
1) Index de clé primaire :
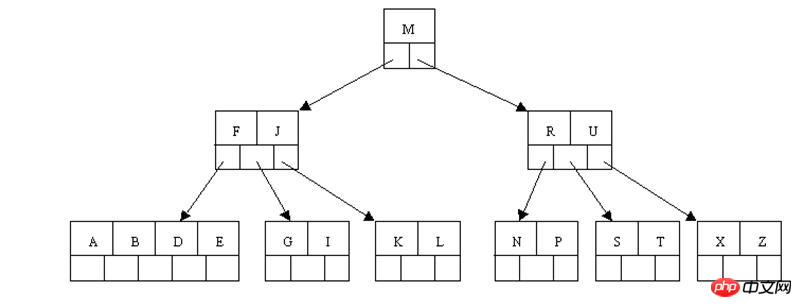
Le moteur MyISAM utilise B+Tree comme structure d'index et le champ de données du Le nœud feuille stocke L'adresse de l'enregistrement de données. La figure suivante est le diagramme schématique de l'index de clé primaire MyISAM :
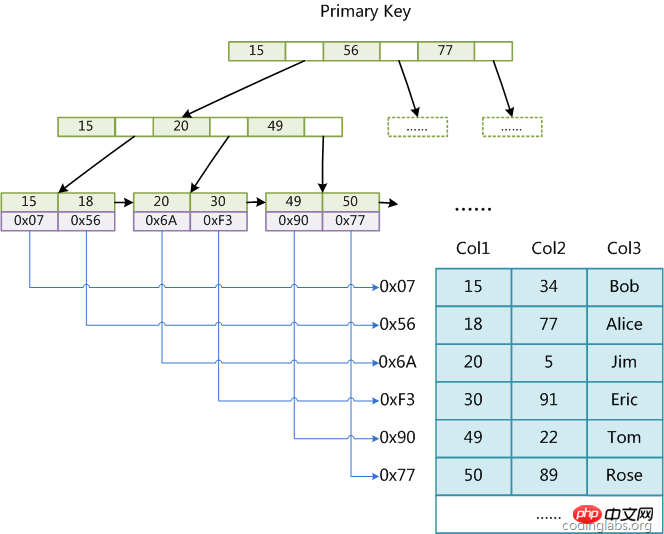
(Image myisam1)
Supposons que la table comporte trois colonnes total. Supposons que nous utilisons Col1 Comme clé primaire, la figure myisam1 montre l'index primaire (Clé primaire) d'une table MyISAM. On peut voir que le fichier d'index de MyISAM enregistre uniquement l'adresse de l'enregistrement de données.
2) Index secondaire (Clé secondaire)
Dans MyISAM, il n'y a pas de différence structurelle entre l'index primaire et l'index secondaire (Clé secondaire). L'index primaire nécessite que la clé soit unique, tandis que la clé de l'index secondaire peut être répétée. Si on crée un index auxiliaire sur Col2, la structure de cet index est la suivante :
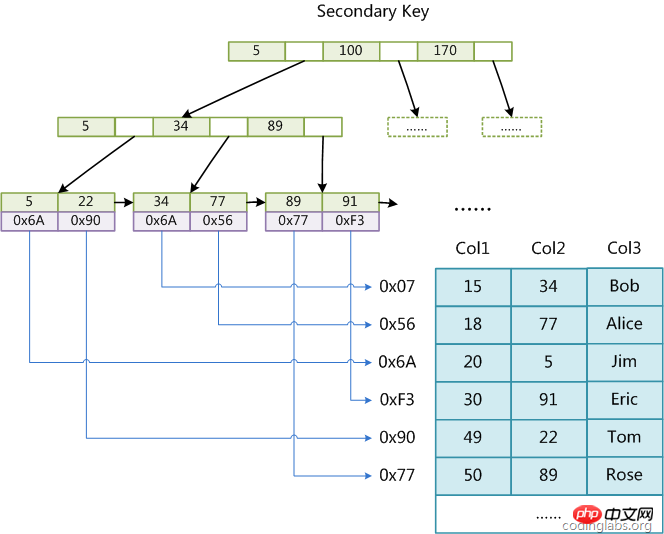
est également la même B+Tree, le champ de données enregistre l'adresse de l'enregistrement de données. Par conséquent, l'algorithme de récupération d'index dans MyISAM consiste à rechercher d'abord l'index selon l'algorithme de recherche B+Tree. Si la clé spécifiée existe, la valeur de son champ de données est supprimée, puis la valeur des données. Le champ est utilisé comme adresse pour lire l'enregistrement de données correspondant.
La méthode d'indexation de MyISAM est également appelée "non clusterisée". La raison pour laquelle elle est appelée ainsi est pour la distinguer de l'index clusterisé d'InnoDB.
Bien qu'InnoDB utilise également B+Tree comme structure d'index, la méthode d'implémentation spécifique est complètement différente de MyISAM.
1) Index de clé primaire :
Le fichier d'index MyISAM et le fichier de données sont séparés, et le fichier d'index enregistre uniquement l'adresse de l'enregistrement de données. Dans InnoDB, le fichier de données de la table lui-même est une structure d'index organisée par B+Tree, et le champ de données du nœud feuille de cet arbre enregistre des enregistrements de données complets. La clé de cet index est la clé primaire de la table de données, donc le fichier de données de la table InnoDB lui-même est l'index primaire.
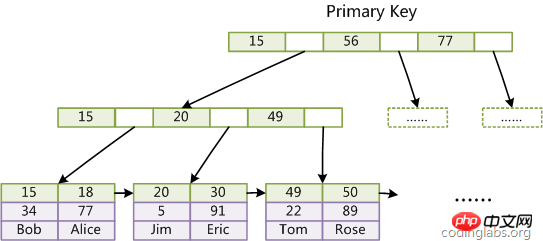
(Figure index de clé primaire inndb) est un diagramme schématique de l'index primaire InnoDB (également un fichier de données). Vous pouvez voir que les nœuds feuilles contiennent des enregistrements de données complets. Ce type d'index est appelé index clusterisé . Étant donné que les fichiers de données d'InnoDB eux-mêmes sont agrégés par clé primaire, InnoDB exige que la table ait une clé primaire (MyISAM peut ne pas en avoir une). Si elle n'est pas explicitement spécifiée, le système MySQL sélectionnera automatiquement une colonne pouvant identifier les données de manière unique. record comme clé primaire. Si elle n'existe pas, Pour ce type de colonne, MySQL génère automatiquement un champ implicite comme clé primaire pour la table InnoDB. La longueur de ce champ est de 6 octets et le type est long.
2). Index auxiliaire d'InnoDB
Tous les index auxiliaires d'InnoDB font référence à la clé primaire comme champ de données. Par exemple, la figure suivante montre un index auxiliaire défini sur Col3 :
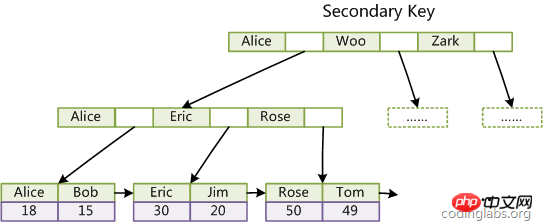
La table InnoDB est construite sur la base de l'index clusterisé . Par conséquent, l'index d'InnoDB peut fournir des performances de recherche de clé primaire très rapides. Cependant, son index auxiliaire (index secondaire, c'est-à-dire index de clé non primaire) contiendra également la colonne de clé primaire, donc si la clé primaire est définie de manière relativement grande, les autres index seront également grands. Si vous souhaitez définir plusieurs index sur la table, essayez de définir la clé primaire aussi petite que possible. InnoDB ne compresse pas les index.
Le code ASCII du caractère du texte est utilisé comme critère de comparaison. L'implémentation de l'index clusterisé rend la recherche par clé primaire très efficace, mais la recherche par index auxiliaire nécessite de récupérer l'index deux fois : d'abord, récupérer l'index auxiliaire pour obtenir la clé primaire, puis utiliser la clé primaire pour récupérer les enregistrements dans la clé primaire. indice.
Les méthodes d'implémentation d'index des différents moteurs de stockage sont très utiles pour l'utilisation correcte et l'optimisation des index. Par exemple, après avoir connu l'implémentation d'index d'InnoDB, il est facile de comprendre pourquoi elle n'est pas recommandée. pour utiliser des champs trop longs comme clés primaires, étant donné que tous les index secondaires font référence à l'index primaire, un index primaire trop long rendra l'index secondaire trop grand. Pour un autre exemple, utiliser des champs non monotones comme clés primaires n'est pas une bonne idée dans InnoDB car le fichier de données InnoDB lui-même est un B+Tree. Les clés primaires non monotones permettront au fichier de données de conserver les caractéristiques du B+Tree. lors de l'insertion de nouveaux enregistrements, les ajustements de fractionnement fréquents sont très inefficaces et l'utilisation de champs à incrémentation automatique comme clés primaires est un bon choix.
La différence entre l'index InnoDB et l'index MyISAM :
Tout d'abord, la différence entre l'index principal, le fichier de données InnoDB lui-même est le fichier d'index. L'index et les données de MyISAM sont séparés.
La deuxième différence est l'index auxiliaire : le champ de données d'index auxiliaire d'InnoDB stocke la valeur de la clé primaire de l'enregistrement correspondant au lieu de l'adresse. Il n'y a pas beaucoup de différence entre l'index secondaire de MyISAM et l'index primaire.
Analyse du principe de l'algorithme d'indexation MySQL (facile à comprendre, ne parlant que de B-tree)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 qu'est-ce que l'index
qu'est-ce que l'index
 L'index dépasse la solution des limites du tableau
L'index dépasse la solution des limites du tableau
 Le rôle de l'index
Le rôle de l'index
 Quels sont les types d'index Oracle ?
Quels sont les types d'index Oracle ?
 qu'est-ce qu'Internet.exe
qu'est-ce qu'Internet.exe
 Comment résoudre les problèmes lors de l'analyse des packages
Comment résoudre les problèmes lors de l'analyse des packages
 La différence entre Unix et Linux
La différence entre Unix et Linux
 Qu'est-ce qui est le plus difficile, le langage C ou Python ?
Qu'est-ce qui est le plus difficile, le langage C ou Python ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



