

Top 10 des algorithmes d'apprentissage automatique que vous devez connaître

Il ne fait aucun doute que les domaines de l’apprentissage automatique et de l’intelligence artificielle ont reçu de plus en plus d’attention ces dernières années. Alors que le Big Data est devenu la tendance technologique la plus en vogue dans l’industrie, l’apprentissage automatique a également obtenu des résultats étonnants en matière de prédiction et de recommandation à l’aide du Big Data. Des cas d'apprentissage automatique plus célèbres incluent Netflix recommandant des films aux utilisateurs en fonction de leur comportement de navigation historique, et Amazon recommandant des livres en fonction du comportement d'achat historique des utilisateurs. Cet article présente principalement les dix principaux algorithmes qui doivent être compris dans une brève discussion sur l'apprentissage automatique. Il a une certaine valeur de référence et les amis dans le besoin peuvent s'y référer.
Alors, si vous souhaitez apprendre les algorithmes d’apprentissage automatique, par où commencer ? Dans mon cas, mon cours d'introduction était un cours d'intelligence artificielle que j'ai suivi lors de mes études à l'étranger à Copenhague. L'enseignant est professeur à temps plein de mathématiques appliquées et d'informatique à l'Université technique du Danemark. Son domaine de recherche est la logique et l'intelligence artificielle, principalement la modélisation à l'aide de méthodes logiques. Le cours comprend deux parties : discussion de la théorie/des concepts de base et pratique pratique. Le manuel que nous utilisons est l'un des livres classiques sur l'intelligence artificielle : "Artificial Intelligence - A Modern Approach" du professeur Peter Norvig. Le cours implique des agents intelligents, la résolution basée sur la recherche, la recherche contradictoire, la théorie des probabilités, les systèmes multi-agents et. socialisation Intelligence artificielle, ainsi que des sujets tels que l'éthique et l'avenir de l'intelligence artificielle. Plus tard dans le cours, nous avons également fait équipe tous les trois pour réaliser un projet de programmation et implémenté un algorithme simple basé sur la recherche pour résoudre des tâches de transport dans un environnement virtuel.
J'ai beaucoup appris du cours et j'ai l'intention de continuer à étudier en profondeur ce sujet. Au cours des dernières semaines, j'ai assisté à plusieurs conférences sur l'apprentissage profond, les réseaux de neurones et l'architecture des données dans la région de San Francisco, ainsi qu'à une conférence sur l'apprentissage automatique avec de nombreux professeurs renommés. Plus important encore, je me suis inscrit au cours en ligne « Introduction à l'apprentissage automatique » d'Udacity début juin et j'ai terminé le contenu du cours il y a quelques jours. Dans cet article, j'aimerais partager quelques algorithmes d'apprentissage automatique courants que j'ai appris pendant le cours.
Les algorithmes d'apprentissage automatique peuvent généralement être divisés en trois grandes catégories : l'apprentissage supervisé, l'apprentissage non supervisé et l'apprentissage par renforcement. L'apprentissage supervisé est principalement utilisé dans des scénarios dans lesquels une partie de l'ensemble de données (données de formation) a une certaine familiarité (étiquettes) qui peut être obtenue, mais les échantillons restants sont manquants et doivent être prédits. L'apprentissage non supervisé est principalement utilisé pour explorer les relations implicites entre des ensembles de données non étiquetés. L'apprentissage par renforcement se situe quelque part entre les deux : chaque étape de prédiction ou de comportement contient plus ou moins d'informations en retour, mais il n'y a pas d'étiquette précise ni d'invite d'erreur. Puisqu’il s’agit d’un cours d’introduction, l’apprentissage par renforcement n’est pas évoqué, mais j’espère que les dix algorithmes d’apprentissage supervisé et non supervisé suffiront à vous mettre en appétit.
Apprentissage supervisé
1. Arbre de décision :
L'arbre de décision est un outil d'aide à la décision qui utilise un diagramme en arbre ou un modèle d'arbre pour représenter la décision. -processus de création et résultats ultérieurs, y compris les résultats d'événements probabilistes, etc. Veuillez observer le diagramme ci-dessous pour comprendre la structure de l'arbre de décision.
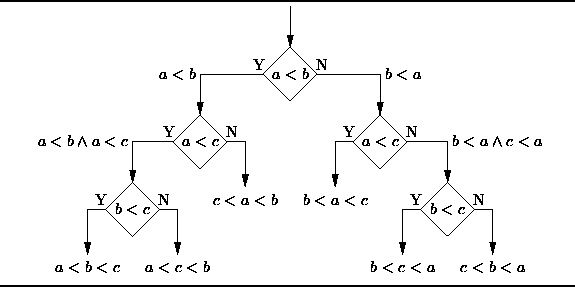
Du point de vue de la prise de décision commerciale, un arbre de décision consiste à prédire la probabilité d'une décision correcte à travers le moins de bonnes et de mauvaises questions de jugement possible. Cette approche peut vous aider à utiliser une approche structurée et systématique pour tirer des conclusions raisonnables.
2. Classificateur Naive Bayes :
Le classificateur Naive Bayes est un classificateur probabiliste simple basé sur la théorie bayésienne. Il suppose que les fonctionnalités étaient auparavant indépendantes les unes des autres. La figure ci-dessous montre la formule : P(A|B) représente la probabilité a posteriori, P(B|A) est la valeur de vraisemblance, P(A) est la probabilité a priori de la catégorie et P(B) représente le prédicteur. Probabilité préalable.

Quelques exemples de scénarios réels :
Détecter les courriers indésirables
Catégoriser les actualités dans des catégories telles que la technologie, la politique, le sport , etc.
Déterminer si un morceau de texte exprime des émotions positives ou négatives
Utilisé dans les logiciels de détection de visages
Régression des moindres carrés :
Si vous avez suivi un cours de statistiques, vous avez peut-être entendu parler du concept de régression linéaire. La régression des moindres carrés est une méthode de régression linéaire. Vous pouvez considérer la régression linéaire comme l’ajustement d’une ligne droite à plusieurs points. Il existe de nombreuses méthodes d'ajustement. La stratégie des « moindres carrés » équivaut à tracer une ligne droite, puis à calculer la distance verticale de chaque point à la ligne droite, et enfin à additionner les distances. La ligne droite la mieux ajustée est celle avec ; la plus petite somme de distances.
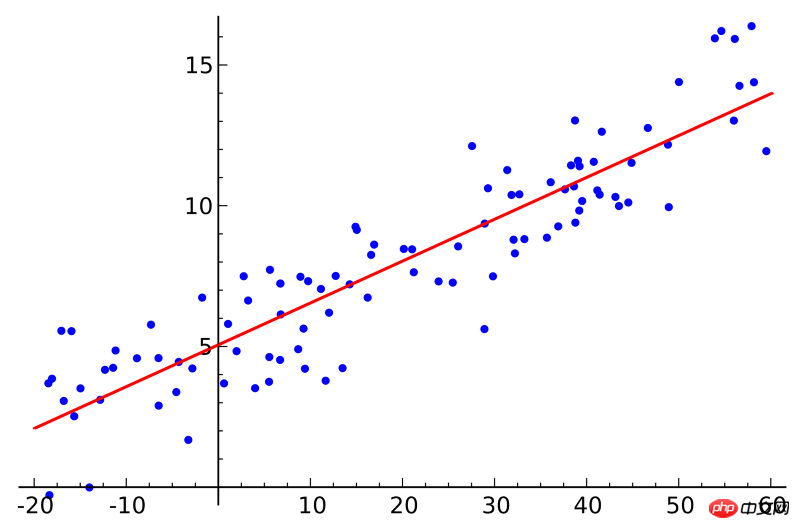
Linéaire fait référence au modèle utilisé pour ajuster les données, tandis que les moindres carrés font référence à la fonction de perte à optimiser.
4. Régression logistique :
Le modèle de régression logistique est une méthode de modélisation statistique puissante qui utilise une ou plusieurs variables explicatives pour générer des résultats binaires. Il utilise la fonction logistique pour estimer la valeur de probabilité afin de mesurer la relation entre une variable dépendante catégorielle et une ou plusieurs variables indépendantes, qui appartiennent à la distribution logistique cumulative.

De manière générale, les applications des modèles de régression logistique dans des scénarios réels incluent :
Pointage de crédit
Prédire la probabilité de succès des activités commerciales
Prédire les revenus d'un certain produit
Prédire la probabilité d'un tremblement de terre un certain jour
5. Machine à vecteurs de support :
La machine à vecteurs de support est un algorithme de classification binaire. Étant donné deux types de points dans un espace à N dimensions, la machine à vecteurs de support génère un hyperplan à (N-1) dimensions pour classer ces points en deux catégories. Par exemple, il existe deux types de points linéairement séparables sur le papier. La machine à vecteurs supports trouve une ligne droite qui sépare ces deux types de points et qui est aussi éloignée que possible de chacun d'eux.
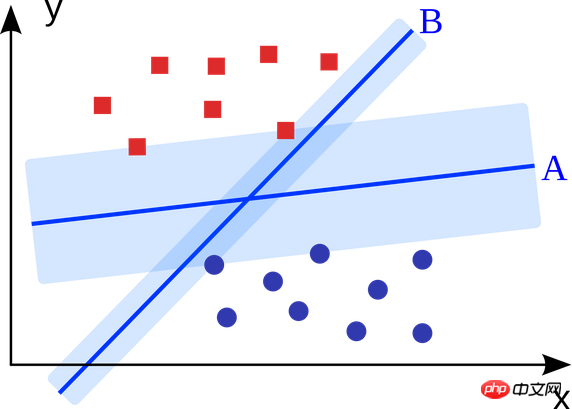
Les problèmes à grande échelle résolus à l'aide de machines à vecteurs de support (améliorées en fonction de scénarios d'application spécifiques) incluent la publicité display, la reconnaissance des parties articulaires du corps humain, la vérification du sexe basée sur l'image, les grandes échelle Classification des images, etc...
6. Méthode d'intégration :
La méthode d'intégration consiste d'abord à construire un ensemble de classificateurs, puis à utiliser le vote pondéré de chaque classificateur pour prédire de nouveaux algorithmes de données. La méthode d'ensemble originale était la moyenne bayésienne, mais les algorithmes plus récents incluent des algorithmes de codage de sortie et d'amplification avec correction des erreurs.

Alors quel est le principe du modèle intégré, et pourquoi est-il plus performant que le modèle indépendant ?
Ils éliminent l'effet de biais : par exemple, si vous mélangez le questionnaire du Parti démocrate avec celui du Parti républicain, vous obtiendrez une information quelconque et neutre.
Ils peuvent réduire la variance des prédictions : les résultats de prédiction de l'agrégation de plusieurs modèles sont plus stables que les résultats de prédiction d'un seul modèle. Dans le monde financier, cela s’appelle la diversification : un mélange de plusieurs actions évolue toujours beaucoup moins qu’une seule action. Cela explique également pourquoi le modèle s'améliorera à mesure que les données d'entraînement augmenteront.
Ils ne sont pas sujets au surajustement : si un seul modèle n'est pas surajusté, alors en combinant simplement les résultats de prédiction de chaque modèle (moyenne, moyenne pondérée, régression logistique), il n'y a aucune raison de surajuster l'ajustement.
Apprentissage non supervisé
7. Algorithme de clustering :
La tâche de l'algorithme de clustering est de regrouper un groupe d'objets en plusieurs groupes d'objets. le même groupe (cluster) est plus similaire que les objets des autres groupes.
Chaque algorithme de clustering est différent, en voici quelques-uns :
Algorithme de clustering basé sur le centre
Algorithme de clustering basé sur les connexions
Algorithme de clustering basé sur la densité
Algorithme probabiliste
Algorithme de réduction de dimensionnalité
Réseau neuronal/apprentissage profond
Composant principal analyse :
L'analyse en composantes principales est une méthode statistique. La transformation orthogonale convertit un ensemble de variables qui peuvent être corrélées en un ensemble de variables linéairement non corrélées, l'ensemble de variables converti est appelé la composante principale. .

Certaines applications pratiques de l'analyse en composantes principales incluent la compression des données, la représentation simplifiée des données, la visualisation des données, etc. Il convient de mentionner que la connaissance du domaine est nécessaire pour juger s’il est approprié d’utiliser l’algorithme d’analyse en composantes principales. Si les données sont trop bruitées (c'est-à-dire que la variance de chaque composante est grande), il n'est pas approprié d'utiliser l'algorithme d'analyse des composantes principales.
9. Décomposition en valeurs singulières :
La décomposition en valeurs singulières est une décomposition matricielle importante en algèbre linéaire et une généralisation de la diagonalisation unitaire matricielle normale en analyse matricielle. Pour une matrice m*n donnée M, elle peut être décomposée en M=UΣV, où U et V sont des matrices unitaires d'ordre m×m, et Σ est une matrice diagonale semi-définie positive d'ordre m×n.

L'analyse en composantes principales est en fait un simple algorithme de décomposition en valeurs singulières. Dans le domaine de la vision par ordinateur, le premier algorithme de reconnaissance faciale utilisait l'analyse en composantes principales et la décomposition en valeurs singulières pour représenter le visage comme une combinaison linéaire d'un ensemble de « faces propres », après réduction de dimensionnalité, puis utilisait des méthodes simples pour faire correspondre le visage du candidat. Bien que les méthodes modernes soient plus sophistiquées, de nombreuses techniques sont similaires.
10. Analyse des composants indépendants :
L'analyse des composants indépendants est une méthode qui utilise des principes statistiques pour effectuer des calculs afin de révéler les facteurs cachés derrière des variables aléatoires, des mesures ou des signaux. . L'algorithme d'analyse des composants indépendants définit un modèle génératif pour les données multivariées observées, généralement de grands lots d'échantillons. Dans ce modèle, les variables de données sont supposées être des mélanges linéaires de certaines variables latentes inconnues, et le système de mélange est également inconnu. Les variables latentes sont supposées non gaussiennes et indépendantes ; elles sont appelées composantes indépendantes des données observées.
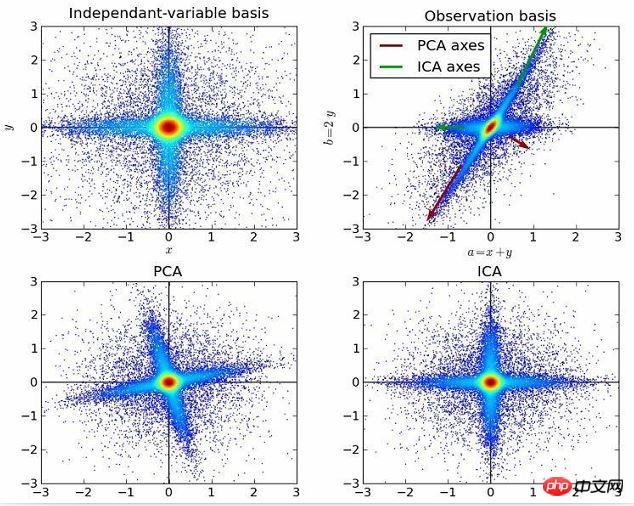
L'analyse en composantes indépendantes est liée à l'analyse en composantes principales, mais c'est une technique plus puissante. Il peut toujours trouver les facteurs sous-jacents à la source de données lorsque ces méthodes classiques échouent. Ses applications incluent les images numériques, les bases de données documentaires, les indicateurs économiques et les mesures psychométriques.
Maintenant, veuillez utiliser les algorithmes que vous comprenez pour créer des applications d'apprentissage automatique et améliorer la qualité de vie des personnes dans le monde entier.
Recommandations associées :
Fonction de service client automatique du mini-programme WeChat
Développement php du robot de paiement et de chat WeChat
Exemple de tutoriel de la bibliothèque d'apprentissage automatique PHP php-ml

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Apprenez à désinstaller complètement pip et à utiliser Python plus efficacement
Jan 16, 2024 am 09:01 AM
Apprenez à désinstaller complètement pip et à utiliser Python plus efficacement
Jan 16, 2024 am 09:01 AM
Plus besoin de pip ? Venez apprendre à désinstaller pip efficacement ! Introduction : pip est l'un des outils de gestion de packages Python, qui peut facilement installer, mettre à niveau et désinstaller les packages Python. Cependant, nous devrons parfois désinstaller pip, peut-être parce que nous souhaitons utiliser un autre outil de gestion de packages, ou parce que nous devons vider complètement l'environnement Python. Cet article explique comment désinstaller pip efficacement et fournit des exemples de code spécifiques. 1. Méthodes de désinstallation de pip Ce qui suit présente deux méthodes courantes de désinstallation de pip.
 Une plongée approfondie dans la palette de couleurs de matplotlib
Jan 09, 2024 pm 03:51 PM
Une plongée approfondie dans la palette de couleurs de matplotlib
Jan 09, 2024 pm 03:51 PM
Pour en savoir plus sur la table de couleurs matplotlib, vous avez besoin d'exemples de code spécifiques 1. Introduction matplotlib est une puissante bibliothèque de dessins Python. Elle fournit un riche ensemble de fonctions et d'outils de dessin qui peuvent être utilisés pour créer différents types de graphiques. La palette de couleurs (colormap) est un concept important dans matplotlib, qui détermine la palette de couleurs du graphique. Une étude approfondie de la table des couleurs matplotlib nous aidera à mieux maîtriser les fonctions de dessin de matplotlib et à rendre les dessins plus pratiques.
 Révéler l'attrait du langage C : découvrir le potentiel des programmeurs
Feb 24, 2024 pm 11:21 PM
Révéler l'attrait du langage C : découvrir le potentiel des programmeurs
Feb 24, 2024 pm 11:21 PM
Le charme de l'apprentissage du langage C : libérer le potentiel des programmeurs Avec le développement continu de la technologie, la programmation informatique est devenue un domaine qui a beaucoup attiré l'attention. Parmi les nombreux langages de programmation, le langage C a toujours été apprécié des programmeurs. Sa simplicité, son efficacité et sa large application font de l’apprentissage du langage C la première étape pour de nombreuses personnes souhaitant entrer dans le domaine de la programmation. Cet article discutera du charme de l’apprentissage du langage C et de la manière de libérer le potentiel des programmeurs en apprenant le langage C. Tout d’abord, le charme de l’apprentissage du langage C réside dans sa simplicité. Comparé à d'autres langages de programmation, le langage C
 Apprenons ensemble à saisir le numéro racine dans Word
Mar 19, 2024 pm 08:52 PM
Apprenons ensemble à saisir le numéro racine dans Word
Mar 19, 2024 pm 08:52 PM
Lors de la modification du contenu du texte dans Word, vous devez parfois saisir des symboles de formule. Certains gars ne savent pas comment saisir le numéro racine dans Word, alors Xiaomian m'a demandé de partager avec mes amis un tutoriel sur la façon de saisir le numéro racine dans Word. J'espère que cela aidera mes amis. Tout d'abord, ouvrez le logiciel Word sur votre ordinateur, puis ouvrez le fichier que vous souhaitez modifier et déplacez le curseur vers l'emplacement où vous devez insérer le signe racine, reportez-vous à l'exemple d'image ci-dessous. 2. Sélectionnez [Insérer], puis sélectionnez [Formule] dans le symbole. Comme indiqué dans le cercle rouge dans l'image ci-dessous : 3. Sélectionnez ensuite [Insérer une nouvelle formule] ci-dessous. Comme indiqué dans le cercle rouge dans l'image ci-dessous : 4. Sélectionnez [Formule radicale], puis sélectionnez le signe racine approprié. Comme le montre le cercle rouge sur l'image ci-dessous :
 Premiers pas avec Pygame : didacticiel complet d'installation et de configuration
Feb 19, 2024 pm 10:10 PM
Premiers pas avec Pygame : didacticiel complet d'installation et de configuration
Feb 19, 2024 pm 10:10 PM
Apprenez Pygame à partir de zéro : didacticiel complet d'installation et de configuration, exemples de code spécifiques requis Introduction : Pygame est une bibliothèque de développement de jeux open source développée à l'aide du langage de programmation Python. Elle fournit une multitude de fonctions et d'outils, permettant aux développeurs de créer facilement une variété de types. de jeu. Cet article vous aidera à apprendre Pygame à partir de zéro et fournira un didacticiel complet d'installation et de configuration, ainsi que des exemples de code spécifiques pour vous permettre de démarrer rapidement. Première partie : Installer Python et Pygame Tout d'abord, assurez-vous d'avoir
 Quelle configuration est requise pour exécuter la CAO en douceur ?
Jan 01, 2024 pm 07:17 PM
Quelle configuration est requise pour exécuter la CAO en douceur ?
Jan 01, 2024 pm 07:17 PM
Quelles configurations sont nécessaires pour utiliser la CAO de manière fluide ? Pour utiliser le logiciel de CAO de manière fluide, vous devez répondre aux exigences de configuration suivantes : Configuration requise du processeur : Pour exécuter "Word Play Flowers" de manière fluide, vous devez être équipé d'au moins un processeur Intel Corei5 ou Processeur AMD Ryzen5 ou supérieur. Bien entendu, si vous choisissez un processeur plus performant, vous pourrez obtenir des vitesses de traitement plus rapides et de meilleures performances. La mémoire est un composant très important de l’ordinateur. Elle a un impact direct sur les performances et l’expérience utilisateur de l’ordinateur. De manière générale, nous recommandons au moins 8 Go de mémoire, ce qui peut répondre aux besoins de la plupart des utilisations quotidiennes. Cependant, pour de meilleures performances et une expérience d'utilisation plus fluide, il est recommandé de choisir une configuration de mémoire de 16 Go ou plus. Cela garantit que le
 Apprenez la fonction principale du langage Go à partir de zéro
Mar 27, 2024 pm 05:03 PM
Apprenez la fonction principale du langage Go à partir de zéro
Mar 27, 2024 pm 05:03 PM
Titre : Apprenez la fonction principale du langage Go à partir de zéro. En tant que langage de programmation simple et efficace, le langage Go est privilégié par les développeurs. Dans le langage Go, la fonction principale est une fonction d'entrée, et chaque programme Go doit contenir la fonction principale comme point d'entrée du programme. Cet article explique comment apprendre la fonction principale du langage Go à partir de zéro et fournit des exemples de code spécifiques. 1. Tout d’abord, nous devons installer l’environnement de développement du langage Go. Vous pouvez aller sur le site officiel (https://golang.org
 Apprenez rapidement l'installation de pip et maîtrisez les compétences à partir de zéro
Jan 16, 2024 am 10:30 AM
Apprenez rapidement l'installation de pip et maîtrisez les compétences à partir de zéro
Jan 16, 2024 am 10:30 AM
Apprenez l'installation de pip à partir de zéro et maîtrisez rapidement les compétences. Des exemples de code spécifiques sont nécessaires. Présentation : pip est un outil de gestion de packages Python qui peut facilement installer, mettre à niveau et gérer les packages Python. Pour les développeurs Python, il est très important de maîtriser les compétences d'utilisation de pip. Cet article présentera la méthode d'installation de pip à partir de zéro et donnera quelques conseils pratiques et exemples de code spécifiques pour aider les lecteurs à maîtriser rapidement l'utilisation de pip. 1. Installer pip Avant d'utiliser pip, vous devez d'abord installer pip. pépin