

Quelle est la cause fondamentale des pages Web tronquées ?
先看段代码:
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>网页编码</title> </head> <body> </body> </html>
HTML代码中的 指定了网页的编码为utf-8。
网页编码涉及的知识点比较多,总的说来它也是一个历史遗留问题。
第一台计算机(ENIAC)于1946年2月诞生于美国,当时美国只考虑自己使用,并在计算机诞生后的几年里制定了一套ASCII码标准(American Standard Code for Information Interchange,美国信息交换标准代码),它是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
ASCII码使用8位二进制数组合来表示256种可能的字符(2的8次方=256),包含了大小写字母,数字0到9,标点符号,以及在美式英语中使用的特殊控制字符。一个字符占1个字节。ASCII码表部分编码如下:
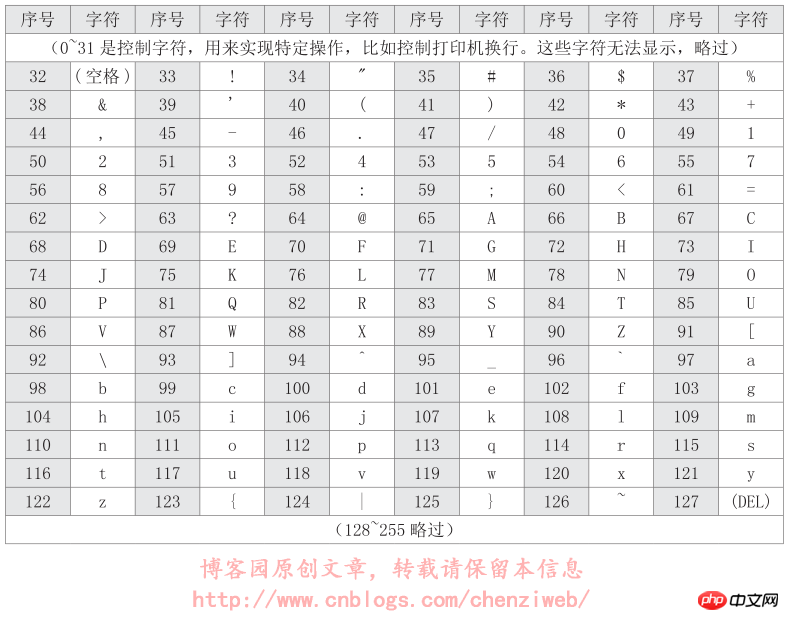
HTML的转义符(字符实体),比如符号“<”的转义符为“<”或“<”,其中的数字编号“60”即是ASCII码表的第60序号。类似的,大写字母“K”也可以转义为“K”。
我们使用转义符做个试验: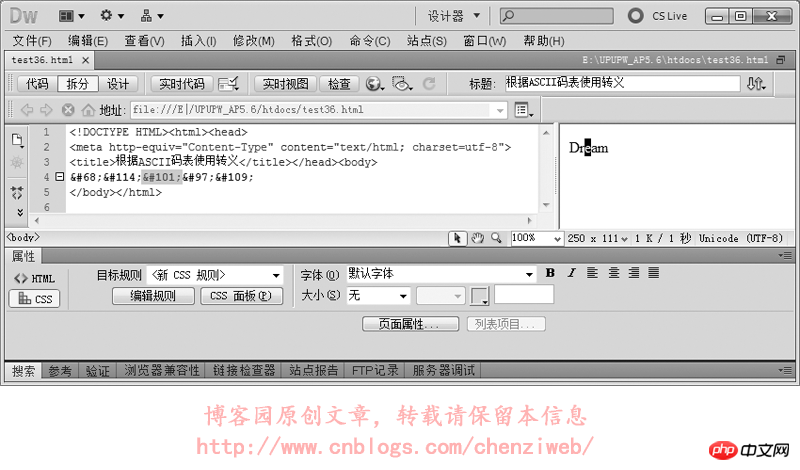
美国制定ASCII码的意思是:ASCII码可以满足在计算机领域所有字符和表示上的需要。不过这只是美国自己的意思,毕竟所有的英文单词都可以拆分来自26个英文字母,ASCII码表能表达256个字符,确实足够美国使用。
后来世界各地也都开始使用计算机,很多国家的语言文字并不是英文,这些国家的文字都没被包含在ASCII码表里。以我们中国为例,汉字近10万个,根本无法排进ASCII码表。于是我们国家对ASCII码表进行拓展并形成自己的的一套标准,在标准中一个汉字占2个字节,新的码表可以表达65536个汉字。但一开始并没有将码表全部填充使用完,只收录了常用的6000多个汉字、英文及其它符号,这套标准称为GB2312(信息交换用汉字编码字符集,GB是“国家标准”的简化词“国标”的拼音首字母缩写,2312是国标序号)。后来又制定了一套收录更多汉字的标准(收录的汉字有2万多个),称为GBK(汉字编码扩展规范,K是“扩”的拼音首字母)。
在GB2312或GBK里,许多标点符号都使用2个字节进行了重新编码,这类占2个字节的标点符号称为“全角”字符(“全角”也称“全形”或“全宽”或“全码”),原来ASCII码表中占1个字节的标点符号则称为“半角”字符(“半角”也称“半形”或“半宽”或“半码”)。全角的逗号、括号、句号等与半角是不一样的:
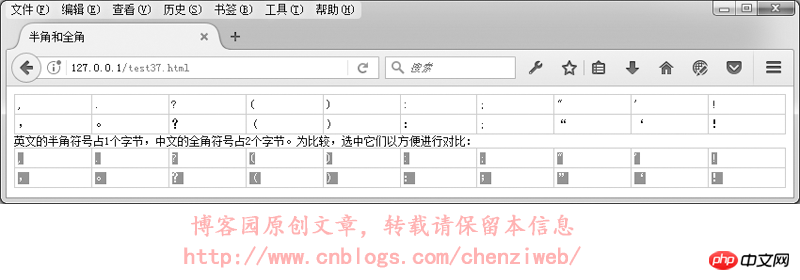
Sous la méthode de saisie chinoise, les signes de ponctuation par défaut sont des caractères pleine chasse ; sous la méthode de saisie anglaise, les signes de ponctuation sont des caractères demi-chasse.
Nous continuons à raconter l'histoire : à mesure que de plus en plus de pays utilisent des ordinateurs, de plus en plus de pays formulent leurs propres normes de codage informatique. Le résultat est que le codage informatique des différents pays ne se prend pas en charge ou ne se comprend pas. Par exemple, si vous souhaitez afficher des caractères chinois sur un ordinateur aux États-Unis, vous devez installer un système de caractères chinois, sinon les fichiers chinois seront tronqués lorsqu'ils seront ouverts sur un ordinateur doté d'un système américain.
Ainsi, durant cette période, une organisation internationale appelée ISO (Organisation internationale de normalisation, Organisation internationale de normalisation) est née pour commencer à résoudre les problèmes de codage dans divers pays. L'ISO a produit de manière uniforme un système de codage appelé UNICODE (Universal Multiple-Octet Coded Character Set, également appelé UCS), qui est utilisé pour enregistrer tous les mots et symboles de la Terre. Les caractères UNICODE sont divisés en 17 groupes, et chaque groupe est appelé un plan. Chaque plan possède 65 536 points de code et un total de 1 114 112 caractères peuvent être enregistrés (1,11 million de caractères, une capacité suffisamment grande). Le codage UNICODE unifié d'un caractère occupe 2 octets.
Mais UNICODE n'a pas pu être promu pendant longtemps jusqu'à l'émergence d'Internet. La transmission et l'échange de données ont rendu urgent l'unification du codage entre les pays. Cependant, les premiers disques durs et le trafic réseau étaient très coûteux. Chaque caractère du codage UNICODE occupait donc 2 octets de capacité, afin d'économiser l'espace disque occupé lors du stockage des fichiers, ainsi que le temps nécessaire à la transmission des caractères. sur le réseau, Pour occuper le trafic réseau, de nombreuses normes orientées transmission basées sur UNICODE ont été formulées. Ces normes orientées transmission sont collectivement appelées UTF (UCS Transfer Format). Le codage UNICODE et le codage UTF n'ont pas de correspondance directe un à un, mais doivent être convertis via certains algorithmes et règles. La relation entre UNICODE et UTF est la suivante : UNICODE est le fondement, la fondation et le but, tandis que UTF n'est qu'un moyen, une méthode et un processus pour réaliser UNICODE.
Les formats UTF courants sont : UTF-8, UTF-16, UTF-32. Parmi eux, UTF-8 est l'implémentation UNICODE la plus utilisée sur Internet. Elle est spécialement conçue pour la transmission. Précisément parce que UTF-8 est une méthode de mise en œuvre de transmission conçue sur la base d'UNICODE, il peut effectuer un encodage sans frontières et le texte de n'importe quel pays peut être affiché normalement dans un navigateur informatique dans n'importe quel pays. L'une des principales caractéristiques de l'UTF-8 est qu'il s'agit d'une méthode de codage de longueur variable. Elle peut utiliser 1 à 4 octets pour représenter un symbole. La longueur de l'octet change en fonction des différents symboles. Lorsqu'un symbole est représenté, 1 octet est utilisé pour le représenter. Si un symbole nécessite 2 octets pour être représenté, 2 octets sont utilisés pour le représenter, et ainsi de suite, jusqu'à 4 octets, économisant ainsi de l'espace de stockage sur le disque dur et du trafic réseau. .
Ainsi, si notre site Web est développé en utilisant l'encodage GB2312 ou GBK et que les ordinateurs d'autres pays ne prennent pas en charge l'encodage des caractères chinois, ce que vous verrez seront des codes tronqués, qui s'afficheront comme ceci : 口口口口口. Si le site Web utilise le codage UTF-8, le contenu sera automatiquement converti en codage UNICODE lorsqu'un ordinateur dans n'importe quel pays ouvrira le site Web, et comme tous les ordinateurs modernes prennent en charge le codage UNICODE, n'importe quel texte peut être affiché normalement !
Cependant, de nombreux sites Web nationaux utilisent encore l'encodage GB2312 ou GBK. Ces sites Web ne fournissent généralement des services qu'aux utilisateurs nationaux et n'auront pas de problèmes d'affichage pour les utilisateurs nationaux. Cependant, s’ils sont confrontés à des visiteurs d’autres pays, ces sites Web apparaîtront largement tronqués une fois ouverts.
Dans un souci de haute compatibilité et d'internationalisation du site Web, il est recommandé que le site Web utilise l'encodage UTF-8 au lieu de l'encodage GB2312 ou GBK.
Les balises qui spécifient les pages Web au format UTF-8, GB2312 et GBK sont :
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <meta http-equiv="Content-Type" content="text/html; charset=gb2312"> <meta http-equiv="Content-Type" content="text/html; charset=gbk">
那么有一个问题出现了:网页各种编码的区别,仅仅是在于这一行meta标签的设置差别吗?仅仅是“utf-8”这5个字符换成“gb2312”这6个字符之类的这种“小差别”吗?
不是的,差别不仅仅是这几个字符的差别。当网页指定meta标签中的编码为utf-8后,DreamWeaver在保存网页时会自动将网页文件保存为utf-8的编码格式(二进制码使用utf-8的编码格式),meta标签中的utf-8编码是为了告诉浏览器:这个网页用的是utf-8编码,请在显示时使用utf-8编码的格式解析并呈现出来;而如果meta标签中指定编码为gb2312,DreamWeaver在保存网页时会自动将网页文件保存为gb2312的编码格式(二进制码使用gb2312的编码格式),同样,meta标签中的gb2312编码只是为了告诉浏览器:这个网页用的是gb2312编码,请在显示时使用gb2312编码的格式解析并呈现出来。我们做个试验,将一个文本文件分别保存为utf-8格式(打开记事本新建文本文件,输入内容后,选择菜单:文件→另存为,编码选择为UTF-8)和gb2312格式(另存时编码选择为ANSI,ANSI代表当前操作系统的默认编码,在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码,类推),对比其二进制数据。这里使用UltraEdit-32文件编辑器对文本文件进行16进制查看,即使用16进制查看文件的二进制数据: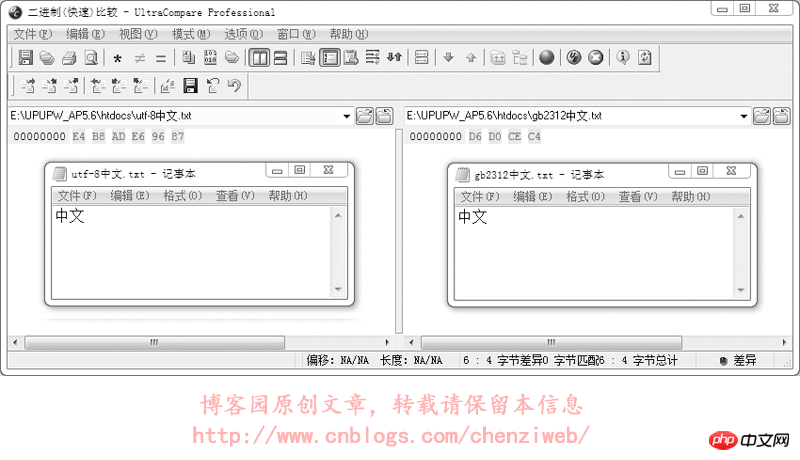
从上图中可以看到,使用utf-8编码和使用gb2312编码保存的文件,其二进制数据是不一样的,即这两个文件的二进制数据内容是不一样的。记事本软件在打开文本文件时,会尝试识别文件的编码并进行解析和显示,即文字保存在记事本里,无论保存成utf-8编码还是gb2312编码,通常情况下记事本都能正常识别和显示,不需要在文件里额外记录数据以告知记事本该文件是什么编码。但很多软件却无法做到智能识别文本文件的编码,这就要求文本文件在保存时,必须附带一些特殊的内容(额外的数据)以告知该文件是什么编码。UNICODE规范中有一个BOM(Byte Order Mark)的概念,就是字节序标记,在文件头部开始位置写入三个字节(EF BB BF)以告知该文件是utf-8编码格式。但这个BOM又带出了新的问题:不是所有的软件或处理程序都支持BOM,即不是所有的软件或处理程序都能识别文件开头的(EF BB BF)这三个字节。当不支持识别时,这三个字节又会被当成文件的实际数据内容。早期的火狐不支持对BOM的识别,当遇到BOM时会对这三个字节显示出特殊的乱码符号;而到目前为止,PHP处理程序仍然不支持BOM,即当一个PHP文件保存为utf-8时,如果附带了BOM,那么PHP处理程序会将BOM解析为PHP文件的实际数据内容而导致出错!在DreamWeaver中,选择软件头部菜单:修改→页面属性(也可以直接按快捷键ctrl+j),在弹出的页面属性面板中点选“标题/编码”,即可看到可供选择的编码。通常在改变网页的编码时,使用这种方式改变。如下图: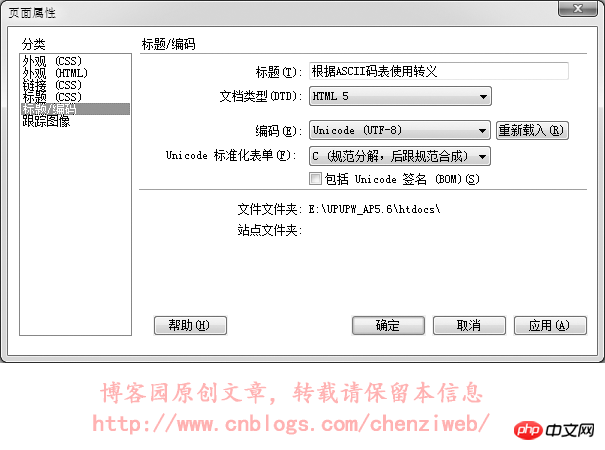
所以:当我们在meta标签中设置为utf-8编码格式时,网页文件就必须要存储为utf-8格式,这样浏览器才能正常显示网页而不是显示乱码。如果在meta标签中设置utf-8编码格式,网页文件却保存为gbk或其它格式,那么在打开网页时浏览器会接到网页meta标签中格式的通知:使用utf-8编码格式来解析和显示网页,而网页的二进制码(数据内容)却为gbk编码或其它格式,显示出来就会是乱码!这好比相亲时,红娘手里的资料有误,错误的告知男方:女方讲英语(meta标签中设置为utf-8编码)。结果女方却不懂英语(文件却不是utf-8编码)。男方开口一句“Hello”就让女方不知所谓了(乱码)。
我们来实验一下,网页指定meta标签中的编码为utf-8,文件却保存为gbk格式:我们先用DreamWeaver编辑一个utf-8格式的网页并保存,然后再用记事本打开该网页,另存为,编码选择为ANSI。
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>中文</title> </head> <body> 本文件使用dreamweaver保存后,再使用记事本打开,并另存为ANSI编码。 </body> </html>
在浏览器中的执行结果如下:
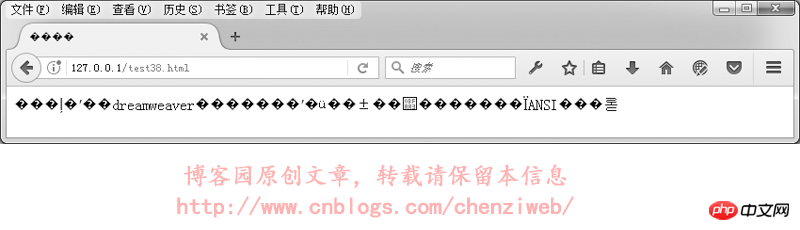
En résumé : Lors du développement de pages Web, essayez d'utiliser le format d'encodage utf-8, et lors de l'enregistrement de fichiers, enregistrez-les au format d'encodage utf-8. (Lorsque dreamweaver enregistre les fichiers de pages Web, il enregistre automatiquement le codage correct en fonction du codage spécifié par Encodage correspondant, mais si vous utilisez d'autres éditeurs de code de sites Web, tels que Notepad, Editplus, etc., vous devez faire attention à sélectionner le bon encodage lors de l'enregistrement du fichier).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle est la raison pour laquelle le screencasting échoue ? 'Une lecture incontournable pour les débutants : Comment résoudre le problème de l'échec d'une connexion de screencasting sans fil'
Feb 07, 2024 pm 05:03 PM
Quelle est la raison pour laquelle le screencasting échoue ? 'Une lecture incontournable pour les débutants : Comment résoudre le problème de l'échec d'une connexion de screencasting sans fil'
Feb 07, 2024 pm 05:03 PM
Pourquoi le screencasting sans fil ne parvient-il pas à se connecter ? Certains amis ont signalé que la connexion échouait lors de l'utilisation de la mise en miroir d'écran sans fil. Que se passe-t-il ? Que dois-je faire si la connexion de mise en miroir d'écran sans fil échoue ? Veuillez confirmer si votre ordinateur, votre téléviseur et votre téléphone portable sont connectés au même réseau WiFi. Le logiciel de mise en miroir d'écran nécessite que les appareils soient sur le même réseau pour fonctionner correctement, et Quick Screen Mirroring ne fait pas exception. Par conséquent, veuillez vérifier rapidement vos paramètres réseau. Il est important de déterminer si la fonction de mise en miroir d'écran est prise en charge. Les téléviseurs intelligents et les téléphones mobiles prennent généralement en charge les fonctionnalités DLNA ou AirPlay. Si la fonction screencast n’est pas prise en charge, la capture d’écran ne sera pas possible. Vérifiez si l'appareil est correctement connecté : Il peut y avoir plusieurs appareils sous le même WiFi. Assurez-vous que vous vous connectez à l'appareil avec lequel vous souhaitez partager l'écran. 4. Assurez-vous que le réseau
 Qu'est-ce qui empêche WPS Office de démarrer un travail d'impression ?
Mar 20, 2024 am 09:52 AM
Qu'est-ce qui empêche WPS Office de démarrer un travail d'impression ?
Mar 20, 2024 am 09:52 AM
Lors de la connexion d'une imprimante à un réseau local et du démarrage d'un travail d'impression, certains problèmes mineurs peuvent survenir. Par exemple, le problème "wpsoffice ne peut pas démarrer le travail d'impression..." se produit occasionnellement, entraînant l'impossibilité d'imprimer des fichiers, etc. ., retardant notre travail et nos études et provoquant un impact négatif, laissez-moi vous expliquer comment résoudre le problème selon lequel wpsoffice ne peut pas démarrer le travail d'impression ? Bien sûr, vous pouvez mettre à niveau le logiciel ou le pilote pour résoudre le problème, mais cela vous prendra beaucoup de temps. Ci-dessous, je vais vous donner une solution qui peut être résolue en quelques minutes. Tout d'abord, j'ai remarqué que wpsoffice ne pouvait pas démarrer le travail d'impression, ce qui entraînait l'impossibilité d'imprimer. Pour résoudre ce problème, nous devons enquêter un par un. Assurez-vous également que l’imprimante est sous tension et connectée. Généralement, une connexion anormale entraînera
 Comment résoudre les caractères chinois tronqués sous Linux
Feb 21, 2024 am 10:48 AM
Comment résoudre les caractères chinois tronqués sous Linux
Feb 21, 2024 am 10:48 AM
Le problème du chinois tronqué sous Linux est un problème courant lors de l'utilisation de jeux de caractères et d'encodages chinois. Les caractères tronqués peuvent être causés par des paramètres de codage de fichier incorrects, des paramètres régionaux du système non installés ou définis, des erreurs de configuration de l'affichage du terminal, etc. Cet article présentera plusieurs solutions de contournement courantes et fournira des exemples de code spécifiques. 1. Vérifiez le paramètre d'encodage du fichier. Utilisez la commande file pour afficher l'encodage du fichier. Utilisez la commande file dans le terminal pour afficher l'encodage du fichier : file-ifilename S'il y a "charset" dans la sortie.
 Comment résoudre le problème des caractères chinois tronqués dans Windows 10
Jan 16, 2024 pm 02:21 PM
Comment résoudre le problème des caractères chinois tronqués dans Windows 10
Jan 16, 2024 pm 02:21 PM
Dans le système Windows 10, les caractères tronqués sont courants. La raison derrière cela est souvent que le système d'exploitation ne fournit pas de prise en charge par défaut pour certains jeux de caractères, ou qu'il y a une erreur dans les options de jeu de caractères définies. Afin de prescrire le bon médicament, nous analyserons en détail ci-dessous les procédures opératoires réelles. Comment résoudre le code tronqué de Windows 10 1. Ouvrez les paramètres et recherchez « Heure et langue » 2. Recherchez ensuite « Langue » 3. Recherchez « Gérer les paramètres de langue » 4. Cliquez sur « Modifier les paramètres régionaux du système » ici 5. Vérifiez comme indiqué et cliquez sur Assurez-vous juste.
 Mar 22, 2024 pm 12:45 PM
Mar 22, 2024 pm 12:45 PM
Un guide complet des erreurs PHP500 : causes, diagnostics et correctifs Au cours du développement PHP, nous rencontrons souvent des erreurs avec le code d'état HTTP 500. Cette erreur est généralement appelée « 500InternalServerError », ce qui signifie que des erreurs inconnues se sont produites lors du traitement de la requête côté serveur. Dans cet article, nous explorerons les causes courantes des erreurs PHP500, comment les diagnostiquer et comment les corriger, et fournirons des exemples de code spécifiques pour référence. Causes courantes des erreurs 1.500 1.
 Méthode d'édition pour résoudre le problème des caractères tronqués lors de l'ouverture de fichiers dll
Jan 06, 2024 pm 07:53 PM
Méthode d'édition pour résoudre le problème des caractères tronqués lors de l'ouverture de fichiers dll
Jan 06, 2024 pm 07:53 PM
Lorsque de nombreux utilisateurs utilisent des ordinateurs, ils constateront qu'il existe de nombreux fichiers avec le suffixe dll, mais de nombreux utilisateurs ne savent pas comment ouvrir de tels fichiers. Pour ceux qui veulent savoir, veuillez consulter les détails suivants. pour ouvrir et modifier les fichiers dll : 1. Téléchargez un logiciel appelé "exescope", puis téléchargez-le et installez-le. 2. Cliquez ensuite avec le bouton droit sur le fichier dll et sélectionnez "Modifier les ressources avec exescope". 3. Cliquez ensuite sur « OK » dans la boîte de dialogue d'erreur contextuelle. 4. Ensuite, sur le panneau de droite, cliquez sur le signe « + » devant chaque groupe pour afficher le contenu qu'il contient. 5. Cliquez sur le fichier dll que vous souhaitez afficher, puis cliquez sur « Fichier » et sélectionnez « Exporter ». 6. Ensuite, vous pouvez
 Pourquoi le chargement des téléphones mobiles Apple est-il si lent ?
Mar 08, 2024 pm 06:28 PM
Pourquoi le chargement des téléphones mobiles Apple est-il si lent ?
Mar 08, 2024 pm 06:28 PM
Certains utilisateurs peuvent rencontrer des vitesses de chargement lentes lorsqu'ils utilisent des téléphones Apple. Ce problème peut avoir de nombreuses raisons. Il peut être dû à une faible puissance du chargeur, à une panne de l'appareil, à des problèmes avec l'interface USB du téléphone mobile ou même au vieillissement de la batterie et à d'autres facteurs. Pourquoi le téléphone mobile Apple se charge-t-il très lentement ? Réponse : problème d'équipement de charge, problème matériel de téléphone mobile, problème de système de téléphonie mobile. 1. Lorsque les utilisateurs utilisent un équipement de chargement avec une puissance relativement faible, la vitesse de chargement du téléphone mobile sera très lente. 2. L'utilisation de chargeurs ou de câbles de charge tiers de qualité inférieure entraînera également une charge lente. 3. Il est recommandé aux utilisateurs d'utiliser le chargeur d'origine officiel ou de le remplacer par un chargeur haute puissance certifié standard. 4. Il y a un problème avec le matériel du téléphone mobile de l'utilisateur. Par exemple, l'interface USB du téléphone mobile ne peut pas être contactée.
 Résolvez le problème des caractères tronqués dans le bloc-notes Win11
Jan 05, 2024 pm 03:11 PM
Résolvez le problème des caractères tronqués dans le bloc-notes Win11
Jan 05, 2024 pm 03:11 PM
Certains amis veulent ouvrir un bloc-notes et constatent que leur bloc-notes Win11 est tronqué et ne savent pas quoi faire. En fait, il suffit généralement de modifier la région et la langue. Le Bloc-notes Win11 est tronqué : Première étape, utilisez la fonction de recherche, recherchez et ouvrez le "Panneau de configuration". Deuxième étape, cliquez sur "Modifier le format de la date, de l'heure ou des nombres" sous Horloge et région. Troisième étape, cliquez sur l'option "Gérer". au-dessus de la carte. La quatrième étape consiste à cliquer sur « Modifier les paramètres régionaux du système » ci-dessous. La cinquième étape consiste à modifier les paramètres régionaux actuels du système en « Chinois (simplifié, Chine) » et à cliquer sur « OK » pour enregistrer.
