

Cet article présente principalement la lecture de fichiers Java et la fonction d'obtention de numéros de téléphone basés sur des expressions régulières. Il analyse en détail la syntaxe pertinente des opérations de correspondance régulières et les principes et techniques de mise en œuvre de la correspondance des numéros de téléphone avec des exemples. can Pour référence,
L'exemple de cet article décrit la fonction de lecture Java de fichiers et d'obtention de numéros de téléphone basés sur des expressions régulières. Partagez-le avec tout le monde pour votre référence, les détails sont les suivants :
1. Expression régulière
Expression régulière, également connue sous le nom d'expression régulière. , représentation d'expression régulière (anglais : expression régulière, souvent abrégée en regex, regexp ou RE dans le code), un concept en informatique. Les expressions régulières utilisent une seule chaîne pour décrire et faire correspondre une série de chaînes correspondant à une certaine règle de syntaxe. Dans de nombreux éditeurs de texte, les expressions régulières sont souvent utilisées pour récupérer et remplacer du texte correspondant à un certain modèle.
Analyse de la signification de certaines expressions régulières construites spéciales utilisées :
? |
Lorsque ce caractère suit immédiatement l'un des autres qualificatifs (*,+,?, {n}, {n,}, {n,m}), le modèle de correspondance est non gourmand. Le mode non gourmand correspond le moins possible à la chaîne recherchée, tandis que le mode gourmand par défaut correspond le plus possible à la chaîne recherchée. Par exemple, pour la chaîne « oooo », « o+ ? » correspondra à un seul « o », tandis que « o+ » correspondra à tous les « o ». |
. Le point |
correspond à n'importe quel caractère sauf "rn". Pour faire correspondre n'importe quel caractère incluant "rn", utilisez un modèle comme "[sS]". |
(motif) |
Faites correspondre le modèle et obtenez cette correspondance. Les correspondances obtenues peuvent être obtenues à partir de la collection Matches générée, en utilisant la collection SubMatches dans VBScript et les attributs $0...$9 dans JScript. Pour faire correspondre les caractères entre parenthèses, utilisez "". |
(?:motif) |
correspond au motif mais n'obtient pas le résultat correspondant, ce qui signifie qu'il s'agit d'un Les non-correspondances sont obtenues sans les stocker pour une utilisation ultérieure. Ceci est utile lors de la combinaison de parties d'un motif à l'aide du caractère ou "(|)". Par exemple, « industr(?:y|ies) » est une expression plus simple que « industry|industries ». |
(?=motif) |
Recherche positive positive, au début de tout modèle de correspondance de chaîne Correspond à la recherche chaîne. Il s'agit d'une correspondance sans récupération, c'est-à-dire qu'il n'est pas nécessaire de récupérer la correspondance pour une utilisation ultérieure. Par exemple, « Windows(?=95|98|NT|2000) » peut correspondre à « Windows » dans « Windows2000 », mais ne peut pas correspondre à « Windows » dans « Windows3.1 ». La prélecture ne consomme pas de caractères, c'est-à-dire qu'après une correspondance, la recherche de la correspondance suivante commence immédiatement après la dernière correspondance, plutôt qu'après le caractère contenant la prélecture. |
(?!modèle) |
Recherche négative positive, en commençant par toute chaîne qui ne correspond pas au modèle correspond au chaîne de recherche. Il s'agit d'une correspondance sans récupération, c'est-à-dire qu'il n'est pas nécessaire de récupérer la correspondance pour une utilisation ultérieure. Par exemple, « Windows(?!95|98|NT|2000) » peut correspondre à « Windows » dans « Windows3.1 », mais ne peut pas correspondre à « Windows » dans « Windows2000 ». |
(?<=motif) |
Pré-vérification positive inversée, similaire à la pré-vérification positive avant, sauf dans la direction au contraire. Par exemple, "(?<=95|98|NT|2000)Windows" peut correspondre à "Windows" dans "2000Windows", mais ne peut pas correspondre à "Windows" dans "3.1Windows". |
(? |
Aperçu négatif inversé, similaire à l'aperçu négatif direct, juste dans le direction opposée. Par exemple, "(? |
Utiliser des quantificateurs
| X { n }? | X ,恰好 n 次 |
| X { n ,}? | X ,至少 n 次 |
| X { n , m}? | X ,至少 n 次,但是不超过 m 次 |
2、手机号码
组成
国家区域号-手机号码
手机号码格式比较固定,无非是13x xxxx xxxx或者15x xxxx xxxx再或者18x xxxx xxxx的格式。座机就比较麻烦,比如长途区号变长(3位或者4位)电话号码变长(7位或者8位)有些还需要输入分机号。
通常可以看到解决这个复杂问题的解决方案是手机号和座机号分开。座机号拆分成三段,区号,电话号码+分机号。但是为了表单看起来清爽,设计的时候给了一个“万能”的输入框,给用户输入电话号码或者手机号码。
在这样的一个需求的大前提下,用复杂的正则表达式解决验证的问题是一种快速的解决方案。
首先搞定最容易的手机号码
因为目前开放的号段是130-139, 150-159, 185-189, 180
只考虑移动电话(手机)号码的可以使用下面方法
public static void main(String[] args) {
String text = "13522158842;托尔斯泰;test2;13000002222;8613111113313";
Pattern pattern = Pattern.compile("(?<!\\d)(?:(?:1[358]\\d{9})|(?:861[358]\\d{9}))(?!\\d)");
Matcher matcher = pattern.matcher(text);
StringBuffer bf = new StringBuffer(64);
while (matcher.find()) {
bf.append(matcher.group()).append(",");
}
int len = bf.length();
if (len > 0) {
bf.deleteCharAt(len - 1);
}
System.out.println(bf.toString());
}只是手机号码可以匹配可以给出下面的匹配正则表达式:
(?:((13[0-9]{1})|(15[0-9]{1})|(18[0,5-9]{1}))+\\d{8})
当我们 加上国家区域号 (86)或者(+86)或者86-或者直接是86,可以使用下面的正则表达式:
"(?:(\\(\\+?86\\))((13[0-9]{1})|(15[0-9]{1})|(18[0,5-9]{1}))+\\d{8})|" +
"(?:86-?((13[0-9]{1})|(15[0-9]{1})|(18[0,5-9]{1}))+\\d{8})|" +
"(?:((13[0-9]{1})|(15[0-9]{1})|(18[0,5-9]{1}))+\\d{8})"
注意 :为了最长得匹配电话号码,需要写成三句,并且相对长的需要放在前面,否则匹配到了之后,后面的就不会匹配了。
3、座机号码
组成:
国家区域号(+86等)-区号-固定电话号码-分机号
三位 区号 的部分
010, 021-029,852(香港)
因为采用三位区号的地方都是8位电话号码,因此可以写成
(010|021|022|023|024|025|026|027|028|029|852)\d{8}
当然不会这么简单,有些人习惯(010) xxxxxxxx的格式,我们也要支持一把,把以上表达式升级成
再看4位区号的城市
这里简单判断了不可能存在0111或者0222的区号,以及电话号码是7位或者8位。
最后是分机号(1-4位的数字)
(?<分机号>\D?\d{1,4})?
以上拼装起来就是:
"(?:(\\(\\+?86\\))(0[0-9]{2,3}\\-?)?([2-9][0-9]{6,7})+(\\-[0-9]{1,4})?)|" +
"(?:(86-?)?(0[0-9]{2,3}\\-?)?([2-9][0-9]{6,7})+(\\-[0-9]{1,4})?)"
4、编码实现
实现功能:读取文件,将其中的电话号码存入一个Set返回。
方法介绍:
find():尝试查找与该模式匹配的输入序列的下一个子序列。group():返回由以前匹配操作所匹配的输入子序列。
①、从一个字符串中获取出其中的电话号码
import java.util.HashSet;
import java.util.Set;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 从字符串中截取出电话号码
* @author zcr
*
*/
public class CheckIfIsPhoneNumber
{
/**
* 获得电话号码的正则表达式:包括固定电话和移动电话
* 符合规则的号码:
* 1》、移动电话
* 86+‘-'+11位电话号码
* 86+11位正常的电话号码
* 11位正常电话号码a
* (+86) + 11位电话号码
* (86) + 11位电话号码
* 2》、固定电话
* 区号 + ‘-' + 固定电话 + ‘-' + 分机号
* 区号 + ‘-' + 固定电话
* 区号 + 固定电话
* @return 电话号码的正则表达式
*/
public static String isPhoneRegexp()
{
String regexp = "";
//能满足最长匹配,但无法完成国家区域号和电话号码之间有空格的情况
String mobilePhoneRegexp = "(?:(\\(\\+?86\\))((13[0-9]{1})|(15[0-9]{1})|(18[0,5-9]{1}))+\\d{8})|" +
"(?:86-?((13[0-9]{1})|(15[0-9]{1})|(18[0,5-9]{1}))+\\d{8})|" +
"(?:((13[0-9]{1})|(15[0-9]{1})|(18[0,5-9]{1}))+\\d{8})";
// System.out.println("regexp = " + mobilePhoneRegexp);
//固定电话正则表达式
String landlinePhoneRegexp = "(?:(\\(\\+?86\\))(0[0-9]{2,3}\\-?)?([2-9][0-9]{6,7})+(\\-[0-9]{1,4})?)|" +
"(?:(86-?)?(0[0-9]{2,3}\\-?)?([2-9][0-9]{6,7})+(\\-[0-9]{1,4})?)";
regexp += "(?:" + mobilePhoneRegexp + "|" + landlinePhoneRegexp +")";
return regexp;
}
/**
* 从dataStr中获取出所有的电话号码(固话和移动电话),将其放入Set
* @param dataStr 待查找的字符串
* @param phoneSet dataStr中的电话号码
*/
public static void getPhoneNumFromStrIntoSet(String dataStr,Set<String> phoneSet)
{
//获得固定电话和移动电话的正则表达式
String regexp = isPhoneRegexp();
System.out.println("Regexp = " + regexp);
Pattern pattern = Pattern.compile(regexp);
Matcher matcher = pattern.matcher(dataStr);
//找与该模式匹配的输入序列的下一个子序列
while (matcher.find())
{
//获取到之前查找到的字符串,并将其添加入set中
phoneSet.add(matcher.group());
}
//System.out.println(phoneSet);
}
}②、读取文件并调用电话号码获取
实现方式:根据文件路径获得文件后,一行行读取,去获取里面的电话号码
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
/**
* 读取文件操作
*
* @author zcr
*
*/
public class ImportFile
{
/**
* 读取文件,将文件中的电话号码读取出来,保存在Set中。
* @param filePath 文件的绝对路径
* @return 文件中包含的电话号码
*/
public static Set<String> getPhoneNumFromFile(String filePath)
{
Set<String> phoneSet = new HashSet<String>();
try
{
String encoding = "UTF-8";
File file = new File(filePath);
if (file.isFile() && file.exists())
{ // 判断文件是否存在
InputStreamReader read = new InputStreamReader(
new FileInputStream(file), encoding);// 考虑到编码格
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
while ((lineTxt = bufferedReader.readLine()) != null)
{
//读取文件中的一行,将其中的电话号码添加到phoneSet中
CheckIfIsPhoneNumber.getPhoneNumFromStrIntoSet(lineTxt, phoneSet);
}
read.close();
}
else
{
System.out.println("找不到指定的文件");
}
}
catch (Exception e)
{
System.out.println("读取文件内容出错");
e.printStackTrace();
}
return phoneSet;
}
}③、测试
public static void main(String argv[])
{
String filePath = "F:\\three.txt";
Set<String> phoneSet = getPhoneNumFromFile(filePath);
System.out.println("电话集合:" + phoneSet);
}文件中数据:
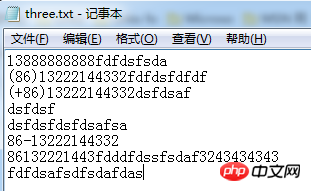
结果:
电话集合:[86132221, (86)13222144332, 86-13222144332, 32434343, (+86)13222144332, 13888888888]
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



