
 base de données
tutoriel mysql
Analyse comparative des solutions haute disponibilité pour Oracle et MySQL
base de données
tutoriel mysql
Analyse comparative des solutions haute disponibilité pour Oracle et MySQL
Analyse comparative des solutions haute disponibilité pour Oracle et MySQL

Concernant les solutions de haute disponibilité d'Oracle et MySQL, j'ai toujours voulu les résumer, je vais donc en parler brièvement dans plusieurs séries. Grâce à cette comparaison, vous aurez une compréhension de base des différences détaillées dans la conception des deux architectures de bases de données. Oracle dispose d'une solution très mature. À en juger par mon ppt sur OOW, c'est le plan de MAA. Cette année, c'est le 16ème anniversaire de ce plan. Cet article présente principalement l'analyse comparative des solutions haute disponibilité d'Oracle et MySQL. Elle est très bonne et a une valeur de référence. Les amis dans le besoin peuvent s'y référer.

En raison de la nature open source de MySQL, la communauté a lancé davantage de solutions. À mon avis, InnoDB Cluster sera la solution standard à haute disponibilité pour MySQL dans le monde. avenir.
À l'heure actuelle, MGR est certainement bon, et il existe également des solutions MySQL Cluster, PXC, Galera et d'autres solutions. Personnellement, je préfère toujours MHA.
Cet article sera donc divisé en plusieurs. parties à interpréter. Faisons d’abord une comparaison de base entre RAC et MHA.
Les solutions d'Oracle ont répondu aux principaux besoins commerciaux d'Alibaba au cours de sa période de développement rapide. C'est probablement ce genre de système d'architecture, qui semble très énorme. Le RAC à l'intérieur est considéré comme un aristocrate, utilisant un stockage commercial coûteux, des exigences de bande passante réseau extrêmement élevées, un grand nombre de petits services informatiques frontaux et des frais de licence coûteux. Une architecture classique IOE très typique.

Si vous souhaitez envisager une reprise après sinistre hors site, alors l'allocation des ressources doit être doublée et le budget doit être doublé.
La solution architecturale de MySQL est relativement plus civile. Un PC ordinaire suffit, mais l'ordre de grandeur est plus élevé lors du fractionnement d'entreprise, le fractionnement horizontal peut étendre horizontalement de nombreux nœuds. Les clusters MySQL comptent des centaines ou des centaines, et des milliers ne sont pas rares. Avec autant de ressources de services, il existe toujours une probabilité d’échec. Garantir un accès durable aux services professionnels est la clé des solutions techniques. Si vous suivez l'architecture MHA, le nœud MHA Manager est essentiellement responsable du statut de l'ensemble du cluster. C'est comme une tante du comité de quartier qui connaît toutes les petites et grandes choses sur les résidents.

Bien sûr, la déclaration ci-dessus est trop générale, commençons par quelques détails. Par exemple, parlons d’abord d’Internet.
Oracle a des exigences très strictes pour le réseau. Généralement, il nécessite 2 cartes réseau physiques. Chaque serveur nécessite au moins 3 IP, IP publique, IP privée, VIP En plus du stockage partagé, au moins 2 sont. requis.
L'IP privée est pour la confiance mutuelle entre les nœuds. L'IP publique et le VIP sont dans le même segment de réseau. En termes simples, VIP est externe et est l'IP de dérive du réseau où se trouve l'IP publique. tout se fait via VIP Pour l'équilibrage de charge, le scan-IP a été introduit depuis 11g, et le VIP d'origine est toujours conservé, de sorte que les exigences de configuration réseau dans Oracle sont toujours très élevées. Indépendamment du stockage partagé, le cœur de la construction est la configuration du réseau, et le réseau est général.
scan-IP peut continuer à être étendu, prenant en charge jusqu'à 3 scan-ips, comme le montre la figure ci-dessous

Bien sûr, le niveau réseau ne se limite pas à ceux-là. Le point fort d'Oracle est qu'il est très professionnel. Nous devons comprendre TAF. Dans mon livre "Oracle DBA Work Notes", j'ai écrit :
TAF (Transparent Application Failover) est un basculement transparent des applications dans Oracle dans un environnement RAC particulièrement largement utilisé. Load Balance dans RAC a en effet été grandement amélioré Du Load Balance de plusieurs adresses VIP à partir de la version 10g, au SCAN dans la version 11g, il a été grandement simplifié.
Dans l'implémentation du Failover, il existe encore certaines restrictions d'utilisation. Par exemple, l'implémentation par défaut de SCAN-IP dans 11g n'a en fait pas d'option Failover par défaut. Si l'un des deux nœuds raccroche, alors. Si vous continuez à interroger la connexion d'origine, vous serez informé que la session a été déconnectée et doit être reconnectée. Le client TAF abordera principalement certains contenus simples de la méthode de basculement et du type de basculement.
(1)Méthode de basculement
L'idée principale de la méthode de basculement est d'échanger le temps de basculement ou d'échanger des ressources pour la mise en œuvre.
Cela peut être compris ainsi. Supposons que nous ayons deux nœuds. Si une session est connectée au nœud 2, mais que le nœud 2 raccroche soudainement, afin de gérer la situation de basculement plus rapidement, la méthode de basculement a deux types. : préconnecté et type basique.
— la préconnexion consommera encore beaucoup de ressources. Elle occupera des ressources supplémentaires sur chaque nœud. La commutation sera relativement plus fluide et plus rapide.
—Basique Cette méthode, lorsqu'un basculement se produit, change les ressources correspondantes. Il y aura un certain retard dans le processus, mais la consommation de ressources est relativement beaucoup plus faible.
Pour faire simple, la méthode de base ne jugera que lorsqu'un défaut se produit, tandis que la préconnexion consiste à préparer un jour de pluie à partir d'une application pratique, la méthode de base est plus polyvalente et constitue également la méthode de basculement par défaut ; .
(2)Type de basculement
La mise en œuvre du type de basculement est plus riche, plus flexible et très puissante. À l'heure actuelle, la granularité du contrôle peut être contrôlée en fonction de l'exécution du SQL utilisateur. Il existe deux types : select et session, illustrons avec un petit exemple.
Par exemple, nous avons une requête volumineuse sur le nœud 2, et le nœud 2 raccroche soudainement. Pour la requête en cours d'exécution, par exemple, il y a 10 000 données, et le résultat est détecté juste au moment de la panne. se produit. Si vous possédez 8 000 éléments, que devez-vous faire des 2 000 restants ?
La première méthode consiste à utiliser select ; c'est-à-dire que le basculement sera terminé et que les 2 000 enregistrements restants continueront d'être renvoyés. Bien sûr, il y aura un changement de contexte au milieu, ce qui est transparent. l'utilisateur.
La deuxième méthode est la session ; c'est-à-dire se déconnecter directement et demander à nouveau d'interroger.
Dans la version 10g, la configuration pour réaliser Load Balance+Failover à l'aide de la configuration VIP est la suivante :
racdb= (DESCRIPTION = (ADDRESS= (PROTOCOL= TCP)(HOST=192.168.3.101)(PORT= 1521)) (ADDRESS= (PROTOCOL= TCP)(HOST=192.168.3.201)(PORT= 1521)) (LOAD_BALANCE = yes) (FAILOVER = ON) (CONNECT_DATA = (SERVER= DEDICATED) (SERVICE_NAME = racdb) (FAILOVER_MODE = (TYPE= SELECT) (METHOD= BASIC) (RETRIES = 30) (DELAY = 5)))) 如果11g的SCAN-IP也想进一步扩展Failover,同样也需要设置failover_mode和对应的类型。 RACDB = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = rac-scan)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = RACDB) ) )
De ce point de vue, la solution d’Oracle est vraiment sophistiquée. Jetons un coup d'œil à la solution MySQL.
La solution distribuée fait ressembler MySQL à un couteau suisse. Concernant les exigences au niveau du réseau, on peut dire que MySQL n'a aucune exigence. Si vous postulez pour un maître et un esclave, vous n'avez besoin que de 4 IP (Maître. , esclave, VIP, MHA_Manager (considérez un nœud gestionnaire)), un maître et deux esclaves font 5.

MySQL ne prend pas en charge nativement ce que l'on appelle l'équilibrage de charge. Il peut être détourné via des activités frontales, telles que l'utilisation d'un proxy middleware ou le fractionnement continu, pour atteindre un certain objectif. Après la granularité, les exigences sont satisfaites grâce à la conception architecturale. Étant donné que la réplication basée sur la logique est facile à étendre, un maître et plusieurs esclaves sont très courants et le coût n'est pas élevé. On ne peut pas dire que le délai est nul, mais simplement très faible, et il peut s'adapter à la plupart des besoins des entreprises Internet.
En ce qui concerne les conditions qui déclenchent la commutation MHA, du point de vue du réseau, les points rouges suivants sont des dangers potentiels. Certains sont des interruptions du réseau et d'autres des retards du réseau. Lorsqu'une panne se produit, il est préférable de le faire. protéger les données. Les performances sont stables et peuvent être personnalisées en fonction de vos propres besoins. De ce point de vue, il existe une probabilité de perte de données. Ce n’est certainement pas une copie sans perte avec une forte cohérence.
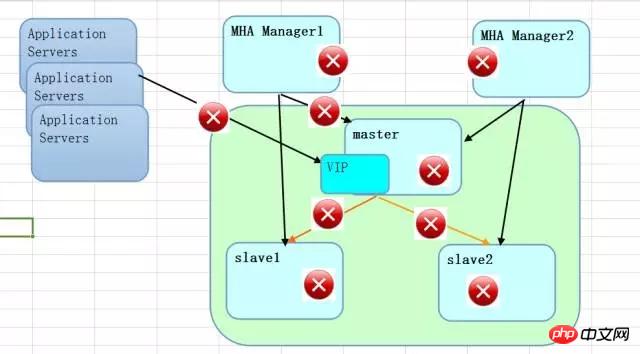
En regardant les deux solutions dans leur ensemble, RAC est un partage centralisé En plus du partage au niveau du stockage, la multidiffusion au niveau du réseau augmentera en fait le coût de la communication entre les nœuds. , donc RAC a de grandes exigences sur le réseau. S'il y a du retard, c'est très dangereux. Si un cerveau divisé se produit, ce sera très embarrassant. La solution MySQL MHA est distribuée. Prenant en charge les environnements à volume élevé, le coût de la communication entre les nœuds est relativement faible. Mais du point de vue de l'architecture des données, comme il s'agit d'une méthode de distribution de données répliquée, même si le stockage n'est pas un stockage partagé, le coût du stockage est toujours plus élevé que celui du RAC (il ne s'agit pas du prix du stockage, mais de la quantité de données stockées). ).
Recommandations associées :
Oracle et Mysql génèrent respectivement des séquences de séquence
Comparaison de quelques commandes simples entre Oracle et MySQL_MySQL
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment vérifier la taille de l'espace de table d'Oracle
Apr 11, 2025 pm 08:15 PM
Comment vérifier la taille de l'espace de table d'Oracle
Apr 11, 2025 pm 08:15 PM
Pour interroger la taille de l'espace de table Oracle, suivez les étapes suivantes: Déterminez le nom de l'espace de table en exécutant la requête: sélectionnez Tablespace_name dans dba_tablespaces; Requête la taille de l'espace de table en exécutant la requête: sélectionnez SUM (Bytes) comme total_size, sum (bytes_free) comme disponible_space, sum (bytes) - sum (bytes_free) comme used_space à partir de dba_data_files où tablespace_
 Comment désinstaller l'installation d'Oracle a échoué
Apr 11, 2025 pm 08:24 PM
Comment désinstaller l'installation d'Oracle a échoué
Apr 11, 2025 pm 08:24 PM
Désinstaller la méthode pour la défaillance de l'installation d'Oracle: Fermez le service Oracle, supprimez les fichiers du programme Oracle et les clés de registre, désinstallez les variables d'environnement Oracle et redémarrez l'ordinateur. Si la désinstallation échoue, vous pouvez désinstaller manuellement à l'aide de l'outil Oracle Universal Disinstal.
 Comment afficher le nom d'instance d'Oracle
Apr 11, 2025 pm 08:18 PM
Comment afficher le nom d'instance d'Oracle
Apr 11, 2025 pm 08:18 PM
Il existe trois façons d'afficher les noms d'instance dans Oracle: utilisez le "SQLPlus" et "SELECT INSTRESS_NAME FROM V $ INSTERNE;" Commandes sur la ligne de commande. Utilisez "Show instance_name;" Commande dans SQL * Plus. Vérifiez les variables d'environnement (Oracle_sid sur Linux) via le gestionnaire de tâches du système d'exploitation, Oracle Enterprise Manager ou via le système d'exploitation.
 Comment crypter Oracle View
Apr 11, 2025 pm 08:30 PM
Comment crypter Oracle View
Apr 11, 2025 pm 08:30 PM
Oracle View Encryption vous permet de crypter les données dans la vue, améliorant ainsi la sécurité des informations sensibles. Les étapes incluent: 1) la création de la clé de cryptage maître (MEK); 2) Création d'une vue cryptée, spécifiant la vue et MEK à crypter; 3) Autoriser les utilisateurs à accéder à la vue cryptée. Comment fonctionnent les vues cryptées: lorsqu'un utilisateur interroge pour une vue cryptée, Oracle utilise MEK pour décrypter les données, garantissant que seuls les utilisateurs autorisés peuvent accéder aux données lisibles.
 Comment résoudre le code brouillé dans Oracle
Apr 11, 2025 pm 10:09 PM
Comment résoudre le code brouillé dans Oracle
Apr 11, 2025 pm 10:09 PM
Oracle Bragled Les problèmes peuvent être résolus en vérifiant le jeu de caractères de la base de données pour s'assurer qu'ils correspondent aux données. Définissez le jeu de caractères client pour correspondre à la base de données. Convertir les données ou modifier les jeux de caractères de colonne pour faire correspondre les jeux de caractères de base de données. Utilisez des jeux de caractères Unicode et évitez les jeux de caractères mulabyte. Vérifiez que les paramètres de langue de la base de données et du client sont corrects.
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Que faire si l'oracle ne peut pas être ouvert
Apr 11, 2025 pm 10:06 PM
Que faire si l'oracle ne peut pas être ouvert
Apr 11, 2025 pm 10:06 PM
Les solutions à Oracle ne peuvent pas être ouvertes comprennent: 1. Démarrer le service de base de données; 2. Commencez l'auditeur; 3. Vérifiez les conflits portuaires; 4. Définir correctement les variables d'environnement; 5. Assurez-vous que le pare-feu ou le logiciel antivirus ne bloque pas la connexion; 6. Vérifiez si le serveur est fermé; 7. Utilisez RMAN pour récupérer les fichiers corrompus; 8. Vérifiez si le nom du service TNS est correct; 9. Vérifier la connexion réseau; 10. Réinstaller le logiciel Oracle.
