durée la plus longue (la quatrième durée de requête de la requête synchrone est de quelques secondes), cohérente avec le temps total des requêtes simultanées), et l'ordre des requêtes simultanées et l'ordre dans lequel les résultats arrivent sont différents.
Comparaison de plusieurs requêtes avec des temps de requête plus courts
Utilisez plusieurs requêtes SQL avec des temps de requête plus courts à des fins de comparaison
Test 1 des requêtes simultanées Résultats (base de données le temps de liaison est également compté :
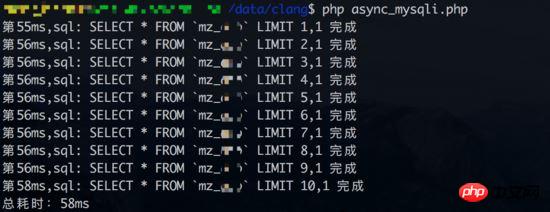
Résultats de requêtes synchrones (le temps de liaison à la base de données est également compté) :

Concurrent Résultats du test de requête 2 (le temps de liaison à la base de données n'est pas compté) :

À en juger par les résultats, le test de requête simultané 1 n'a pas bénéficié. Du point de vue d'une requête synchrone, chaque requête prend environ 3 à 4 ms. Mais si le temps de connexion à la base de données n'est pas inclus dans les statistiques (la requête synchrone n'a qu'une seule connexion à la base de données), les avantages des requêtes simultanées peuvent à nouveau être reflétés.
Conclusion
Ici, nous avons discuté de la mise en œuvre des requêtes simultanées MySQL en PHP et compris intuitivement les avantages et les inconvénients des requêtes simultanées à partir des résultats expérimentaux. Le temps nécessaire pour établir une connexion à une base de données représente toujours une grande partie d'une requête SQL optimisée. #Il n'y a pas de pool de connexion, à quoi ça sert
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'avenir de PHP: adaptations et innovations
Apr 11, 2025 am 12:01 AM
L'avenir de PHP: adaptations et innovations
Apr 11, 2025 am 12:01 AM
L'avenir de PHP sera réalisé en s'adaptant aux nouvelles tendances technologiques et en introduisant des fonctionnalités innovantes: 1) s'adapter aux architectures de cloud computing, de conteneurisation et de microservice, en prenant en charge Docker et Kubernetes; 2) introduire des compilateurs JIT et des types d'énumération pour améliorer l'efficacité des performances et du traitement des données; 3) Optimiser en continu les performances et promouvoir les meilleures pratiques.
 PHP vs Python: comprendre les différences
Apr 11, 2025 am 12:15 AM
PHP vs Python: comprendre les différences
Apr 11, 2025 am 12:15 AM
PHP et Python ont chacun leurs propres avantages, et le choix doit être basé sur les exigences du projet. 1.Php convient au développement Web, avec une syntaxe simple et une efficacité d'exécution élevée. 2. Python convient à la science des données et à l'apprentissage automatique, avec une syntaxe concise et des bibliothèques riches.
 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 PHP: Est-il en train de mourir ou est-ce simplement de s'adapter?
Apr 11, 2025 am 12:13 AM
PHP: Est-il en train de mourir ou est-ce simplement de s'adapter?
Apr 11, 2025 am 12:13 AM
Le PHP n'est pas en train de mourir, mais d'adapter et d'évoluer constamment. 1) PHP a subi plusieurs itérations de version depuis 1994 pour s'adapter aux nouvelles tendances technologiques. 2) Il est actuellement largement utilisé dans le commerce électronique, les systèmes de gestion de contenu et d'autres domaines. 3) PHP8 introduit le compilateur JIT et d'autres fonctions pour améliorer les performances et la modernisation. 4) Utilisez OPCACHE et suivez les normes PSR-12 pour optimiser les performances et la qualité du code.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 PHPMYADMIN CONNEXION MYSQL
Apr 10, 2025 pm 10:57 PM
PHPMYADMIN CONNEXION MYSQL
Apr 10, 2025 pm 10:57 PM
Comment se connecter à MySQL à l'aide de PhpMyAdmin? L'URL pour accéder à phpmyadmin est généralement http: // localhost / phpmyadmin ou http: // [votre adresse IP de serveur] / phpmyadmin. Entrez votre nom d'utilisateur et votre mot de passe MySQL. Sélectionnez la base de données à laquelle vous souhaitez vous connecter. Cliquez sur le bouton "Connexion" pour établir une connexion.
