

J'apprends python3 récemment. L'article suivant vous présente principalement les informations pertinentes sur le robot d'exploration pratique Python3 pour explorer les images du livre de Jingdong. L'article le présente en détail à travers un exemple de code, qui sera une certaine référence pour l'étude ou le travail de chacun. . La valeur de l'apprentissage, les amis qui en ont besoin, venez jeter un œil ci-dessous.
Avant-propos
J'ai récemment rencontré un besoin au travail. J'ai besoin de télécharger des photos de livres sur JD.com. livres sur JD.com Télécharger localement toutes les images de la catégorie de produits, les copier et les coller manuellement sera un projet très énorme. À l'heure actuelle, il peut être implémenté avec un robot d'exploration Web Python. Ce type de robot d'exploration est appelé robot d'exploration d'images. Ensuite, nous implémenterons le robot d'exploration .
Implémenter l'analyse
Tout d'abord, ouvrez la première page Web à explorer. Cette page Web sera utilisée comme page de départ à explorer. . Nous ouvrons JD.com et sélectionnons la catégorie de livre Comme il existe de nombreux livres de tous types, nous choisissons d'explorer les images de livres de tous les langages de programmation. =1713, 3287,3797&page=1&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main
Comme le montre l'image :
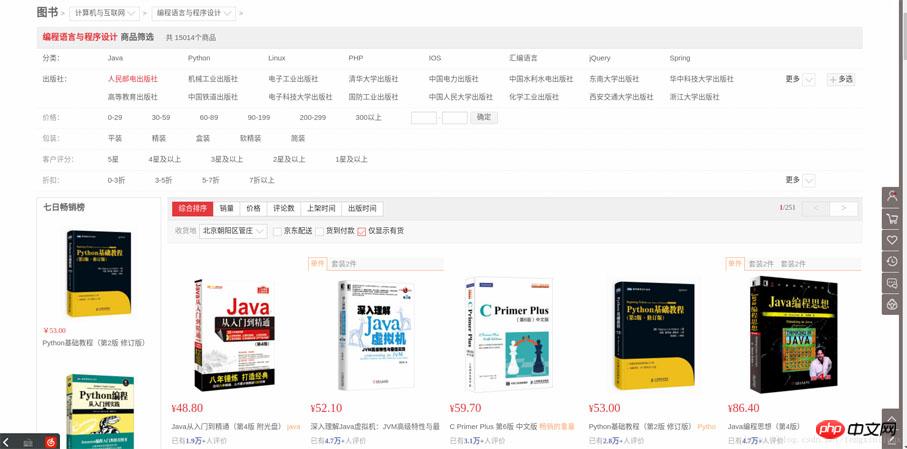
Après être entré, nous trouverons un total de 251 pages.
Alors, comment pouvons-nous explorer automatiquement d'autres pages en plus de la première page ?
Vous pouvez cliquer sur "Page suivante" pour observer les changements dans l'URL. Après avoir cliqué sur la page suivante, j'ai constaté que l'URL était devenue https://list.jd.com/list.html?cat=1713,3287,3797&page=2&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main.
Nous pouvons constater que la page à obtenir ici est identifiée par l'URL, c'est-à-dire demandée via GET. Dans cette requête GET, il y a plusieurs champs, dont l'un est page, avec une valeur correspondante de 2. À partir de là, nous pouvons obtenir les informations clés dans l'URL : https://list.jd.com/list.html ? cat=1713,3287,3797&page=2. Ensuite, sur la base de spéculations, nous avons changé page=2 en page=6 et avons constaté que nous pouvions accéder avec succès à la page 6.
À partir de là, nous pouvons penser à un moyen d'obtenir automatiquement plusieurs pages : cela peut être implémenté à l'aide d'une boucle for. Après chaque boucle, le champ de la page dans l'URL correspondante est augmenté de 1, ce qui est augmenté de 1. signifie qu'il passe automatiquement à la page suivante.
Dans chaque page, nous devons extraire l'image correspondante. Nous pouvons utiliser des expressions régulières pour faire correspondre la partie lien de l'image dans le code source, puis enregistrer l'image liée correspondante via urllib.request. .urlretrieve() en local.
Mais il y a un problème ici. Les images de cette page Web incluent non seulement les images des produits dans la liste, mais incluent également des images non pertinentes à côté d'eux, afin que nous puissions effectuer une information. filtrage en premier. Le premier filtrage des informations Laissez les données dans la liste de produits au milieu et filtrez les données dans les autres parties. Vous pouvez cliquer avec le bouton droit et afficher le code source de la page Web, comme indiqué dans l'image :
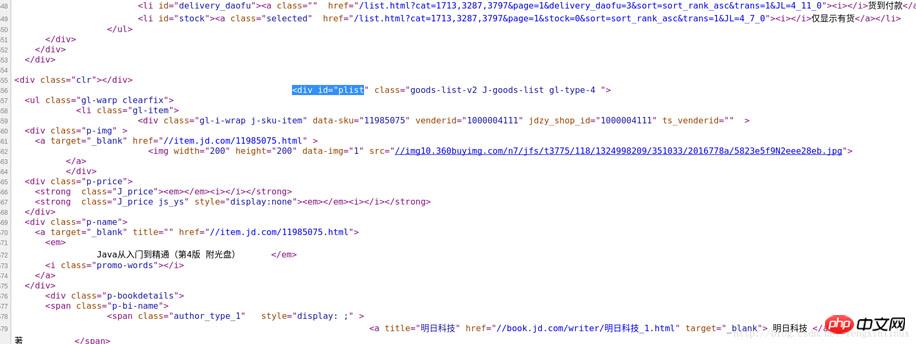
Vous pouvez parcourir rapidement le premier produit de la liste de produits appelé " JAVA du débutant au maître" Localisez la position correspondante dans le code source, puis observez le logo spécial dans la partie liste des produits. Vous pouvez voir qu'il y a un code "
Alors, d'où vient la valeur valide. fin de l'information ?
De même, nous passons dans le code source Trouvez le dernier livre de la liste de produits sur cette page, localisons rapidement l'emplacement du code source et analysons-le. un tel code comme identifiant, comme le montre la figure :
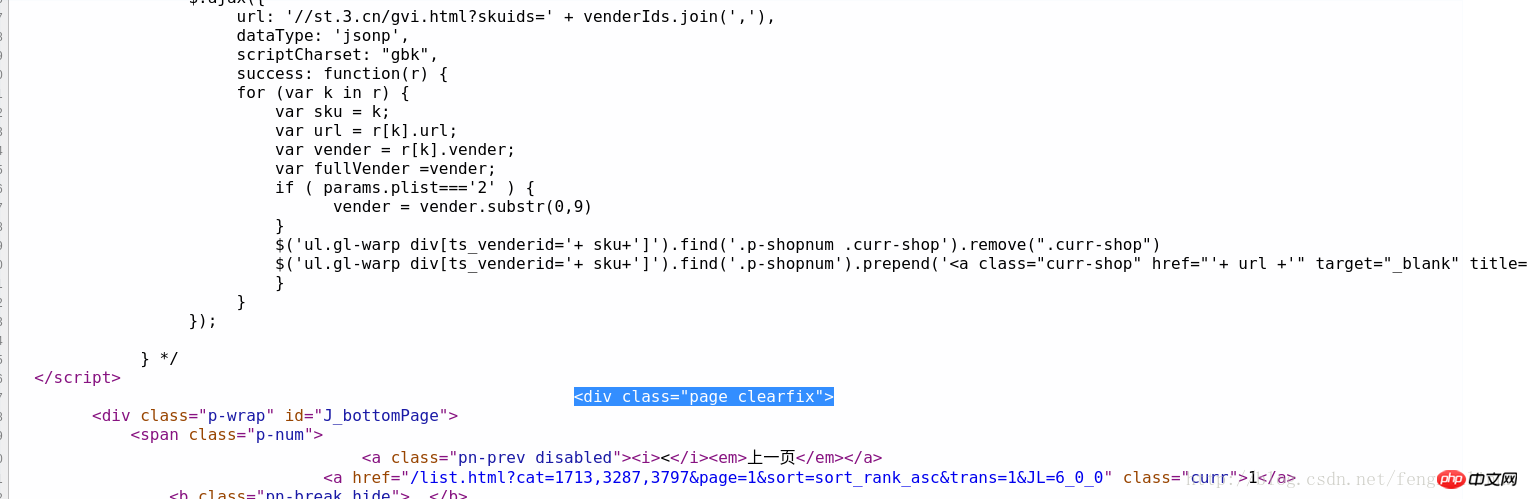
Donc, si nous voulons effectuer le premier filtrage, notre expression régulière peut être construite comme :
<p id="plist".+? <p class="page clearfix">
Après le premier filtrage des informations, les liens d'image restants C'est l'image que nous voulons explorer. L'étape suivante consiste à filtrer les informations de lien d'image en fonction du premier filtrage. .
À ce stade, nous devons observer le code source de l'image correspondante dans la page Web, nous avons observé le code source correspondant de deux des images :
Image. 1 :
<img width="200" height="200" data-img="1" src="//img13.360buyimg.com/n7/jfs/t6130/167/771989293/235186/608d0264/592bf167Naf49f7f6.jpg">
Image 2 :
<img width="200" height="200" data-img="1" src="//img10.360buyimg.com/n7/g14/M03/0E/0D/rBEhV1Im1n8IAAAAAAcHltD_3_8AAC0FgC-1WoABweu831.jpg">
Comparaison des deux codes d'image, nous avons constaté que le format de base est le même, mais l'URL du lien de l'image est différente, donc à ce moment, nous construisons l'image extraite basée sur cette règle Expression régulière pour les liens :
<img width="200" height="200" data-img="1" src="//(.+?\.jpg)">
刚开始到这里,我以为就结束了,后来在爬取的过程中我发现每一页都少爬取了很多图片,再次查看源码发现,每页后面的几十张图片又是另一种格式:
<img width="200" height="200" data-img="1" src-img="//img10.360buyimg.com/n7/jfs/t3226/230/618950227/110172/7749a8bc/57bb23ebNfe011bfe.jpg">
所以,完整的正则表达式应该是这两种格式的或:
<img width="200" height="200" data-img="1" src="//(.+?\.jpg)">|
到这里,我们根据该正则表达式,就可以提取出一个页面中所有想要爬取的图片链接。
所以,根据上面的分析,我们可以得到该爬虫的编写思路与过程,具体如下:
建立一个爬取图片的自定义函数,该函数负责爬取一个页面下的我们想爬取的图片,爬取过程为:首先通过urllib.request.utlopen(url).read()读取对应网页的全部源代码,然后根据上面的第一个正则表达式进行第一次信息过滤,过滤完成之后,在第一次过滤结果的基础上,根据上面的第二个正则表达式进行第二次信息过滤,提取出该网页上所有的目标图片的链接,并将这些链接地址存储的一个列表中,随后遍历该列表,分别将对应链接通过urllib.request.urlretrieve(imageurl,filename=imagename)存储到本地,为了避免程序中途异常崩溃,我们可以建立异常处理。
通过for循环将该分类下的所有网页都爬取一遍,链接可以构造为url='https://list.jd.com/list.html?cat=1713,3287,3797&page=' + str(i)
完整的代码如下:
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import re import urllib.request import urllib.error import urllib.parse sum = 0 def craw(url,page): html1=urllib.request.urlopen(url).read() html1=str(html1) pat1=r'<p id="plist".+? <p class="page clearfix">' result1=re.compile(pat1).findall(html1) result1=result1[0] pat2=r'<img width="200" height="200" data-img="1" src="//(.+?\.jpg)">|' imagelist=re.compile(pat2).findall(result1) x=1 global sum for imageurl in imagelist: imagename='./books/'+str(page)+':'+str(x)+'.jpg' if imageurl[0]!='': imageurl='http://'+imageurl[0] else: imageurl='http://'+imageurl[1] print('开始爬取第%d页第%d张图片'%(page,x)) try: urllib.request.urlretrieve(imageurl,filename=imagename) except urllib.error.URLError as e: if hasattr(e,'code') or hasattr(e,'reason'): x+=1 print('成功保存第%d页第%d张图片'%(page,x)) x+=1 sum+=1 for i in range(1,251): url='https://list.jd.com/list.html?cat=1713,3287,3797&page='+str(i) craw(url,i) print('爬取图片结束,成功保存%d张图'%sum)
运行结果如下:
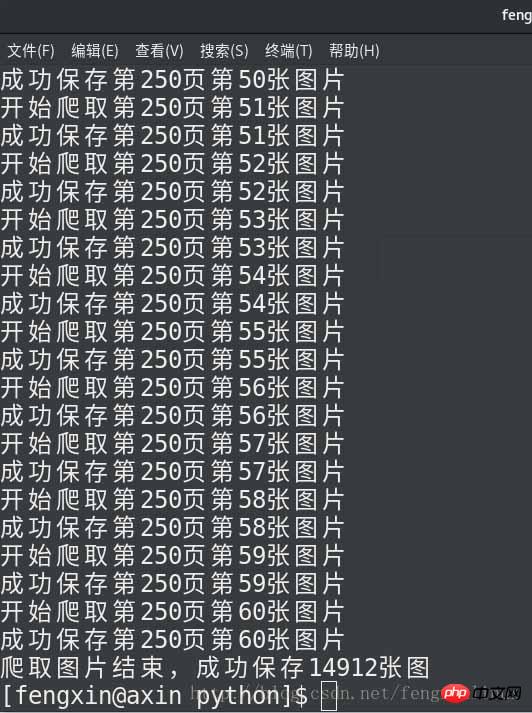
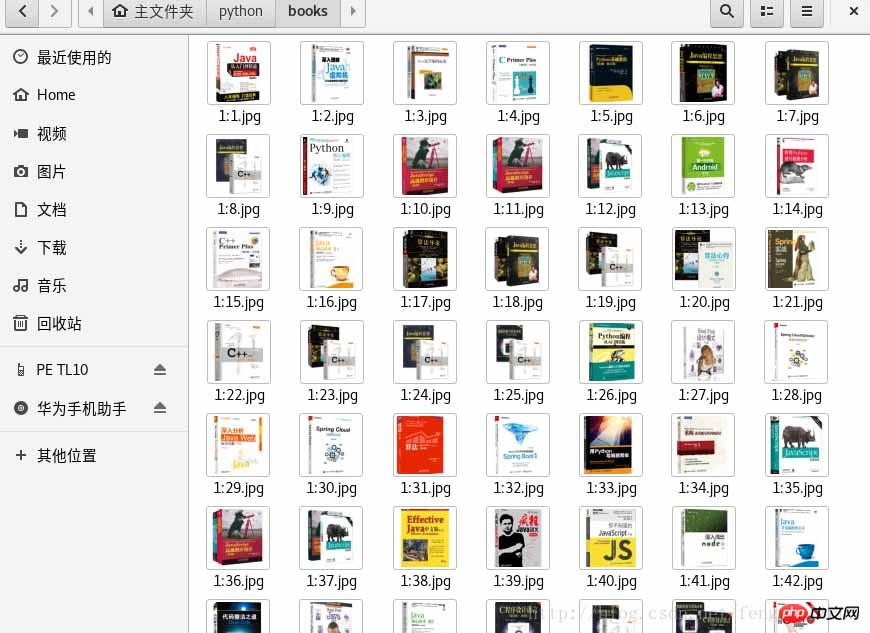
总结
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Introduction aux commandes CLI
Introduction aux commandes CLI
 Logiciel d'évaluation de serveur
Logiciel d'évaluation de serveur
 Quelle est la différence entre ibatis et mybatis
Quelle est la différence entre ibatis et mybatis
 Comment activer la même fonction de ville sur Douyin
Comment activer la même fonction de ville sur Douyin
 Quels sont les systèmes de correction d'erreurs de noms de domaine ?
Quels sont les systèmes de correction d'erreurs de noms de domaine ?
 La différence entre l'API de repos et l'API
La différence entre l'API de repos et l'API
 Méthode de récupération de données informatiques Xiaomi
Méthode de récupération de données informatiques Xiaomi
 Que dois-je faire si la souris ne bouge plus ?
Que dois-je faire si la souris ne bouge plus ?
 Comment fermer le port 445 sous XP
Comment fermer le port 445 sous XP








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



