

Cet article vous parle principalement des principes du système d'exploitation Linux. Il s'agit d'un très bon tutoriel de base sur le système Linux. Nous avons résumé tous les contenus pertinents sélectionnés pour que vous puissiez apprendre ensemble. J'espère que cela aide tout le monde.
1. Quatre époques d'ordinateurs
1. La première génération :
Ordinateurs à tube à vide, entrée et sortie. : Les cartes perforées sont très peu pratiques à utiliser sur des ordinateurs. Faire une chose peut nécessiter plus d'une douzaine de personnes pour la réaliser ensemble. L'année est probablement : 1945-1955. Et cela consomme beaucoup d'énergie. Si vous aviez un ordinateur à la maison à cette époque, la luminosité de vos ampoules pourrait diminuer dès que vous allumerez l'ordinateur, haha~
2. 🎜>
Des ordinateurs à transistors et des systèmes de traitement par lots (fonctionnant en mode série) ont vu le jour. Il permet d'économiser beaucoup plus d'énergie que le premier. Le représentant typique est Mainframe. Année approximative : 1955-1965. A cette époque : le langage Fortran était né, un langage informatique très ancien. 3. La troisième génération : L'émergence des circuits intégrés et la conception de programmes de traitement multicanaux (fonctionnant en mode parallèle). Les représentants les plus typiques sont : les systèmes en temps partagé (). divisant le fonctionnement du CPU en pièce d'horlogerie). L'année est probablement : vers 1965-1980. 4. La quatrième génération : Le PC est apparu, probablement vers 1980. Je crois aux représentants typiques de cette époque : Bill Gates, Steve Jobs. 2. Système de travail informatique Bien que les ordinateurs aient évolué à travers quatre époques, à ce jour, le système de travail informatique est encore relativement simple. De manière générale, notre ordinateur comporte cinq parties de base. 1.MMU (unité de contrôle de la mémoire, implémente la pagination de la mémoire [page mémoire]) Le mécanisme informatique est indépendant du CPU (unité de contrôle informatique). Il y a une puce unique dans le CPU). appelé MMU. Il permet de calculer la correspondance entre l'adresse du thread et l'adresse physique du processus. Il est également utilisé pour la protection d'accès, c'est-à-dire que si un processus accède d'abord à une adresse mémoire qui n'est pas la sienne, il sera rejeté ! 2. Mémoire (mémoire) 3. Périphérique d'affichage (interface VGA, moniteur, etc.) [appartient au périphérique IO] 4. périphérique clavier) [Appartient aux périphériques IO] 5. Périphérique de disque dur (contrôle de la parabole dure, contrôleur de disque dur ou adaptateur) [Appartient aux périphériques IO] Connaissances approfondies :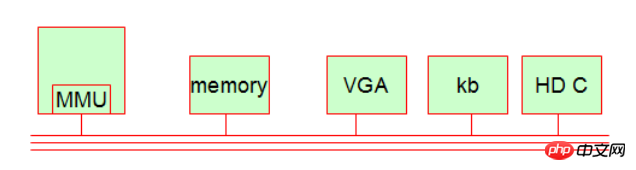
Connaissances étendues :
Étant donné que l'espace de stockage des registres à l'intérieur du CPU est limité, la mémoire est utilisée pour stocker les données. Cependant, puisque la vitesse du CPU et la vitesse de la mémoire ne sont pas au même niveau. du tout, donc dans le traitement La plupart d'entre eux attendent lorsque les données sont renvoyées (le CPU doit récupérer une donnée de la mémoire, et elle peut être traitée en une seule rotation du CPU, tandis que la mémoire peut avoir besoin de tourner 20 fois). Afin d'améliorer l'efficacité, le concept de mise en cache a émergé.
Maintenant que nous connaissons le principe de localité du programme, nous savons également que pour obtenir plus d'espace, le CPU utilise en fait du temps pour échanger de l'espace, mais le cache peut directement laisser le CPU récupérer les données, ce qui permet de gagner du temps. , donc la mise en cache signifie échanger de l'espace contre du temps
3 Même s'il s'agit d'un système de stockage
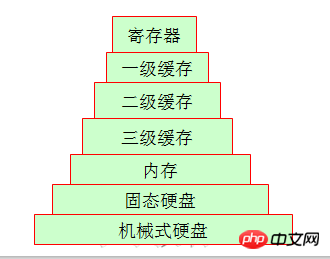
Les amis qui travaillent pendant les heures de travail ont peut-être vu des lecteurs de bande, et maintenant, ils le sont pratiquement tous. De nombreuses entreprises utilisent des disques durs pour remplacer les lecteurs de bande, regardons donc la structure de l'ordinateur personnel que nous connaissons le mieux. Les données sont différentes de la dernière fois qu'elles ont été stockées. Nous pouvons donner un exemple simple. Il existe un grand écart entre leurs cycles de stockage hebdomadaires. Le disque dur mécanique et la mémoire sont particulièrement évidents. L'écart entre les deux est assez grand.
Connaissances élargies :
Par rapport à votre propre ordinateur de bureau ou ordinateur portable, vous l'avez peut-être démonté vous-même et parlé de disques durs mécaniques, de disques SSD ou de mémoire, etc. Mais peut-être n'avez-vous pas vu le périphérique physique du cache, mais il se trouve en fait sur le processeur. Il se peut donc qu’il y ait des angles morts dans notre compréhension.
Parlons d'abord du cache de premier niveau et du cache du casque. Lorsque leur processeur récupère les données ici, la période de temps n'est fondamentalement pas très longue, car le cache de premier niveau et le cache de deuxième niveau sont internes. ressources du cœur du processeur. (Dans les mêmes conditions matérielles, le prix du marché d'un cache L1 de 128 000 $ peut être d'environ 300 yuans, le prix du marché d'un cache L1 de 256 000 $ peut être d'environ 600 yuans et le prix du marché d'un cache L1 de 512 000 $ peut être supérieur à quatre chiffres. Vous pouvez vous référer à JD.com pour le prix spécifique. Cela suffit à montrer que le coût du cache est très élevé !) À ce stade, vous pouvez vous demander qu'en est-il du cache de troisième niveau ? En fait, le cache de troisième niveau est l'espace partagé par plusieurs processeurs. Bien entendu, plusieurs processeurs partagent également de la mémoire.
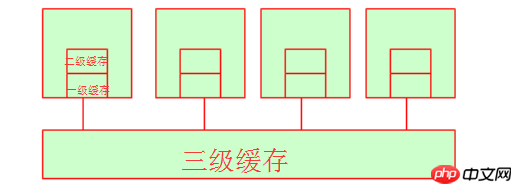
4. Accès à la mémoire non uniforme (NUMA)
Nous savons que lorsque plusieurs processeurs partagent le cache ou la mémoire L3, ils le feront. d’expropriation des ressources. Nous savons que les variables ou les chaînes ont des adresses mémoire lorsqu'elles sont enregistrées en mémoire. Comment obtiennent-ils l’adresse mémoire ? Nous pouvons nous référer à l'image ci-dessous :
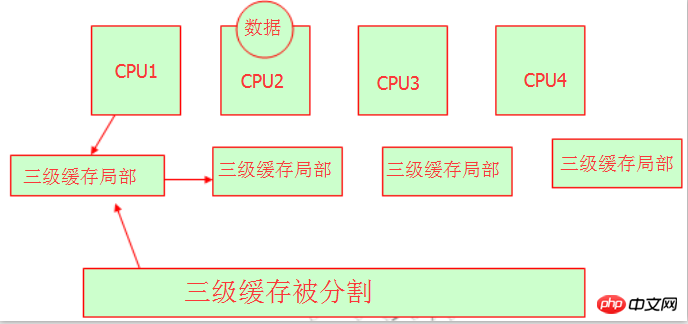
Oui, ces experts en matériel divisent le cache à trois niveaux et laissent différents processeurs occuper différentes adresses mémoire. Il est compréhensible qu'ils aient tous leur propre zone de cache de niveau 3, et il n'y aura aucun problème d'accaparement de ressources, mais il convient de noter qu'il s'agit toujours du même cache de niveau 3. Tout comme Pékin a le district de Chaoyang, le district de Fengtai, le district de Daxing, le district de Haidian, etc., mais ils font tous partie de Pékin. On peut comprendre ici. Il s'agit de NUMA, et ses caractéristiques sont : un accès mémoire non uniforme, chacun a son propre espace mémoire.
Connaissances étendues :
Ensuite, le problème est que, en fonction du résultat du rechargement, si le processus exécuté sur cpu1 est suspendu, son adresse est enregistrée dans sa propre adresse de cache, mais comment est-il géré par CPU2 quand il exécute à nouveau le programme ?
Il n'y a pas d'autre choix que de copier une adresse de la zone de rugosité de troisième niveau du CPU1 ou de la déplacer vers le CPU2 pour le traitement. Cela prendra un certain temps. Par conséquent, le rééquilibrage entraînera une diminution des performances du processeur. À l'heure actuelle, nous pouvons utiliser la liaison de processus pour y parvenir, de sorte que lorsque le processus est à nouveau traité, le processeur utilisé pour le traiter sera toujours utilisé. C'est-à-dire l'affinité CPU du processus.
5. Mécanismes d'écriture directe et de réécriture dans le cache.
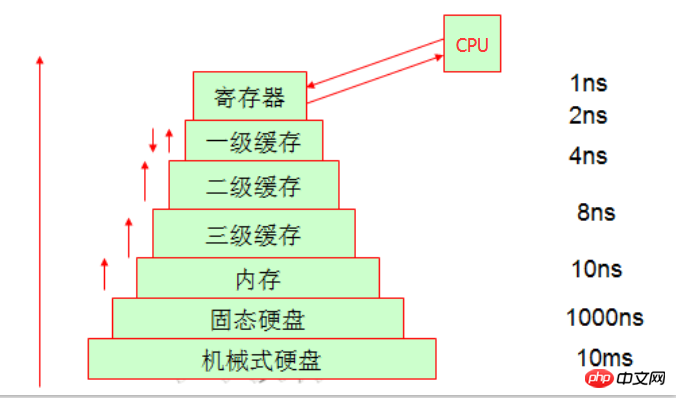
L'endroit où le CPU traite les données est de les modifier dans le registre. Lorsque le registre n'a pas les données qu'il recherche, il ira au premier-. cache de niveau pour les trouver. S'il n'y a pas de données dans le cache de premier niveau, les données seront trouvées dans le cache de deuxième niveau, recherchées séquentiellement jusqu'à ce qu'elles soient trouvées sur le disque, puis chargées dans le registre. Lorsque le cache de troisième niveau récupère les données de la mémoire et constate que le cache de troisième niveau est insuffisant, il libère automatiquement l'espace dans le cache de troisième niveau.
Nous savons que l'emplacement final où les données sont stockées est le disque dur, et ce processus d'accès est complété par le système d'exploitation. Lorsque notre processeur traite des données, il écrit les données à différents endroits via deux méthodes d'écriture, à savoir l'écriture directe (écriture dans la mémoire) et la réécriture (écriture dans le cache de premier niveau). Évidemment, les performances de réécriture sont bonnes, mais ce sera embarrassant si l'alimentation est coupée et les données seront perdues, car elles sont écrites directement dans le cache de premier niveau, mais les autres processeurs ne peuvent pas accéder au cache de premier niveau. , donc du point de vue de la fiabilité Du point de vue de l'écriture, la méthode générale d'écriture sera plus fiable. La méthode spécifique à utiliser dépend de vos propres besoins.
4. Périphérique IO
1. Le périphérique IO se compose du contrôleur de périphérique et de l'appareil lui-même.
Contrôleur de périphérique : une puce ou un ensemble de puces intégrées à la carte mère. Responsable de la réception des commandes du système d’exploitation et de l’achèvement de l’exécution des commandes. Par exemple, il est responsable de la lecture des données du système d'exploitation.
L'appareil lui-même : Il possède sa propre interface, mais l'interface de l'appareil lui-même n'est pas disponible, c'est juste une interface physique. Tel que l'interface IDE.
Connaissances étendues :
Chaque contrôleur dispose d'un petit nombre de registres pour la communication (allant de quelques à des dizaines). Ce registre est intégré directement dans le contrôleur de l'appareil. Par exemple, un contrôleur de disque minimal sera également utilisé pour spécifier des registres pour les adresses de disque, le nombre de secteurs, les directions de lecture et d'écriture et d'autres demandes d'opérations associées. Ainsi, chaque fois que vous souhaitez activer le contrôleur, le pilote de périphérique reçoit l'instruction d'opération du système d'exploitation, puis la convertit en opération de base du périphérique correspondant et place la demande d'opération dans le registre pour terminer l'opération. Chaque registre se comporte comme un port IO. Toutes les combinaisons de registres sont appelées espace d'adressage d'E/S de l'appareil, également appelé espace de port d'E/S,
2. Pilote
L'opération matérielle réelle est complétée par l'opération du pilote. Les pilotes doivent généralement être complétés par le fabricant du périphérique. Généralement, le pilote est situé dans le noyau. Bien que le pilote puisse s'exécuter en dehors du noyau, peu de gens le font car c'est trop inefficace !
3. Implémenter l'entrée et la sortie
Les ports d'E/S de l'appareil ne peuvent pas être attribués à l'avance car les modèles de chaque carte mère sont incohérents, nous devons donc les attribuer dynamiquement. Lorsque l'ordinateur est allumé, chaque périphérique IO doit s'enregistrer pour utiliser le port E/S dans l'espace du port E/S du bus. Ce port dynamique est composé de tous les registres combinés dans l'espace d'adressage E/S de l'appareil. Il y a 2 ^ 16 ports, soit 65 535 ports.
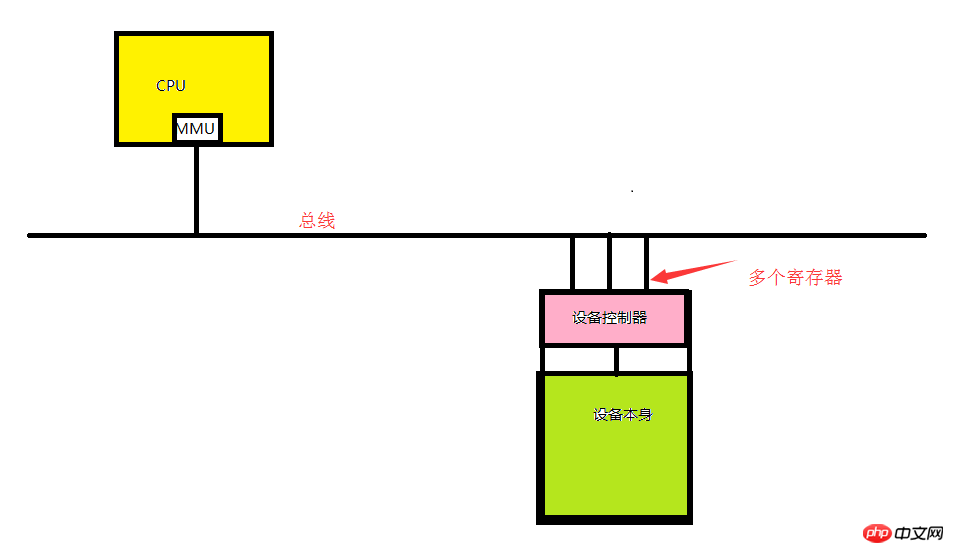
Comme le montre l'image ci-dessus, si notre processeur veut gérer le périphérique spécifié, il doit transmettre la commande au pilote, puis le pilote convertira le Commande CPU en quelque chose que l'appareil peut comprendre. Le signal est placé dans un registre (également appelé socket). Ainsi, le registre (port E/S) est l'adresse (port E/S) par laquelle le CPU interagit avec l'appareil. l'autobus.
Connaissances étendues :
Trois façons d'implémenter l'entrée et la sortie des périphériques d'E/S :
A.. Interrogation :
Se réfère généralement à l'utilisateur Le programme lance un appel système et le noyau le traduit en un appel de procédure pour le pilote correspondant du noyau. Ensuite, le pilote de périphérique démarre les E/S et vérifie le périphérique en boucle continue pour voir s'il a terminé son travail. Ceci est quelque peu similaire à une attente occupée (c'est-à-dire que le processeur utilisera une période fixe pour vérifier en permanence chaque périphérique d'E/S via une traversée pour voir s'il y a des données. Évidemment, cette efficacité n'est pas idéale.),
B. .Interruption :
Interrompre le programme en cours de traitement par le CPU et interrompre l'opération en cours d'exécution par le CPU, informant ainsi le noyau d'obtenir une demande d'interruption. Il existe généralement un périphérique unique sur notre carte mère appelé contrôleur d'interruption programmable. Ce contrôleur d'interruption peut communiquer directement avec le CPU via une certaine broche et peut déclencher la déviation du CPU à une certaine position, permettant ainsi au CPU de savoir qu'un certain signal est arrivé. Il y aura un vecteur d'interruption sur le contrôleur d'interruption (lorsque chacun de nos périphériques d'E/S démarre, nous voulons que le contrôleur d'interruption enregistre un numéro d'interruption. Ce numéro est généralement unique. Habituellement, chaque broche du vecteur d'interruption peut identifier plusieurs interruptions. numéro), qui peut également être appelé numéro d’interruption.
Ainsi, lorsqu'une interruption se produit réellement sur cet appareil, cet appareil ne mettra pas de données directement sur le bus. Cet appareil enverra immédiatement une demande d'interruption au contrôleur d'interruption. Le contrôleur d'interruption identifie la requête par laquelle cette demande transite. le vecteur d'interruption envoyé par le périphérique, il est ensuite notifié au CPU d'une manière ou d'une autre, permettant au CPU de savoir quel périphérique a atteint la demande d'interruption. À ce stade, le processeur peut utiliser le numéro de port E/S en fonction de l'enregistrement du périphérique, afin que les données du périphérique puissent être obtenues. (Notez que le processeur ne peut pas récupérer directement les données, car il ne reçoit que le signal d'interruption. Il peut uniquement avertir le noyau, laisser le noyau s'exécuter sur le processeur lui-même et le noyau obtient la demande d'interruption.) Par exemple, une carte réseau reçoit Pour les requêtes IP externes, la carte réseau dispose également de sa propre zone de cache. Le processeur prend le cache de la carte réseau dans la mémoire et le lit d'abord s'il s'agit de sa propre adresse IP. Si c'est le cas, il commence à décompresser l'adresse IP. paquet, et obtient finalement un numéro de port. Ensuite, le CPIU trouve ce port dans son propre contrôleur d'interruption et le gère en conséquence.
Le traitement de l'interruption du noyau est divisé en deux étapes : la première moitié de l'interruption (traitée immédiatement) et la seconde moitié de l'interruption (pas nécessairement). Prenons l'exemple de la réception de données de la carte réseau. Lorsque la demande de l'utilisateur atteint la carte réseau, le CPU commande que les données dans la zone de cache de la carte réseau soient directement récupérées dans la mémoire. traitée immédiatement après sa réception (le traitement consiste ici à transférer les données de la carte réseau vers la mémoire). Elle est simplement lue dans la mémoire sans autre traitement pour faciliter le traitement ultérieur. C'est ce qu'on appelle la partie supérieure de l'interruption, et). la partie suivante qui gère réellement la requête est appelée la seconde moitié
C.DMA :
L'accès direct à la mémoire Tout le monde sait que la transmission des données est implémentée sur le bus. contrôle le bus. Quels périphériques d'E/S utilisent le bus à un moment donné ? Cela est déterminé par le contrôleur de la CPU. Le bus a trois fonctions : bus d'adresse (pour compléter la fonction d'adressage de l'appareil), bus de contrôle (pour contrôler la fonction de chaque adresse d'appareil à l'aide du bus) et bus de données (pour réaliser la transmission de données).
Habituellement, il s'agit d'une puce de contrôle intelligente fournie avec le périphérique d'E/S (nous l'appelons le contrôleur d'accès direct à la mémoire). Lorsque la première moitié de l'interruption doit être traitée, le CPU en informe le DMA. périphérique pour accepter l'interruption. Le bus est utilisé par le périphérique DMA et il est informé de l'espace mémoire qui peut être utilisé pour lire les données du périphérique d'E/S dans l'espace mémoire. Lorsque le périphérique d'E/S DMA termine la lecture des données, il enverra un message pour indiquer au CPU que l'opération de lecture est terminée. À ce moment, le CPU informera le noyau que les données ont été chargées. la seconde moitié de l'interruption sera transmise au noyau. La plupart des appareils utilisent désormais des contrôleurs DMA, tels que des cartes réseau, des disques durs, etc.
5. Concepts du système d'exploitation
Grâce à l'étude ci-dessus, nous savons qu'un ordinateur comporte cinq composants de base. Le système d'exploitation résume principalement ces cinq composants dans une interface relativement intuitive, directement utilisée par les programmeurs ou les utilisateurs de niveau supérieur. Alors, quelles sont les choses qui sont réellement abstraites dans le système d’exploitation ?
1.CPU (tranche de temps)
Dans le système d'exploitation, le CPU est résumé en tranches de temps, puis le programme est résumé en processus, et le programme est exécuté en allouant des tranches de temps . La CPU dispose d'une unité d'adressage qui identifie l'adresse de mémoire collective où la variable est stockée en mémoire.
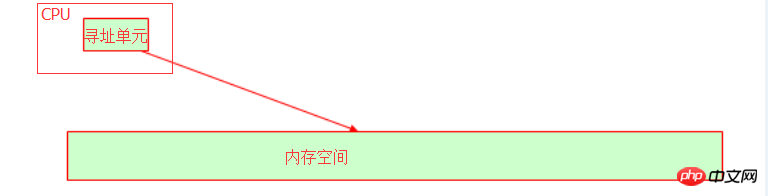
Le bus interne de notre hôte dépend de la largeur de bits (également appelée longueur de mot) du CPU. Par exemple, le bus d'adresse 32 bits peut représenter 2 pour le. 32ème puissance. L'adresse mémoire, convertie en décimale, est un espace mémoire 4G. À ce stade, vous devriez comprendre pourquoi le système d'exploitation 32 bits ne peut reconnaître que la mémoire 4G, n'est-ce pas ? Même si votre mémoire physique est de 16 Go, la mémoire disponible est toujours de 4 Go. Par conséquent, si vous constatez que votre système d'exploitation peut reconnaître les adresses mémoire supérieures à 4 Go, alors votre système d'exploitation ne doit pas être en 32 bits !
2. Mémoire
Dans le système d'exploitation, la mémoire est implémentée via l'espace d'adressage virtuel.
3. Périphérique d'E/S
Dans le système d'exploitation, le périphérique d'E/S principal est le disque. Tout le monde sait que le disque fournit de l'espace de stockage dans le noyau. déposer.
4. Processus
Pour parler franchement, le but principal de l’existence d’un ordinateur n’est-il pas simplement d’exécuter des programmes ? Lorsque le programme s'exécute, nous l'appelons un processus (nous n'avons pas à nous soucier des threads pour le moment). Si plusieurs processus s'exécutent en même temps, cela signifie que ces ressources abstraites limitées (processeur, mémoire, etc.) sont allouées à plusieurs processus. Nous appelons collectivement ces ressources abstraites des ensembles de ressources.
L'ensemble de ressources comprend :
1>.cpu time ;
2>. Adresse mémoire : extraite dans l'espace d'adressage virtuel (tel qu'un système d'exploitation 32 bits, prend en charge). Espace 4G, le noyau occupe 1G d'espace et le processus utilisera par défaut 3G d'espace disponible. En fait, il se peut qu'il n'y ait pas 3G d'espace, car votre ordinateur peut avoir moins de 4G de mémoire)
3>. ;.I/O : tout est un fichier. Pour ouvrir plusieurs fichiers, ouvrez le fichier spécifié via fd (descripteur de fichier). Nous divisons les fichiers en trois catégories : les fichiers normaux, les fichiers de périphérique et les fichiers de pipeline.
Chaque processus a sa propre structure d'adresse de tâche, à savoir : task struct. Il s'agit d'une structure de données maintenue par le noyau pour chaque processus (une structure de données est utilisée pour sauvegarder les données. Pour parler franchement, c'est l'espace mémoire, qui enregistre l'ensemble de ressources appartenant au processus, et bien sûr son processus parent, qui enregistre la scène [Utilisé pour la commutation de processus], attente de mappage de mémoire). La structure de tâche simule les adresses linéaires et permet au processus d'utiliser ces adresses linéaires, mais elle enregistre la relation de mappage entre les adresses linéaires et les adresses de mémoire physique.
5. Mappage mémoire - cadre de page
Tant qu'il ne s'agit pas de l'espace mémoire physique utilisé par le noyau, nous l'appelons espace utilisateur. Le noyau découpera la mémoire physique de l'espace utilisateur en un cadre de page de taille fixe (c'est-à-dire un cadre de page, en termes Huanju, il s'agit d'une unité de stockage de taille fixe, qui est plus petite que l'unité de stockage unique par défaut (la valeur par défaut est). un octet, soit 8 bits) doit être volumineux. Généralement, une unité de stockage par 4 Ko. Chaque cadre de page est attribué vers l'extérieur en tant qu'unité indépendante, et chaque cadre de page est également numéroté. [Par exemple : supposons qu'un espace 4G soit disponible, que chaque cadre de page est de 4K et qu'il y a 1 million de cadres de page au total. 】Ces cadres de page sont alloués à différents processus.
Nous supposons que vous disposez de 4 Go de mémoire, que le système d'exploitation occupe 1 Go et que les 3 Go de mémoire physique restants sont alloués à l'espace utilisateur. Après le démarrage de chaque processus, il pensera qu'il dispose d'un espace 3G disponible, mais en fait, il ne peut pas du tout utiliser la 3G. La mémoire écrite par le processus est stockée discrètement. Partout où il y a de la mémoire libre, accédez-y. Ne me posez pas de questions sur l'algorithme d'accès spécifique, je ne l'ai pas étudié non plus.
Structure de l'espace de traitement :
1>. Espace réservé
2>. Pile (emplacement de stockage variable)
3>.
4>.Heap (ouvre un fichier dans lequel le flux de données du fichier est stocké)5>.Segment de données (stockage global de variables statiques)6>.Code Le La relation de stockage entre le segment processus et la mémoire est la suivante :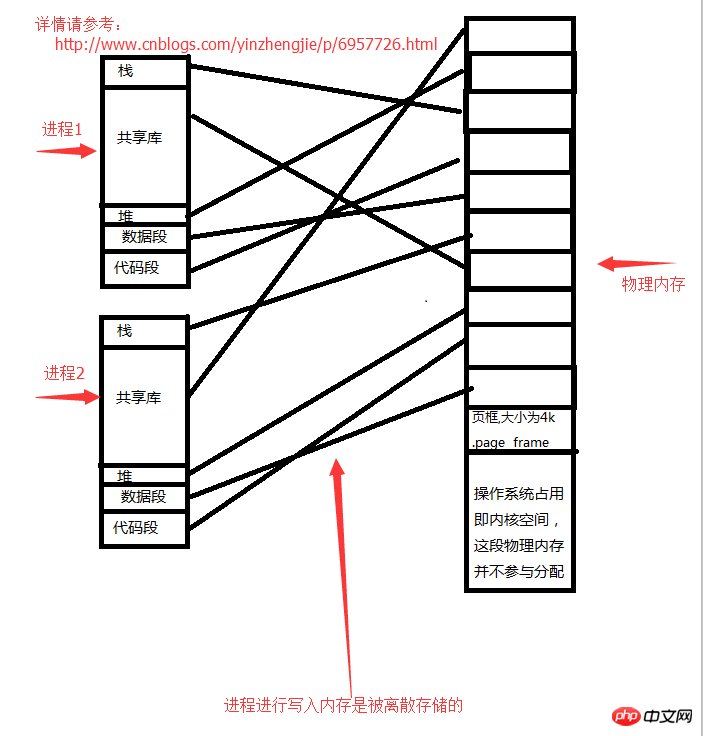
Si une application doit appeler la fonction du noyau au lieu de la fonction du programme utilisateur, l'application constatera qu'elle doit effectuer une opération privilégiée, et l'application elle-même n'a pas cette capacité. une application au noyau et laissez le noyau vous aider à effectuer des opérations privilégiées. Le noyau constate que l'application est autorisée à utiliser des instructions privilégiées. Le noyau exécutera ces instructions privilégiées et renverra les résultats de l'exécution à l'application. Ensuite, l'application poursuivra le code suivant après avoir obtenu les résultats d'exécution des instructions privilégiées. Il s’agit d’un changement de paradigme.
Par conséquent, si un programmeur souhaite rendre votre programme productif, il doit essayer de faire exécuter votre code dans l'espace utilisateur. Si la plupart de votre code s'exécute dans l'espace du noyau, on estime que votre application ne gagnera pas. cela ne vous apporte pas beaucoup de productivité. Parce que nous savons que l'espace noyau n'est pas responsable de la productivité.
Connaissances élargies :
Nous savons que le fonctionnement de l'ordinateur consiste à exécuter l'opération spécifiée. Les instructions sont également divisées en niveaux d'instruction privilégiés et en niveaux d'instruction non privilégiés. Les amis qui connaissent les ordinateurs savent peut-être que l'architecture du processeur du X86 est grossièrement divisée en quatre niveaux. Il y a quatre anneaux de l'intérieur vers l'extérieur, appelés anneau 0, anneau 1, anneau 2 et anneau 3. Nous savons que les instructions de l’anneau 0 sont des instructions privilégiées et que les instructions de l’anneau 3 sont des instructions utilisateur. De manière générale, le niveau d'instruction privilégié concerne l'exploitation du matériel, le contrôle du bus, etc.
L'exécution d'un programme nécessite la coordination du noyau, et il est possible de basculer entre le mode utilisateur et le mode noyau. Par conséquent, l'exécution d'un programme doit être planifiée par le noyau vers le CPU pour son exécution. Certaines applications sont exécutées pendant le fonctionnement du système d'exploitation pour exécuter des fonctions de base. Nous les laissons s'exécuter automatiquement en arrière-plan. C'est ce qu'on appelle un processus démon. Mais certains programmes ne sont exécutés que lorsque l'utilisateur en a besoin. Alors, comment pouvons-nous demander au noyau d'exécuter les applications dont nous avons besoin ? À ce stade, vous avez besoin d’un interprète capable de gérer le système d’exploitation et de lancer l’exécution des instructions. Pour parler franchement, cela signifie que la requête en cours d'exécution de l'utilisateur peut être soumise au noyau, et que le noyau peut alors ouvrir les conditions de base requises pour son fonctionnement. Le programme est ensuite exécuté.
Recommandations associées :
Compréhension des threads dans la connaissance du système d'exploitation
Interruptions CPU sous le système d'exploitation Linux
Un exemple de tutoriel sur le renforcement de la sécurité du système d'exploitation Linux
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



