

Supposons que nous venions de regarder le blockbuster de Nolan « Interstellar ». Comment pouvons-nous laisser une machine analyser automatiquement si l'évaluation du film par le public est « positive » ou « négative » ? Ce type de problème est un problème d’analyse des sentiments. La première étape pour résoudre ce type de problème consiste à convertir le texte en fonctionnalités. Cet article présente principalement en détail l'algorithme d'extraction et de vectorisation des fonctionnalités de texte. Il a une certaine valeur de référence. J'espère que cela pourra aider tout le monde.
Par conséquent, dans ce chapitre, nous n'apprenons que la première étape, comment extraire des fonctionnalités du texte et les vectoriser.
Étant donné que le traitement du chinois implique une segmentation de mots, cet article utilise un exemple simple pour illustrer comment utiliser la bibliothèque d'apprentissage automatique de Python pour extraire des fonctionnalités de l'anglais.
1. Préparation des données
sklearn.datasets de Python prend en charge la lecture de tous les textes classifiés du répertoire. Cependant, les répertoires doivent être placés selon les règles d'un dossier et d'un nom d'étiquette. Par exemple, l'ensemble de données utilisé dans cet article comporte un total de 2 étiquettes, l'une est « net » et l'autre est « pos », et il y a 6 fichiers texte sous chaque répertoire. Le répertoire est le suivant :
neg
1.txt
2.txt
......
pos
1.txt
2.txt
....
Le contenu des 12 fichiers est résumé comme suit :
neg: shit. waste my money. waste of money. sb movie. waste of time. a shit movie. pos: nb! nb movie! nb! worth my money. I love this movie! a nb movie. worth it!
2. Caractéristiques du texte
Comment extraire les attitudes émotionnelles de ces mots anglais et les classer ?
La manière la plus intuitive est d'extraire des mots. On pense généralement que de nombreux mots-clés peuvent refléter l’attitude de l’orateur. Par exemple, dans l’ensemble de données simple ci-dessus, il est facile de constater que tout ce qui dit « merde » doit appartenir à la catégorie négative.
Bien sûr, l'ensemble de données ci-dessus est simplement conçu pour faciliter la description. En réalité, un mot a souvent des attitudes ambiguës. Mais il y a encore des raisons de croire que plus un mot apparaît dans la catégorie négative, plus grande est la probabilité qu'il exprime l'attitude négative.
Nous remarquons également que certains mots n'ont aucun sens pour la classification des sentiments. Par exemple, des mots tels que « de » et « je » dans les données ci-dessus. Ce type de mot a un nom, "Stop_Word" (mot vide). De tels mots peuvent être complètement ignorés et ne pas compter. Évidemment, en ignorant ces mots, l'espace de stockage des enregistrements de fréquence de mots peut être optimisé et la vitesse de construction est plus rapide.
Il y a également un problème à prendre la fréquence des mots de chaque mot comme une caractéristique importante. Par exemple, « film » dans les données ci-dessus apparaît 5 fois sur 12 échantillons, mais le nombre d'occurrences positives et négatives est presque le même et il n'y a aucune distinction. Et « valeur » apparaît deux fois, mais uniquement dans la catégorie pos. Il a évidemment une couleur forte, c'est-à-dire que la distinction est très élevée.
Par conséquent, nous devons introduire TF-IDF (Fréquence des termes-Fréquence inverse des documents, Fréquence des termes et fréquence inverse des documents ) pour examiner plus en détail chaque mot .
TF (fréquence du terme) Le calcul de est très simple, c'est-à-dire, pour un document t, la fréquence d'un certain mot Nt apparaissant dans le document. Par exemple, dans le document « J'adore ce film », le TF du mot « amour » est de 1/4. Si vous supprimez les mots vides « je » et « il », c'est 1/2.
IDF (Inverse File Frequency) signifie que pour un certain mot t, le nombre de documents Dt dans lesquels le mot apparaît représente la proportion de tous les documents de test D. Alors trouver le logarithme népérien.
Par exemple, le mot « film » apparaît 5 fois au total, et le nombre total de documents est de 12, donc l'IDF est ln(5/12).
Évidemment, IDF vise à mettre en valeur les mots qui apparaissent rarement mais qui ont une forte couleur émotionnelle. Par exemple, l'IDF d'un mot comme « film » est ln(12/5)=0,88, ce qui est beaucoup plus petit que l'IDF de « love »=ln(12/1)=2,48.
TF-IDF multiplie simplement les deux ensemble. De cette façon, trouver le TF-IDF de chaque mot dans chaque document est la valeur de la caractéristique du texte que nous avons extraite.
3. Vectorisation
Avec la base ci-dessus, le document peut être vectorisé. Regardons d'abord le code, puis analysons le sens de la vectorisation :
# -*- coding: utf-8 -*-
import scipy as sp
import numpy as np
from sklearn.datasets import load_files
from sklearn.cross_validation import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
'''''加载数据集,切分数据集80%训练,20%测试'''
movie_reviews = load_files('endata')
doc_terms_train, doc_terms_test, y_train, y_test\
= train_test_split(movie_reviews.data, movie_reviews.target, test_size = 0.3)
'''''BOOL型特征下的向量空间模型,注意,测试样本调用的是transform接口'''
count_vec = TfidfVectorizer(binary = False, decode_error = 'ignore',\
stop_words = 'english')
x_train = count_vec.fit_transform(doc_terms_train)
x_test = count_vec.transform(doc_terms_test)
x = count_vec.transform(movie_reviews.data)
y = movie_reviews.target
print(doc_terms_train)
print(count_vec.get_feature_names())
print(x_train.toarray())
print(movie_reviews.target)运行结果如下:
[b'waste of time.', b'a shit movie.', b'a nb movie.', b'I love this movie!', b'shit.', b'worth my money.', b'sb movie.', b'worth it!']
['love', 'money', 'movie', 'nb', 'sb', 'shit', 'time', 'waste', 'worth']
[[ 0. 0. 0. 0. 0. 0. 0.70710678 0.70710678 0. ]
[ 0. 0. 0.60335753 0. 0. 0.79747081 0. 0. 0. ]
[ 0. 0. 0.53550237 0.84453372 0. 0. 0. 0. 0. ]
[ 0.84453372 0. 0.53550237 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 1. 0. 0. 0. ]
[ 0. 0.76642984 0. 0. 0. 0. 0. 0. 0.64232803]
[ 0. 0. 0.53550237 0. 0.84453372 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 1. ]]
[1 1 0 1 0 1 0 1 1 0 0 0]
python输出的比较混乱。我这里做了一个表格如下:
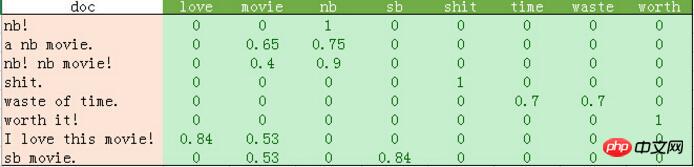
从上表可以发现如下几点:
1、停用词的过滤。
初始化count_vec的时候,我们在count_vec构造时传递了stop_words = 'english',表示使用默认的英文停用词。可以使用count_vec.get_stop_words()查看TfidfVectorizer内置的所有停用词。当然,在这里可以传递你自己的停用词list(比如这里的“movie”)
2、TF-IDF的计算。
这里词频的计算使用的是sklearn的TfidfVectorizer。这个类继承于CountVectorizer,在后者基本的词频统计基础上增加了如TF-IDF之类的功能。
我们会发现这里计算的结果跟我们之前计算不太一样。因为这里count_vec构造时默认传递了max_df=1,因此TF-IDF都做了规格化处理,以便将所有值约束在[0,1]之间。
3. Le résultat de count_vec.fit_transform est une énorme matrice. Nous pouvons voir qu'il y a beaucoup de 0 dans le tableau ci-dessus, donc sklearn utilise une matrice clairsemée pour son implémentation interne. Les données de cet exemple sont petites. Si les lecteurs sont intéressés, vous pouvez essayer des données réelles utilisées par des chercheurs en apprentissage automatique de l'Université Cornell : http://www.cs.cornell.edu/people/pabo/movie-review-data/. Ce site Web fournit de nombreux ensembles de données, dont plusieurs bases de données d'environ 2 millions, avec environ 700 exemples positifs et négatifs. L'échelle de ce type de données n'est pas grande et peut toujours être complétée en 1 minute, je vous suggère de l'essayer. Cependant, sachez que ces ensembles de données peuvent présenter des problèmes de caractère illégal. Ainsi, lors de la construction de count_vec, decode_error = 'ignore' est transmis pour ignorer ces caractères illégaux.
Les résultats du tableau ci-dessus sont les résultats de la formation de 8 fonctionnalités sur 8 échantillons. Ce résultat peut être classé à l'aide de divers algorithmes de classification.
Recommandations associées :
Partagez un exemple de code QR de génération de texte Python
Explication détaillée de la distance d'édition pour le calcul de similarité de texte Python
Exemple détaillé de la façon de capturer des images de pages Web simples en Python
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



