
 développement back-end
tutoriel php
Explication détaillée du tri par tas de l'algorithme de tri PHP
développement back-end
tutoriel php
Explication détaillée du tri par tas de l'algorithme de tri PHP
Explication détaillée du tri par tas de l'algorithme de tri PHP

Cet article présente principalement en détail l'algorithme Heap Sort implémenté en PHP. Il a une certaine valeur de référence. Les amis intéressés peuvent s'y référer. J'espère qu'il pourra aider tout le monde.
Introduction à l'algorithme :
Ici, je cite directement le début de "Dahua Data Structure" :
Comme mentionné précédemment, le tri par sélection simple, il sélectionne le plus petit enregistrement parmi les n enregistrements à trier nécessite n - 1 comparaisons. Il est normal de trouver les premières données et de devoir les comparer plusieurs fois. Sinon, comment savoir qu'il s'agit du plus petit enregistrement.
Malheureusement, cette opération ne sauvegarde pas les résultats de comparaison de chaque voyage. Les résultats de comparaison dans ce dernier voyage sont plus lourds. De nombreuses comparaisons ont été effectuées lors du voyage précédent, mais en raison du voyage précédent, ces résultats de comparaison ont été. non sauvegardés lors du tri, ces opérations de comparaison ont donc été répétées lors de la passe de tri suivante, donc un plus grand nombre de comparaisons ont été enregistrées.
Si vous pouvez sélectionner le plus petit enregistrement à chaque fois et apporter les ajustements correspondants aux autres enregistrements en fonction des résultats de la comparaison, l'efficacité globale du tri sera très élevée. Le tri par tas est une amélioration par rapport au tri par sélection simple, et l'effet de cette amélioration est très évident.
Idée de base :
Avant d'introduire le tri par tas, commençons par présenter le tas :
La définition dans "Structure de données Dahua" : Heap It est un arbre binaire complet avec les propriétés suivantes : la valeur de chaque nœud est supérieure ou égale à la valeur de ses nœuds enfants gauche et droit, devenant un big top tas (big root tas) ou la valeur de chaque nœud est inférieure à ; ou égal à la valeur de ses nœuds gauche et droit, devenant Petit tas supérieur (petit tas de racines).
Quand j'ai vu cela, j'ai également eu des doutes quant à "si le tas est un arbre binaire complet". Il y a aussi des gens sur Internet qui disent que ce n'est pas un arbre binaire complet, mais que le tas soit ou non. est un arbre binaire complet, je réserve quand même mon avis. Il faut seulement savoir que nous utilisons ici un grand tas racine (petit tas racine) sous la forme d'un arbre binaire complet, principalement pour faciliter le stockage et le calcul (nous verrons la commodité plus tard).
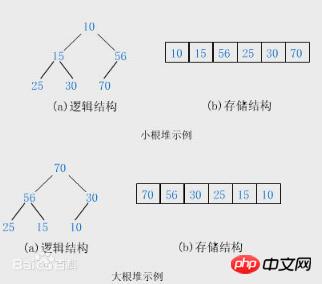
Algorithme de tri par tas :
Le tri par tas est une méthode de tri utilisant un tas (en supposant qu'il s'agit d'un grand tas racine). basic L'idée est la suivante : construire la séquence à trier dans un grand tas racine. À ce stade, la valeur maximale de la séquence entière est le nœud racine en haut du tas. Supprimez-le (en fait, échangez-le avec le dernier élément du tableau de tas, auquel moment le dernier élément est la valeur maximale), puis reconstruisez les n - 1 séquences restantes dans un tas, de sorte que vous obteniez les n éléments La prochaine plus petite valeur. Si vous exécutez ceci à plusieurs reprises, vous pouvez obtenir une séquence ordonnée.
Opérations de base de l'algorithme de tri du tas de grandes racines :
① Construire un tas La construction d'un tas est un processus d'ajustement constant du tas, en commençant par len/2 et en allant jusqu'au tas. premier nœud, ici len est le nombre d'éléments dans le tas. Le processus de construction d'un tas est un processus linéaire. Le processus d'ajustement du tas est toujours appelé de len/2 à 0, ce qui équivaut à o(h1) + o(h2) ... + o(hlen/2) où h représente la profondeur du nœud, len /2 représente le nombre de nœuds. Il s'agit d'un processus de sommation et le résultat est linéaire O(n).
②Tas d'ajustement : le tas d'ajustement sera utilisé dans le processus de construction du tas, et sera également utilisé dans le processus de tri du tas. L'idée est de comparer le nœud i avec ses nœuds enfants gauche(i) et droit(i), et de sélectionner le plus grand (ou le plus petit) des trois si la valeur la plus grande (la plus petite) n'est pas le nœud i mais l'un de ses nœuds enfants. , Là, le nœud i interagit avec le nœud, puis appelle le processus d'ajustement du tas. Il s'agit d'un processus récursif. La complexité temporelle du processus d'ajustement du tas est liée à la profondeur du tas. Il s'agit d'une opération de lgn car elle est ajustée dans le sens de la profondeur.
③Tri par tas : le tri par tas est effectué à l'aide des deux processus ci-dessus. La première consiste à construire un tas basé sur des éléments. Retirez ensuite le nœud racine du tas (généralement échangez-le avec le dernier nœud), continuez le processus d'ajustement du tas avec les premiers nœuds len-1, puis retirez le nœud racine jusqu'à ce que tous les nœuds aient été supprimés. La complexité temporelle du processus de tri du tas est O(nlgn). Parce que la complexité temporelle de la construction d'un tas est O(n) (un appel) ; la complexité temporelle de l'ajustement du tas est lgn, et elle est appelée n-1 fois, donc la complexité temporelle du tri du tas est O(nlgn).
Ce processus nécessite beaucoup de schémas pour comprendre clairement, mais je suis paresseux. . . . . .
Mise en œuvre de l'algorithme :
<?php
//堆排序(对简单选择排序的改进)
function swap(array &$arr,$a,$b){
$temp = $arr[$a];
$arr[$a] = $arr[$b];
$arr[$b] = $temp;
}
//调整 $arr[$start]的关键字,使$arr[$start]、$arr[$start+1]、、、$arr[$end]成为一个大根堆(根节点最大的完全二叉树)
//注意这里节点 s 的左右孩子是 2*s + 1 和 2*s+2 (数组开始下标为 0 时)
function HeapAdjust(array &$arr,$start,$end){
$temp = $arr[$start];
//沿关键字较大的孩子节点向下筛选
//左右孩子计算(我这里数组开始下标识 0)
//左孩子2 * $start + 1,右孩子2 * $start + 2
for($j = 2 * $start + 1;$j <= $end;$j = 2 * $j + 1){
if($j != $end && $arr[$j] < $arr[$j + 1]){
$j ++; //转化为右孩子
}
if($temp >= $arr[$j]){
break; //已经满足大根堆
}
//将根节点设置为子节点的较大值
$arr[$start] = $arr[$j];
//继续往下
$start = $j;
}
$arr[$start] = $temp;
}
function HeapSort(array &$arr){
$count = count($arr);
//先将数组构造成大根堆(由于是完全二叉树,所以这里用floor($count/2)-1,下标小于或等于这数的节点都是有孩子的节点)
for($i = floor($count / 2) - 1;$i >= 0;$i --){
HeapAdjust($arr,$i,$count);
}
for($i = $count - 1;$i >= 0;$i --){
//将堆顶元素与最后一个元素交换,获取到最大元素(交换后的最后一个元素),将最大元素放到数组末尾
swap($arr,0,$i);
//经过交换,将最后一个元素(最大元素)脱离大根堆,并将未经排序的新树($arr[0...$i-1])重新调整为大根堆
HeapAdjust($arr,0,$i - 1);
}
}
$arr = array(9,1,5,8,3,7,4,6,2);
HeapSort($arr);
var_dump($arr);Analyse de la complexité temporelle :
Tant que sa durée d'exécution est Temps passé sur les paires de construction initiales et examen répété de la pile de reconstruction.
Dans l'ensemble, la complexité temporelle du tri par tas est O(nlogn). Étant donné que le tri par tas n'est pas sensible à l'état de tri des enregistrements d'origine, sa complexité temporelle meilleure, pire et moyenne est O(nlogn). C'est évidemment bien meilleur en termes de performances que la complexité temporelle O(n^2) du bouillonnement, de la sélection simple et de l'insertion directe.
Recommandations associées :
Explication détaillée du tri par sélection directe des séries d'algorithmes de tri PHP
Explication détaillée du tri par fusion de l'algorithme de tri PHP
Explication détaillée du tri par bucket de l'algorithme de tri PHP series_php skills
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Guide d'installation et de mise à niveau de PHP 8.4 pour Ubuntu et Debian
Dec 24, 2024 pm 04:42 PM
Guide d'installation et de mise à niveau de PHP 8.4 pour Ubuntu et Debian
Dec 24, 2024 pm 04:42 PM
PHP 8.4 apporte plusieurs nouvelles fonctionnalités, améliorations de sécurité et de performances avec une bonne quantité de dépréciations et de suppressions de fonctionnalités. Ce guide explique comment installer PHP 8.4 ou mettre à niveau vers PHP 8.4 sur Ubuntu, Debian ou leurs dérivés. Bien qu'il soit possible de compiler PHP à partir des sources, son installation à partir d'un référentiel APT comme expliqué ci-dessous est souvent plus rapide et plus sécurisée car ces référentiels fourniront les dernières corrections de bogues et mises à jour de sécurité à l'avenir.
 7 fonctions PHP que je regrette de ne pas connaître auparavant
Nov 13, 2024 am 09:42 AM
7 fonctions PHP que je regrette de ne pas connaître auparavant
Nov 13, 2024 am 09:42 AM
Si vous êtes un développeur PHP expérimenté, vous aurez peut-être le sentiment d'y être déjà allé et de l'avoir déjà fait. Vous avez développé un nombre important d'applications, débogué des millions de lignes de code et peaufiné de nombreux scripts pour réaliser des opérations.
 Comment configurer Visual Studio Code (VS Code) pour le développement PHP
Dec 20, 2024 am 11:31 AM
Comment configurer Visual Studio Code (VS Code) pour le développement PHP
Dec 20, 2024 am 11:31 AM
Visual Studio Code, également connu sous le nom de VS Code, est un éditeur de code source gratuit – ou environnement de développement intégré (IDE) – disponible pour tous les principaux systèmes d'exploitation. Avec une large collection d'extensions pour de nombreux langages de programmation, VS Code peut être c
 Expliquez les jetons Web JSON (JWT) et leur cas d'utilisation dans les API PHP.
Apr 05, 2025 am 12:04 AM
Expliquez les jetons Web JSON (JWT) et leur cas d'utilisation dans les API PHP.
Apr 05, 2025 am 12:04 AM
JWT est une norme ouverte basée sur JSON, utilisée pour transmettre en toute sécurité des informations entre les parties, principalement pour l'authentification de l'identité et l'échange d'informations. 1. JWT se compose de trois parties: en-tête, charge utile et signature. 2. Le principe de travail de JWT comprend trois étapes: la génération de JWT, la vérification de la charge utile JWT et l'analyse. 3. Lorsque vous utilisez JWT pour l'authentification en PHP, JWT peut être généré et vérifié, et les informations sur le rôle et l'autorisation des utilisateurs peuvent être incluses dans l'utilisation avancée. 4. Les erreurs courantes incluent une défaillance de vérification de signature, l'expiration des jetons et la charge utile surdimensionnée. Les compétences de débogage incluent l'utilisation des outils de débogage et de l'exploitation forestière. 5. L'optimisation des performances et les meilleures pratiques incluent l'utilisation des algorithmes de signature appropriés, la définition des périodes de validité raisonnablement,
 Comment analysez-vous et traitez-vous HTML / XML dans PHP?
Feb 07, 2025 am 11:57 AM
Comment analysez-vous et traitez-vous HTML / XML dans PHP?
Feb 07, 2025 am 11:57 AM
Ce tutoriel montre comment traiter efficacement les documents XML à l'aide de PHP. XML (Language de balisage extensible) est un langage de balisage basé sur le texte polyvalent conçu à la fois pour la lisibilité humaine et l'analyse de la machine. Il est couramment utilisé pour le stockage de données et
 Programme PHP pour compter les voyelles dans une chaîne
Feb 07, 2025 pm 12:12 PM
Programme PHP pour compter les voyelles dans une chaîne
Feb 07, 2025 pm 12:12 PM
Une chaîne est une séquence de caractères, y compris des lettres, des nombres et des symboles. Ce tutoriel apprendra à calculer le nombre de voyelles dans une chaîne donnée en PHP en utilisant différentes méthodes. Les voyelles en anglais sont a, e, i, o, u, et elles peuvent être en majuscules ou en minuscules. Qu'est-ce qu'une voyelle? Les voyelles sont des caractères alphabétiques qui représentent une prononciation spécifique. Il y a cinq voyelles en anglais, y compris les majuscules et les minuscules: a, e, i, o, u Exemple 1 Entrée: String = "TutorialSpoint" Sortie: 6 expliquer Les voyelles dans la chaîne "TutorialSpoint" sont u, o, i, a, o, i. Il y a 6 yuans au total
 Expliquez la liaison statique tardive en PHP (statique: :).
Apr 03, 2025 am 12:04 AM
Expliquez la liaison statique tardive en PHP (statique: :).
Apr 03, 2025 am 12:04 AM
Liaison statique (statique: :) implémente la liaison statique tardive (LSB) dans PHP, permettant à des classes d'appel d'être référencées dans des contextes statiques plutôt que de définir des classes. 1) Le processus d'analyse est effectué au moment de l'exécution, 2) Recherchez la classe d'appel dans la relation de succession, 3) il peut apporter des frais généraux de performance.
 Quelles sont les méthodes PHP Magic (__construct, __ destruct, __ call, __get, __set, etc.) et fournir des cas d'utilisation?
Apr 03, 2025 am 12:03 AM
Quelles sont les méthodes PHP Magic (__construct, __ destruct, __ call, __get, __set, etc.) et fournir des cas d'utilisation?
Apr 03, 2025 am 12:03 AM
Quelles sont les méthodes magiques de PHP? Les méthodes magiques de PHP incluent: 1. \ _ \ _ Construct, utilisé pour initialiser les objets; 2. \ _ \ _ Destruct, utilisé pour nettoyer les ressources; 3. \ _ \ _ Appel, gérer les appels de méthode inexistants; 4. \ _ \ _ GET, Implémentez l'accès à l'attribut dynamique; 5. \ _ \ _ SET, Implémentez les paramètres d'attribut dynamique. Ces méthodes sont automatiquement appelées dans certaines situations, améliorant la flexibilité et l'efficacité du code.
