
 développement back-end
Tutoriel C#.Net
Tutoriel d'implémentation de l'effet de pagination personnalisé Entity Framework
développement back-end
Tutoriel C#.Net
Tutoriel d'implémentation de l'effet de pagination personnalisé Entity Framework
Tutoriel d'implémentation de l'effet de pagination personnalisé Entity Framework
Cet article présente principalement en détail la mise en œuvre générale des effets de pagination personnalisés, des ajouts, des suppressions et des modifications basés sur Entity Framework. Il a une certaine valeur de référence. Les amis intéressés peuvent s'y référer
Introduction<.>
Code
Comment exécuter l'exemple

Classe de base du référentiel - requête
public virtual Tuple<IEnumerable<T>, int> Find(Expression<Func<T, bool>> criteria
, int pageIndex
, int pageSize
, string[] asc
, string[] desc
, params Expression<Func<T, object>>[] includeProperties)Classe de base du référentiel - ajout, suppression et modification
public virtuel T Update (entité T)
public virtuel T CreateOrUpdate (entité T)
public virtuel vide Supprimer (TId id)
var uow = new EFUnitOfWork();
var repo = uow.GetLogRepository();
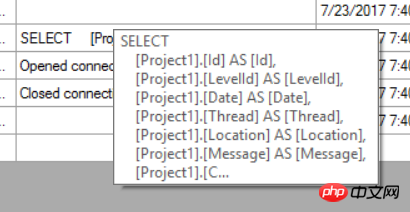
repo.Create(new Log
{
LevelId = 1,
Thread = "",
Location = "Manual Creation",
Message = "This is manually created log.",
CreateTime = DateTimeOffset.Now,
Date = DateTime.Now
});
uow.Commit();Classes dérivées de Repository
.
public class LogRepository : AbstractRepository<Log, int>
{
public LogRepository(EFContext context)
: base(context)
{
}
}À propos de la génération d'entités
Utilisez Logging pour suivre EF SQL
Modèle de spécification
public class LogSearchSpecification : ISpecification<Log>
{
public string LevelName { get; set; }
public string Message { get; set; }
public Expression<Func<Log, bool>> ToExpression()
{
return log => (log.Level.Name == LevelName || LevelName == "") &&
(log.Message.Contains(Message) || Message == "");
}
public bool IsSatisfiedBy(Log entity)
{
return (entity.Level.Name == LevelName || LevelName == "") &&
(entity.Message.Contains(Message) || Message == "");
}
}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment configurer rapidement un avatar personnalisé dans Netflix
Feb 19, 2024 pm 06:33 PM
Comment configurer rapidement un avatar personnalisé dans Netflix
Feb 19, 2024 pm 06:33 PM
Un avatar sur Netflix est une représentation visuelle de votre identité de streaming. Les utilisateurs peuvent aller au-delà de l'avatar par défaut pour exprimer leur personnalité. Continuez à lire cet article pour savoir comment définir une photo de profil personnalisée dans l'application Netflix. Comment définir rapidement un avatar personnalisé dans Netflix Dans Netflix, il n'y a pas de fonctionnalité intégrée pour définir une photo de profil. Cependant, vous pouvez le faire en installant l'extension Netflix sur votre navigateur. Tout d’abord, installez une photo de profil personnalisée pour l’extension Netflix sur votre navigateur. Vous pouvez l'acheter dans la boutique Chrome. Après avoir installé l'extension, ouvrez Netflix sur votre navigateur et connectez-vous à votre compte. Accédez à votre profil dans le coin supérieur droit et cliquez sur
 Problèmes d'installation de Microsoft NET Framework, code d'erreur 0x800c0006, correctif
May 05, 2023 pm 04:01 PM
Problèmes d'installation de Microsoft NET Framework, code d'erreur 0x800c0006, correctif
May 05, 2023 pm 04:01 PM
.NET Framework 4 est requis par les développeurs et les utilisateurs finaux pour exécuter les dernières versions des applications sous Windows. Cependant, lors du téléchargement et de l'installation de .NET Framework 4, de nombreux utilisateurs se sont plaints de l'arrêt du programme d'installation à mi-chemin, affichant le message d'erreur suivant : « .NET Framework 4 n'a pas été installé car le téléchargement a échoué avec le code d'erreur 0x800c0006 ». Si vous le rencontrez également lors de l'installation de .NETFramework4 sur votre appareil, vous êtes au bon endroit
 Comment personnaliser l'image d'arrière-plan dans Win11
Jun 30, 2023 pm 08:45 PM
Comment personnaliser l'image d'arrière-plan dans Win11
Jun 30, 2023 pm 08:45 PM
Comment personnaliser l’image d’arrière-plan dans Win11 ? Dans le nouveau système win11, il existe de nombreuses fonctions personnalisées, mais de nombreux amis ne savent pas comment utiliser ces fonctions. Certains amis pensent que l'image d'arrière-plan est relativement monotone et souhaitent personnaliser l'image d'arrière-plan, mais ne savent pas comment personnaliser l'image d'arrière-plan. Si vous ne savez pas comment définir l'image d'arrière-plan, l'éditeur a compilé les étapes pour. personnalisez l'image d'arrière-plan dans Win11 ci-dessous. Si vous êtes intéressé, jetez un œil ci-dessous ! Étapes de personnalisation des images d'arrière-plan dans Win11 : 1. Cliquez sur le bouton Win sur le bureau et cliquez sur Paramètres dans le menu contextuel, comme indiqué sur la figure. 2. Entrez dans le menu des paramètres et cliquez sur Personnalisation, comme indiqué sur la figure. 3. Entrez Personnalisation et cliquez sur Arrière-plan, comme indiqué sur l'image. 4. Entrez les paramètres d'arrière-plan et cliquez pour parcourir les images
 Comment identifier les problèmes de mise à niveau de Windows à l'aide de SetupDiag sous Windows 11/10
Apr 17, 2023 am 10:07 AM
Comment identifier les problèmes de mise à niveau de Windows à l'aide de SetupDiag sous Windows 11/10
Apr 17, 2023 am 10:07 AM
Chaque fois que votre PC Windows 11 ou Windows 10 rencontre un problème de mise à niveau ou de mise à jour, vous verrez généralement un code d'erreur indiquant la raison réelle de l'échec. Cependant, une confusion peut parfois survenir lorsqu'une mise à niveau ou une mise à jour échoue sans qu'un code d'erreur ne s'affiche. Grâce à des codes d'erreur pratiques, vous savez exactement où se situe le problème afin que vous puissiez essayer de le résoudre. Mais comme aucun code d’erreur n’apparaît, il devient difficile d’identifier le problème et de le résoudre. Cela prendra beaucoup de temps pour simplement découvrir la raison de l'erreur. Dans ce cas, vous pouvez essayer d'utiliser un outil dédié appelé SetupDiag fourni par Microsoft qui vous aide à identifier facilement la véritable raison de l'erreur.
 Comment créer et personnaliser des diagrammes de Venn en Python ?
Sep 14, 2023 pm 02:37 PM
Comment créer et personnaliser des diagrammes de Venn en Python ?
Sep 14, 2023 pm 02:37 PM
Un diagramme de Venn est un diagramme utilisé pour représenter les relations entre des ensembles. Pour créer un diagramme de Venn, nous utiliserons matplotlib. Matplotlib est une bibliothèque de visualisation de données couramment utilisée en Python pour créer des tableaux et des graphiques interactifs. Il est également utilisé pour créer des images et des graphiques interactifs. Matplotlib fournit de nombreuses fonctions pour personnaliser les tableaux et graphiques. Dans ce didacticiel, nous illustrerons trois exemples pour personnaliser les diagrammes de Venn. La traduction chinoise de l'exemple est : Exemple Il s'agit d'un exemple simple de création de l'intersection de deux diagrammes de Venn. Nous avons d'abord importé les bibliothèques nécessaires et importé les Venns. Ensuite, nous créons l'ensemble de données en tant qu'ensemble Python, après quoi nous utilisons la fonction "venn2()" pour créer
 Comment personnaliser les paramètres des touches de raccourci dans Eclipse
Jan 28, 2024 am 10:01 AM
Comment personnaliser les paramètres des touches de raccourci dans Eclipse
Jan 28, 2024 am 10:01 AM
Comment personnaliser les paramètres des touches de raccourci dans Eclipse ? En tant que développeur, la maîtrise des touches de raccourci est l'une des clés pour améliorer l'efficacité du codage dans Eclipse. En tant qu'environnement de développement intégré puissant, Eclipse fournit non seulement de nombreuses touches de raccourci par défaut, mais permet également aux utilisateurs de les personnaliser selon leurs propres préférences. Cet article explique comment personnaliser les paramètres des touches de raccourci dans Eclipse et donne des exemples de code spécifiques. Ouvrez Eclipse Tout d'abord, ouvrez Eclipse et entrez
 Comment activer et personnaliser les fondus enchaînés dans Apple Music sur iPhone avec iOS 17
Jun 28, 2023 pm 12:14 PM
Comment activer et personnaliser les fondus enchaînés dans Apple Music sur iPhone avec iOS 17
Jun 28, 2023 pm 12:14 PM
La mise à jour iOS 17 pour iPhone apporte de gros changements à Apple Music. Cela inclut la collaboration avec d'autres utilisateurs sur des listes de lecture, le lancement de la lecture de musique à partir de différents appareils lors de l'utilisation de CarPlay, et bien plus encore. L'une de ces nouvelles fonctionnalités est la possibilité d'utiliser des fondus enchaînés dans Apple Music. Cela vous permettra de passer facilement d’une piste à l’autre, ce qui est une fonctionnalité intéressante lors de l’écoute de plusieurs pistes. Le fondu enchaîné contribue à améliorer l'expérience d'écoute globale, en vous assurant de ne pas être surpris ou abandonné de l'expérience lorsque la piste change. Alors si vous souhaitez profiter au maximum de cette nouvelle fonctionnalité, voici comment l'utiliser sur votre iPhone. Comment activer et personnaliser le fondu enchaîné pour Apple Music dont vous avez besoin de la dernière version
 Comment créer une pagination personnalisée dans CakePHP ?
Jun 04, 2023 am 08:32 AM
Comment créer une pagination personnalisée dans CakePHP ?
Jun 04, 2023 am 08:32 AM
CakePHP est un framework PHP puissant qui fournit aux développeurs de nombreux outils et fonctionnalités utiles. L'un d'eux est la pagination, qui nous aide à diviser de grandes quantités de données en plusieurs pages, facilitant ainsi la navigation et la manipulation. Par défaut, CakePHP fournit des méthodes de pagination de base, mais vous devrez parfois créer des méthodes de pagination personnalisées. Cet article va vous montrer comment créer une pagination personnalisée dans CakePHP. Étape 1 : Créer une classe de pagination personnalisée Tout d'abord, nous devons créer une classe de pagination personnalisée. ce
