
1》Créer une base de données :
Syntaxe : créer le nom de la base de données ;
Syntaxe : afficher les bases de données Afficher les bases de données existantes
Exemple :
Mysql->create database zytest; 注意每一条要以;号结尾 Mysql->show databases;查询是否创建成功 >use zytest;
🎜>2》Supprimer la base de données : 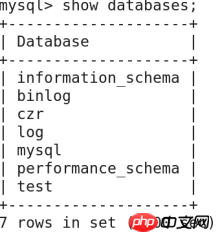 Syntaxe : supprimer le nom de la base de données ;
Syntaxe : supprimer le nom de la base de données ;
Mysql->drop database zytest; Supprimer zytest
Mysql- >afficher les bases de données ;
3> Introduction réussie du moteur de stockage :
1>moteur innoDB
innoDB est le premier moteur de table à fournir des contraintes de clé étrangère et a la capacité de gérer des transactions avec innoDB. C’est aussi quelque chose avec lequel les autres moteurs ne peuvent pas rivaliser. ,  Innodb prend en charge les colonnes à incrémentation automatique à l'aide de auto_increment. La valeur de la colonne à incrémentation automatique ne peut pas être vide
Innodb prend en charge les colonnes à incrémentation automatique à l'aide de auto_increment. La valeur de la colonne à incrémentation automatique ne peut pas être vide
Dans le moteur de stockage innodb, créez une table. La structure de la table est stockée dans le fichier .frm, et les données et index sont stockés dans l'espace table défini par innodb_data_home_dir et innodb_data_file_path. Par défaut, il se trouve sous le datadir. Les métadonnées de chaque table de données dans InnoDB sont toujours stockées dans l'espace table partagé d'ibdata1, ce fichier est donc essentiel
innodb_data_file_path = ibdata1:10M:autoextend
Les fichiers de données et d'index sont rassemblés : *.ibd Chaque table a des métadonnées distinctes,
Métadonnées totales de toutes les tables Le fichier est ibdata1 Moteur de stockage Inoodb Avantages : il offre une bonne gestion des transactions, des capacités de crash, de réparation et un contrôle de concurrence, Inconvénients : son efficacité de lecture et d'écriture est légèrement médiocre et l'espace de données qu'il occupe est relativement petit. Grand.
Qu'est-ce qu'une transaction ? ? Jetons d'abord un coup d'œil aux principes ACID
ACID sont les quatre éléments de base pour l'exécution normale des transactions de base de données, qui font référence à l'atomicité, à la cohérence, à l'indépendance et à la durabilité
L'atomicité d'une transaction signifie qu'une transaction est soit entièrement exécutée, soit non exécutée. En d'autres termes, une transaction ne peut pas être exécutée seulement à moitié puis s'arrêter. Par exemple, si vous retirez de l'argent à un guichet automatique, cela. La transaction peut être divisée en deux étapes : 1. glisser la carte, 2. retirer de l'argent. Il est impossible de glisser la carte mais l'argent ne sort pas. Ces deux étapes doivent être complétées en même temps. terminé. 🎜> :La cohérence de la transaction signifie que l'exécution de la transaction ne modifie pas la cohérence des données dans la base de données. Par exemple, la contrainte d'intégrité a+b=10, si une transaction modifie a, alors b devrait le faire. changent également en conséquence. Isolement 2>Moteur MyISAM Inconvénients : Manque de stabilité et d'intégrité Fournit des verrous de ligne (verrouillage au niveau de la ligne) De plus, les verrous de ligne des tables InnoDB ne sont pas absolus If MySQL If. la plage à analyser ne peut pas être déterminée, la table InnoDB verrouillera également la table entière 🎜> 1) Réduisez l'état LOCK lorsque de nombreuses connexions effectuent des requêtes différentes. 2) Si une exception se produit, la perte de données peut être réduite. Parce que vous ne pouvez restaurer qu'une ou quelques lignes de petites quantités de données à la fois. Les inconvénients des verrous au niveau des lignes sont les suivants : 1) Cela prend plus de mémoire que les verrous au niveau de la page et les verrous au niveau de la table. 2) Les requêtes nécessitent plus d'E/S que les verrous au niveau de la page et les verrous au niveau de la table, nous utilisons donc souvent des verrous au niveau de la ligne pour les opérations d'écriture plutôt que pour les opérations de lecture. 3) Une impasse est susceptible de se produire. Remarque : inodb ne peut pas déterminer la ligne de l'opération. À ce stade, le verrouillage d'intention est utilisé, c'est-à-dire le verrouillage de la table au niveau de la ligne 3>查询Mysql默认存储引擎 如果想修改存储引擎,可以在 my.ini中进行修改或者my.cnf中的Default-storage-engine=引擎类型; 5》如何选择存储引擎: 在企业生产环境中,选择一个款合适的存储引擎是一个很复杂的问题。每一种存储引擎都有各自的优势,不能笼统的说,谁比谁好。通常用的比较多的 是innodb存储引擎 ==========================创建,修改,删除表: 1》创建表的方法: 2》表的完整性约束: | 约束条件 | 说明| | (1)primary key | 标识该字段为表的主键,具备唯一性| | (2)foreign key | 标识该字段为表的外键,与某表的主键联系| | (3)not null | 标识该属于的值不能为空| | (4)unique | 标识这个属性值是唯一| | (5)auto_increment | 标识该属性值的自动增加 | (6)default | 为该属性值设置默认值| 1>设置表的主键: 举例: 2>设置多个字段做主键 3>设置表的外键: (1) yy1表存储了zhangsan姓名和ID号 (2) yy2表存储了ID号和zhangsan的年龄(old) (3)数据填充yy1和yy2表 (4)更新测试: (5)删除测试: 4>设置表的非空值 5> 设置表的唯一性约束 6>设置表的属性值自动增加 7>、设置表的默认值 插入数据,应为ID为自增,值为空,user_name设置了默认值,所以也为空。 3》查看表结构的方法: 2>修改表的数据类型 3>修改表的字段名称 4>修改增加字段 v 增加没有约束条件的字段: v 增加有完整约束条件的字段 v 在表的第一个位置增加字段默认情况每次增加的字段。都在表的最后。 v 执行在那个位置插入新的字段,在phone后面增加 总结: 6>更改表的存储引擎 7>删除表的外键约束 4》删除表的方法 1>删除没有被关联的普通表 Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
:L'indépendance d'une transaction est également appelée isolement, ce qui signifie que deux transactions ou plus ne entrelaceront le statut d'exécution. . Parce que cela peut conduire à une incohérence des données.
Durabilité (Durabilité) :La durabilité d'une transaction fait référence aux modifications apportées par la transaction à la base de données une fois la transaction réussie. Les modifications exécutées sont enregistrées de manière permanente dans la base de données et ne seront pas annulées sans raison
.
La table de stockage MyISAM est divisée en 3 fichiers. Les noms de fichiers et de tables sont les mêmes, et les extensions incluent frm, MYD et MYI
La structure de la table de stockage de fichiers où. frm est l'extension
myd Stocke les données pour les fichiers avec des extensions
Myi stocke les index pour les fichiers avec des extensions
Avantages : Petit espace occupé. Vitesse de traitement rapide,
Inconvénients : Ne prend pas en charge l'intégrité et la concurrence des journaux de transactions 3>Moteur MEMORY Le moteur spécial de Mysql, toutes les données sont stockées dans la mémoire, dans l'environnement de production de l'entreprise. Presque inutile. Parce que les données sont stockées en mémoire, s'il y a une exception dans la mémoire. Cela affectera l’intégrité des données. Avantages : Stockage rapide
MyISAM : ne prend pas en charge les clés étrangères, ne prend pas en charge les transactions, les index et les données sont séparés et d'autres peuvent être chargés Index, et l'index est compressé, l'efficacité d'utilisation est bien améliorée par rapport à la mémoire. Il utilise un mécanisme de verrouillage de table pour optimiser plusieurs opérations de lecture et d'écriture simultanées
Occasion d'utilisation : dans une plate-forme de projet ; héberge la plupart des projets qui lisent plus et écrivent moins, les performances de lecture de MyISAM sont bien meilleures que celles d'Innodb
Innodb : prend en charge les clés étrangères, prend en charge les transactions et la restauration, mais l'index et les données sont étroitement lié et aucune compression n'est utilisée, ce qui rendra INNODB beaucoup plus grand que MYISAM.
Occasions d'utilisation : Si vous souhaitez effectuer une insertion et une mise à jour sur la plupart des projets hébergés, vous devez choisir InnoDB.
Introduction aux verrous : il existe trois niveaux de verrouillage courants dans MySQL : les verrous au niveau de la table, les verrous de page et les verrous au niveau de la ligne ; de verrous au niveau de la table – Verrou de lecture partagé de table et verrou d'écriture exclusif de table.
MyISAM :
verrouillage au niveau de la table : Lors de l'exécution d'une opération de lecture sur la table myisam, cela ne bloquera pas les demandes de lecture des autres utilisateurs pour la même table, mais il bloquera les opérations d'écriture sur la même table>; cela bloquera les demandes de lecture et d'écriture des autres utilisateurs sur la même table.
innodb :
.
4》Afficher le moteur de stockage : Le moteur de stockage est une fonctionnalité de Mysql. Mysql peut choisir plusieurs moteurs de stockage. et différentes méthodes de stockage. S'il faut effectuer le traitement des transactions, etc. ;
1> Interroger les moteurs pris en charge par Mysql > 🎜>
2> Interroger les détails du moteur Mysql : Mysql->show engine innodb status\G;
Mysql-> show variables like 'storage_engine';

以下是存储引擎的对比: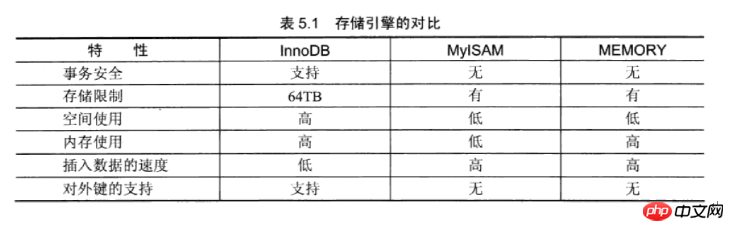
语法:create table 表名(
属性名数据类型完整约束条件,
属性名数据类型条完整约束件,
。。。。。。。。。
属性名数据类型
);
举例: create table example0(
id int,
name varchar(20),
sexboolean);
主键是一个表的特殊字段,这个字段是唯一标识表中的每条信息,主键和记录的关系,跟人的身份证一样。名字可以一样,但是身份证号码觉得不会一样, 主键用来标识每个记录,每个记录的主键值都不同,主键可以帮助Mysql以最快的速度查找到表中的某一条信息,主键必须满足的条件那就是它的唯一性,表中的 任意两条记录的主键值,不能相同,否则就会出现主键值冲突,主键值不能为空,可以是单一的字段,也可以多个字段的组合。 create table sxkj(
User_id int primary key,
user_name varchar(20),
user_sexchar(7));
举例: create table sxkj2(
user_id int ,
user_name float,
grade float,
primary key(user_id,user_name));
外键是表的一个特殊字段,如果aa是B表的一个属性且依赖于A表的主键,那么A表被称为父表。B表为被称为子表,
举例说明:
user_id 是A 表的主键,aa 是B表的外键,那么user_id的值为zhangsan,如果这个zhangsan离职了,需要从A表中删除,那么B表关于 zhangsan的信息也该得到相应的删除,这样可以保证信息的完整性。
语法:
constraint外键别名 foreign key(外键字段1,外键字段2)
references 表名(关联的主键字段1,主键字段2)
create table yy1(
user_id int primary key not null,
user_name varchar(20));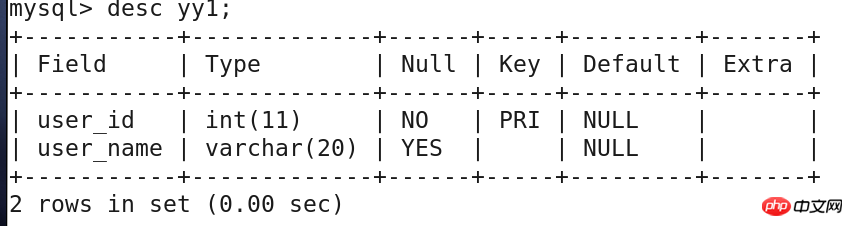
create table yy2(
user_id int primary key not null,
old int(5),
constraint y_fk foreign key(user_id)
references yy1(user_id)on delete cascade on update cascade);
insert into yy1 values('110','zhangsan');
insert into yy2 values('110','30');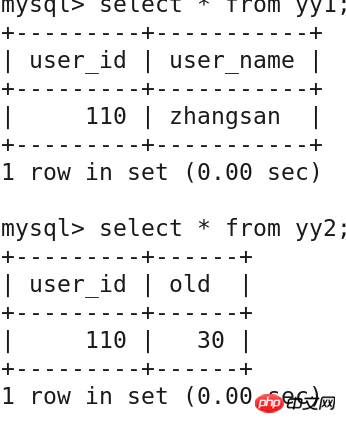
update yy1 set user_id='120' where user_name='zhangsan';
查询验证
select * from yy2;
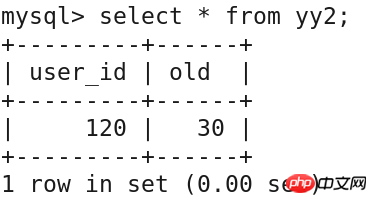
delete from yy1 where user_id='120';
查询验证
select * from yy2;

语法:属性名数据类型 NOT NULL
举例: create table C(
user_id int NOT NULL);
唯一性指的就是所有记录中该字段。不能重复出现。
语法:属性名数据类型 unique
举例: root@zytest 15:43>create table D(
->user_id int unique);
root@zytest 15:44>show create table D;
Auto_increment 是Mysql数据库中特殊的约束条件,它的作用是向表中插入数据时自动生成唯一的ID,一个表只能有一个字段使用 auto_increment 约束,必须是唯一的;
语法:属性名数据类型 auto_increment,默认该字段的值从1开始自增。
举例:
create table F( user_id int primary key auto_increment);
root@zytest 15:56>insert into F values();插入一条空的信息
Query OK, 1 row affected, 1 warning (0.00 sec)
root@zytest 15:56>select * from F;值自动从1开始自增
+---------+
| user_id |
+---------+
| 1 |
+---------+
1 row in set (0.01 sec)
在创建表时,可以指定表中的字段的默认值,如果插入一条新的纪录时,没有给这个字段赋值,那么数据库会自动的给这个字段插入一个默认 值,字段的默认值用default来设置。
语法: 属性名数据类型 default 默认值
举例: root@zytest 16:05>create table G(
user_id int primary key auto_increment,
user_name varchar(20) default 'zero');
root@zytest 16:05>insert into G values('','');
DESCRIBE可以查看那表的基本定义,包括、字段名称,字段的数据类型,是否为主键以及默认值等。。
(1)语法:describe 表名;可以缩写为desc
(2) show create table查询表详细的结构语句,
1>修改表名
语法:alter table 旧表名 rename 新表名;
举例; root@zytest 16:11>alter table A rename zyA;
Query OK, 0 rows affected (0.02 sec)
语法:alter table 表名 modify 属性名 数据类型;
举例; root@zytest 16:15>alter table A modify user_name double;
Query OK, 0 rows affected (0.18 sec)
语法: alter table 表名 change 旧属性名 新属性名 新数据类型; root@zytest 16:15>alter table A change user_name user_zyname float;
Query OK, 0 rows affected (0.10 sec) alter table 表名 ADD 属性名1 数据类型 [完整性约束条件] [FIRST |AFTER 属性名2]
root@zytest 16:18>alter table A add phone varchar(20);
Query OK, 0 rows affected (0.13 sec)root@zytest 16:42>alter table A add age int(4) not null;
Query OK, 0 rows affected (0.13 sec)root@zytest 16:45>alter table tt add num int(8) primary key first;
Query OK, 1 row affected (0.12 sec)
Records: 1 Duplicates: 0 Warnings: 0 root@zytest 16:46>alter table A add address varchar(30) not null after phone;
Query OK, 0 rows affected (0.10 sec)
Records: 0 Duplicates: 0 Warnings: 0
(1) 默认ADD 增加字段是在最后面增加
(2) 如果想在表的最前端增加字段用first关键字
(3) 如果想在某一个字段后面增加的新的字段,使用after关键字
5>删除一个字段
alter table 表名DROP 属性名;
举例: 删除A 表的age字段 root@zytest 16:51>alter table A drop age;
Query OK, 0 rows affected (0.11 sec)
Records: 0 Duplicates: 0 Warnings: 0 alter table表名 engine=存储引擎
alter table A engine=MyISAM; alter table 表名drop foreign key 外键别名;
alter table yy2 drop foreign key y_fk;
drop table 表名;
2>删除被其它表关联的父表
在数据库中某些表之间建立了一些关联关系。一些成为了父表,被其子表关联,要删除这些父表,就不是那么简单了。删除方法,先删除所关联的 子表的外键,在删除主表。
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



