

Blocage MySQL et analyse des journaux

Cet article vous parle principalement du blocage et des journaux MySQL. Comment localiser rapidement les problèmes MySQL en ligne et corriger les exceptions dans les affaires réelles ? Cet article partage des expériences et des méthodes pertinentes basées sur deux cas réels. Les amis intéressés peuvent s'y référer. J'espère que cela pourra aider tout le monde.
Récemment, plusieurs anomalies de données se sont produites dans MySQL en ligne, toutes survenues tôt le matin. Étant donné que le scénario commercial est une application typique d'entrepôt de données, la pression pendant la journée est faible et ne peut pas être reproduite. Certaines anomalies sont même étranges et l’analyse finale des causes profondes est assez difficile. Alors, comment pouvons-nous localiser rapidement les problèmes MySQL en ligne et corriger les exceptions dans les affaires réelles ? Ci-dessous, je partagerai des expériences et des méthodes pertinentes basées sur deux cas réels.
Cas 1 : Une partie de la mise à jour des données a échoué
Un jour, des camarades de classe de la chaîne ont signalé que très peu de données de chaîne dans un certain rapport était 0. La plupart des données de canal sont normales. Ces données sont régulièrement mises à jour par un programme statistique chaque matin. Il va de soi que soit tout est normal, soit tout échoue. Alors, quelle pourrait être la raison de l'anomalie de quelques données individuelles ?
Tout d'abord, la première chose à laquelle nous pouvons penser est de regarder le journal des tâches de statistiques, mais après avoir regardé le journal imprimé par le programme de statistiques, nous n'avons trouvé aucune description anormale telle qu'un échec de la mise à jour SQL. . Alors que s’est-il passé exactement dans la base de données à ce moment-là ? Avant de vérifier le journal du serveur MySQL, j'avais l'habitude de regarder l'état de la base de données :

Il m'est arrivé de constater un blocage dans cette mise à jour tôt le matin :
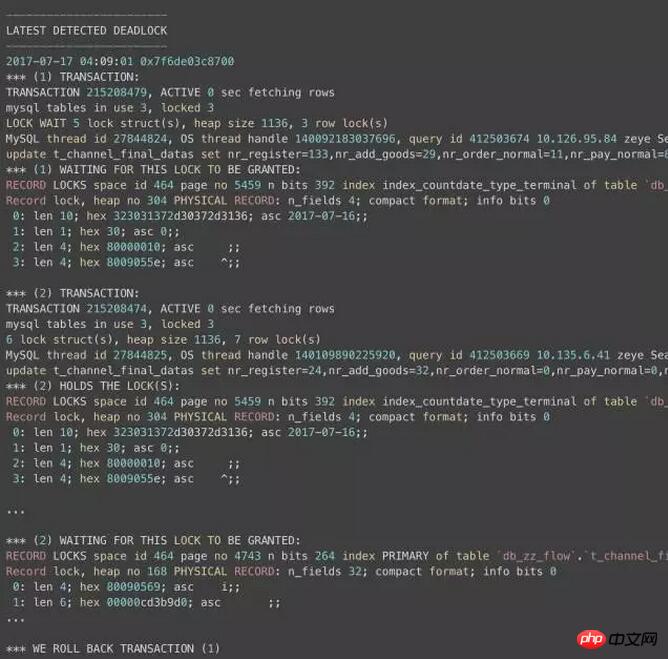
En raison du manque d'espace, j'ai omis beaucoup de contexte ici. Comme vous pouvez le voir sur ce journal, TRANSACTION 1 et TRANSACTION 2 détiennent chacune un certain nombre de verrous de ligne, puis attendent. Finalement, MySQL a détecté un blocage et a ensuite choisi d'annuler la TRANSACTION 1 : la méthode actuelle d'Innodb pour gérer les blocages consiste à annuler la transaction détenant le verrou exclusif au niveau de la ligne le plus faible.
Ensuite, il y a 3 questions ici :
1. Le verrouillage de ligne innodb ne verrouille-t-il qu'une seule ligne ?
Étant donné que cette table provient du moteur innodb, InnoDB prend en charge les verrous de ligne et les verrous de table. Les verrous de ligne InnoDB sont implémentés en verrouillant les entrées d'index sur l'index. Ceci est différent de MySQL et Oracle, qui sont implémentés en verrouillant les lignes de données correspondantes dans le bloc de données. La fonctionnalité d'implémentation du verrouillage de ligne d'InnoDB signifie qu'InnoDB utilise des verrous au niveau de la ligne uniquement lorsque les données sont récupérées via des conditions d'index. Sinon, InnoDB utilisera des verrous de table et verrouillera toutes les lignes analysées ! Dans les applications pratiques, une attention particulière doit être accordée à cette fonctionnalité des verrous de ligne InnoDB, sinon elle peut provoquer un grand nombre de conflits de verrouillage, affectant ainsi les performances de concurrence. Étant donné que le verrou de ligne de MySQL est un verrou pour l'index, pas pour l'enregistrement, même si les enregistrements de lignes différentes sont accessibles, si la même clé d'index est utilisée, un conflit de verrouillage se produira. Lorsque nous utilisons des conditions de plage au lieu de conditions d'égalité pour récupérer des données et demander des verrous partagés ou exclusifs, InnoDB verrouillera les entrées d'index des enregistrements de données existants qui répondent aux conditions. De plus, les verrous d'espacement verrouilleront également plusieurs lignes. conditions de plage mais verrouillez également plusieurs lignes. En plus d'utiliser des verrous d'espacement lors du verrouillage, si vous utilisez des conditions égales pour demander le verrouillage d'un enregistrement qui n'existe pas, InnoDB utilisera également des verrous d'espacement !
Cela dit, jetons un oeil à l'index de notre table business :
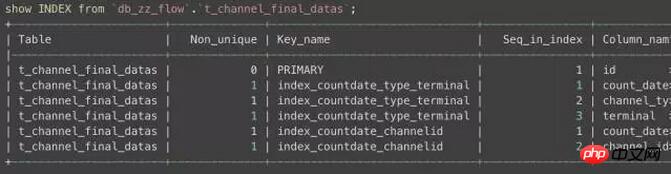
Vous voyez que l'index de cette table est extrêmement déraisonnable : Il existe 3 index, mais la mise à jour n'utilise pas complètement l'index. Par conséquent, la mise à jour n'utilise pas l'index avec précision et doit verrouiller les données de plage à plusieurs lignes, provoquant ainsi un blocage.
Après avoir connu le principe, nous pouvons soigneusement construire un index combiné à quatre champs afin que la mise à jour puisse utiliser avec précision l'index innodb. En fait, après avoir mis à jour l'index, ce problème de blocage est résolu.
Remarque : innodb imprimera non seulement les transactions et les verrous détenus et attendus par les transactions, mais également les enregistrements eux-mêmes, qui malheureusement, il peut dépasser la longueur réservée par innodb pour le résultat de sortie (seul 1 million de contenus peuvent être imprimés et seules les informations de blocage les plus récentes peuvent être conservées. Si vous ne pouvez pas voir la sortie complète, vous pouvez créer une table innodb_monitor ou innodb_lock_monitor sous n'importe quelle bibliothèque). à ce moment-là, les informations sur l'état d'Innodb seront complètes et enregistrées dans le journal des erreurs toutes les 15 secondes. Par exemple : créez la table innodb_monitor(a int)engine=innodb;, supprimez simplement la table lorsqu'il n'est pas nécessaire de l'enregistrer dans le journal des erreurs.
2. Pourquoi seules certaines instructions de mise à jour échouent lors de la restauration ?
Lors de la restauration, pourquoi seules certaines instructions de mise à jour échouent-elles au lieu de toutes les mises à jour de la transaction entière ?
C'est parce que notre innodb est automatiquement soumis par défaut :
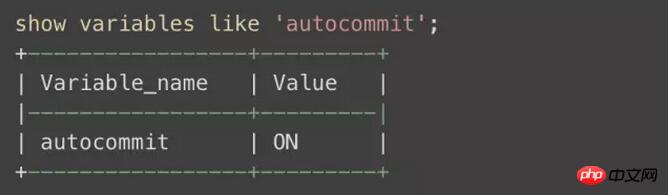
Dans le cas de plusieurs instructions de mise à jour ou d'insertion, après l'exécution de chaque SQL, innodb s'engagera immédiatement une fois pour conserver les modifications et libérer le verrou en même temps. C'est pourquoi dans cet exemple, il n'y a que quelques instructions. après la transaction d'annulation de blocage. Raison de l'échec.
Il convient de noter qu'il existe généralement une autre situation qui peut également entraîner l'annulation de certaines déclarations, ce qui nécessite une attention particulière. Il y a un paramètre dans innodb appelé : innodb_rollback_on_timeout
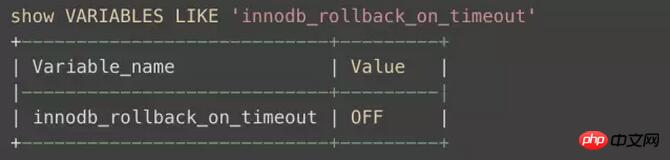
Le manuel officiel le décrit comme ceci :
Dans MySQL 5.1, InnoDB roule ne renvoie que la dernière instruction lors d'un délai d'expiration de transaction par défaut. Si –innodb_rollback_on_timeout est spécifié, un délai d'attente de transaction provoque l'abandon et l'annulation de la transaction entière par InnoDB (le même comportement que dans MySQL 4.1). Cette variable a été ajoutée dans MySQL 5.1.15. .
Explication : Si ce paramètre est désactivé ou n'existe pas, seule la dernière requête de la transaction sera annulée si un délai d'attente se produit. S'il est activé, l'intégralité de la transaction sera annulée si. la transaction rencontre un délai d'attente.
3. Comment réduire la probabilité de blocage d'Innodb ?
Les blocages sont difficiles à éliminer complètement dans les scénarios de verrouillage de ligne et de transaction, mais les conflits de verrouillage et les blocages peuvent être réduits grâce à la conception de tables et à l'ajustement SQL, notamment :
Utilisez autant que possible Niveau d'isolement inférieur, par exemple, si un verrouillage d'espacement se produit, vous pouvez modifier le niveau d'isolement de transaction de la session ou de la transaction au niveau RC (lecture validée) pour l'éviter, mais à ce stade, vous devez définir binlog_format sur ligne ou mixte. formater
Concevez soigneusement les index et essayez d'utiliser des index pour accéder aux données afin de rendre le verrouillage plus précis, réduisant ainsi le risque de conflits de verrouillage
Choisissez une taille de transaction raisonnable et la probabilité de conflits de verrouillage ; pour les petites transactions, il sera plus petit ;
Lorsque l'affichage verrouille l'ensemble d'enregistrements, il est préférable de demander un niveau de verrouillage suffisant en même temps. Par exemple, si vous souhaitez modifier des données, il est préférable de demander directement un verrou exclusif au lieu de demander d'abord un verrou partagé, puis de demander un verrou exclusif lors de la modification. Cela peut facilement provoquer un blocage
Quand. différents programmes accèdent à un groupe de tables, essayez de Il est convenu d'accéder à chaque table dans le même ordre Pour une table, les lignes du tableau doivent être accessibles dans un ordre fixe autant que possible. Cela peut réduire considérablement le risque de blocage ;
Essayez d'utiliser des conditions égales pour accéder aux données, afin d'éviter l'impact des verrouillages d'espacement sur l'insertion simultanée
Ne demandez pas de niveau de verrouillage ; cela dépasse le besoin réel ; sauf si cela est nécessaire, n'affichez pas le verrouillage lors de l'interrogation
Pour certaines transactions spécifiques, les verrous de table peuvent être utilisés pour augmenter la vitesse de traitement ou réduire le risque de blocage.
Cas 2 : Délai d'attente de verrouillage bizarre
Il y a 6h du matin et 8h du matin pendant plusieurs jours consécutifs. a échoué et une exception Java SQL de délai d'attente de verrouillage dépassé, essayez de redémarrer la transaction innodb a été signalée lors du chargement du fichier local de données. Après avoir communiqué avec nos camarades de classe sur la plate-forme, nous avons appris qu'il s'agissait d'un problème de temps de verrouillage trop court ou d'un conflit de verrouillage dans notre. propre base de données d'entreprise. Mais quand on y repense, n’est-ce pas ? N'est-ce pas toujours bon ? De plus, il s’agit essentiellement de tâches à forme unique et il n’y a pas de conflit entre plusieurs personnes.
Peu importe de qui il s'agit, vérifions d'abord s'il y a un problème avec notre base de données :
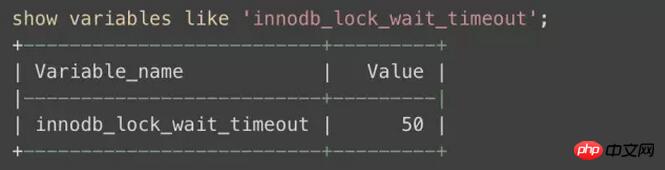
Le délai d'expiration de verrouillage par défaut est de 50 secondes, ce qui est vraiment pas court. Ça ne sert probablement à rien de l'ajuster. En fait, c'est vrai que ça n'a pas marché après l'avoir essayé comme un cheval mort. . .
Et cette fois, SHOW ENGINE INNODB STATUSG n'a montré aucune information de blocage. Ensuite, j'ai porté mon attention sur le journal du serveur MySQL, dans l'espoir de voir dans le journal quelles opérations les données effectuaient avant et après ce moment. Voici une brève introduction à la composition du système de fichiers journaux MySQL :
(a) journal des erreurs : enregistre les problèmes qui surviennent lors du démarrage, de l'exécution ou de l'arrêt de mysqld, activé par défaut.
(b) Journal général : journal général des requêtes, qui enregistre toutes les instructions et instructions. Il y aura une perte de performances d'environ 5 % lors de l'ouverture de la base de données.
(c) journal binlog : format binaire, enregistre toutes les instructions qui modifient les données, principalement utilisées pour la réplication esclave et la récupération de données.
(d) journal lent : enregistre toutes les requêtes qui prennent plus de long_query_time secondes à s'exécuter ou les requêtes qui n'utilisent pas d'index, fermées par défaut.
(e) Journal Innodb : journal redo innodb, journal d'annulation, utilisé pour restaurer les données et annuler les opérations.
Comme vous pouvez le voir dans l'introduction ci-dessus, les journaux actuels pour ce problème peuvent être dans d et b. S'il n'y a pas de connexion dans d, vous ne pouvez activer que b, mais b aura une certaine perte. sur les performances de la base de données, car il s'agit d'un journal complet, le volume est très énorme, il faut donc être prudent lors de son ouverture :
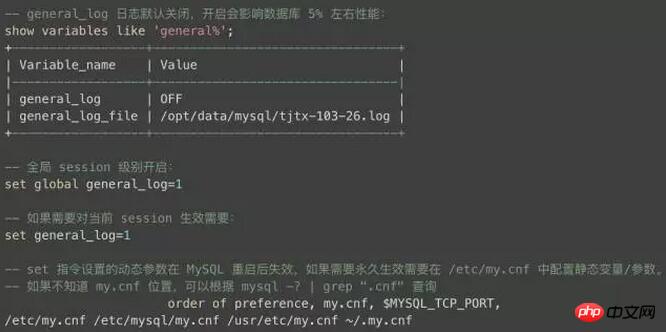
Je n'ai ouvert que le complet. Connectez-vous une demi-heure avant et après que le problème se soit produit chaque jour et n'avez rien trouvé. Aucune demande de client MySQL à notre base de données professionnelle ! Le format du journal est le suivant, enregistrant toutes les connexions et commandes :
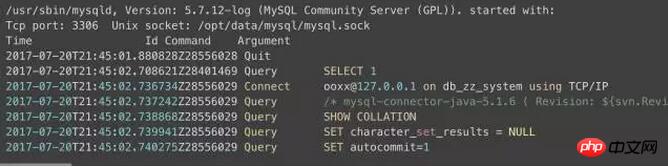
Le problème est essentiellement confirmé. L'exception ci-dessus a été levée avant que la demande du client ne nous parvienne. Après des communications et des confirmations répétées avec la plateforme, la plateforme a finalement vérifié que c'était parce qu'elle devait démarrer la tâche SQL avant d'exécuter l'insertion. . La table a récupéré SQL et mis à jour l'état de la tâche. En conséquence, cette table avait un grand nombre d'insertions et de mises à jour simultanées à l'heure, provoquant l'expiration du délai d'attente de certains SQL en attendant le verrouillage. . .
Script d'analyse des journaux MySQL
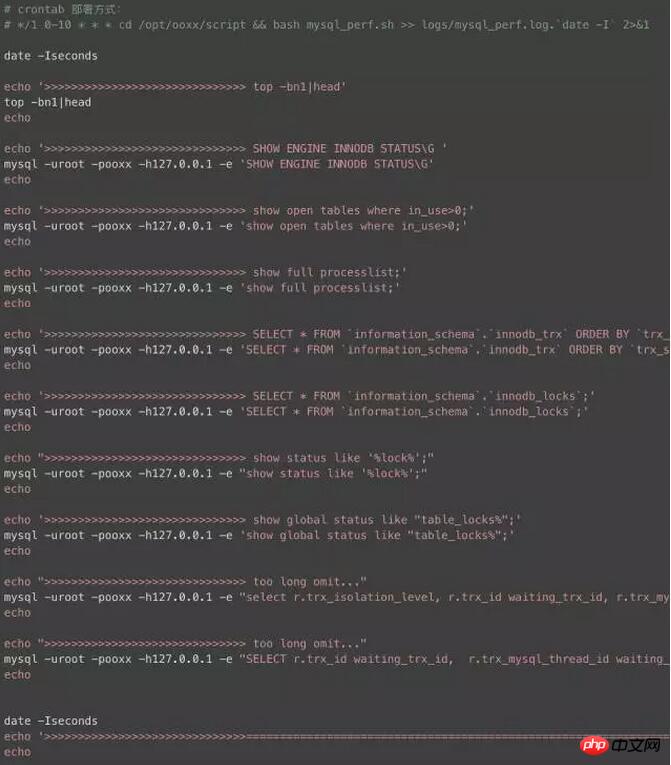
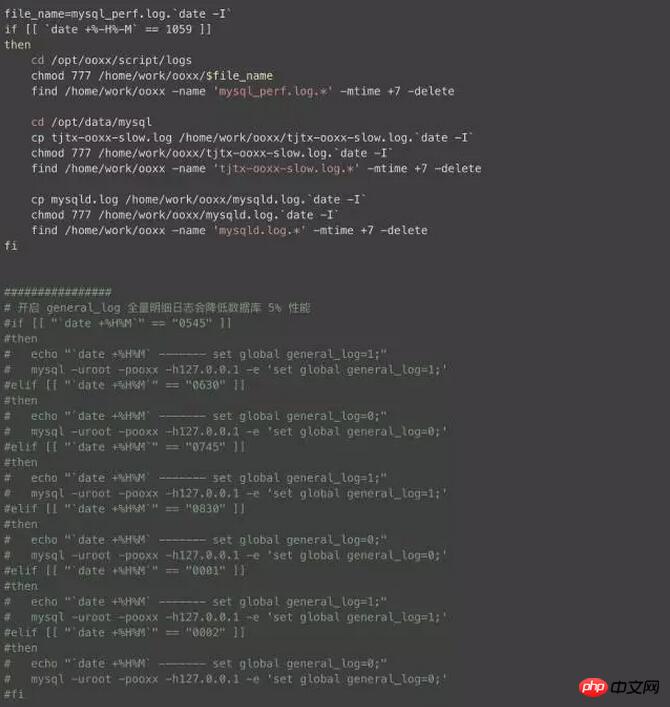
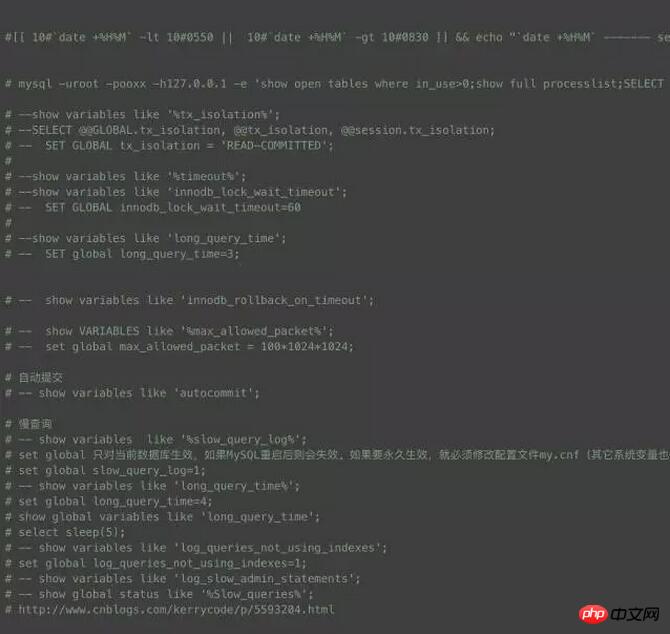
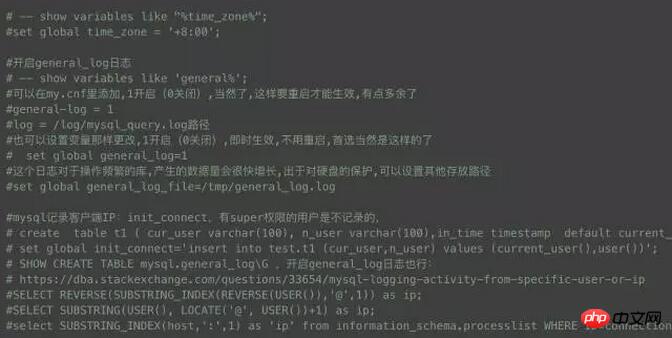
Étant donné que tôt le matin est le pic d'activité de l'entrepôt de données, de nombreux problèmes surviennent à ce moment-là, et certains problèmes étranges passent souvent par là village Ce magasin n'existe plus et ne peut être restauré en journée. Comment capturer les journaux qui nous intéressent pour localiser rapidement le problème est la priorité absolue. Ici, j'ai écrit un petit script, le déploiement de crontab, vous pouvez choisir la plage de temps à ouvrir, échantillonner le journal toutes les minutes, ce qui doit être expliqué, c'est le journal général Ne l'allumez pas facilement, sinon cela causerait de gros dommages aux performances de la base de données.
Recommandations associées :
Le concept et les conditions du blocage
Partage d'une méthode pour résoudre le problème de blocage MySQL
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
Dans la base de données MySQL, la relation entre l'utilisateur et la base de données est définie par les autorisations et les tables. L'utilisateur a un nom d'utilisateur et un mot de passe pour accéder à la base de données. Les autorisations sont accordées par la commande Grant, tandis que le tableau est créé par la commande Create Table. Pour établir une relation entre un utilisateur et une base de données, vous devez créer une base de données, créer un utilisateur, puis accorder des autorisations.
 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Simplification de l'intégration des données: AmazonrDSMysQL et l'intégration Zero ETL de Redshift, l'intégration des données est au cœur d'une organisation basée sur les données. Les processus traditionnels ETL (extrait, converti, charge) sont complexes et prennent du temps, en particulier lors de l'intégration de bases de données (telles que AmazonrDSMysQL) avec des entrepôts de données (tels que Redshift). Cependant, AWS fournit des solutions d'intégration ETL Zero qui ont complètement changé cette situation, fournissant une solution simplifiée et à temps proche pour la migration des données de RDSMySQL à Redshift. Cet article plongera dans l'intégration RDSMYSQL ZERO ETL avec Redshift, expliquant comment il fonctionne et les avantages qu'il apporte aux ingénieurs de données et aux développeurs.
 Comment remplir le nom d'utilisateur MySQL et le mot de passe
Apr 08, 2025 pm 07:09 PM
Comment remplir le nom d'utilisateur MySQL et le mot de passe
Apr 08, 2025 pm 07:09 PM
Pour remplir le nom d'utilisateur et le mot de passe MySQL: 1. Déterminez le nom d'utilisateur et le mot de passe; 2. Connectez-vous à la base de données; 3. Utilisez le nom d'utilisateur et le mot de passe pour exécuter des requêtes et des commandes.
 L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
1. Utilisez l'index correct pour accélérer la récupération des données en réduisant la quantité de données numérisées SELECT * FROMMLOYEESEESHWHERELAST_NAME = 'SMITH'; Si vous recherchez plusieurs fois une colonne d'une table, créez un index pour cette colonne. If you or your app needs data from multiple columns according to the criteria, create a composite index 2. Avoid select * only those required columns, if you select all unwanted columns, this will only consume more server memory and cause the server to slow down at high load or frequency times For example, your table contains columns such as created_at and updated_at and timestamps, and then avoid selecting * because they do not require inefficient query se
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Comment copier et coller Mysql
Apr 08, 2025 pm 07:18 PM
Comment copier et coller Mysql
Apr 08, 2025 pm 07:18 PM
Copier et coller dans MySQL incluent les étapes suivantes: Sélectionnez les données, copiez avec Ctrl C (Windows) ou CMD C (Mac); Cliquez avec le bouton droit à l'emplacement cible, sélectionnez Coller ou utilisez Ctrl V (Windows) ou CMD V (Mac); Les données copiées sont insérées dans l'emplacement cible ou remplacer les données existantes (selon que les données existent déjà à l'emplacement cible).
