

Comment implémenter l'analyse des champs de sélection CSS

Sur la base des connaissances de base sur la syntaxe CSS apprises ci-dessus, implémentons maintenant l'analyse des champs. Tout d’abord, analysez le titre. Ouvrez les outils de développement Web et recherchez le code source correspondant au titre. Cet article présente principalement les informations pertinentes sur la mise en œuvre du sélecteur CSS pour l'analyse des champs. Les amis qui en ont besoin peuvent s'y référer. J'espère que cela pourra aider tout le monde
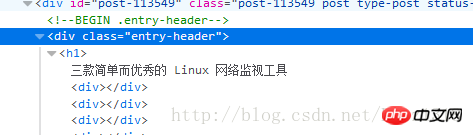
J'ai trouvé que c'était le cas. le nœud h1 ci-dessous p class="entry-header", j'ai donc ouvert le shell Scrapy pour le débogage

Mais que dois-je faire si je ne veux pas de balise comme
? cette fois, je dois utiliser le pseudo-code dans la méthode de classe CSS. Comme indiqué ci-dessous.

Notez les deux deux-points. Utiliser des sélecteurs CSS est vraiment pratique. De la même manière, j'utilise CSS pour implémenter l'analyse de champs. Le code est le suivant
# -*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/113549/']
def parse(self, response):
# title = response.xpath('//p[@class = "entry-header"]/h1/text()').extract()[0]
# create_date = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip()
# praise_numbers = response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
# fav_nums = response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
# match_re = re.match(".*?(\d+).*",fav_nums)
# if match_re:
# fav_nums = match_re.group(1)
# comment_nums = response.xpath("//a[@href='#article-comment']/span").extract()[0]
# match_re = re.match(".*?(\d+).*", comment_nums)
# if match_re:
# comment_nums = match_re.group(1)
# content = response.xpath("//p[@class='entry']").extract()[0]
#通过CSS选择器提取字段
title = response.css(".entry-header h1::text").extract()[0]
create_date = response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip()
praise_numbers = response.css(".vote-post-up h10::text").extract()[0]
fav_nums = response.css("span.bookmark-btn::text").extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)
content = response.css("p.entry").extract()[0]
tags = response.css("p.entry-meta-hide-on-mobile a::text").extract()[0]
pass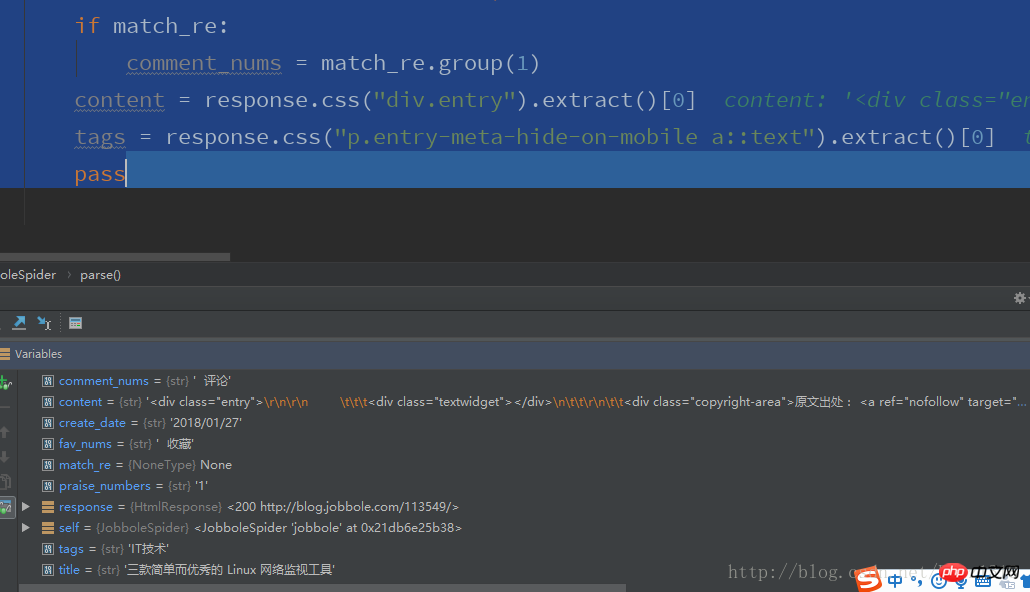
Recommandations associées :
Employé OpenERP ( employé) table Analyse des champs associés aux tables utilisateur
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment écrire des lignes fendues sur bootstrap
Apr 07, 2025 pm 03:12 PM
Comment écrire des lignes fendues sur bootstrap
Apr 07, 2025 pm 03:12 PM
Il existe deux façons de créer une ligne divisée bootstrap: en utilisant la balise, qui crée une ligne divisée horizontale. Utilisez la propriété CSS Border pour créer des lignes de fractionnement de style personnalisées.
 Comment insérer des photos sur bootstrap
Apr 07, 2025 pm 03:30 PM
Comment insérer des photos sur bootstrap
Apr 07, 2025 pm 03:30 PM
Il existe plusieurs façons d'insérer des images dans Bootstrap: insérer directement les images, en utilisant la balise HTML IMG. Avec le composant d'image bootstrap, vous pouvez fournir des images réactives et plus de styles. Définissez la taille de l'image, utilisez la classe IMG-FLUID pour rendre l'image adaptable. Réglez la bordure en utilisant la classe IMG-border. Réglez les coins arrondis et utilisez la classe Roundée IMG. Réglez l'ombre, utilisez la classe Shadow. Redimensionner et positionner l'image, en utilisant le style CSS. À l'aide de l'image d'arrière-plan, utilisez la propriété CSS d'image d'arrière-plan.
 Comment redimensionner le bootstrap
Apr 07, 2025 pm 03:18 PM
Comment redimensionner le bootstrap
Apr 07, 2025 pm 03:18 PM
Pour ajuster la taille des éléments dans Bootstrap, vous pouvez utiliser la classe de dimension, qui comprend: ajuster la largeur: .col-, .w-, .mw-ajustement Hauteur: .h-, .min-h-, .max-h-
 Comment configurer le cadre de bootstrap
Apr 07, 2025 pm 03:27 PM
Comment configurer le cadre de bootstrap
Apr 07, 2025 pm 03:27 PM
Pour configurer le framework Bootstrap, vous devez suivre ces étapes: 1. Référez le fichier bootstrap via CDN; 2. Téléchargez et hébergez le fichier sur votre propre serveur; 3. Incluez le fichier bootstrap dans HTML; 4. Compiler les sass / moins au besoin; 5. Importer un fichier personnalisé (facultatif). Une fois la configuration terminée, vous pouvez utiliser les systèmes, composants et styles de grille de Bootstrap pour créer des sites Web et des applications réactifs.
 Les rôles de HTML, CSS et JavaScript: responsabilités de base
Apr 08, 2025 pm 07:05 PM
Les rôles de HTML, CSS et JavaScript: responsabilités de base
Apr 08, 2025 pm 07:05 PM
HTML définit la structure Web, CSS est responsable du style et de la mise en page, et JavaScript donne une interaction dynamique. Les trois exercent leurs fonctions dans le développement Web et construisent conjointement un site Web coloré.
 Comment utiliser le bouton bootstrap
Apr 07, 2025 pm 03:09 PM
Comment utiliser le bouton bootstrap
Apr 07, 2025 pm 03:09 PM
Comment utiliser le bouton bootstrap? Introduisez Bootstrap CSS pour créer des éléments de bouton et ajoutez la classe de bouton bootstrap pour ajouter du texte du bouton
 Comment utiliser Bootstrap en Vue
Apr 07, 2025 pm 11:33 PM
Comment utiliser Bootstrap en Vue
Apr 07, 2025 pm 11:33 PM
L'utilisation de bootstrap dans vue.js est divisée en cinq étapes: installer bootstrap. Importer un bootstrap dans main.js. Utilisez le composant bootstrap directement dans le modèle. Facultatif: style personnalisé. Facultatif: utilisez des plug-ins.
 Comment afficher la date de bootstrap
Apr 07, 2025 pm 03:03 PM
Comment afficher la date de bootstrap
Apr 07, 2025 pm 03:03 PM
Réponse: Vous pouvez utiliser le composant de sélecteur de date de bootstrap pour afficher les dates dans la page. Étapes: Présentez le framework bootstrap. Créez une boîte d'entrée de sélecteur de date dans HTML. Bootstrap ajoutera automatiquement des styles au sélecteur. Utilisez JavaScript pour obtenir la date sélectionnée.
