

Introduction détaillée au partitionnement de table dans MySQL

Le partitionnement des tables MySQL est le même que la subdivision de la base de données et des tables, tous deux destinés à améliorer le débit de la base de données. Le partitionnement est similaire au partitionnement de table. Le partitionnement de table consiste à diviser logiquement une table contenant une grande quantité de données en plusieurs tables, qui peuvent être divisées horizontalement ou verticalement. Le partitionnement consiste à diviser un fichier de données d'une table en plusieurs fichiers de données. Différentes données sont divisées en différents fichiers. De cette façon, pour une table contenant une très grande quantité de données, plusieurs fichiers de données sont utilisés pour le stockage, ce qui améliore les performances d'E/S de la base de données.
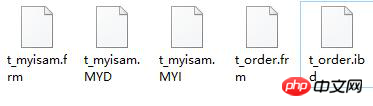
Puisque nous opérons sur les fichiers de la table de données, nous devons d'abord comprendre le stockage de la table MySQL. Nous savons que MySQL dispose de plusieurs moteurs de stockage et que différents moteurs de stockage stockent différents formats de fichiers. Ici, nous utilisons principalement les deux moteurs de stockage InnoDB et MyISAM pour explication.
InnoDB
Structure de la table de données du fichier .frm
.idb fichier de données de la table Fichier, espace table exclusif, chaque table a un fichier .idb
fichier .ibdata fichier de données de table, espace table partagé, toutes les tables utilisent ces données
Fichier
MyISAM
.frm Structure de la table de données du fichier
fichier de données du fichier .myd
fichier d'index de fichier .myi
Tout d'abord, nous avons besoin pour vérifier si notre version actuelle de la base de données prend en charge le partitionnement
1 show variables like '%partition%';
Comment partitionner ? Lors de la segmentation horizontale de la base de données, nous savons que la segmentation horizontale peut être divisée en différentes tables en fonction du module des champs spécifiés, ou elle peut être divisée en fonction de la date, ou segmentée en fonction de l'identifiant, 1-1 million Dans la première table , 1 million et 1 à 2 millions dans le deuxième tableau et ainsi de suite. En bref, nous avons de nombreuses façons de procéder à la segmentation. Ensuite, la base de données nous offre également une variété d’options parmi lesquelles choisir sur les partitions de table.
Stratégie de partitionnement de table MySQL
Partitionnement RANGE basé sur les valeurs des colonnes à intervalles continus, attribuez plusieurs lignes aux partitions
1 DROP TABLE IF EXISTS `p_range`; 2 CREATE TABLE `p_range` ( 3 `id` int(10) NOT NULL AUTO_INCREMENT, 4 `name` char(20) NOT NULL, 5 PRIMARY KEY (`id`) 6 ) ENGINE=MyISAM AUTO_INCREMENT=9 DEFAULT CHARSET=utf8 7 /*!50100 PARTITION BY RANGE (id) 8 (PARTITION p0 VALUES LESS THAN (8) ENGINE = MyISAM) */;
Valeur maximale
1 PARTITION BY RANGE (id) 2 ( 3 PARTITION p0 VALUES LESS THAN (8), 4 PARTITION p1 VALUES LESS THAN MAXVALUE)
Scénarios applicables :
Cela signifie que tous les enregistrements de données avec un identifiant supérieur à 7 existent dans la partition p1.
Le partitionnement RANGE est particulièrement utile dans les situations suivantes :
·Lorsque les "anciennes" données doivent être supprimées. Si vous utilisiez le schéma de partitionnement présenté dans l'exemple le plus récent ci-dessus, vous pouvez simplement utiliser "ALTER TABLE employés DROP PARTITION p0;" pour supprimer toutes les lignes des employés qui ont arrêté de travailler avant 1991. Pour les tables comportant un grand nombre de lignes, cela est beaucoup plus efficace que d'exécuter une requête DELETE telle que "DELETE FROM employés WHERE YEAR(separated) <=
1990;"
· Vous souhaitez utiliser une colonne qui contient des valeurs de date ou d'heure, ou des valeurs qui proviennent d'une autre série.
Exécutez fréquemment des requêtes qui dépendent directement des colonnes utilisées pour diviser la table. Par exemple, lors de l'exécution d'une requête telle que
“SELECT COUNT(*) FROM employees WHERE YEAR(separated) = 2000 GROUP BY store_id;”
, MySQL peut rapidement déterminer que seule la partition p2 doit être analysée, car il est peu probable que les partitions restantes contiennent des données correspondant à cette requête. Tout enregistrement dans la clause WHERE
Le partitionnement LIST est similaire au partitionnement par RANGE, la différence est que le partitionnement LIST est basé sur la correspondance des valeurs de colonne Sélectionnez une valeur parmi un ensemble de valeurs discrètes.
1 DROP TABLE IF EXISTS `p_list`; 2 CREATE TABLE `p_list` ( 3 `id` int(10) NOT NULL AUTO_INCREMENT, 4 `typeid` mediumint(10) NOT NULL DEFAULT '0', 5 `typename` char(20) DEFAULT NULL, 6 PRIMARY KEY (`id`,`typeid`) 7 ) ENGINE=MyISAM AUTO_INCREMENT=9 DEFAULT CHARSET=utf8 8 /*!50100 PARTITION BY LIST (typeid) 9 (PARTITION p0 VALUES IN (1,2,3,4) ENGINE = MyISAM, PARTITION p1 VALUES IN (5,6,7,8) ENGINE = MyISAM) */;
Partitionnement HASH Sélectionnez des partitions en fonction de la valeur de retour d'une expression définie par l'utilisateur à l'aide du tableau à insérer dans Les valeurs de colonne de ces lignes sont calculées. Cette fonction peut contenir n'importe quelle expression valide dans MySQL qui produit une valeur entière non négative. Le partitionnement HASH est principalement utilisé pour garantir que les données sont réparties uniformément entre un nombre prédéterminé de partitions. Dans le partitionnement RANGE et LIST, vous devez spécifier explicitement dans quelle partition une valeur de colonne donnée ou un ensemble de valeurs de colonne doit être enregistrée ; dans le partitionnement HASH, MySQL le fait automatiquement, et tout ce que vous avez à faire est basé sur la valeur à être. haché. La valeur de la colonne spécifie une valeur ou une expression de colonne et spécifie le nombre de partitions dans lesquelles la table partitionnée sera divisée
1 DROP TABLE IF EXISTS `p_hash`; 2 CREATE TABLE `p_hash` ( 3 `id` int(10) NOT NULL AUTO_INCREMENT, 4 `storeid` mediumint(10) NOT NULL DEFAULT '0', 5 `storename` char(255) DEFAULT NULL, 6 PRIMARY KEY (`id`,`storeid`) 7 ) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8 8 /*!50100 PARTITION BY HASH (storeid)9 PARTITIONS 4 */;
简单点说就是数据的存入可以按 partition by hash(expr); 这里的 expr 可以
是键名也可以是表达式比如 YEAR(time),如果是表达式的情况下
“但是应当记住,每当插入或更新(或者可能删除)一行,这个表达式都要计
算一次;这意味着非常复杂的表达式可能会引起性能问题,尤其是在执行同时
影响大量行的运算(例如批量插入)的时候。 ”
在执行删除、写入、更新时这个表达式都会计算一次。
数据的分布采用基于用户函数结果的模数来确定使用哪个编号的分区。换句话,对于一个表达式“expr”,将要保存记录的分区编号为 N ,其中“N = MOD(expr, num)”。
比如上面的 storeid 为 10;那么 N=MOD(10,4) ;N 是等于 2 的,那么这条记录就存储在 p2 的分区里面。
如果插入一个表达式列值为'2005-09-15′的记录到表中,那么保存该条记录的分区确定如下:MOD(YEAR('2005-09-01′),4) = MOD(2005,4) = 1 ; 就存储在 p1 分区里面了。
分区注意点
1、重新分区时,如果原分区里面存在 maxvalue 则新的分区里面也必须包含
maxvalue 否则就错误。
alter table p_range2x reorganize partition p1,p2 into (partition p0 values less than (5), partition p1 values less than maxvalue); [Err] 1520 – Reorganize of range partitions cannot change total ranges except for last partition where it can extend the range
2、分区删除时,数据也同样会被删除 alter table p_range drop partition p0;
3、如果 range 分区列表里面没有 maxvalue 则如有新数据大于现在分区 range 数据值那么这个数据是无法写入到数据库表的。
4、修改表名不需要 删除分区后在进行更改,修改表名后分区存储 myd myi 对应也会自动更改。
如果希望从所有分区删除所有的数据,但是又保留表的定义和表的分区模式,使用 TRUNCATE TABLE 命令。(请参见 13.2.9 节,“TRUNCATE 语法”)。
如果希望改变表的分区而又不丢失数据,使用“ALTER TABLE … REORGANIZE PARTITION”语句。参见下面的内容,或者在 13.1.2 节,“ALTER TABLE 语法” 中参考关于 REORGANIZE PARTITION 的信息。
5、对表进行分区时,不论采用哪种分区方式如果表中存在主键那么主键必须在分区列中。表分区的局限性。
6、list 方式分区没有类似于 range 那种 less than maxvalue 的写法,也就是说 list 分区表的所有数据都必须在分区字段的值列表集合中。
7、在 MySQL 5.1 版中,同一个分区表的所有分区必须使用同一个存储引擎;例如,不能对一个分区使用 MyISAM,而对另一个使用 InnoDB。
8、分区的名字是不区分大小写的,myp1 与 MYp1 是相同的。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
La surveillance efficace des bases de données Redis est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Le service Redis Exporter est un utilitaire puissant conçu pour surveiller les bases de données Redis à l'aide de Prometheus. Ce didacticiel vous guidera à travers la configuration et la configuration complètes du service Redis Exportateur, en vous garantissant de créer des solutions de surveillance de manière transparente. En étudiant ce tutoriel, vous réaliserez les paramètres de surveillance entièrement opérationnels
 Comment afficher l'erreur de base de données SQL
Apr 10, 2025 pm 12:09 PM
Comment afficher l'erreur de base de données SQL
Apr 10, 2025 pm 12:09 PM
Les méthodes de visualisation des erreurs de base de données SQL sont: 1. Afficher directement les messages d'erreur; 2. Utilisez des erreurs d'affichage et des commandes d'avertissement Show; 3. Accédez au journal d'erreur; 4. Utiliser les codes d'erreur pour trouver la cause de l'erreur; 5. Vérifiez la connexion de la base de données et la syntaxe de requête; 6. Utilisez des outils de débogage.
