

Apprenez le didacticiel de base de données MySQL en une heure

Que savez-vous de la base de données MySQL ? Actuellement, un grand nombre de sites Web utilisent le langage PHP, qui correspond à la base de données MySQL. Je partagerai ici avec vous les connaissances pertinentes de la base de données MySQL, en espérant vous aider.
Table des matières
1. Présentation de la base de données
-
1.4.1. >
> - 1.4.2. Trois paradigmes majeurs
- 1.4.3 Paradigme et efficacité
- 1.3. .1. Base de données Type de relation
- 1.3.2, base de données non relationnelle
- 1.1.1, étape de traitement manuel
- 1.1.2. Système de fichiers
- 1.1.3. Système de gestion de base de données
- 1.1. >
- 1.3. Classification des bases de données
- 1.4. Standardisation des bases de données
- 2.2. Caractéristiques du système
- 2.3. Moteur de stockage
- .
- 3.1.2. Modifier le mot de passe de l'utilisateur MySQL
- . 3.1.2. Service d'installation
- 3.1, utilisez la version verte
- 3.2, utilisez la version d'installation
- . 4.5.2. Supprimer les données
- 4.5.3. Modifier la structure de la table
- 4.5.4. 🎜>
- 4.5.5. Clé unique
- 4.1. Concepts typiques des bases de données relationnelles
- 4.2. > 4.3. Créer une base de données
- 4.4, créer une table
- 4.5, gérer les données
- 4.6, utiliser l'ordinateur Exercices
- 5. Utiliser SQL pour accéder à la base de données MySQL
- 5.5.1. Ajouter des colonnes
- 5.5.3 Supprimer des colonnes
.
5.5.4. Renommer la table- 5.5.5, supprimer la table
- 5.5.6, supprimer la base de données
- 5.5.7, mille lignes de notes MySQL
- 5.5.8, SQL couramment utilisé
- 5.2.1, Expression et requête conditionnelle
- 5.2.2, fonction d'agrégation
- 5.0.1, créer une nouvelle base de données
- 5.0.2, créez une nouvelle table
- 5.0.3 Créez une nouvelle requête
- 5.0. . Définir la table étudiant Stu
- 5.1 Ajouter des données
- Requête de données
- . 5.3. Supprimer les données
- 5.4. Mettre à jour les données
- 5.5. >6. Télécharger le programme, l'aide, la vidéo
- Avec la fin de l'Internet mobile et l'arrivée de l'intelligence artificielle, le big data est devenu de plus en plus important. Le prochain gagnant devrait en être un. avec des données massives, vous devez connaître les données et les bases de données.
- 1. Présentation de la base de données
- La base de données est un système logiciel permettant de stocker et de gérer des données, tout comme un entrepôt logistique qui stocke des données. Dans le domaine des affaires, l'information est synonyme d'opportunités commerciales. Un moyen très important d'obtenir des informations est d'analyser et de traiter les données. Cela a donné naissance à divers logiciels professionnels de gestion de données, et la base de données en fait partie. Bien entendu, le système de gestion de bases de données n’a pas été créé d’un seul coup. Il a également fait l’objet d’un enrichissement et d’un développement continus pour devenir ce qu’il est aujourd’hui.
- 2.1, présentation de MySQL
- 3.1.1. Configurer l'accès à distance MySQL
- 4.5.1 Ajouter des données
- 5.5.2 Modifier des colonnes
1.1. Historique du développement
1.1.1 Étape de traitement manuel
Ordinateurs avant le milieu des années 1950 Au début Quelques jours après sa naissance, sa puissance de traitement était très limitée et il ne pouvait effectuer que quelques opérations simples, et ses capacités de traitement de données étaient également très limitées, ce qui faisait que l'ordinateur à cette époque n'était utilisé que pour des calculs scientifiques et techniques. Il n'existe aucun logiciel spécial pour gérer les données sur l'ordinateur. Les données sont transportées par l'ordinateur ou le programme qui les traite. Lorsque le format de stockage des données, les chemins de lecture et d'écriture ou les méthodes changent, le programme de traitement doit également apporter les modifications correspondantes pour maintenir l'exactitude du programme. 1.1.2. Système de fichiers De la fin des années 1950 au milieu des années 1960, avec le développement de la technologie matérielle et logicielle, les ordinateurs n'étaient pas seulement utilisés pour les calculs scientifiques, mais aussi pour la gestion commerciale. Au cours de cette période, les données et les programmes étaient complètement séparés dans l'emplacement de stockage, et les données étaient organisées en fichiers séparés et enregistrées sur des périphériques de stockage externes, afin que les fichiers de données puissent être utilisés par plusieurs programmes différents à des moments différents.  Bien que les programmes et les données soient séparés dans les emplacements de stockage et que le système d'exploitation puisse également nous aider à gérer l'emplacement de stockage et les chemins d'accès aux données, la conception des programmes est toujours affectée par le format et la méthode de stockage des données et ne peut pas être complètement indépendante des données. et la redondance des données est importante.
Bien que les programmes et les données soient séparés dans les emplacements de stockage et que le système d'exploitation puisse également nous aider à gérer l'emplacement de stockage et les chemins d'accès aux données, la conception des programmes est toujours affectée par le format et la méthode de stockage des données et ne peut pas être complètement indépendante des données. et la redondance des données est importante.
1.1.3. Système de gestion de bases de données
Depuis les années 1970, la technologie informatique et matérielle a connu un développement rapide au cours de cette période. L'émergence d'un véritable système de gestion de bases de données, qui réalise les interfaces et les interfaces. partage de données entre les applications et les données véritablement unifié, de sorte que les applications puissent exploiter directement les données de manière unifiée, c'est-à-dire que les applications et les données ont un haut degré d'indépendance.

1.2. Marques, services et architectures communs de technologies de bases de données
Après tant d'années de développement, de nombreux systèmes de bases de données sont apparus sur le marché, je pense personnellement. que le plus puissant est Oracle, bien sûr, il en existe bien d'autres tels que : DB2, Microsoft SQL Server, MySQL, SyBase, etc. La figure suivante répertorie les marques, services et architectures courants de technologies de bases de données.
1.3. Classification des bases de données
Les bases de données sont généralement divisées en bases de données hiérarchiques, bases de données réseau et bases de données relationnelles.
Différentes bases de données sont connectées et organisées selon différentes structures de données.
Dans Internet d'aujourd'hui, il existe deux principaux types de modèles de bases de données, à savoir les bases de données relationnelles et les bases de données non relationnelles.
1.3.1. Base de données relationnelle
La base de données principale actuellement dans les applications matures et servant divers systèmes est toujours la base de données relationnelle.
Représente : Oracle, SQL Server, MySQL
1.3.2, base de données non relationnelle
Avec l'évolution des temps et les besoins de développement, des bases de données non relationnelles ont émergé.
Représente : Redis, Mongodb
La base de données NoSQL présente des avantages en termes de vitesse de stockage et de flexibilité, et est également couramment utilisée pour la mise en cache.
1.4. Normalisation de la base de données
Après une série d'étapes, nous avons finalement converti les besoins du client en tables de données et établi la relation entre ces tables. Donc, si nous le pouvons maintenant. être utilisé dans le développement ? La réponse est non, pourquoi ! Pour le même projet, de nombreuses personnes ont participé à l'analyse des besoins et à la conception de la base de données. Différentes personnes ont des idées différentes, et différents départements ont des besoins commerciaux différents. La base de données que nous concevons sur cette base contiendra inévitablement une grande quantité des mêmes. Il peut également y avoir des conflits structurels, causant des désagréments au cours du développement.
1.4.1. Qu'est-ce qu'un paradigme
Pour concevoir une base de données standardisée, nous devons le faire selon le paradigme de conception de base de données, c'est-à-dire les principes normatifs de la conception de bases de données. Le paradigme peut nous guider pour mieux concevoir la structure des tables de la base de données et réduire les données redondantes, améliorant ainsi l'efficacité du stockage, l'intégrité des données et l'évolutivité de la base de données.
Lors de la conception d'une base de données relationnelle, suivez différentes exigences normatives pour concevoir une base de données relationnelle raisonnable. Ces différentes exigences normatives sont appelées différents paradigmes. Plus la redondance de la base de données paradigmatique est élevée, plus j'en reçois. plus je deviens petit. Il existe actuellement six paradigmes dans les bases de données relationnelles : première forme normale (1NF), deuxième forme normale (2NF), troisième forme normale (3NF), forme normale de Badsko (BCNF), quatrième forme normale (4NF) et cinquième forme normale (5NF). . , également connu sous le nom de paradigme parfait). La forme normale qui répond aux exigences minimales est la première forme normale (1NF). Celle qui répond en outre à des exigences plus normatives basées sur la première forme normale est appelée deuxième forme normale (2NF), et ainsi de suite pour les autres formes normales. De manière générale, la base de données doit uniquement répondre à la troisième forme normale (3NF).
1.4.2.Trois paradigmes majeurs
Première Forme Normale (1NF)
La dite première forme normale (1NF) fait référence à modèle relationnel , une exigence standard pour l'ajout de colonnes, toutes les colonnes doivent être atomiques, c'est-à-dire que chaque colonne de la table de base de données est un élément de données atomiques indivisible et ne peut pas être des éléments de données non atomiques tels que des ensembles, des tableaux, des enregistrements, etc. Autrement dit, lorsqu'un attribut d'une entité a plusieurs valeurs, il doit être divisé en différents attributs. Chaque valeur de champ dans une première table de forme normale (1NF) ne peut être qu'un attribut ou une partie d'un attribut de l'entité. En bref, la première forme normale est un domaine sans répétition.
Par exemple : Dans le tableau 1-1, la colonne « Adresse du projet » peut également être subdivisée en provinces, villes, etc. A l'étranger, de plus en plus de programmes divisent la colonne « nom » en 2 colonnes, à savoir « nom » et « prénom ».
Bien que la première forme normale exige que chaque colonne soit atomique et ne puisse pas être divisée, cette exigence est liée à nos besoins. Comme le montre le tableau ci-dessus, nous n'avons pas de provinces ou de villes pour « l'adresse du projet ». . Selon les exigences de la requête et de l'application, il n'est pas nécessaire de diviser, et il en va de même pour la colonne "Nom".
Tableau 1-1 Tableau original
Numéro du projet |
Nom du projet |
Adresse du projet |
Numéro de l'employé |
Nom de l'employé |
Salaire |
Poste |
P001 |
Hong Kong-Zhuhai- Pont de Macao |
Zhuhai, Guangdong |
E0001 |
Jack |
6000/mois |
Ouvrier |
P001 |
Pont Hong Kong Zhuhai-Macao |
Zhuhai, Guangdong |
E0002 |
Rejoignez |
7800/mois |
Ouvrier |
P001 |
Pont Hong Kong-Zhuhai-Macao |
Zhuhai, Guangdong |
E0003 |
Pomme |
8000/mois |
Mécanicien Premium |
P002 |
Nanhai Aerospace |
Hainan Sanya |
E0001 |
Jack |
5000/mois |
Travailleurs |
Deuxième Forme Normale (2NF)
Sur la base du 1NF, les non- Les attributs de clé doivent dépendre entièrement de la clé primaire. La seconde forme normale (2NF) est établie sur la base de la première forme normale (1NF), c'est-à-dire que pour satisfaire la seconde forme normale (2NF), la première forme normale (1NF) doit d'abord être satisfaite. La deuxième forme normale (2NF) exige que chaque instance ou enregistrement dans une table de base de données puisse être distingué de manière unique. Sélectionnez un attribut ou un groupe d'attributs qui peut distinguer chaque entité en tant qu'identifiant unique de l'entité.
La Deuxième Forme Normale (2NF) exige que les attributs d'une entité dépendent entièrement de la clé primaire. La dépendance dite complète signifie qu'il ne peut pas y avoir un attribut qui ne dépend que d'une partie de la clé primaire. S'il existe, alors cet attribut et cette partie de la clé primaire doivent être séparés pour former une nouvelle entité. l'entité d'origine est une relation un-à-plusieurs. Pour réaliser la différenciation, il est généralement nécessaire d'ajouter une colonne au tableau pour stocker l'identifiant unique de chaque instance. En bref, la deuxième forme normale est que les attributs dépendent entièrement de la clé primaire sur la base de la première forme normale.
Par exemple : dans le tableau 1-1, un tableau décrit les informations sur le projet, les informations sur les employés, etc. Cela entraîne une grande quantité de duplication de données. Selon la deuxième forme normale, nous pouvons diviser le tableau 1-1 en tableau 1-2 et tableau 1-3 :
l Tableau d'informations sur le projet : (numéro du projet, nom du projet, adresse du projet) :
Tableau 1-2 Tableau d'informations sur le projet
工程编号 |
工程名称 |
工程地址 |
P001 |
港珠澳大桥 |
广东珠海 |
P002 |
南海航天 |
海南三亚 |
Numéro du projet
员工编号 |
员工姓名 |
职务 |
薪资水平 |
E0001 |
Jack |
工人 |
3000/月 |
E0002 |
Join |
工人 |
3000/月 |
E0003 |
Apple |
高级技工 |
6000/月 |
Adresse du projet
P001 Port Pont Zhuhai-Macao Zhuhai, Guangdong员工编号 |
员工姓名 |
职务编号 |
E0001 |
Jack |
1 |
E0002 |
Join |
1 |
E0003 |
Apple |
2 |
工程编号 |
工程名称 |
工程地址 |
P001 |
港珠澳大桥 |
广东珠海 |
P002 |
南海航天 |
海南三亚 |
|
Nom du poste
|
Salaire | |||||||||||||||||||||
| 1 | Travailleur | 3000/mois | |||||||||||||||||||||
| 2 | Technicien senior | 6 000/mois |
Grâce à la comparaison, nous avons constaté qu'il y a plus de tables, que les relations sont plus complexes, qu'il devient plus difficile d'interroger les données et que la difficulté de programmation a également augmenté. Cependant, le contenu de chaque table est plus clair, il y en a moins. les données dupliquées, et les mises à jour et la maintenance deviennent plus difficiles, alors comment équilibrer cette contradiction ?
1.4.3. Paradigme et efficacité
Lorsque nous concevons une base de données, les concepteurs, les clients et les développeurs ont généralement certains conflits sur la conception de la base de données. Les clients préfèrent des résultats pratiques et clairs. Les développeurs espèrent également que les relations entre les bases de données seront plus simples afin de réduire les difficultés de développement, tandis que les concepteurs devront appliquer les trois paradigmes majeurs pour normaliser strictement la base de données, réduire la redondance des données et améliorer la maintenabilité et l'évolutivité de la base de données. Il ressort de cela que pour répondre aux trois paradigmes majeurs, la conception de nos bases de données sera différente selon les clients et les développeurs. Par conséquent, dans la conception réelle des bases de données, nous ne pouvons pas poursuivre aveuglément la normalisation. Nous devons considérer les trois paradigmes majeurs et réduire les données. redondance. En cas de fonctionnement anormal de diverses bases de données, les problèmes de performances de la base de données doivent être pleinement pris en compte et une redondance de base de données appropriée est autorisée.
2. Introduction à MySQL
2.1 Présentation de MySQL
MySQL est un système de gestion de base de données relationnelle développé par la société suédoise MySQL AB et est actuellement un produit. d'Oracle. MySQL est l'un des systèmes de gestion de bases de données relationnelles les plus populaires. En termes d'applications WEB, MySQL est l'un des meilleurs logiciels d'application RDBMS (Relational Database Management System).

MySQL est un système de gestion de base de données relationnelle qui stocke les données dans différentes tables au lieu de placer toutes les données dans un grand entrepôt, ce qui augmente la vitesse et la flexibilité.
Le langage SQL utilisé par MySQL est le langage standardisé le plus couramment utilisé pour accéder aux bases de données. Le logiciel MySQL adopte une double politique de licence et est divisé en version communautaire et version commerciale. En raison de sa petite taille, de sa vitesse rapide, de son faible coût total de possession et surtout de ses caractéristiques open source, MySQL est généralement choisi comme base de données de site Web pour le site Web. développement de sites Internet de petite et moyenne taille.
Site officiel MySQL : https://www.mysql.com/
Téléchargement MySQL : https://www.mysql.com/downloads/
2.2. fonctionnalités
1. Écrit en C et C++ et testé à l'aide de divers compilateurs pour garantir la portabilité du code source.
2. Prend en charge AIX, FreeBSD, HP-UX, Linux, Mac OS, NovellNetware, OpenBSD, OS/2 Wrap, Solaris, Windows et d'autres systèmes d'exploitation.
3. Des API sont fournies pour plusieurs langages de programmation. Ces langages de programmation incluent C, C++, Python, Java, Perl, PHP, Eiffel, Ruby, .NET et Tcl, etc.
4. Prend en charge le multithreading et utilise pleinement les ressources du processeur.
5. L'algorithme de requête SQL optimisé améliore efficacement la vitesse des requêtes.
6. Il peut être utilisé comme application autonome dans un environnement réseau client-serveur, ou intégré dans d'autres logiciels sous forme de bibliothèque.
7. Une prise en charge multilingue est fournie. Les codages courants tels que le chinois GB 2312, BIG5, le japonais Shift_JIS, etc. peuvent être utilisés comme noms de table de données et noms de colonnes de données.
8. Fournit plusieurs canaux de connexion à la base de données tels que TCP/IP, ODBC et JDBC.
9. Fournit des outils de gestion pour gérer, vérifier et optimiser les opérations de base de données.
10. Prend en charge les grandes bases de données. Peut gérer de grandes bases de données contenant des dizaines de millions d’enregistrements.
11. Prend en charge plusieurs moteurs de stockage.
12.MySQL est open source, vous n'avez donc pas besoin de payer de supplément.
13.MySQL utilise le formulaire de langage de données SQL standard.
14.MySQL prend bien en charge PHP, qui est actuellement le langage de développement Web le plus populaire.
15.MySQL peut être personnalisé et adopte le protocole GPL. Vous pouvez modifier le code source pour développer votre propre système MySQL.
16. Fonctionnalité DDL/changement en ligne, l'architecture de données prend en charge les applications dynamiques et la flexibilité des développeurs (nouveau dans la version 5.6)
17. Répliquez les identifiants de transaction globaux pour prendre en charge les clusters d'auto-réparation (nouveau dans la version 5.6).
18. Copiez les esclaves sans crash pour améliorer la disponibilité (nouveau dans la version 5.6)
19. Copiez les esclaves multithread pour améliorer les performances (nouveau dans la version 5.6)
20,3x performances plus rapides (nouveau dans 5.7)
21. Nouvel optimiseur (nouveau dans 5.7)
22 Prise en charge native de JSON (nouveau dans 5.7)
23. (nouveau dans 5.7)
24. Expansion spatiale SIG (nouveau dans 5.7)
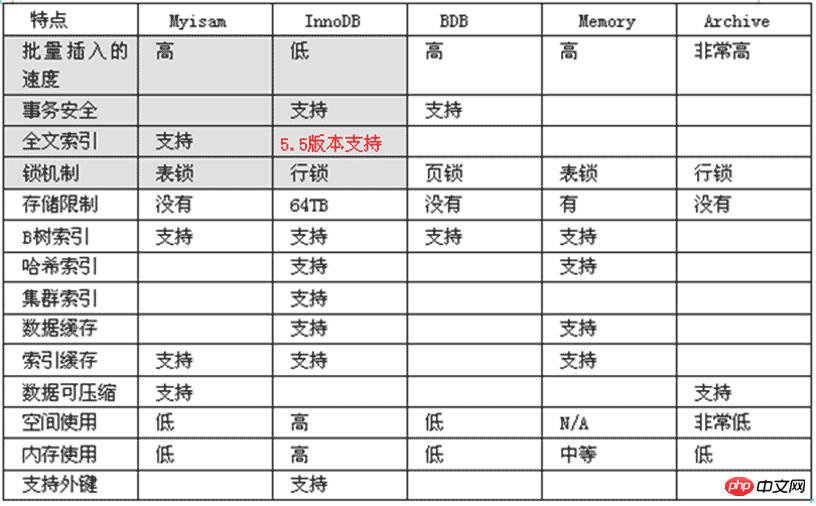
2.3 Moteur de stockage
La base de données MySQL basée sur différents moteurs est préparée en fonction des besoins de. l'application. Différents moteurs ont des objectifs différents. Les différences sont les suivantes :
MyISAM, le moteur de base de données par défaut avant MySQL 5.0, est le plus couramment utilisé. Il a une vitesse d'insertion et de requête élevée, mais ne prend pas en charge les transactions
InnoDB est le moteur préféré pour les bases de données transactionnelles, prend en charge les transactions ACID et le verrouillage au niveau des lignes. Il est devenu le moteur de base de données par défaut depuis MySQL 5.5.
BDB est dérivé de Berkeley DB, un autre choix pour la base de données transactionnelle, prenant en charge d'autres fonctionnalités de transaction telles que Commit et Rollback
La mémoire est un moteur de stockage qui place toutes les données en mémoire, avec une efficacité de mise à jour et de requête extrêmement élevée. Mais il occupera un espace mémoire proportionnel à la quantité de données. Et son contenu sera perdu au redémarrage de MySQL
Merge regroupe un certain nombre de tables MyISAM en un tout, ce qui est utile pour le stockage de données à très grande échelle
Archive est très approprié pour stocker de grandes quantités de données historiques indépendantes. Parce qu'ils ne sont pas lus souvent. Archive a une vitesse d'insertion efficace, mais sa prise en charge des requêtes est relativement faible
Federated combine différents serveurs MySQL pour former logiquement une base de données complète. Très adapté aux applications distribuées
Cluster/NDB est un moteur de stockage hautement redondant qui utilise plusieurs machines de données pour fournir conjointement des services afin d'améliorer les performances et la sécurité globales. Convient aux applications avec de grandes quantités de données et des exigences élevées en matière de sécurité et de performances
CSV est un moteur de stockage qui sépare logiquement les données par des virgules. Il crée un fichier .csv pour chaque table de données du sous-répertoire de la base de données. Il s'agit d'un fichier texte normal, chaque ligne de données occupant une ligne de texte. Le moteur de stockage CSV ne prend pas en charge l'indexation.
Moteur de trou noir BlackHole, toutes les données écrites disparaîtront, généralement utilisé pour enregistrer le binlog comme relais pour la réplication
EXEMPLE Le moteur de stockage est un moteur stub qui ne fait rien. Il est destiné à servir d'exemple dans le code source MySQL pour montrer comment commencer à écrire un nouveau moteur de stockage. Là encore, son principal intérêt réside dans les développeurs. EXEMPLE Le moteur de stockage ne prend pas en charge l'indexation.
De plus, l'interface du moteur de stockage de MySQL est bien définie. Les développeurs intéressés peuvent écrire leurs propres moteurs de stockage en lisant la documentation.
3. Installez et exécutez rapidement la base de données MySQL
MySQL a toujours été open source et gratuit. acquise par Oracle, quelques changements : Les versions précédentes étaient gratuites. La version communautaire est open source et gratuite sous licence GPL. La version commerciale offre des fonctionnalités plus riches mais est payante.
Adresse de téléchargement de la version communautaire : https://dev.mysql.com/downloads/ (gratuit)
Adresse de téléchargement de la version entreprise : https://www.mysql.com/downloads / (facturé)
3.1. Utiliser la version verte
Afin d'utiliser MySQL de manière pratique et rapide, j'ai préparé un MySQL vert, qui peut être utilisé directement après décompression sans aucune configuration.
Adresse de téléchargement 1 : https://pan.baidu.com/s/1hrS5KUw Mot de passe : sug9
Adresse de téléchargement 2 : http://www.jb51.net/softs/594937. html
Décompressez directement après le téléchargement :
Cliquez pour démarrer PStart.exe Il s'agit d'un petit outil de personnalisation des menus, utilisé pour organiser les ressources.
Il existe deux versions vertes du logiciel MySQL 5.0 et 5.5
Navicat pour MySQL est un outil de gestion de client de base de données
Les résultats après avoir cliqué pour démarrer PStart.exe sont les suivants :
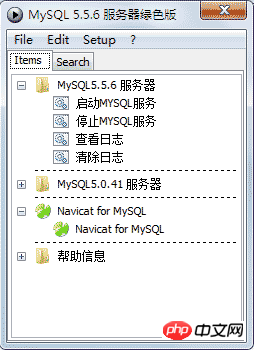
Cliquez pour démarrer le service MySQL et exécuter Navicat pour MySQL.
*Remarque : Le PStart ci-dessus n'est qu'un outil pour organiser la documentation et n'est pas nécessaire. S'il y a une erreur ou s'il est vide au démarrage, vous pouvez le fermer directement et démarrer directement le service MySQL, par exemple :
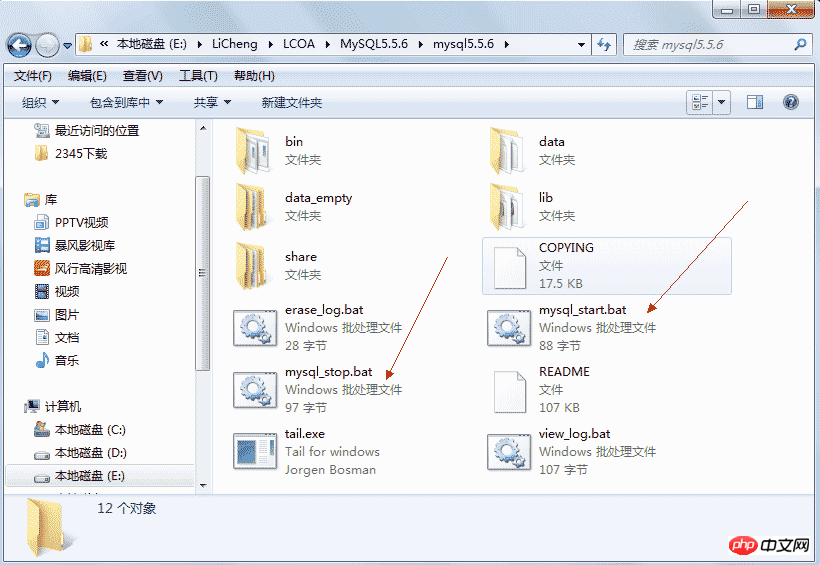
mysql_start.bat est utilisé pour démarrer la base de données MySql, et mysql_stop.bat est utilisé pour fermer la base de données MySql.
L'outil de développement se démarre de la même manière, comme suit :
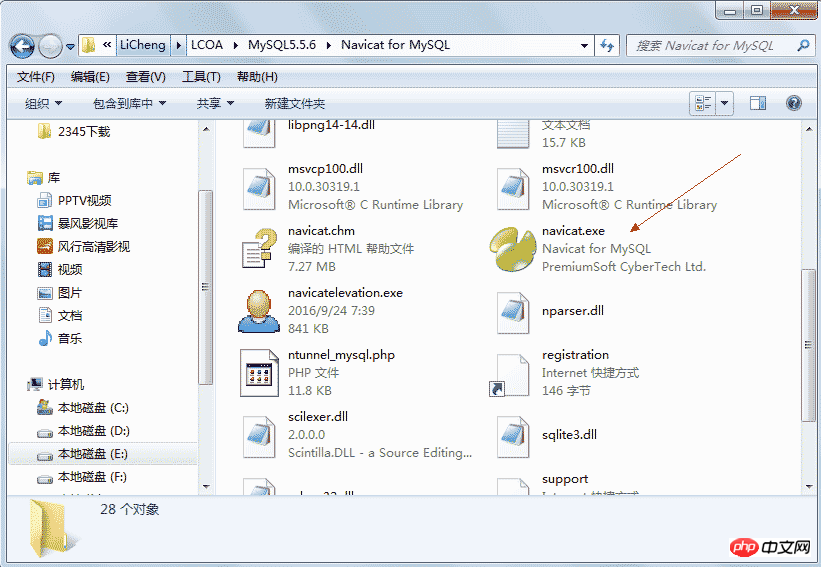
navicat.exe est utilisé pour démarrer le client de base de données Navicat. envoyez le raccourci vers le bureau, ce qui vous évite d'avoir à ouvrir un dossier à chaque fois.
3.1.1. Configurer l'accès à distance mysql
Exécutez la commande mysql pour entrer en mode commande mysql et exécutez le code SQL suivant
mysql> use mysql; mysql> GRANT ALL ON *.* TO admin@'%' IDENTIFIED BY 'admin' WITH GRANT OPTION;
#Le sens de cette phrase est de permettre à tout ordinateur possédant une adresse IP (le % ci-dessus signifie cela) d'accéder à ce serveur MySQL avec le compte admin et le mot de passe (admin)
#Vous devez ajouter un compte comme ceci avant de pouvoir vous connecter à distance. Le compte root ne peut pas se connecter à distance, mais ne peut se connecter que localement
3.1.2 Modifier le mot de passe de l'utilisateur mysql
1 La commande mysqladmin
a le format suivant. (où USER est le nom d'utilisateur, PASSWORD est le nouveau mot de passe) :
mysqladmin -u USER -p password PASSWORD
Après cette commande, vous serez invité à saisir le mot de passe d'origine, qui pourra être modifié par la suite. est saisi correctement.
Par exemple, si le mot de passe de l'utilisateur root est défini sur 123456, alors
mysqladmin -u root -p password 123456
2.UPDATE déclaration utilisateur
Cette méthode doit être enregistrée avec le compte root d'abord mysql, puis exécutez :
UPDATE user SET password=PASSWORD('123456') WHERE user='root';FLUSH PRIVILEGES;
Instruction 3.SET PASSWORD
Cette méthode nécessite également de se connecter à mysql avec la commande root d'abord, puis en exécutant :
SET PASSWORD FOR root=PASSWORD('123456');
4. Lorsque le mot de passe root est perdu
Utilisez "MySQL GUI Tools", un outil fourni avec MySQL. J'utilise la version 5.0. Exécutez un programme MySQLSystemTrayMonitor.exe dans le répertoire d'installation. Après l'exécution, une icône apparaîtra dans la barre d'état système. Si le service MySQL n'a pas été installé, il n'apparaîtra pas. Vous pouvez d'abord configurer et installer le service via Action>Gérer les instances MySQL. Si le service a été installé, le menu « Configurer l'instance » apparaîtra après un clic droit de la souris. Après avoir cliqué, la fenêtre Administrateur MySQL suivante apparaîtra :
Si la configuration d'origine du service est normale, sélectionnez "Variables de démarrage" dans la liste de gauche, et sélectionnez "Sécurité" dans l'étiquette correspondante à droite, et cochez Sélectionnez "Désactiver la table des subventions" puis "Appliquer les modifications".
Retournez dans l'onglet "Contrôle du serveur" à gauche et dans l'onglet "Démarrer/Arrêter le service" correspondant à droite, cliquez pour démarrer le service. À ce stade, un nom d'utilisateur et un mot de passe ne sont plus requis pour se connecter à MySQL. Vous pouvez modifier le mot de passe root.
3.1.2. Service d'installation
Nous entrons d'abord dans le répertoire bin sous le répertoire d'installation mysql, puis ouvrons la fenêtre de commande DOS et entrons dans le répertoire (assurez-vous d'entrer dans le répertoire, sinon le erreur d'opération)
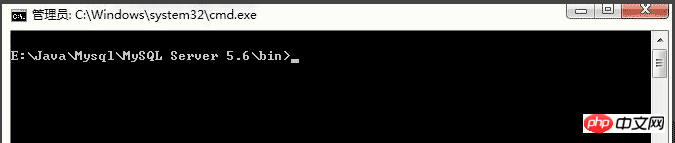
Exécutez la commande DOS :
Entrez la commande : mysqld --install, et l'interface suivante apparaîtra. Il indique que l'installation du service a réussi.
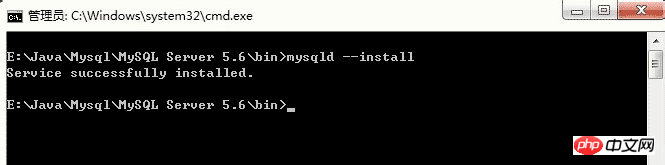
Notez qu'il s'agit de mysqld --install et non de mysql --install
Si vous souhaitez désinstaller le service, vous pouvez saisir la commande suivante : mysqld --retirer. L'interface suivante apparaît. Invite indiquant que le service a été supprimé avec succès.

3.2. Utilisez la version d'installation
Adresse de téléchargement du package d'installation MySQL5.5.27_64 bits 1 : https://pan.baidu.com/s /1minwz1m Mot de passe : ispn
Adresse de téléchargement du package d'installation MySQL5.5.56_64 bits 2 : http://www.jb51.net/softs/363920.html
Officiel du package d'installation MySQL5.7.17 Adresse de téléchargement du site Web : https://dev.mysql.com/downloads/windows/installer/
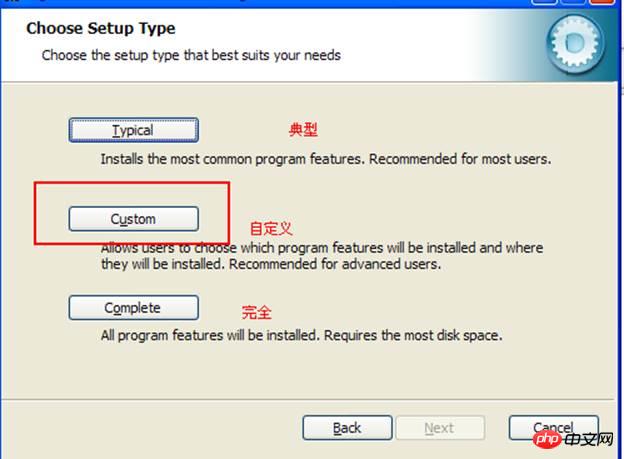
Sélectionnez la personnalisation :
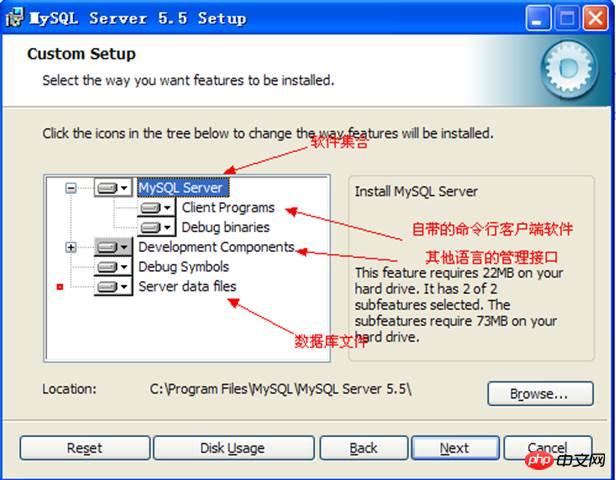
Informations sur le composant installé :
Répertoire des logiciels du serveur : 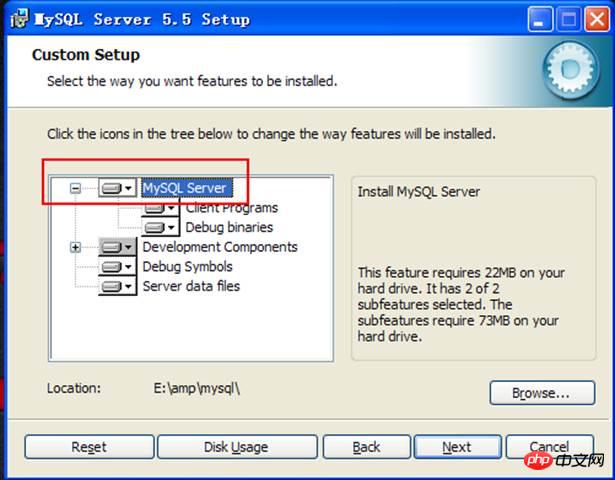
Répertoire des données :
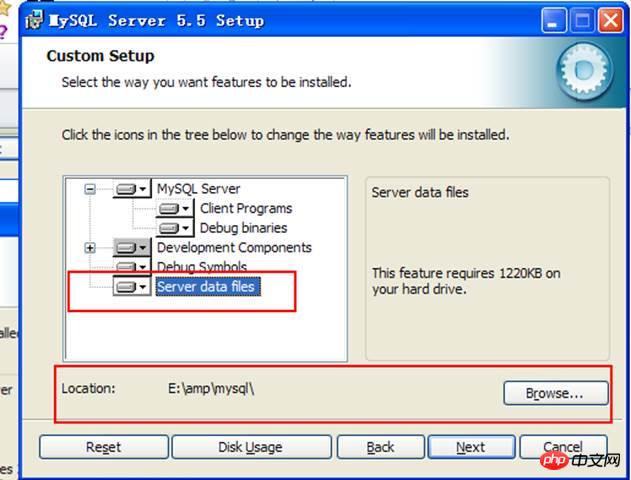
Cliquez sur installer pour installer :
Configuration :
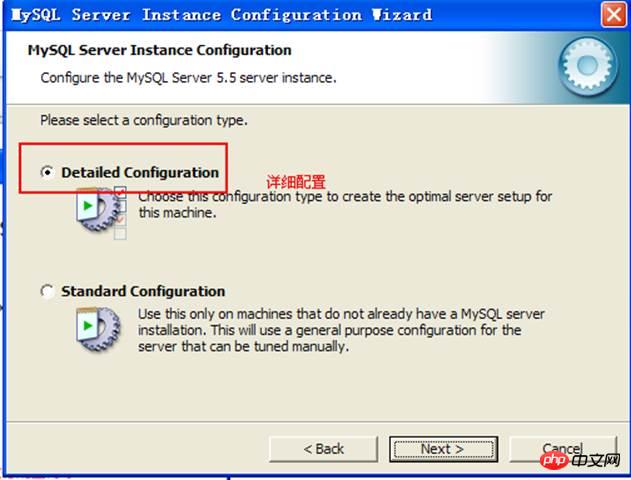
Type de machine
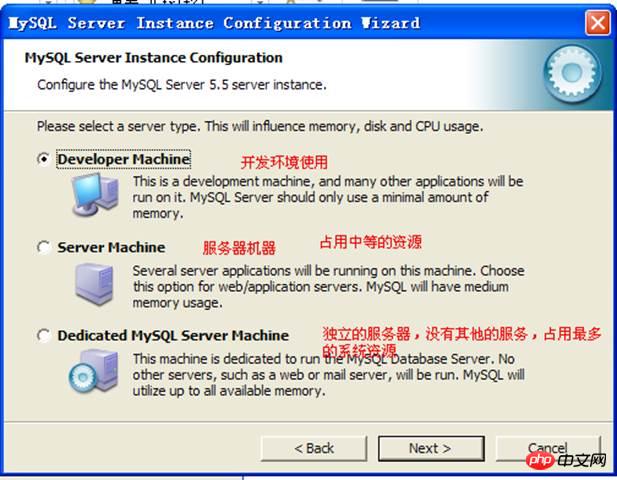
S'il faut prendre en charge la fonction de transaction :
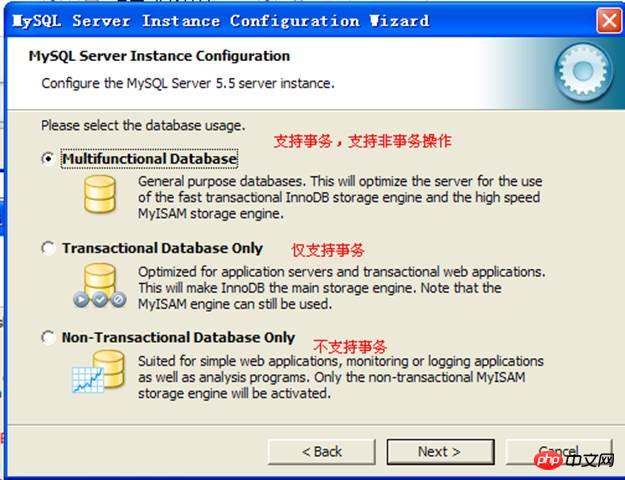
espace table innodb :
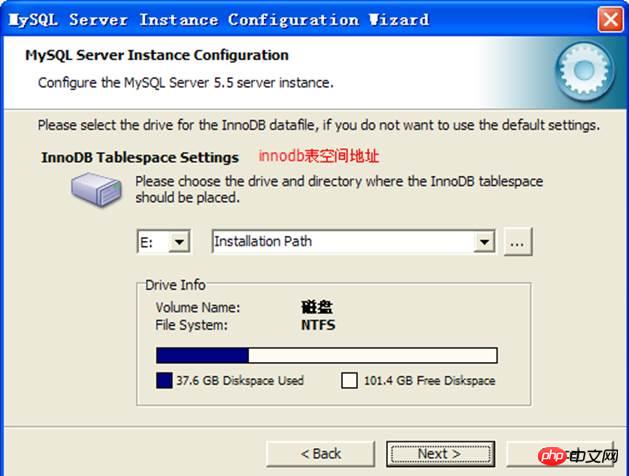
Nombre de connexions :
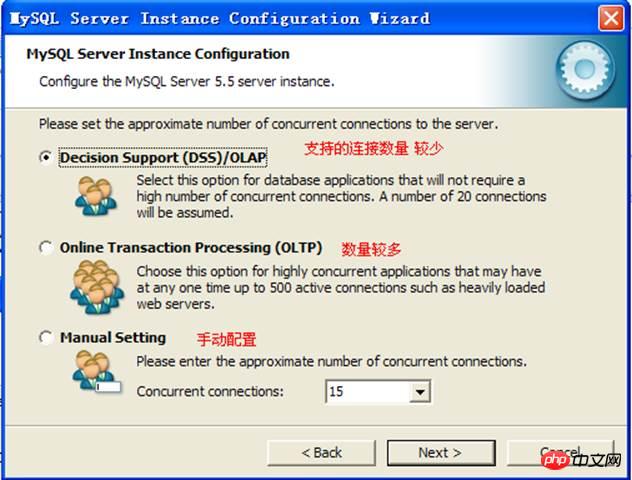
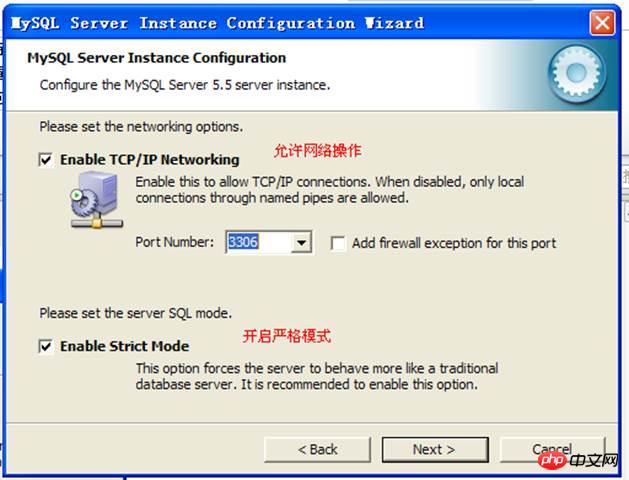
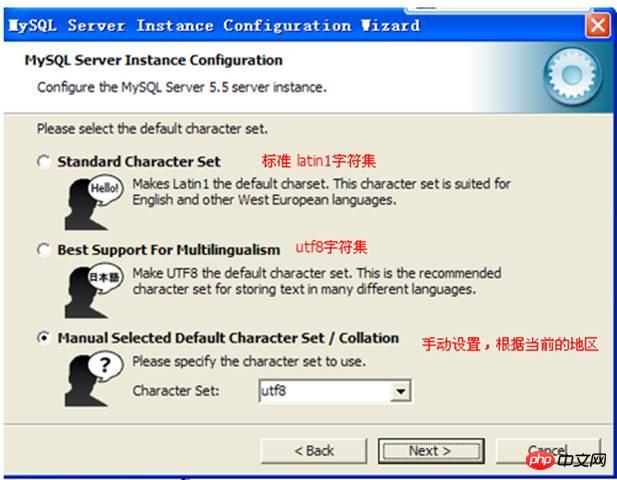
Paramètre du jeu de caractères :
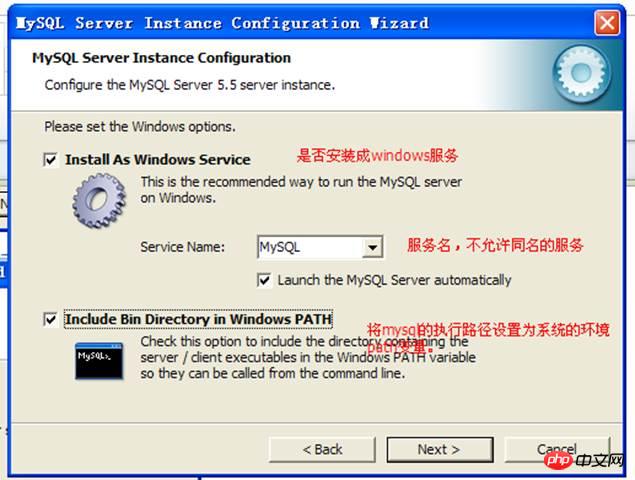
Configurer Windows Concernant la gestion :
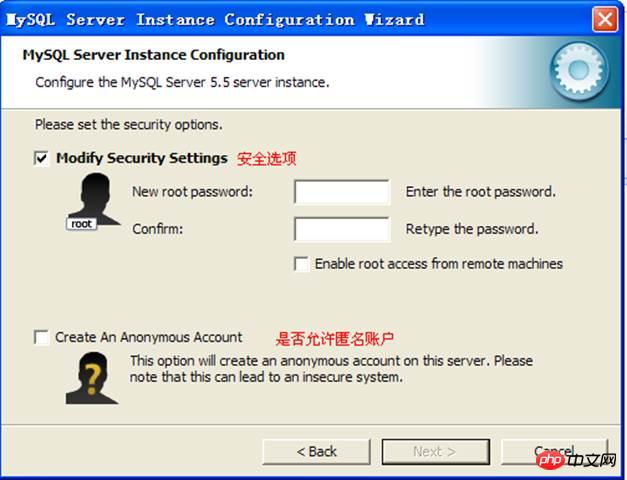
Configurer les options de sécurité, définir le nom d'utilisateur et le mot de passe de l'administrateur :
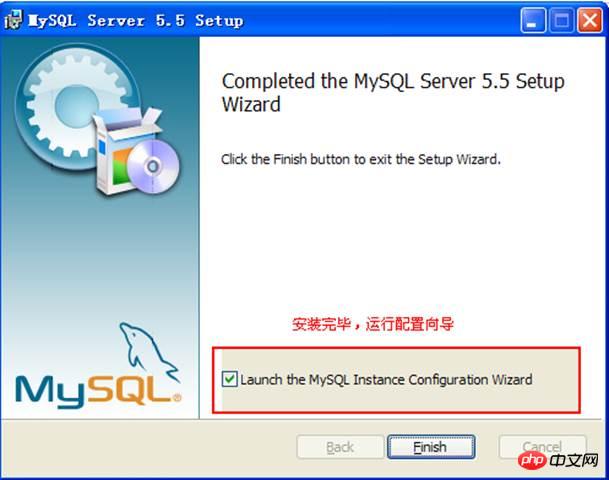
Enfin, exécuter la configuration . Disponible :
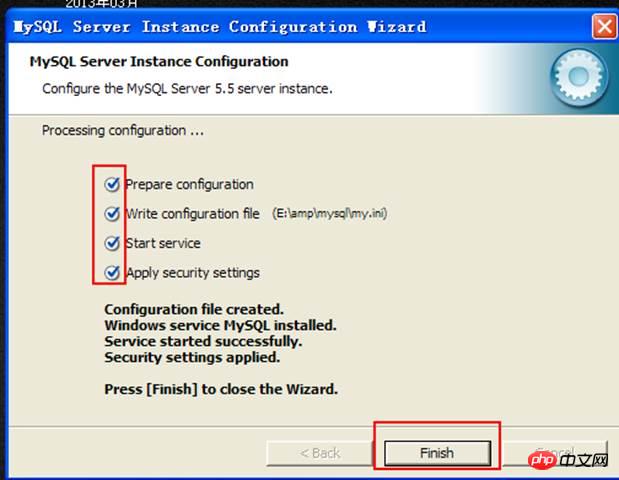
Après la configuration, le service sera démarré.
La nouvelle version du package d'installation de MySQL est beaucoup plus volumineuse et le processus d'installation est également quelque peu différent.
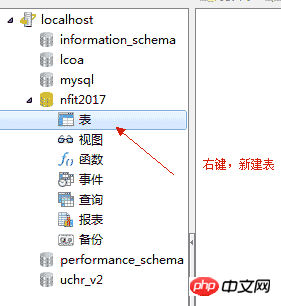
4. Utiliser l'interface graphique pour faire fonctionner MySQL 4.1 et les concepts typiques des bases de données relationnelles
Base de données : entrepôt de données
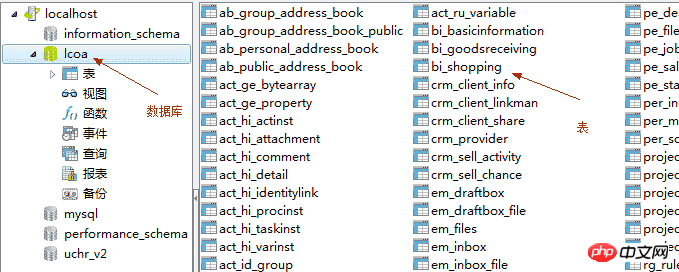
table : Données est enregistrée dans un tableau. Les données enregistrées dans un tableau doivent avoir le même format de données
Ligne : la ligne est utilisée pour enregistrer les données
Enregistrement : données dans une ligne
Colonne. : La colonne est utilisée pour spécifier le format des données
Champ : Une certaine colonne de données
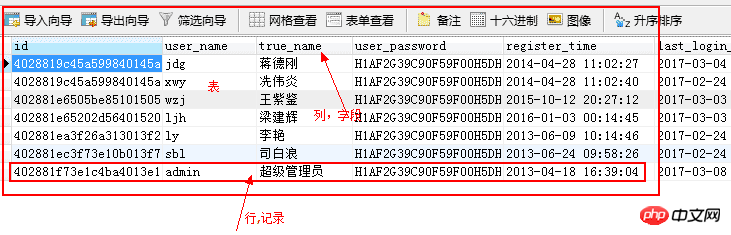
SQL:用来管理数据的语言。结构化查询语言(SQL,Structured Query Language)
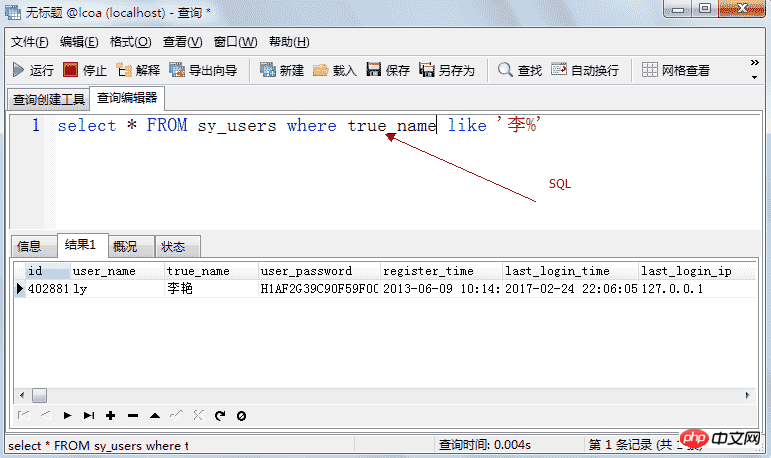
主键:唯一地标识表中的某一条记录,不能空,不能重复
4.2、登录数据库
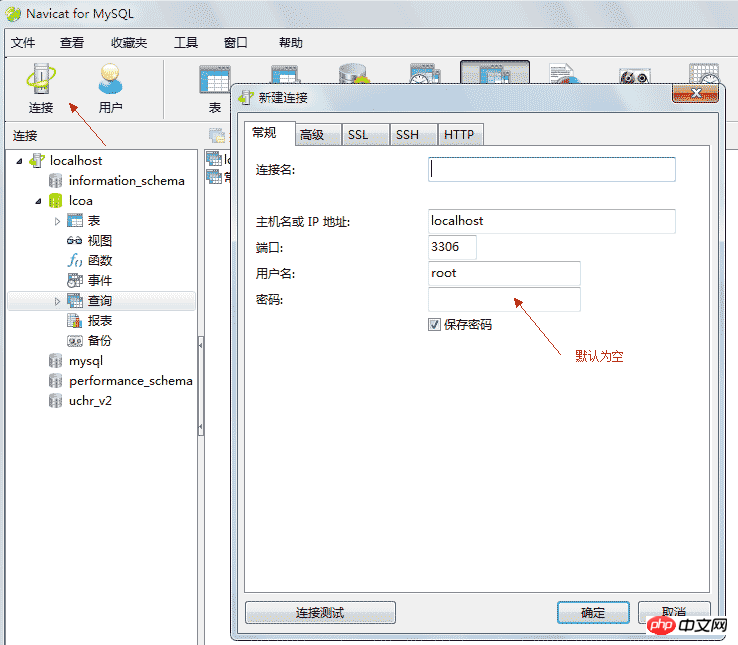
*连接本地数据库时需要启动服务
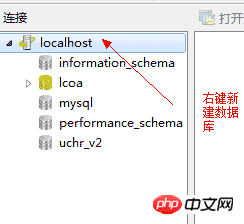
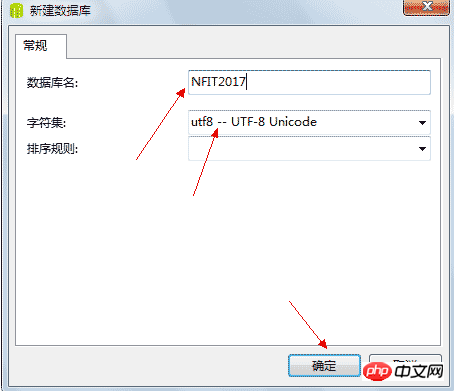
4.3、创建数据库
4.4、创建表
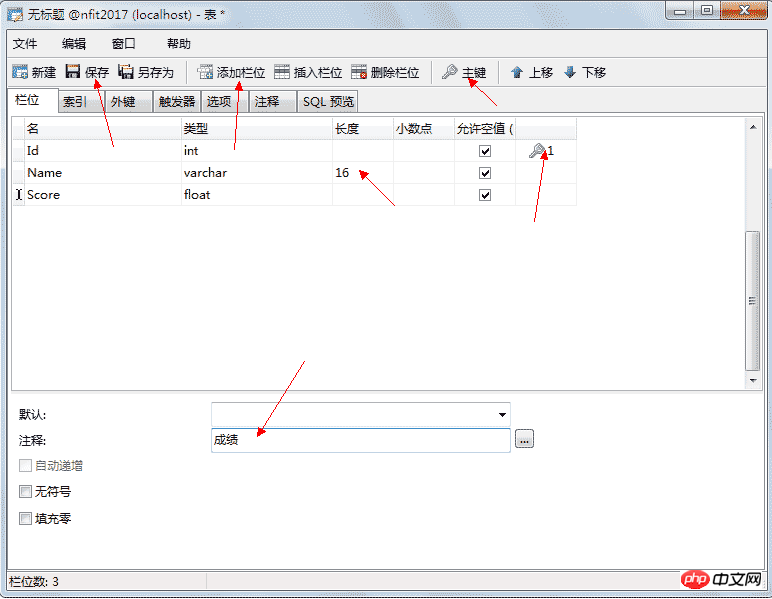
列的类型:
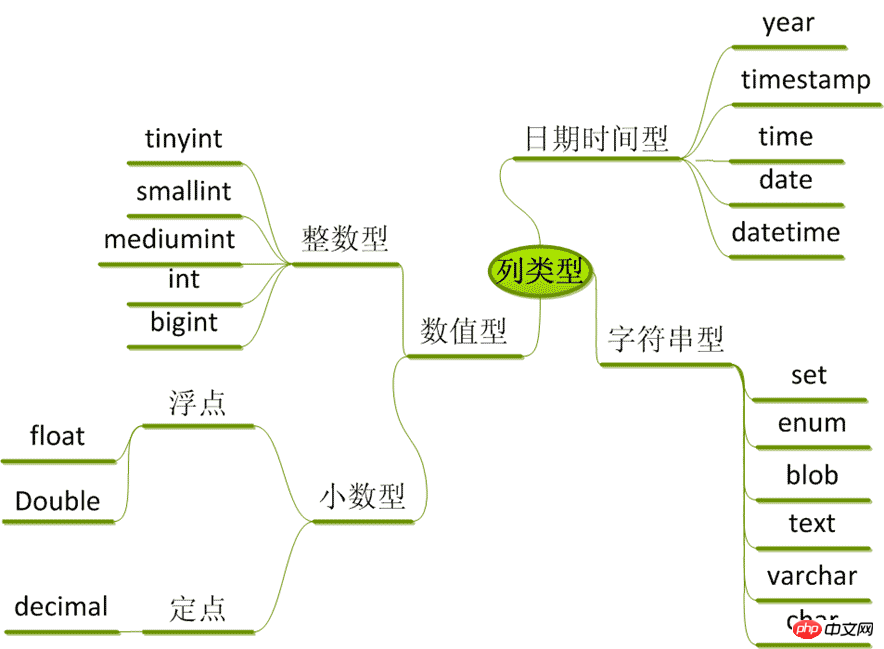
数字类型
整数: tinyint、smallint、mediumint、int、bigint
浮点数: float、double、real、decimal
日期和时间: date、time、datetime、timestamp、year
字符串类型
字符串: char、varchar
文本: tinytext、text、mediumtext、longtext
二进制(可用来存储图片、音乐等): tinyblob、blob、mediumblob、longblob
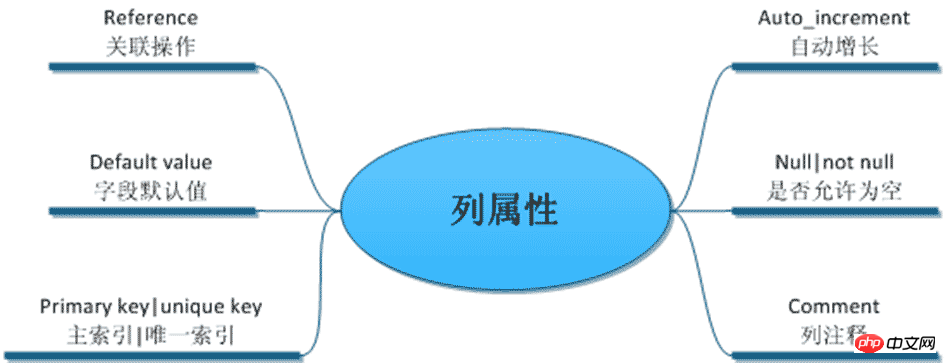
列的约束:
4.5、管理数据4.5.1、添加数据
双击新建好的表名,打开表,就可以添加数据了。
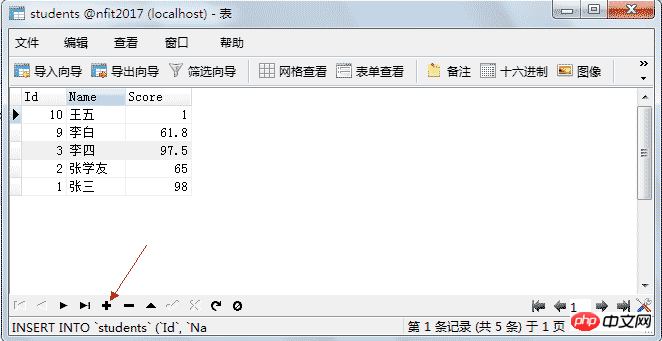
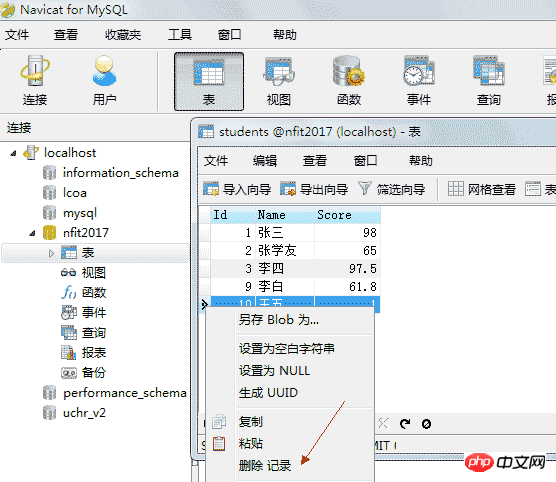
4.5.2、删除数据
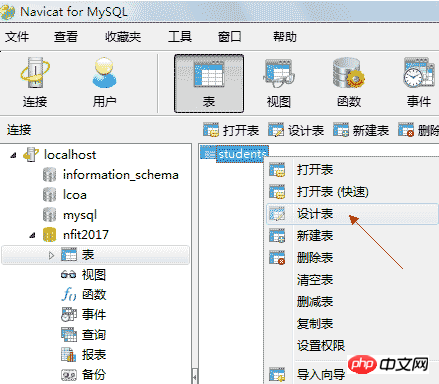
4.5.3、修改表结构
如果想向现有的表中添加一列,则可以修改表结构:
4.5.4、外键
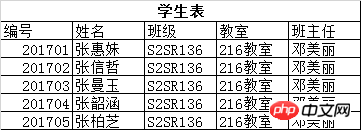
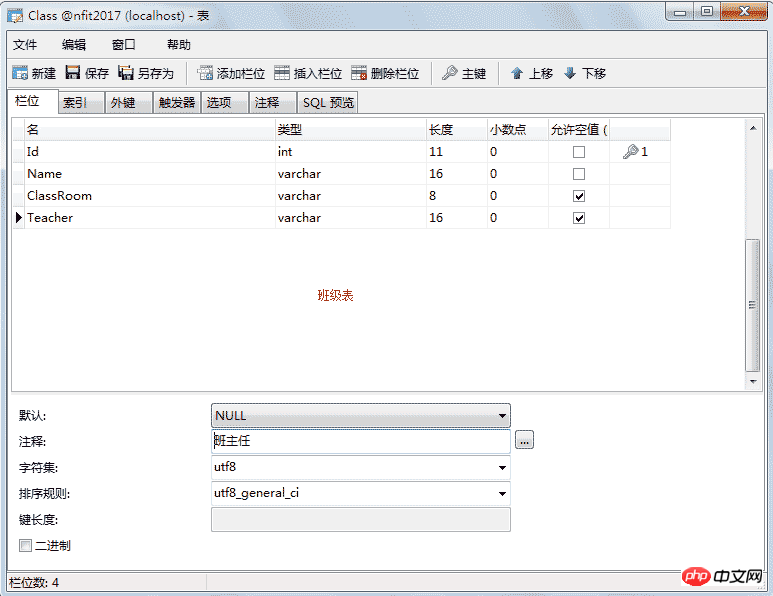
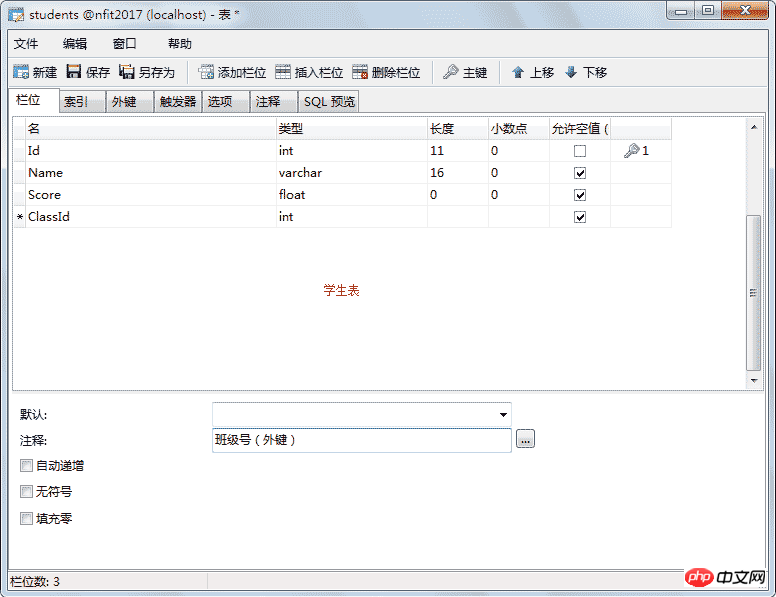
上面这个学生表是有些问题的:
a)、不便于修改,比如教室换成了305教室,则每个学员都要修改
b)、数据冗余,大量的重复数据
将表拆分成两个,分解后问题解决,如下图所示:

这里的班级编号就是外键,可以空,但不为空时他的值一定在要引用表中存在。如果学生表中的编号是主键这里就不应该重复,外键则可以重复也允许为空。
添加外键:
班级表:
学生表:
添加外键:
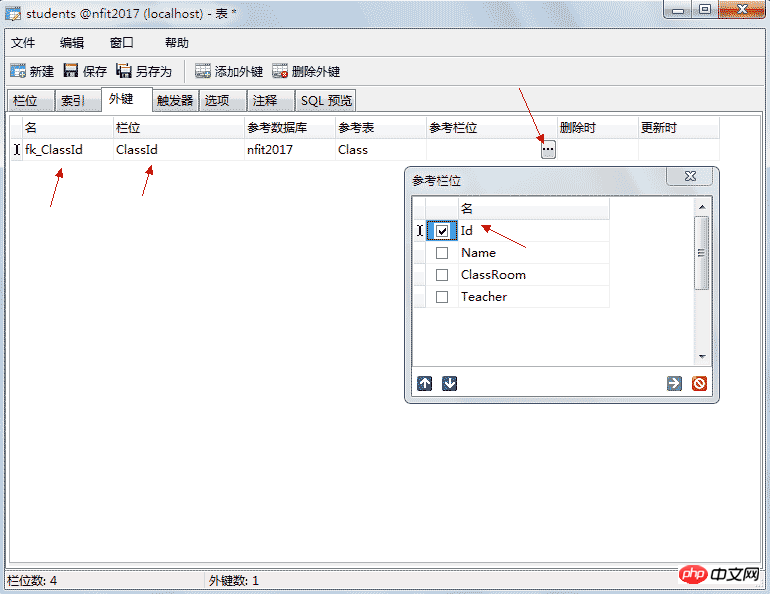
删除与更新时可以实现级联更新与删除,当更新设置为CASCADE时主键变化引用主键的表也会一起变化,当删除设置为CASCADE时删除主键表,引用的记录都将被删除。
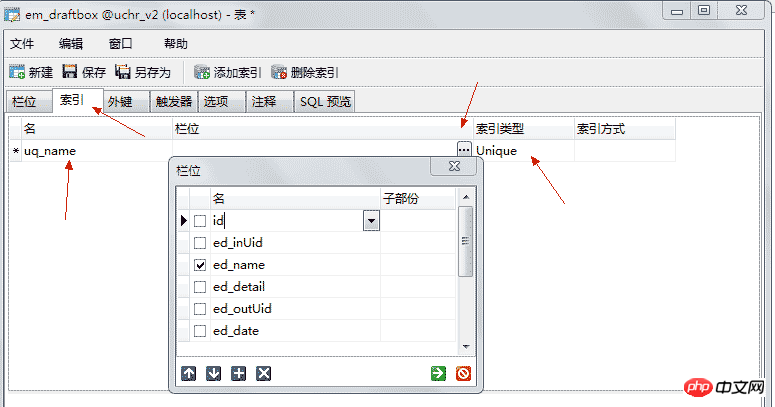
4.5.5、唯一键
唯一键,也称(唯一约束),和主键的区别是可以为有多个唯一键并且值可以为NULL,但NULL也不能重复,也就是说只能有一行的值为NULL。它会隐式的创建唯一索引。
设置方法:索引 --> 添加索引 --> 栏位名 添加你想设置唯一约束的列 --> 索引类型选择 Unique
#查询 select id,name from yuangong select * from yuangong select * from yuangong where salary>5000 #增加 INSERT into yuangong(name,salary,bumenId,mobile) value('张为剑',2190.6,2,19889007867); INSERT into yuangong(name,salary,bumenId,mobile) value('张娜拉',9871.6,1,19889007777); #修改 update yuangong set salary=salary+1 where id=7 #删除 INSERT into yuangong(name,salary,bumenId,mobile) value('张拉拉',9871.6,1,19889007777); delete from yuangong where id=8
4.6、上机练习
1、请创建一个新的数据库叫HR,在HR数据库中添加EMP表,EMP表的表结构如下所示
EMP表:员工信息
№ | 名称 | 类型 | 描述 |
1 | EMPNO | int | 雇员的编号,主键,自动增长 |
2 | ENAME | VARCHAR(10) | 雇员的姓名,由10位字符所组成,不为空,唯一键 |
3 | JOB | VARCHAR(9) | 雇员的职位 |
4 | MGR | int | Le numéro de leader correspondant à l'employé Le leader est aussi un employé et. peut être vide (peut être supprimé) Cette colonne) |
5 | HIREDATE | TimeStamp | La date d'embauche de l'employé, par défaut la date actuelle |
6 | SAL | Numérique(7,2) | Salaire de base, qui comporte deux décimales et cinq entiers, soit un total de sept chiffres |
7 | COMM | Numérique(7,2) | Bonus, Commission |
8 | DEPTNO | int | Le numéro du département où se trouve l'employé, facultatif, clé étrangère fk_deptno |
9 | DÉTAIL | Texte | Remarques, peut être vide |
Département : table de département
№ | 名称 | 类型 | 描述 |
1 | DeptNO | int | 部门的编号,主键,自动增长 |
2 | DNAME | VARCHAR(10) | 部门名,由50位字符所组成,不为空,唯一键 |
3 | DTel | VARCHAR(10) | 电话,可空 |
2、根据上面的表结构完成表的创建,表名为emp
3、在表中添加5条以上的数据
4、完成下列查询要求
4.1查询所有员工信息
4.2查询所有工资介于2000-5000间的员工姓名、职位与工资
4.3查询所有姓“张”的员工
4.4 按工资降序查询出2014年到2015年间入职的员工
4.5、将工资普遍上调20%
4.6、将工资低于3000元的员工奖金修改为工资的2.8倍
4.7、删除编号为5或者姓“王”的员工
五、使用SQL访问MySQL数据库
5.0、定义学生表Stu
(id编号,name姓名,sex性别,age年龄,...)
5.0.1、新建数据库
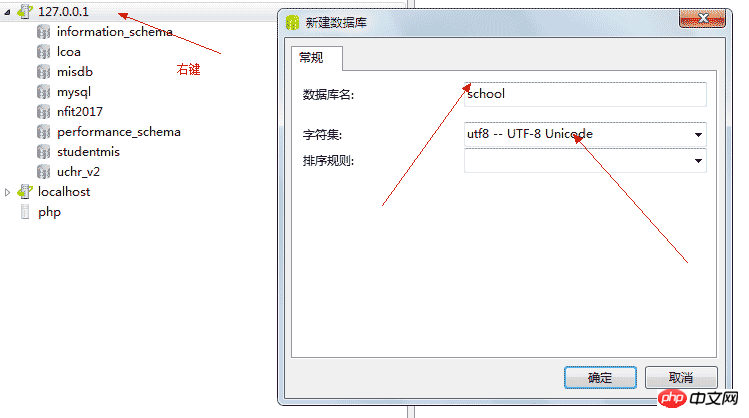
5.0.2、新建表
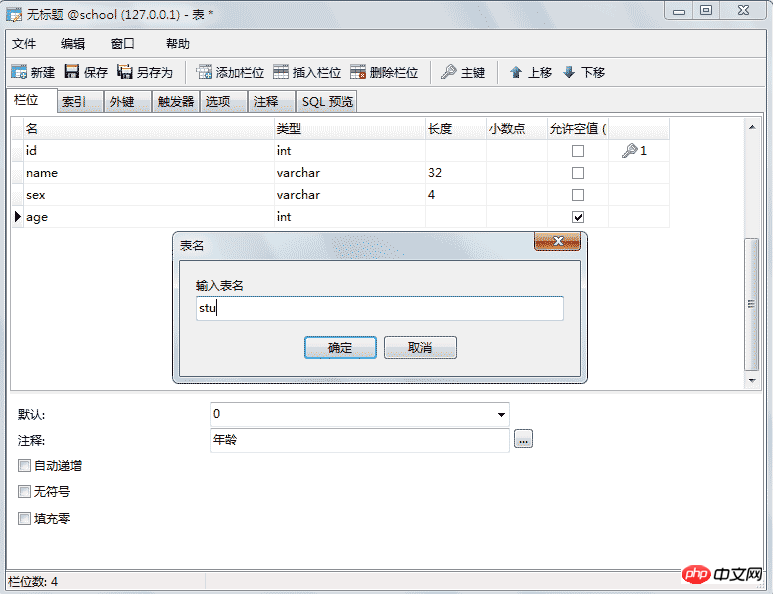
5.0.3、新建查询
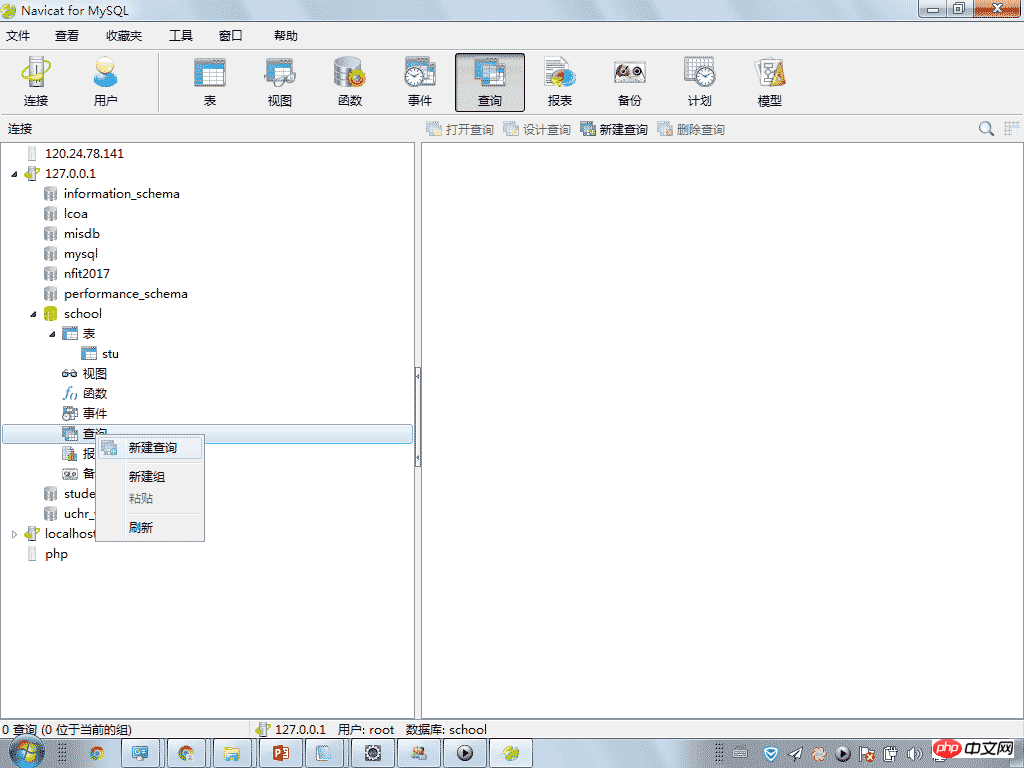
5.1、增加数据
insert 语句可以用来将一行或多行数据插到数据库表中, 使用的一般形式如下:
Insert into 表名(字段列表) values (值列表);
insert [into] 表名 [(列名1, 列名2, 列名3, ...)] values (值1, 值2, 值3, ...);
insert into students values(NULL, "张三", "男", 20, "18889009876");
有时我们只需要插入部分数据, 或者不按照列的顺序进行插入, 可以使用这样的形式进行插入:
insert into students (name, sex, age) values("李四", "女", 21);
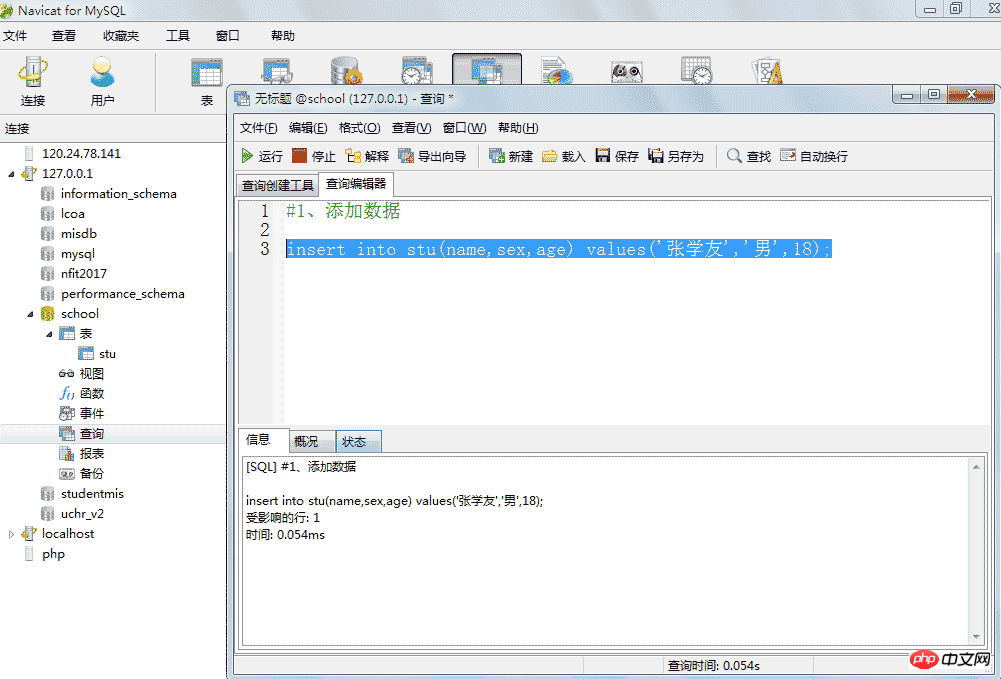
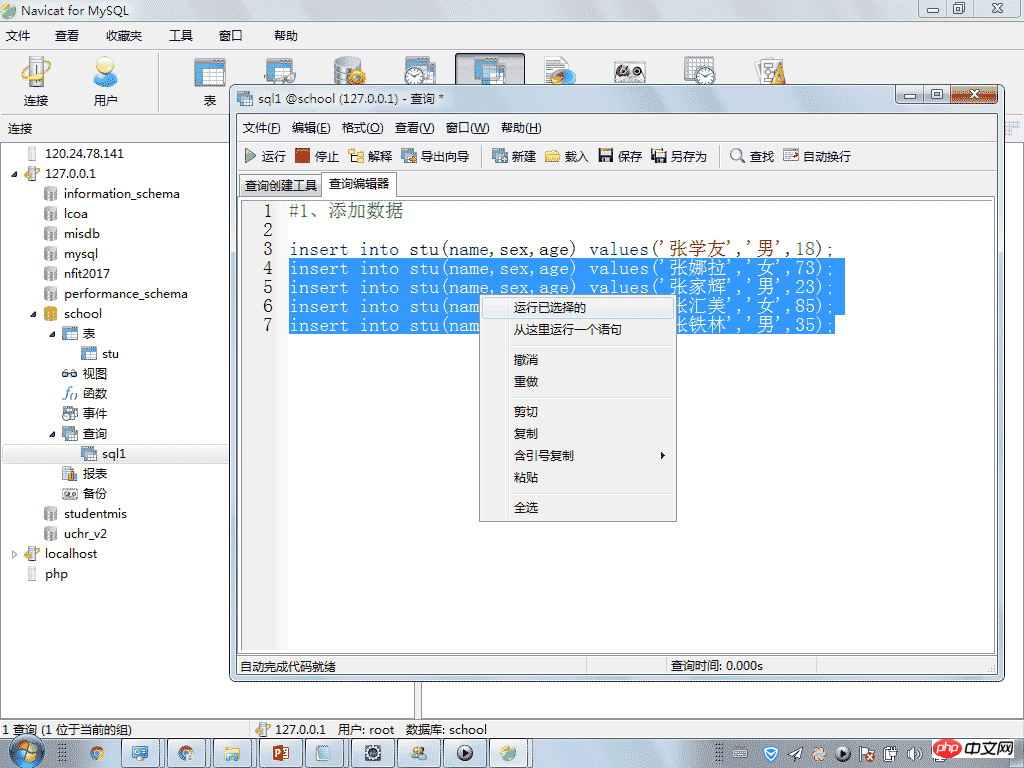
#1、添加数据 insert into stu(name,sex,age) values('张学友','男',18); insert into stu(name,sex,age) values('张娜拉','女',73); insert into stu(name,sex,age) values('张家辉','男',23); insert into stu(name,sex,age) values('张汇美','女',85); insert into stu(name,sex,age) values('张铁林','男',35);
5.2、查询数据
select 语句常用来根据一定的查询规则到数据库中获取数据, 其基本的用法为:
select 字段名 from 表名称 [查询条件];
查询学生表中的所有信息:select * from students;
查询学生表中所有的name与age信息:select name, age from students;
也可以使用通配符 * 查询表中所有的内容, 语句: select * from students;
#1、添加数据
insert into stu(name,sex,age) values('张学友','男',18);
insert into stu(name,sex,age) values('张娜拉','女',73);
insert into stu(name,sex,age) values('张家辉','男',23);
insert into stu(name,sex,age) values('张汇美','女',85);
insert into stu(name,sex,age) values('张铁林','男',35);
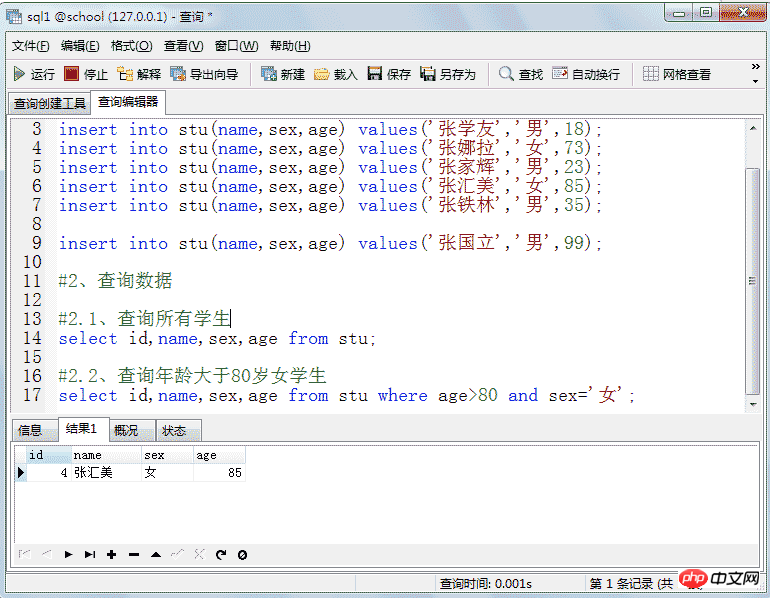
insert into stu(name,sex,age) values('张国立','男',99);
#2、查询数据
#2.1、查询所有学生
select id,name,sex,age from stu;
#2.2、查询年龄大于80岁女学生
select id,name,sex,age from stu where age>80 and sex='女';结果:
5.2.1、表达式与条件查询
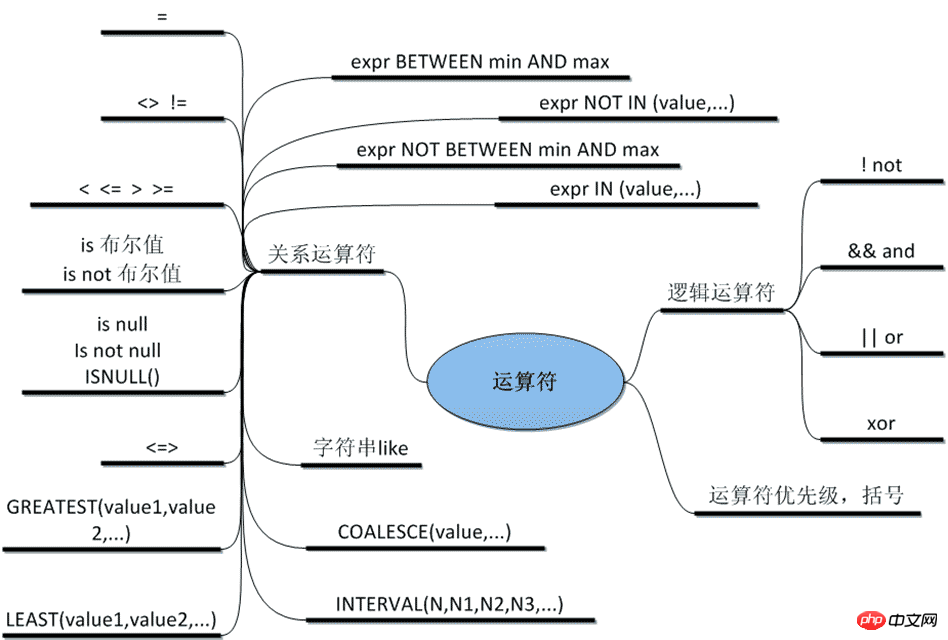
where 关键词用于指定查询条件, 用法形式为: select 列名称 from 表名称 where 条件;
以查询所有性别为女的信息为例, 输入查询语句: select * from students where sex="女";
where 子句不仅仅支持 "where 列名 = 值" 这种名等于值的查询形式, 对一般的比较运算的运算符都是支持的, 例如 =、>、<、>=、<、!= 以及一些扩展运算符 is [not] null、in、like 等等。 还可以对查询条件使用 or 和 and 进行组合查询, 以后还会学到更加高级的条件查询方式, 这里不再多做介绍。
示例:
查询年龄在21岁以上的所有人信息: select * from students where age > 21;
查询名字中带有 "王" 字的所有人信息: select * from students where name like "%王%";
查询id小于5且年龄大于20的所有人信息: select * from students where id<5 and age>20;
5.2.2、聚合函数
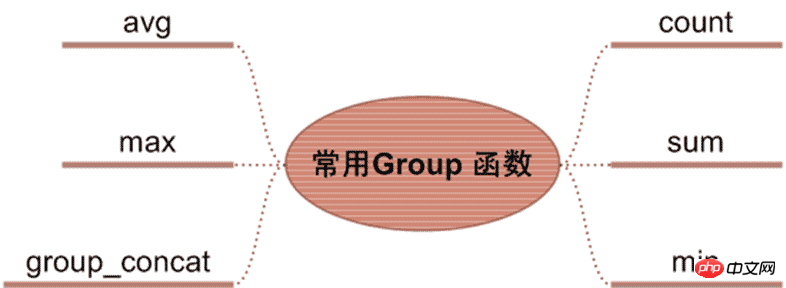
获得学生总人数:select count(*) from students
获得学生平均分:select avg(mark) from students
获得最高成绩:select max(mark) from students
获得最低成绩:select min(mark) from students
获得学生总成绩:select sum(mark) from students
5.3、删除数据
delete from 表名 [删除条件];
删除表中所有数据:delete from students;
删除id为10的行: delete from students where id=10;
删除所有年龄小于88岁的数据: delete from students where age<88;
#1、添加数据----- insert into stu(name,sex,age) values('张学友','男',18); insert into stu(name,sex,age) values('张娜拉','女',73); insert into stu(name,sex,age) values('张家辉','男',23); insert into stu(name,sex,age) values('张汇美','女',85); insert into stu(name,sex,age) values('张铁林','男',35); insert into stu(name,sex,age) values('张国立','男',99); #2、查询数据----- #2.1、查询所有学生 select id,name,sex,age from stu; #2.2、查询年龄大于80岁女学生 select id,name,sex,age from stu where age>80 and sex='女'; #2.3、查询平均年龄 select AVG(age) from stu where sex='女'; #3、修改数据----- #3.1、将编号为1的学生年龄加大1岁 update stu set age=age+1 where id=1; #3.2、将80岁以上的女学生年龄修改为90岁且将姓名后增加“老人” #CONCAT(str1,str2,...) 连接字符串 update stu set age=90,name=CONCAT(name,'(老人)') where age>=80 and sex='女'; #3.3、将编号4的学生名字修改为张汇美 update stu set name='张汇美' where id=4; #4、删除数据----- #4.1、删除年龄大于70岁的学生 delete from stu where age>70; #4.2、删除所有学生 delete from stu;
5.4、更新数据
update 语句可用来修改表中的数据, 基本的使用形式为:
update 表名称 set 列名称=新值 where 更新条件;
Update 表名 set 字段=值 列表 更新条件
使用示例:
将id为5的手机号改为默认的"-": update students set tel=default where id=5;
将所有人的年龄增加1: update students set age=age+1;
将手机号为 13723887766 的姓名改为 "张果", 年龄改为 19: update students set name="张果", age=19 where tel="13723887766";
5.5、修改表
alter table 语句用于创建后对表的修改, 基础用法如下:
5.5.1、添加列
基本形式: alter table 表名 add 列名 列数据类型 [after 插入位置];
示例:
在表的最后追加列 address: alter table students add address char(60);
在名为 age 的列后插入列 birthday: alter table students add birthday date after age;
5.5.2、修改列
基本形式: alter table 表名 change 列名称 列新名称 新数据类型;
示例:
将表 tel 列改名为 phone: alter table students change tel phone char(12) default "-";
将 name 列的数据类型改为 char(9): alter table students change name name char(9) not null;
5.5.3、删除列
基本形式: alter table 表名 drop 列名称;
示例:
删除 age 列: alter table students drop age;
5.5.4、重命名表
基本形式: alter table 表名 rename 新表名;
示例:
重命名 students 表为temp: alter table students rename temp;
5.5.5、删除表
基本形式: drop table 表名;
示例: 删除students表: drop table students;
5.5.6、删除数据库
基本形式: drop database 数据库名;
示例: 删除lcoa数据库: drop database lcoa;
5.5.7、一千行MySQL笔记
/* 启动MySQL */
net start mysql
/* 连接与断开服务器 */
mysql -h 地址 -P 端口 -u 用户名 -p 密码
/* 跳过权限验证登录MySQL */
mysqld --skip-grant-tables
-- 修改root密码
密码加密函数password()
update mysql.user set password=password('root');
SHOW PROCESSLIST -- 显示哪些线程正在运行
SHOW VARIABLES --
/* 数据库操作 */ ------------------
-- 查看当前数据库
select database();
-- 显示当前时间、用户名、数据库版本
select now(), user(), version();
-- 创建库
create database[ if not exists] 数据库名 数据库选项
数据库选项:
CHARACTER SET charset_name
COLLATE collation_name
-- 查看已有库
show databases[ like 'pattern']
-- 查看当前库信息
show create database 数据库名
-- 修改库的选项信息
alter database 库名 选项信息
-- 删除库
drop database[ if exists] 数据库名
同时删除该数据库相关的目录及其目录内容
/* 表的操作 */ ------------------
-- 创建表
create [temporary] table[ if not exists] [库名.]表名 ( 表的结构定义 )[ 表选项]
每个字段必须有数据类型
最后一个字段后不能有逗号
temporary 临时表,会话结束时表自动消失
对于字段的定义:
字段名 数据类型 [NOT NULL | NULL] [DEFAULT default_value] [AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY] [COMMENT 'string']
-- 表选项
-- 字符集
CHARSET = charset_name
如果表没有设定,则使用数据库字符集
-- 存储引擎
ENGINE = engine_name
表在管理数据时采用的不同的数据结构,结构不同会导致处理方式、提供的特性操作等不同
常见的引擎:InnoDB MyISAM Memory/Heap BDB Merge Example CSV MaxDB Archive
不同的引擎在保存表的结构和数据时采用不同的方式
MyISAM表文件含义:.frm表定义,.MYD表数据,.MYI表索引
InnoDB表文件含义:.frm表定义,表空间数据和日志文件
SHOW ENGINES -- 显示存储引擎的状态信息
SHOW ENGINE 引擎名 {LOGS|STATUS} -- 显示存储引擎的日志或状态信息
-- 数据文件目录
DATA DIRECTORY = '目录'
-- 索引文件目录
INDEX DIRECTORY = '目录'
-- 表注释
COMMENT = 'string'
-- 分区选项
PARTITION BY ... (详细见手册)
-- 查看所有表
SHOW TABLES[ LIKE 'pattern']
SHOW TABLES FROM 表名
-- 查看表机构
SHOW CREATE TABLE 表名 (信息更详细)
DESC 表名 / DESCRIBE 表名 / EXPLAIN 表名 / SHOW COLUMNS FROM 表名 [LIKE 'PATTERN']
SHOW TABLE STATUS [FROM db_name] [LIKE 'pattern']
-- 修改表
-- 修改表本身的选项
ALTER TABLE 表名 表的选项
EG: ALTER TABLE 表名 ENGINE=MYISAM;
-- 对表进行重命名
RENAME TABLE 原表名 TO 新表名
RENAME TABLE 原表名 TO 库名.表名 (可将表移动到另一个数据库)
-- RENAME可以交换两个表名
-- 修改表的字段机构
ALTER TABLE 表名 操作名
-- 操作名
ADD[ COLUMN] 字段名 -- 增加字段
AFTER 字段名 -- 表示增加在该字段名后面
FIRST -- 表示增加在第一个
ADD PRIMARY KEY(字段名) -- 创建主键
ADD UNIQUE [索引名] (字段名)-- 创建唯一索引
ADD INDEX [索引名] (字段名) -- 创建普通索引
ADD
DROP[ COLUMN] 字段名 -- 删除字段
MODIFY[ COLUMN] 字段名 字段属性 -- 支持对字段属性进行修改,不能修改字段名(所有原有属性也需写上)
CHANGE[ COLUMN] 原字段名 新字段名 字段属性 -- 支持对字段名修改
DROP PRIMARY KEY -- 删除主键(删除主键前需删除其AUTO_INCREMENT属性)
DROP INDEX 索引名 -- 删除索引
DROP FOREIGN KEY 外键 -- 删除外键
-- 删除表
DROP TABLE[ IF EXISTS] 表名 ...
-- 清空表数据
TRUNCATE [TABLE] 表名
-- 复制表结构
CREATE TABLE 表名 LIKE 要复制的表名
-- 复制表结构和数据
CREATE TABLE 表名 [AS] SELECT * FROM 要复制的表名
-- 检查表是否有错误
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
-- 优化表
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
-- 修复表
REPAIR [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... [QUICK] [EXTENDED] [USE_FRM]
-- 分析表
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
/* 数据操作 */ ------------------
-- 增
INSERT [INTO] 表名 [(字段列表)] VALUES (值列表)[, (值列表), ...]
-- 如果要插入的值列表包含所有字段并且顺序一致,则可以省略字段列表。
-- 可同时插入多条数据记录!
REPLACE 与 INSERT 完全一样,可互换。
INSERT [INTO] 表名 SET 字段名=值[, 字段名=值, ...]
-- 查
SELECT 字段列表 FROM 表名[ 其他子句]
-- 可来自多个表的多个字段
-- 其他子句可以不使用
-- 字段列表可以用*代替,表示所有字段
-- 删
DELETE FROM 表名[ 删除条件子句]
没有条件子句,则会删除全部
-- 改
UPDATE 表名 SET 字段名=新值[, 字段名=新值] [更新条件]
/* 字符集编码 */ ------------------
-- MySQL、数据库、表、字段均可设置编码
-- 数据编码与客户端编码不需一致
SHOW VARIABLES LIKE 'character_set_%' -- 查看所有字符集编码项
character_set_client 客户端向服务器发送数据时使用的编码
character_set_results 服务器端将结果返回给客户端所使用的编码
character_set_connection 连接层编码
SET 变量名 = 变量值
set character_set_client = gbk;
set character_set_results = gbk;
set character_set_connection = gbk;
SET NAMES GBK; -- 相当于完成以上三个设置
-- 校对集
校对集用以排序
SHOW CHARACTER SET [LIKE 'pattern']/SHOW CHARSET [LIKE 'pattern'] 查看所有字符集
SHOW COLLATION [LIKE 'pattern'] 查看所有校对集
charset 字符集编码 设置字符集编码
collate 校对集编码 设置校对集编码
/* 数据类型(列类型) */ ------------------
1. 数值类型
-- a. 整型 ----------
类型 字节 范围(有符号位)
tinyint 1字节 -128 ~ 127 无符号位:0 ~ 255
smallint 2字节 -32768 ~ 32767
mediumint 3字节 -8388608 ~ 8388607
int 4字节
bigint 8字节
int(M) M表示总位数
- 默认存在符号位,unsigned 属性修改
- 显示宽度,如果某个数不够定义字段时设置的位数,则前面以0补填,zerofill 属性修改
例:int(5) 插入一个数'123',补填后为'00123'
- 在满足要求的情况下,越小越好。
- 1表示bool值真,0表示bool值假。MySQL没有布尔类型,通过整型0和1表示。常用tinyint(1)表示布尔型。
-- b. 浮点型 ----------
类型 字节 范围
float(单精度) 4字节
double(双精度) 8字节
浮点型既支持符号位 unsigned 属性,也支持显示宽度 zerofill 属性。
不同于整型,前后均会补填0.
定义浮点型时,需指定总位数和小数位数。
float(M, D) double(M, D)
M表示总位数,D表示小数位数。
M和D的大小会决定浮点数的范围。不同于整型的固定范围。
M既表示总位数(不包括小数点和正负号),也表示显示宽度(所有显示符号均包括)。
支持科学计数法表示。
浮点数表示近似值。
-- c. 定点数 ----------
decimal -- 可变长度
decimal(M, D) M也表示总位数,D表示小数位数。
保存一个精确的数值,不会发生数据的改变,不同于浮点数的四舍五入。
将浮点数转换为字符串来保存,每9位数字保存为4个字节。
2. 字符串类型
-- a. char, varchar ----------
char 定长字符串,速度快,但浪费空间
varchar 变长字符串,速度慢,但节省空间
M表示能存储的最大长度,此长度是字符数,非字节数。
不同的编码,所占用的空间不同。
char,最多255个字符,与编码无关。
varchar,最多65535字符,与编码有关。
一条有效记录最大不能超过65535个字节。
utf8 最大为21844个字符,gbk 最大为32766个字符,latin1 最大为65532个字符
varchar 是变长的,需要利用存储空间保存 varchar 的长度,如果数据小于255个字节,则采用一个字节来保存长度,反之需要两个字节来保存。
varchar 的最大有效长度由最大行大小和使用的字符集确定。
最大有效长度是65532字节,因为在varchar存字符串时,第一个字节是空的,不存在任何数据,然后还需两个字节来存放字符串的长度,所以有效长度是64432-1-2=65532字节。
例:若一个表定义为 CREATE TABLE tb(c1 int, c2 char(30), c3 varchar(N)) charset=utf8; 问N的最大值是多少? 答:(65535-1-2-4-30*3)/3
-- b. blob, text ----------
blob 二进制字符串(字节字符串)
tinyblob, blob, mediumblob, longblob
text 非二进制字符串(字符字符串)
tinytext, text, mediumtext, longtext
text 在定义时,不需要定义长度,也不会计算总长度。
text 类型在定义时,不可给default值
-- c. binary, varbinary ----------
类似于char和varchar,用于保存二进制字符串,也就是保存字节字符串而非字符字符串。
char, varchar, text 对应 binary, varbinary, blob.
3. 日期时间类型
一般用整型保存时间戳,因为PHP可以很方便的将时间戳进行格式化。
datetime 8字节 日期及时间 1000-01-01 00:00:00 到 9999-12-31 23:59:59
date 3字节 日期 1000-01-01 到 9999-12-31
timestamp 4字节 时间戳 19700101000000 到 2038-01-19 03:14:07
time 3字节 时间 -838:59:59 到 838:59:59
year 1字节 年份 1901 - 2155
datetime “YYYY-MM-DD hh:mm:ss”
timestamp “YY-MM-DD hh:mm:ss”
“YYYYMMDDhhmmss”
“YYMMDDhhmmss”
YYYYMMDDhhmmss
YYMMDDhhmmss
date “YYYY-MM-DD”
“YY-MM-DD”
“YYYYMMDD”
“YYMMDD”
YYYYMMDD
YYMMDD
time “hh:mm:ss”
“hhmmss”
hhmmss
year “YYYY”
“YY”
YYYY
YY
4. 枚举和集合
-- 枚举(enum) ----------
enum(val1, val2, val3...)
在已知的值中进行单选。最大数量为65535.
枚举值在保存时,以2个字节的整型(smallint)保存。每个枚举值,按保存的位置顺序,从1开始逐一递增。
表现为字符串类型,存储却是整型。
NULL值的索引是NULL。
空字符串错误值的索引值是0。
-- 集合(set) ----------
set(val1, val2, val3...)
create table tab ( gender set('男', '女', '无') );
insert into tab values ('男, 女');
最多可以有64个不同的成员。以bigint存储,共8个字节。采取位运算的形式。
当创建表时,SET成员值的尾部空格将自动被删除。
/* 选择类型 */
-- PHP角度
1. 功能满足
2. 存储空间尽量小,处理效率更高
3. 考虑兼容问题
-- IP存储 ----------
1. 只需存储,可用字符串
2. 如果需计算,查找等,可存储为4个字节的无符号int,即unsigned
1) PHP函数转换
ip2long可转换为整型,但会出现携带符号问题。需格式化为无符号的整型。
利用sprintf函数格式化字符串
sprintf("%u", ip2long('192.168.3.134'));
然后用long2ip将整型转回IP字符串
2) MySQL函数转换(无符号整型,UNSIGNED)
INET_ATON('127.0.0.1') 将IP转为整型
INET_NTOA(2130706433) 将整型转为IP
/* 列属性(列约束) */ ------------------
1. 主键
- 能唯一标识记录的字段,可以作为主键。
- 一个表只能有一个主键。
- 主键具有唯一性。
- 声明字段时,用 primary key 标识。
也可以在字段列表之后声明
例:create table tab ( id int, stu varchar(10), primary key (id));
- 主键字段的值不能为null。
- 主键可以由多个字段共同组成。此时需要在字段列表后声明的方法。
例:create table tab ( id int, stu varchar(10), age int, primary key (stu, age));
2. unique 唯一索引(唯一约束)
使得某字段的值也不能重复。
3. null 约束
null不是数据类型,是列的一个属性。
表示当前列是否可以为null,表示什么都没有。
null, 允许为空。默认。
not null, 不允许为空。
insert into tab values (null, 'val');
-- 此时表示将第一个字段的值设为null, 取决于该字段是否允许为null
4. default 默认值属性
当前字段的默认值。
insert into tab values (default, 'val'); -- 此时表示强制使用默认值。
create table tab ( add_time timestamp default current_timestamp );
-- 表示将当前时间的时间戳设为默认值。
current_date, current_time
5. auto_increment 自动增长约束
自动增长必须为索引(主键或unique)
只能存在一个字段为自动增长。
默认为1开始自动增长。可以通过表属性 auto_increment = x进行设置,或 alter table tbl auto_increment = x;
6. comment 注释
例:create table tab ( id int ) comment '注释内容';
7. foreign key 外键约束
用于限制主表与从表数据完整性。
alter table t1 add constraint `t1_t2_fk` foreign key (t1_id) references t2(id);
-- 将表t1的t1_id外键关联到表t2的id字段。
-- 每个外键都有一个名字,可以通过 constraint 指定
存在外键的表,称之为从表(子表),外键指向的表,称之为主表(父表)。
作用:保持数据一致性,完整性,主要目的是控制存储在外键表(从表)中的数据。
MySQL中,可以对InnoDB引擎使用外键约束:
语法:
foreign key (外键字段) references 主表名 (关联字段) [主表记录删除时的动作] [主表记录更新时的动作]
此时需要检测一个从表的外键需要约束为主表的已存在的值。外键在没有关联的情况下,可以设置为null.前提是该外键列,没有not null。
可以不指定主表记录更改或更新时的动作,那么此时主表的操作被拒绝。
如果指定了 on update 或 on delete:在删除或更新时,有如下几个操作可以选择:
1. cascade,级联操作。主表数据被更新(主键值更新),从表也被更新(外键值更新)。主表记录被删除,从表相关记录也被删除。
2. set null,设置为null。主表数据被更新(主键值更新),从表的外键被设置为null。主表记录被删除,从表相关记录外键被设置成null。但注意,要求该外键列,没有not null属性约束。
3. restrict,拒绝父表删除和更新。
注意,外键只被InnoDB存储引擎所支持。其他引擎是不支持的。
/* 建表规范 */ ------------------
-- Normal Format, NF
- 每个表保存一个实体信息
- 每个具有一个ID字段作为主键
- ID主键 + 原子表
-- 1NF, 第一范式
字段不能再分,就满足第一范式。
-- 2NF, 第二范式
满足第一范式的前提下,不能出现部分依赖。
消除符合主键就可以避免部分依赖。增加单列关键字。
-- 3NF, 第三范式
满足第二范式的前提下,不能出现传递依赖。
某个字段依赖于主键,而有其他字段依赖于该字段。这就是传递依赖。
将一个实体信息的数据放在一个表内实现。
/* select */ ------------------
select [all|distinct] select_expr from -> where -> group by [合计函数] -> having -> order by -> limit
a. select_expr
-- 可以用 * 表示所有字段。
select * from tb;
-- 可以使用表达式(计算公式、函数调用、字段也是个表达式)
select stu, 29+25, now() from tb;
-- 可以为每个列使用别名。适用于简化列标识,避免多个列标识符重复。
- 使用 as 关键字,也可省略 as.
select stu+10 as add10 from tb;
b. from 子句
用于标识查询来源。
-- 可以为表起别名。使用as关键字。
select * from tb1 as tt, tb2 as bb;
-- from子句后,可以同时出现多个表。
-- 多个表会横向叠加到一起,而数据会形成一个笛卡尔积。
select * from tb1, tb2;
c. where 子句
-- 从from获得的数据源中进行筛选。
-- 整型1表示真,0表示假。
-- 表达式由运算符和运算数组成。
-- 运算数:变量(字段)、值、函数返回值
-- 运算符:
=, <=>, <>, !=, <=, <, >=, >, !, &&, ||,
in (not) null, (not) like, (not) in, (not) between and, is (not), and, or, not, xor
is/is not 加上ture/false/unknown,检验某个值的真假
<=>与<>功能相同,<=>可用于null比较
d. group by 子句, 分组子句
group by 字段/别名 [排序方式]
分组后会进行排序。升序:ASC,降序:DESC
以下[合计函数]需配合 group by 使用:
count 返回不同的非NULL值数目 count(*)、count(字段)
sum 求和
max 求最大值
min 求最小值
avg 求平均值
group_concat 返回带有来自一个组的连接的非NULL值的字符串结果。组内字符串连接。
e. having 子句,条件子句
与 where 功能、用法相同,执行时机不同。
where 在开始时执行检测数据,对原数据进行过滤。
having 对筛选出的结果再次进行过滤。
having 字段必须是查询出来的,where 字段必须是数据表存在的。
where 不可以使用字段的别名,having 可以。因为执行WHERE代码时,可能尚未确定列值。
where 不可以使用合计函数。一般需用合计函数才会用 having
SQL标准要求HAVING必须引用GROUP BY子句中的列或用于合计函数中的列。
f. order by 子句,排序子句
order by 排序字段/别名 排序方式 [,排序字段/别名 排序方式]...
升序:ASC,降序:DESC
支持多个字段的排序。
g. limit 子句,限制结果数量子句
仅对处理好的结果进行数量限制。将处理好的结果的看作是一个集合,按照记录出现的顺序,索引从0开始。
limit 起始位置, 获取条数
省略第一个参数,表示从索引0开始。limit 获取条数
h. distinct, all 选项
distinct 去除重复记录
默认为 all, 全部记录
/* UNION */ ------------------
将多个select查询的结果组合成一个结果集合。
SELECT ... UNION [ALL|DISTINCT] SELECT ...
默认 DISTINCT 方式,即所有返回的行都是唯一的
建议,对每个SELECT查询加上小括号包裹。
ORDER BY 排序时,需加上 LIMIT 进行结合。
需要各select查询的字段数量一样。
每个select查询的字段列表(数量、类型)应一致,因为结果中的字段名以第一条select语句为准。
/* 子查询 */ ------------------
- 子查询需用括号包裹。
-- from型
from后要求是一个表,必须给子查询结果取个别名。
- 简化每个查询内的条件。
- from型需将结果生成一个临时表格,可用以原表的锁定的释放。
- 子查询返回一个表,表型子查询。
select * from (select * from tb where id>0) as subfrom where id>1;
-- where型
- 子查询返回一个值,标量子查询。
- 不需要给子查询取别名。
- where子查询内的表,不能直接用以更新。
select * from tb where money = (select max(money) from tb);
-- 列子查询
如果子查询结果返回的是一列。
使用 in 或 not in 完成查询
exists 和 not exists 条件
如果子查询返回数据,则返回1或0。常用于判断条件。
select column1 from t1 where exists (select * from t2);
-- 行子查询
查询条件是一个行。
select * from t1 where (id, gender) in (select id, gender from t2);
行构造符:(col1, col2, ...) 或 ROW(col1, col2, ...)
行构造符通常用于与对能返回两个或两个以上列的子查询进行比较。
-- 特殊运算符
!= all() 相当于 not in
= some() 相当于 in。any 是 some 的别名
!= some() 不等同于 not in,不等于其中某一个。
all, some 可以配合其他运算符一起使用。
/* 连接查询(join) */ ------------------
将多个表的字段进行连接,可以指定连接条件。
-- 内连接(inner join)
- 默认就是内连接,可省略inner。
- 只有数据存在时才能发送连接。即连接结果不能出现空行。
on 表示连接条件。其条件表达式与where类似。也可以省略条件(表示条件永远为真)
也可用where表示连接条件。
还有 using, 但需字段名相同。 using(字段名)
-- 交叉连接 cross join
即,没有条件的内连接。
select * from tb1 cross join tb2;
-- 外连接(outer join)
- 如果数据不存在,也会出现在连接结果中。
-- 左外连接 left join
如果数据不存在,左表记录会出现,而右表为null填充
-- 右外连接 right join
如果数据不存在,右表记录会出现,而左表为null填充
-- 自然连接(natural join)
自动判断连接条件完成连接。
相当于省略了using,会自动查找相同字段名。
natural join
natural left join
natural right join
select info.id, info.name, info.stu_num, extra_info.hobby, extra_info.sex from info, extra_info where info.stu_num = extra_info.stu_id;
/* 导入导出 */ ------------------
select * into outfile 文件地址 [控制格式] from 表名; -- 导出表数据
load data [local] infile 文件地址 [replace|ignore] into table 表名 [控制格式]; -- 导入数据
生成的数据默认的分隔符是制表符
local未指定,则数据文件必须在服务器上
replace 和 ignore 关键词控制对现有的唯一键记录的重复的处理
-- 控制格式
fields 控制字段格式
默认:fields terminated by '\t' enclosed by '' escaped by '\\'
terminated by 'string' -- 终止
enclosed by 'char' -- 包裹
escaped by 'char' -- 转义
-- 示例:
SELECT a,b,a+b INTO OUTFILE '/tmp/result.text'
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
FROM test_table;
lines 控制行格式
默认:lines terminated by '\n'
terminated by 'string' -- 终止
/* insert */ ------------------
select语句获得的数据可以用insert插入。
可以省略对列的指定,要求 values () 括号内,提供给了按照列顺序出现的所有字段的值。
或者使用set语法。
insert into tbl_name set field=value,...;
可以一次性使用多个值,采用(), (), ();的形式。
insert into tbl_name values (), (), ();
可以在列值指定时,使用表达式。
insert into tbl_name values (field_value, 10+10, now());
可以使用一个特殊值 default,表示该列使用默认值。
insert into tbl_name values (field_value, default);
可以通过一个查询的结果,作为需要插入的值。
insert into tbl_name select ...;
可以指定在插入的值出现主键(或唯一索引)冲突时,更新其他非主键列的信息。
insert into tbl_name values/set/select on duplicate key update 字段=值, …;
/* delete */ ------------------
DELETE FROM tbl_name [WHERE where_definition] [ORDER BY ...] [LIMIT row_count]
按照条件删除
指定删除的最多记录数。Limit
可以通过排序条件删除。order by + limit
支持多表删除,使用类似连接语法。
delete from 需要删除数据多表1,表2 using 表连接操作 条件。
/* truncate */ ------------------
TRUNCATE [TABLE] tbl_name
清空数据
删除重建表
区别:
1,truncate 是删除表再创建,delete 是逐条删除
2,truncate 重置auto_increment的值。而delete不会
3,truncate 不知道删除了几条,而delete知道。
4,当被用于带分区的表时,truncate 会保留分区
/* 备份与还原 */ ------------------
备份,将数据的结构与表内数据保存起来。
利用 mysqldump 指令完成。
-- 导出
1. 导出一张表
mysqldump -u用户名 -p密码 库名 表名 > 文件名(D:/a.sql)
2. 导出多张表
mysqldump -u用户名 -p密码 库名 表1 表2 表3 > 文件名(D:/a.sql)
3. 导出所有表
mysqldump -u用户名 -p密码 库名 > 文件名(D:/a.sql)
4. 导出一个库
mysqldump -u用户名 -p密码 -B 库名 > 文件名(D:/a.sql)
可以-w携带备份条件
-- 导入
1. 在登录mysql的情况下:
source 备份文件
2. 在不登录的情况下
mysql -u用户名 -p密码 库名 < 备份文件
/* 视图 */ ------------------
什么是视图:
视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。
视图具有表结构文件,但不存在数据文件。
对其中所引用的基础表来说,视图的作用类似于筛选。定义视图的筛选可以来自当前或其它数据库的一个或多个表,或者其它视图。通过视图进行查询没有任何限制,通过它们进行数据修改时的限制也很少。
视图是存储在数据库中的查询的sql语句,它主要出于两种原因:安全原因,视图可以隐藏一些数据,如:社会保险基金表,可以用视图只显示姓名,地址,而不显示社会保险号和工资数等,另一原因是可使复杂的查询易于理解和使用。
-- 创建视图
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name [(column_list)] AS select_statement
- 视图名必须唯一,同时不能与表重名。
- 视图可以使用select语句查询到的列名,也可以自己指定相应的列名。
- 可以指定视图执行的算法,通过ALGORITHM指定。
- column_list如果存在,则数目必须等于SELECT语句检索的列数
-- 查看结构
SHOW CREATE VIEW view_name
-- 删除视图
- 删除视图后,数据依然存在。
- 可同时删除多个视图。
DROP VIEW [IF EXISTS] view_name ...
-- 修改视图结构
- 一般不修改视图,因为不是所有的更新视图都会映射到表上。
ALTER VIEW view_name [(column_list)] AS select_statement
-- 视图作用
1. 简化业务逻辑
2. 对客户端隐藏真实的表结构
-- 视图算法(ALGORITHM)
MERGE 合并
将视图的查询语句,与外部查询需要先合并再执行!
TEMPTABLE 临时表
将视图执行完毕后,形成临时表,再做外层查询!
UNDEFINED 未定义(默认),指的是MySQL自主去选择相应的算法。
/* 事务(transaction) */ ------------------
事务是指逻辑上的一组操作,组成这组操作的各个单元,要不全成功要不全失败。
- 支持连续SQL的集体成功或集体撤销。
- 事务是数据库在数据晚自习方面的一个功能。
- 需要利用 InnoDB 或 BDB 存储引擎,对自动提交的特性支持完成。
- InnoDB被称为事务安全型引擎。
-- 事务开启
START TRANSACTION; 或者 BEGIN;
开启事务后,所有被执行的SQL语句均被认作当前事务内的SQL语句。
-- 事务提交
COMMIT;
-- 事务回滚
ROLLBACK;
如果部分操作发生问题,映射到事务开启前。
-- 事务的特性
1. 原子性(Atomicity)
事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
2. 一致性(Consistency)
事务前后数据的完整性必须保持一致。
- 事务开始和结束时,外部数据一致
- 在整个事务过程中,操作是连续的
3. 隔离性(Isolation)
多个用户并发访问数据库时,一个用户的事务不能被其它用户的事物所干扰,多个并发事务之间的数据要相互隔离。
4. 持久性(Durability)
一个事务一旦被提交,它对数据库中的数据改变就是永久性的。
-- 事务的实现
1. 要求是事务支持的表类型
2. 执行一组相关的操作前开启事务
3. 整组操作完成后,都成功,则提交;如果存在失败,选择回滚,则会回到事务开始的备份点。
-- 事务的原理
利用InnoDB的自动提交(autocommit)特性完成。
普通的MySQL执行语句后,当前的数据提交操作均可被其他客户端可见。
而事务是暂时关闭“自动提交”机制,需要commit提交持久化数据操作。
-- 注意
1. 数据定义语言(DDL)语句不能被回滚,比如创建或取消数据库的语句,和创建、取消或更改表或存储的子程序的语句。
2. 事务不能被嵌套
-- 保存点
SAVEPOINT 保存点名称 -- 设置一个事务保存点
ROLLBACK TO SAVEPOINT 保存点名称 -- 回滚到保存点
RELEASE SAVEPOINT 保存点名称 -- 删除保存点
-- InnoDB自动提交特性设置
SET autocommit = 0|1; 0表示关闭自动提交,1表示开启自动提交。
- 如果关闭了,那普通操作的结果对其他客户端也不可见,需要commit提交后才能持久化数据操作。
- 也可以关闭自动提交来开启事务。但与START TRANSACTION不同的是,
SET autocommit是永久改变服务器的设置,直到下次再次修改该设置。(针对当前连接)
而START TRANSACTION记录开启前的状态,而一旦事务提交或回滚后就需要再次开启事务。(针对当前事务)
/* 锁表 */
表锁定只用于防止其它客户端进行不正当地读取和写入
MyISAM 支持表锁,InnoDB 支持行锁
-- 锁定
LOCK TABLES tbl_name [AS alias]
-- 解锁
UNLOCK TABLES
/* 触发器 */ ------------------
触发程序是与表有关的命名数据库对象,当该表出现特定事件时,将激活该对象
监听:记录的增加、修改、删除。
-- 创建触发器
CREATE TRIGGER trigger_name trigger_time trigger_event ON tbl_name FOR EACH ROW trigger_stmt
参数:
trigger_time是触发程序的动作时间。它可以是 before 或 after,以指明触发程序是在激活它的语句之前或之后触发。
trigger_event指明了激活触发程序的语句的类型
INSERT:将新行插入表时激活触发程序
UPDATE:更改某一行时激活触发程序
DELETE:从表中删除某一行时激活触发程序
tbl_name:监听的表,必须是永久性的表,不能将触发程序与TEMPORARY表或视图关联起来。
trigger_stmt:当触发程序激活时执行的语句。执行多个语句,可使用BEGIN...END复合语句结构
-- 删除
DROP TRIGGER [schema_name.]trigger_name
可以使用old和new代替旧的和新的数据
更新操作,更新前是old,更新后是new.
删除操作,只有old.
增加操作,只有new.
-- 注意
1. 对于具有相同触发程序动作时间和事件的给定表,不能有两个触发程序。
-- 字符连接函数
concat(str1[, str2,...])
-- 分支语句
if 条件 then
执行语句
elseif 条件 then
执行语句
else
执行语句
end if;
-- 修改最外层语句结束符
delimiter 自定义结束符号
SQL语句
自定义结束符号
delimiter ; -- 修改回原来的分号
-- 语句块包裹
begin
语句块
end
-- 特殊的执行
1. 只要添加记录,就会触发程序。
2. Insert into on duplicate key update 语法会触发:
如果没有重复记录,会触发 before insert, after insert;
如果有重复记录并更新,会触发 before insert, before update, after update;
如果有重复记录但是没有发生更新,则触发 before insert, before update
3. Replace 语法 如果有记录,则执行 before insert, before delete, after delete, after insert
/* SQL编程 */ ------------------
--// 局部变量 ----------
-- 变量声明
declare var_name[,...] type [default value]
这个语句被用来声明局部变量。要给变量提供一个默认值,请包含一个default子句。值可以被指定为一个表达式,不需要为一个常数。如果没有default子句,初始值为null。
-- 赋值
使用 set 和 select into 语句为变量赋值。
- 注意:在函数内是可以使用全局变量(用户自定义的变量)
--// 全局变量 ----------
-- 定义、赋值
set 语句可以定义并为变量赋值。
set @var = value;
也可以使用select into语句为变量初始化并赋值。这样要求select语句只能返回一行,但是可以是多个字段,就意味着同时为多个变量进行赋值,变量的数量需要与查询的列数一致。
还可以把赋值语句看作一个表达式,通过select执行完成。此时为了避免=被当作关系运算符看待,使用:=代替。(set语句可以使用= 和 :=)。
select @var:=20;
select @v1:=id, @v2=name from t1 limit 1;
select * from tbl_name where @var:=30;
select into 可以将表中查询获得的数据赋给变量。
-| select max(height) into @max_height from tb;
-- 自定义变量名
为了避免select语句中,用户自定义的变量与系统标识符(通常是字段名)冲突,用户自定义变量在变量名前使用@作为开始符号。
@var=10;
- 变量被定义后,在整个会话周期都有效(登录到退出)
--// 控制结构 ----------
-- if语句
if search_condition then
statement_list
[elseif search_condition then
statement_list]
...
[else
statement_list]
end if;
-- case语句
CASE value WHEN [compare-value] THEN result
[WHEN [compare-value] THEN result ...]
[ELSE result]
END
-- while循环
[begin_label:] while search_condition do
statement_list
end while [end_label];
- 如果需要在循环内提前终止 while循环,则需要使用标签;标签需要成对出现。
-- 退出循环
退出整个循环 leave
退出当前循环 iterate
通过退出的标签决定退出哪个循环
--// 内置函数 ----------
-- 数值函数
abs(x) -- 绝对值 abs(-10.9) = 10
format(x, d) -- 格式化千分位数值 format(1234567.456, 2) = 1,234,567.46
ceil(x) -- 向上取整 ceil(10.1) = 11
floor(x) -- 向下取整 floor (10.1) = 10
round(x) -- 四舍五入去整
mod(m, n) -- m%n m mod n 求余 10%3=1
pi() -- 获得圆周率
pow(m, n) -- m^n
sqrt(x) -- 算术平方根
rand() -- 随机数
truncate(x, d) -- 截取d位小数
-- 时间日期函数
now(), current_timestamp(); -- 当前日期时间
current_date(); -- 当前日期
current_time(); -- 当前时间
date('yyyy-mm-dd hh:ii:ss'); -- 获取日期部分
time('yyyy-mm-dd hh:ii:ss'); -- 获取时间部分
date_format('yyyy-mm-dd hh:ii:ss', '%d %y %a %d %m %b %j'); -- 格式化时间
unix_timestamp(); -- 获得unix时间戳
from_unixtime(); -- 从时间戳获得时间
-- 字符串函数
length(string) -- string长度,字节
char_length(string) -- string的字符个数
substring(str, position [,length]) -- 从str的position开始,取length个字符
replace(str ,search_str ,replace_str) -- 在str中用replace_str替换search_str
instr(string ,substring) -- 返回substring首次在string中出现的位置
concat(string [,...]) -- 连接字串
charset(str) -- 返回字串字符集
lcase(string) -- 转换成小写
left(string, length) -- 从string2中的左边起取length个字符
load_file(file_name) -- 从文件读取内容
locate(substring, string [,start_position]) -- 同instr,但可指定开始位置
lpad(string, length, pad) -- 重复用pad加在string开头,直到字串长度为length
ltrim(string) -- 去除前端空格
repeat(string, count) -- 重复count次
rpad(string, length, pad) --在str后用pad补充,直到长度为length
rtrim(string) -- 去除后端空格
strcmp(string1 ,string2) -- 逐字符比较两字串大小
-- 流程函数
case when [condition] then result [when [condition] then result ...] [else result] end 多分支
if(expr1,expr2,expr3) 双分支。
-- 聚合函数
count()
sum();
max();
min();
avg();
group_concat()
-- 其他常用函数
md5();
default();
--// 存储函数,自定义函数 ----------
-- 新建
CREATE FUNCTION function_name (参数列表) RETURNS 返回值类型
函数体
- 函数名,应该合法的标识符,并且不应该与已有的关键字冲突。
- 一个函数应该属于某个数据库,可以使用db_name.funciton_name的形式执行当前函数所属数据库,否则为当前数据库。
- 参数部分,由"参数名"和"参数类型"组成。多个参数用逗号隔开。
- 函数体由多条可用的mysql语句,流程控制,变量声明等语句构成。
- 多条语句应该使用 begin...end 语句块包含。
- 一定要有 return 返回值语句。
-- 删除
DROP FUNCTION [IF EXISTS] function_name;
-- 查看
SHOW FUNCTION STATUS LIKE 'partten'
SHOW CREATE FUNCTION function_name;
-- 修改
ALTER FUNCTION function_name 函数选项
--// 存储过程,自定义功能 ----------
-- 定义
存储存储过程 是一段代码(过程),存储在数据库中的sql组成。
一个存储过程通常用于完成一段业务逻辑,例如报名,交班费,订单入库等。
而一个函数通常专注与某个功能,视为其他程序服务的,需要在其他语句中调用函数才可以,而存储过程不能被其他调用,是自己执行 通过call执行。
-- 创建
CREATE PROCEDURE sp_name (参数列表)
过程体
参数列表:不同于函数的参数列表,需要指明参数类型
IN,表示输入型
OUT,表示输出型
INOUT,表示混合型
注意,没有返回值。
/* 存储过程 */ ------------------
存储过程是一段可执行性代码的集合。相比函数,更偏向于业务逻辑。
调用:CALL 过程名
-- 注意
- 没有返回值。
- 只能单独调用,不可夹杂在其他语句中
-- 参数
IN|OUT|INOUT 参数名 数据类型
IN 输入:在调用过程中,将数据输入到过程体内部的参数
OUT 输出:在调用过程中,将过程体处理完的结果返回到客户端
INOUT 输入输出:既可输入,也可输出
-- 语法
CREATE PROCEDURE 过程名 (参数列表)
BEGIN
过程体
END
/* 用户和权限管理 */ ------------------
用户信息表:mysql.user
-- 刷新权限
FLUSH PRIVILEGES
-- 增加用户
CREATE USER 用户名 IDENTIFIED BY [PASSWORD] 密码(字符串)
- 必须拥有mysql数据库的全局CREATE USER权限,或拥有INSERT权限。
- 只能创建用户,不能赋予权限。
- 用户名,注意引号:如 'user_name'@'192.168.1.1'
- 密码也需引号,纯数字密码也要加引号
- 要在纯文本中指定密码,需忽略PASSWORD关键词。要把密码指定为由PASSWORD()函数返回的混编值,需包含关键字PASSWORD
-- 重命名用户
RENAME USER old_user TO new_user
-- 设置密码
SET PASSWORD = PASSWORD('密码') -- 为当前用户设置密码
SET PASSWORD FOR 用户名 = PASSWORD('密码') -- 为指定用户设置密码
-- 删除用户
DROP USER 用户名
-- 分配权限/添加用户
GRANT 权限列表 ON 表名 TO 用户名 [IDENTIFIED BY [PASSWORD] 'password']
- all privileges 表示所有权限
- *.* 表示所有库的所有表
- 库名.表名 表示某库下面的某表
-- 查看权限
SHOW GRANTS FOR 用户名
-- 查看当前用户权限
SHOW GRANTS; 或 SHOW GRANTS FOR CURRENT_USER; 或 SHOW GRANTS FOR CURRENT_USER();
-- 撤消权限
REVOKE 权限列表 ON 表名 FROM 用户名
REVOKE ALL PRIVILEGES, GRANT OPTION FROM 用户名 -- 撤销所有权限
-- 权限层级
-- 要使用GRANT或REVOKE,您必须拥有GRANT OPTION权限,并且您必须用于您正在授予或撤销的权限。
全局层级:全局权限适用于一个给定服务器中的所有数据库,mysql.user
GRANT ALL ON *.*和 REVOKE ALL ON *.*只授予和撤销全局权限。
数据库层级:数据库权限适用于一个给定数据库中的所有目标,mysql.db, mysql.host
GRANT ALL ON db_name.*和REVOKE ALL ON db_name.*只授予和撤销数据库权限。
表层级:表权限适用于一个给定表中的所有列,mysql.talbes_priv
GRANT ALL ON db_name.tbl_name和REVOKE ALL ON db_name.tbl_name只授予和撤销表权限。
列层级:列权限适用于一个给定表中的单一列,mysql.columns_priv
当使用REVOKE时,您必须指定与被授权列相同的列。
-- 权限列表
ALL [PRIVILEGES] -- 设置除GRANT OPTION之外的所有简单权限
ALTER -- 允许使用ALTER TABLE
ALTER ROUTINE -- 更改或取消已存储的子程序
CREATE -- 允许使用CREATE TABLE
CREATE ROUTINE -- 创建已存储的子程序
CREATE TEMPORARY TABLES -- 允许使用CREATE TEMPORARY TABLE
CREATE USER -- 允许使用CREATE USER, DROP USER, RENAME USER和REVOKE ALL PRIVILEGES。
CREATE VIEW -- 允许使用CREATE VIEW
DELETE -- 允许使用DELETE
DROP -- 允许使用DROP TABLE
EXECUTE -- 允许用户运行已存储的子程序
FILE -- 允许使用SELECT...INTO OUTFILE和LOAD DATA INFILE
INDEX -- 允许使用CREATE INDEX和DROP INDEX
INSERT -- 允许使用INSERT
LOCK TABLES -- 允许对您拥有SELECT权限的表使用LOCK TABLES
PROCESS -- 允许使用SHOW FULL PROCESSLIST
REFERENCES -- 未被实施
RELOAD -- 允许使用FLUSH
REPLICATION CLIENT -- 允许用户询问从属服务器或主服务器的地址
REPLICATION SLAVE -- 用于复制型从属服务器(从主服务器中读取二进制日志事件)
SELECT -- 允许使用SELECT
SHOW DATABASES -- 显示所有数据库
SHOW VIEW -- 允许使用SHOW CREATE VIEW
SHUTDOWN -- 允许使用mysqladmin shutdown
SUPER -- 允许使用CHANGE MASTER, KILL, PURGE MASTER LOGS和SET GLOBAL语句,mysqladmin debug命令;允许您连接(一次),即使已达到max_connections。
UPDATE -- 允许使用UPDATE
USAGE -- “无权限”的同义词
GRANT OPTION -- 允许授予权限
/* 表维护 */
-- 分析和存储表的关键字分布
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE 表名 ...
-- 检查一个或多个表是否有错误
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
-- 整理数据文件的碎片
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
/* 杂项 */ ------------------
1. 可用反引号(`)为标识符(库名、表名、字段名、索引、别名)包裹,以避免与关键字重名!中文也可以作为标识符!
2. 每个库目录存在一个保存当前数据库的选项文件db.opt。
3. 注释:
单行注释 # 注释内容
多行注释 /* 注释内容 */
单行注释 -- 注释内容 (标准SQL注释风格,要求双破折号后加一空格符(空格、TAB、换行等))
4. 模式通配符:
_ 任意单个字符
% 任意多个字符,甚至包括零字符
单引号需要进行转义 \'
5. CMD命令行内的语句结束符可以为 ";", "\G", "\g",仅影响显示结果。其他地方还是用分号结束。delimiter 可修改当前对话的语句结束符。
6. SQL对大小写不敏感
7. 清除已有语句:\c5.5.8、常用的SQL
/*==============================================================*/ /* DBMS name: MySQL 5.0 */ /* Created on: 2017/3/5 10:29:05 */ /*==============================================================*/ drop table if exists Address; drop table if exists ArticleComment; drop table if exists ArticleType; drop table if exists Articles; drop table if exists DictSub; drop table if exists DictTop; drop table if exists OrderPdt; drop table if exists Orders; drop table if exists ProductComment; drop table if exists Products; drop table if exists Users; /*==============================================================*/ /* Table: Address */ /*==============================================================*/ create table Address ( `AddressId` int not null auto_increment comment '收货地址编号', `UserId` int not null comment '用户编号', `Province` varchar(50) not null comment '省', `City` varchar(50) not null comment '市', `County` varchar(50) not null comment '县/区', `Street` varchar(300) not null comment '详细地址', `RevName` varchar(30) not null comment '收货人姓名', `PostCode` varchar(20) comment '邮政编码', `Mobile` varchar(50) not null comment '手机', `Phone` varchar(50) comment '电话', `IsDefault` bool comment '是否为默认地址', primary key (AddressId) ); alter table Address comment '收货地址'; /*==============================================================*/ /* Table: ArticleComment */ /*==============================================================*/ create table ArticleComment ( `ArticleCommentId` int not null auto_increment comment '文章评论编号', `ArticleId` int not null comment '文章编号', `UserId` int not null comment '用户编号', `ArticleCommentContent` varchar(4000) not null comment '文章评论内容', `ArticleCommentDate` timestamp default CURRENT_TIMESTAMP comment '文章评论时间', `ArticleCommentState` int default 1 comment '状态', `ArticleRemark` int comment '打分', `ArticleCommentReserver1` varchar(4000) comment '备用1', `ArticleCommentReserver2` varchar(4000) comment '备用2', primary key (ArticleCommentId) ); alter table ArticleComment comment '文章评论'; /*==============================================================*/ /* Table: ArticleType */ /*==============================================================*/ create table ArticleType ( `ArticleTypeId` int not null auto_increment comment '文章栏目编号', `ArticleTypeName` varchar(200) comment '文章栏目名称', `ArticleTypeState` int default 1 comment '状态', `ArticleTypeDesc` varchar(4000) comment '文章栏目描述', `ArticleTypePicture` varchar(400) comment '文章栏目图片', `ArticleTypeReserve1` varchar(4000) comment '备用1', `ArticleTypeReserve2` varchar(4000) comment '备用2', primary key (ArticleTypeId) ); alter table ArticleType comment '文章栏目'; /*==============================================================*/ /* Table: Articles */ /*==============================================================*/ create table Articles ( `ArticleId` int not null auto_increment comment '文章编号', `ArticleTypeId` int not null comment '文章栏目编号', `ArticleTitle` varchar(400) not null comment '文章标题', `ArticleContent` text comment '文章内容', `ArticleDate` timestamp default CURRENT_TIMESTAMP comment '文章发布时间', `ArticleAuthor` varchar(200) comment '文章发布者', `ArticleFileName` varchar(100) comment '静态文件名', `ArticleThumbNail` varchar(200) comment '缩略图片', `ArticleAddition` varchar(200) comment '附件名称', `ArticleLevel` int comment '显示的优先级', `ArticleIsAllowComment` integer default 1 comment '是否允许评论', `ArticleState` int default 1 comment '状态', `ArticleHotCount` int comment '点击次数', `ArticleReserve1` varchar(4000) comment '备用1', `ArticleReserve2` varchar(4000) comment '备用2', `ArticleReserve3` numeric(8,0) comment '备用3', primary key (ArticleId) ); alter table Articles comment '文章'; /*==============================================================*/ /* Table: DictSub */ /*==============================================================*/ create table DictSub ( `SubId` int not null auto_increment comment '子项编号', `DictId` int not null comment '字典编号', `SubName` varchar(200) not null comment '子项名称', `SubDesc` varchar(4000) comment '子项描述', `SubReserve1` varchar(4000) comment '保留备用1', primary key (SubId) ); alter table DictSub comment '字典子项'; /*==============================================================*/ /* Table: DictTop */ /*==============================================================*/ create table DictTop ( `DictId` int not null auto_increment comment '字典编号', `DictName` varchar(100) not null comment '字典名称', `DictDesc` varchar(4000) comment '字典描述', `DictReserve1` varchar(4000) comment '保留备用', primary key (DictId) ); alter table DictTop comment '字典'; /*==============================================================*/ /* Table: OrderPdt */ /*==============================================================*/ create table OrderPdt ( `OrderPdtId` int not null auto_increment comment '订单商品编号', `Id` int not null comment '编号', `UserId` int not null comment '用户编号', `OrderId` int comment '订单号', `PdtAmount` int comment '订购数量', `PdtPrice` decimal comment '单价', `PdtReserve1` varchar(2000) comment '备用1', `PdtReserve2` varchar(4000) comment '备用2', primary key (OrderPdtId) ); alter table OrderPdt comment '订单商品'; /*==============================================================*/ /* Table: Orders */ /*==============================================================*/ create table Orders ( `OrderId` int not null auto_increment comment '订单号', `AddressId` int not null comment '收货地址编号', `OrderState` int default 1 comment '订单状态', `ExpressNO` varchar(50) comment '快递编号', `ExpressName` varchar(50) comment '快递名称', `PayMoney` decimal comment '应支付', `PayedMoney` decimal comment '已支付', `SendInfo` varchar(300) comment '发货人信息', `BuyDate` timestamp default CURRENT_TIMESTAMP comment '下单时间', `PayDate` datetime comment '支付时间', `SendDate` datetime comment '发货时间', `ReceivDate` datetime comment '收货时间', `OrderMessage` varchar(4000) comment '附言', `UserId` integer comment '用户编号', `OrderReserve1` varchar(4000) comment '备用1', `OrderReserve2` varchar(4000) comment '备用2', `OrderReserve3` decimal comment '备用3', primary key (OrderId) ); alter table Orders comment '订单'; /*==============================================================*/ /* Table: ProductComment */ /*==============================================================*/ create table ProductComment ( `ProductCommentId` int not null auto_increment comment '商品评论编号', `ProductId` int not null comment '商品编号', `UserId` int not null comment '用户编号', `ProductCommentContent` varchar(4000) comment '商品评论内容', `ProductCommentDate` timestamp default CURRENT_TIMESTAMP comment '商品评论时间', `ProductCommentState` int comment '状态', `ProductCommentRemark` int comment '打分', `ProductCommentReserve1` varchar(4000) comment '备用1', `ProductCommentReserve2` varchar(4000) comment '备用2', primary key (ProductCommentId) ); alter table ProductComment comment '商品评论'; /*==============================================================*/ /* Table: Products */ /*==============================================================*/ create table Products ( `Id` int not null auto_increment comment '编号', `Name` varchar(200) not null comment '名称', `SubIdColor` int not null comment '所属颜色', `SubIdBrand` int not null comment '所属品牌', `SubIdInlay` int not null comment '所属镶嵌', `SubIdMoral` int not null comment '所属寓意', `SubIdMaterial` int not null comment '所属种水', `SubIdTopLevel` int not null comment '一级分类编号', `MarketPrice` decimal comment '市场参考价', `MyPrice` decimal not null comment '玉源直销价', `Discount` decimal default 1 comment '折扣', `Picture` varchar(200) comment '图片', `Amount` int comment '库存量', `Description` text comment '详细描述', `State` int default 1 comment '状态', `AddDate` timestamp default CURRENT_TIMESTAMP comment '上货日期', `Hang` int comment '挂件', `RawStone` int comment '赌石', `Size` varchar(200) comment '尺寸', `ExpressageName` varchar(100) comment '快递名称', `Expressage` decimal comment '快递费', `AllowComment` int default 1 comment '是否允许评论', `Reserve1` varchar(4000) comment '保留备用1', `Reserve2` varchar(4000) comment '保留备用2', `Reserve3` decimal(0) comment '保留备用3', primary key (Id) ); alter table Products comment '商品'; /*==============================================================*/ /* Table: Users */ /*==============================================================*/ create table Users ( `UserId` int not null auto_increment comment '用户编号', `UserName` varchar(200) not null comment '用户名', `Password` varchar(512) not null comment '密码', `Email` varchar(100) not null comment '邮箱', `Sex` varchar(10) comment '性别', `State` int default 1 comment '状态', `RightCode` int comment '权限状态', `RegDate` timestamp default CURRENT_TIMESTAMP comment '注册时间', `RegIP` varchar(200) comment '注册IP', `LastLoginDate` datetime comment '最近登录时间', `UserReserve1` varchar(4000) comment '保留备用1', `UserReserve2` varchar(4000) comment '保留备用2', `UserReserve3` varchar(4000) comment '保留备用3', primary key (UserId) ); alter table Users comment '用户'; alter table Address add constraint FK_AddressBelongUser foreign key (UserId) references Users (UserId) on delete restrict on update restrict; alter table ArticleComment add constraint FK_ArticleCommentForArticle foreign key (ArticleId) references Articles (ArticleId) on delete restrict on update restrict; alter table ArticleComment add constraint FK_ArticleCommentForUser foreign key (UserId) references Users (UserId) on delete restrict on update restrict; alter table Articles add constraint FK_ArticleBelongType foreign key (ArticleTypeId) references ArticleType (ArticleTypeId) on delete restrict on update restrict; alter table DictSub add constraint FK_BelongDict foreign key (DictId) references DictTop (DictId) on delete cascade on update cascade; alter table OrderPdt add constraint FK_BelongOrder foreign key (OrderId) references Orders (OrderId) on delete cascade on update cascade; alter table OrderPdt add constraint FK_CartForUser foreign key (UserId) references Users (UserId) on delete restrict on update restrict; alter table OrderPdt add constraint FK_OrderDepProduct foreign key (Id) references Products (Id) on delete restrict on update restrict; alter table Orders add constraint FK_OrderBelongAddress foreign key (AddressId) references Address (AddressId) on delete restrict on update restrict; alter table ProductComment add constraint FK_ProductCommentBelongUsers foreign key (UserId) references Users (UserId) on delete restrict on update restrict; alter table ProductComment add constraint FK_ProductCommentForProduct foreign key (ProductId) references Products (Id) on delete restrict on update restrict; alter table Products add constraint FK_BelongBrand foreign key (SubIdMaterial) references DictSub (SubId) on delete restrict on update restrict; alter table Products add constraint FK_BelongColor foreign key (SubIdBrand) references DictSub (SubId) on delete restrict on update restrict; alter table Products add constraint FK_BelongInlay foreign key (SubIdInlay) references DictSub (SubId) on delete restrict on update restrict; alter table Products add constraint FK_BelongMaterial foreign key (SubIdColor) references DictSub (SubId) on delete restrict on update restrict; alter table Products add constraint FK_BelongMoral foreign key (SubIdTopLevel) references DictSub (SubId) on delete restrict on update restrict; alter table Products add constraint FK_BelongTopLevel foreign key (SubIdMoral) references DictSub (SubId) on delete restrict on update restrict;
六、下载程序、帮助、视频
最全php程序员工具箱:http://tool.php.cn/
MySQL5.7.17安装包官网下载地址: https://dev.mysql.com/downloads/windows/installer/
MYSQL 5.7.12下载地址:http://www.php.cn/xiazai/gongju/116
SQLPro for Mysql1.0.13下载地址:http://www.php.cn/xiazai/gongju/637
文档中没有您可以查帮助:
相关推荐:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Le rôle principal de MySQL dans les applications Web est de stocker et de gérer les données. 1.MySQL traite efficacement les informations utilisateur, les catalogues de produits, les enregistrements de transaction et autres données. 2. Grâce à SQL Query, les développeurs peuvent extraire des informations de la base de données pour générer du contenu dynamique. 3.MySQL fonctionne basé sur le modèle client-serveur pour assurer une vitesse de requête acceptable.
 Comment installer MySQL dans CentOS7
Apr 14, 2025 pm 08:30 PM
Comment installer MySQL dans CentOS7
Apr 14, 2025 pm 08:30 PM
La clé de l'installation de MySQL est d'élégance pour ajouter le référentiel MySQL officiel. Les étapes spécifiques sont les suivantes: Téléchargez la clé GPG officielle MySQL pour empêcher les attaques de phishing. Ajouter un fichier de référentiel MySQL: RPM -UVH https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm Mise à jour du référentiel Cache: Yum Update Installation Mysql: Yum install install install starting starting mysql Service: SystemCTL start start mysqld starger bugo boartup Service mysql Service: SystemCTL start start mysqld starger bugo bo onthing staring Service mysql Service: SystemCTL Start Start MySQLD Set Out Up Boaching Staring Service MySQL Service: SystemCTL Start Start MysQL
