
 développement back-end
Tutoriel Python
Exemple détaillé de la façon dont python3 utilise le module de requêtes pour explorer le contenu de la page
développement back-end
Tutoriel Python
Exemple détaillé de la façon dont python3 utilise le module de requêtes pour explorer le contenu de la page
Exemple détaillé de la façon dont python3 utilise le module de requêtes pour explorer le contenu de la page

Cet article présente principalement la pratique réelle de l'utilisation de python3 pour explorer le contenu d'une page à l'aide du module de requêtes. Il a une certaine valeur de référence. Ceux qui sont intéressés peuvent en savoir plus
1. >
Mon système de bureau personnel utilise Linuxmint. Le système n'a pas installé pip par défaut étant donné que pip sera utilisé pour installer le module de requêtes plus tard, j'installerai pip comme première étape ici.$ sudo apt install python-pip
$ pip -V
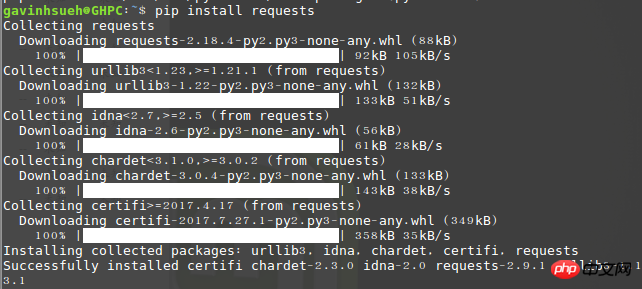
2. Demandes d'installation Module
Ici, je l'ai installé via pip :$ pip install requests

3. Installez beautifulsoup4
Beautiful Soup est un logiciel qui peut être téléchargé à partir de la bibliothèque HTML ou XML Python pour extraire les données des fichiers. Il permet une navigation habituelle dans les documents et des moyens de rechercher et de modifier des documents via votre convertisseur préféré. Beautiful Soup vous fera gagner des heures, voire des jours de travail.$ sudo apt-get install python3-bs4
$ sudo pip install beautifulsoup4
4.Une brève analyse du module de requêtes
1) Envoyer une requête Tout d'abord, bien sûr, importez le module Requêtes :>>> import requests
>>> r = requests.get('http://www.jb51.net/article/124421.htm')
>>> payload = {'newwindow': '1', 'q': 'python爬虫', 'oq': 'python爬虫'}
>>> r = requests.get("https://www.google.com/search", params=payload)>>> import requests
>>> r = requests.get('https://github.com/timeline.json')
>>> r.text>>> r = requests.get('http://www.cnblogs.com/') >>> r.encoding 'utf-8'
>>> r = requests.get('http://www.cnblogs.com/') >>> r.status_code 200
5. Démonstration de cas
L'entreprise vient d'introduire un système OA récemment, ici j'utilise le page de documentation officielle Prenez ceci comme exemple et capturez uniquement les informations utiles telles que les titres des articles et le contenu de la page. Environnement de démonstrationSystème d'exploitation : linuxmintVersion Python : python 3.5.2Utilisation des modules : requêtes, beautifulsoup4Code Comme suit :#!/usr/bin/env python
# -*- coding: utf-8 -*-
_author_ = 'GavinHsueh'
import requests
import bs4
#要抓取的目标页码地址
url = 'http://www.ranzhi.org/book/ranzhi/about-ranzhi-4.html'
#抓取页码内容,返回响应对象
response = requests.get(url)
#查看响应状态码
status_code = response.status_code
#使用BeautifulSoup解析代码,并锁定页码指定标签内容
content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml")
element = content.find_all(id='book')
print(status_code)
print(element)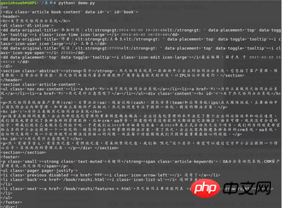
À propos du problème des résultats d'exploration tronqués
En fait, au début, j'utilisais directement le python2 fourni avec le système par défaut, mais j'ai longtemps eu du mal avec le problème de l'encodage tronqué du contenu renvoyé, j'ai recherché diverses solutions sur Google, mais toutes étaient inefficaces. Après avoir été "rendu fou" par python2, je n'ai eu d'autre choix que d'utiliser honnêtement python3. Concernant le problème du contenu tronqué dans les pages crawlées en python2, les seniors sont invités à partager leurs expériences pour aider les générations futures comme moi à éviter les détours.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



![Le module d'extension WLAN s'est arrêté [correctif]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif?x-oss-process=image/resize,m_fill,h_207,w_330) Le module d'extension WLAN s'est arrêté [correctif]
Feb 19, 2024 pm 02:18 PM
Le module d'extension WLAN s'est arrêté [correctif]
Feb 19, 2024 pm 02:18 PM
S'il y a un problème avec le module d'extension WLAN sur votre ordinateur Windows, cela peut entraîner une déconnexion d'Internet. Cette situation est souvent frustrante, mais heureusement, cet article propose quelques suggestions simples qui peuvent vous aider à résoudre ce problème et à rétablir le bon fonctionnement de votre connexion sans fil. Réparer le module d'extensibilité WLAN s'est arrêté Si le module d'extensibilité WLAN a cessé de fonctionner sur votre ordinateur Windows, suivez ces suggestions pour le réparer : Exécutez l'utilitaire de résolution des problèmes réseau et Internet pour désactiver et réactiver les connexions réseau sans fil Redémarrez le service de configuration automatique WLAN Modifier les options d'alimentation Modifier Paramètres d'alimentation avancés Réinstaller le pilote de la carte réseau Exécuter certaines commandes réseau Examinons-le maintenant en détail
 Le module d'extensibilité WLAN ne peut pas démarrer
Feb 19, 2024 pm 05:09 PM
Le module d'extensibilité WLAN ne peut pas démarrer
Feb 19, 2024 pm 05:09 PM
Cet article détaille les méthodes permettant de résoudre l'événement ID10000, qui indique que le module d'extension LAN sans fil ne peut pas démarrer. Cette erreur peut apparaître dans le journal des événements du PC Windows 11/10. Le module d'extensibilité WLAN est un composant de Windows qui permet aux fournisseurs de matériel indépendants (IHV) et aux fournisseurs de logiciels indépendants (ISV) de fournir aux utilisateurs des fonctionnalités de réseau sans fil personnalisées. Il étend les fonctionnalités des composants réseau Windows natifs en ajoutant la fonctionnalité par défaut de Windows. Le module d'extensibilité WLAN est démarré dans le cadre de l'initialisation lorsque le système d'exploitation charge les composants réseau. Si le module d'extension LAN sans fil rencontre un problème et ne peut pas démarrer, vous pouvez voir un message d'erreur dans le journal de l'Observateur d'événements.
 Comment réaliser la conversion mutuelle entre les requêtes CURL et python en python
May 03, 2023 pm 12:49 PM
Comment réaliser la conversion mutuelle entre les requêtes CURL et python en python
May 03, 2023 pm 12:49 PM
curl et Pythonrequests sont des outils puissants pour envoyer des requêtes HTTP. Alors que curl est un outil de ligne de commande qui vous permet d'envoyer des requêtes directement depuis le terminal, la bibliothèque de requêtes de Python fournit un moyen plus programmatique d'envoyer des requêtes à partir du code Python. La syntaxe de base pour convertir curl en commande Pythonrequestscurl est la suivante : curl[OPTIONS]URL Lors de la conversion de la commande curl en requête Python, nous devons convertir les options et l'URL en code Python. Voici un exemple de commande curlPOST : curl-XPOST https://example.com/api
 Comment utiliser la bibliothèque de requêtes du robot Python
May 16, 2023 am 11:46 AM
Comment utiliser la bibliothèque de requêtes du robot Python
May 16, 2023 am 11:46 AM
1. Installez la bibliothèque de requêtes. Étant donné que le processus d'apprentissage utilise le langage Python, Python doit être installé à l'avance. J'ai installé Python 3.8. Vous pouvez vérifier la version de Python que vous avez installée en exécutant la commande python --version. pour installer Python 3.X ou supérieur. Après avoir installé Python, vous pouvez installer directement la bibliothèque de requêtes via la commande suivante. pipinstallrequestsPs : Vous pouvez passer aux sources pip nationales, telles que Alibaba et Douban, qui sont rapides. Afin de démontrer la fonction, j'ai utilisé nginx pour simuler un site Web simple. Après le téléchargement, exécutez simplement le programme nginx.exe dans le répertoire racine.
 Python bibliothèques standard couramment utilisées et bibliothèques tierces module 2-sys
Apr 10, 2023 pm 02:56 PM
Python bibliothèques standard couramment utilisées et bibliothèques tierces module 2-sys
Apr 10, 2023 pm 02:56 PM
1. Introduction au module sys Le module os présenté précédemment est principalement destiné au système d'exploitation, tandis que le module sys de cet article est principalement destiné à l'interpréteur Python. Le module sys est un module fourni avec Python. C'est une interface permettant d'interagir avec l'interpréteur Python. Le module sys fournit de nombreuses fonctions et variables pour gérer différentes parties de l'environnement d'exécution Python. 2. Méthodes couramment utilisées du module sys Vous pouvez vérifier quelles méthodes sont incluses dans le module sys via la méthode dir() : import sys print(dir(sys))1.sys.argv-get les paramètres de ligne de commande sys. argv est utilisé pour implémenter la commande depuis l'extérieur du programme. Le programme reçoit des paramètres et il est capable d'obtenir la colonne des paramètres de la ligne de commande.
 Programmation Python : explication détaillée des points clés de l'utilisation de tuples nommés
Apr 11, 2023 pm 09:22 PM
Programmation Python : explication détaillée des points clés de l'utilisation de tuples nommés
Apr 11, 2023 pm 09:22 PM
Préface Cet article continue de présenter le module de collection Python. Cette fois, il y introduit principalement les tuples nommés, c'est-à-dire l'utilisation de nommétuple. Sans plus tarder, commençons – n'oubliez pas d'aimer, de suivre et de transmettre ~ ^_^Création de tuples nommés La classe de tuple nommé nomméeTuples dans la collection Python donne un sens à chaque position dans le tuple et améliore la lisibilité du code sexuel et descriptif. Ils peuvent être utilisés partout où des tuples réguliers sont utilisés et ajoutent la possibilité d'accéder aux champs par nom plutôt que par index de position. Il provient des collections de modules intégrés Python. La syntaxe générale utilisée est : importer des collections XxNamedT
 Comment Python utilise les requêtes pour demander des pages Web
Apr 25, 2023 am 09:29 AM
Comment Python utilise les requêtes pour demander des pages Web
Apr 25, 2023 am 09:29 AM
Requests hérite de toutes les fonctionnalités de urllib2. Les requêtes prennent en charge la persistance des connexions HTTP et le regroupement de connexions, prennent en charge l'utilisation de cookies pour maintenir les sessions, prennent en charge le téléchargement de fichiers, prennent en charge la détermination automatique du codage du contenu de la réponse et prennent en charge les URL internationalisées et le codage automatique des données POST. La méthode d'installation utilise pip pour installer la requête $pipinstallrequestsGET Requête GET de base (paramètres d'en-tête et paramètres parmas) 1. La requête GET la plus basique peut utiliser directement la méthode get 'response=requests.get("http://www.baidu.com/ "
 Comment fonctionne l'importation de Python ?
May 15, 2023 pm 08:13 PM
Comment fonctionne l'importation de Python ?
May 15, 2023 pm 08:13 PM
Bonjour, je m'appelle somenzz, vous pouvez m'appeler frère Zheng. L'importation de Python est très intuitive, mais même ainsi, vous constaterez parfois que même si le package est là, nous rencontrerons toujours ModuleNotFoundError. Le chemin relatif est évidemment très correct, mais l'erreur ImportError:tentativerelativeimportwithnoknownparentpackage importe un module dans le même répertoire et. un différent. Les modules du répertoire sont complètement différents. Cet article vous aide à gérer facilement l'import en analysant certains problèmes souvent rencontrés lors de l'utilisation de l'import. Sur cette base, vous pouvez facilement créer des attributs.
