

Node.js, jade génère des exemples de fichiers HTML statiques

Cet article vous apporte principalement un exemple de Node.js+jade récupérant tous les articles de blog pour générer des fichiers html statiques. L'éditeur le trouve plutôt bon, je vais donc le partager avec vous maintenant et le donner comme référence pour tout le monde. Suivons l'éditeur pour y jeter un œil, j'espère que cela pourra aider tout le monde.
Structure du projet :
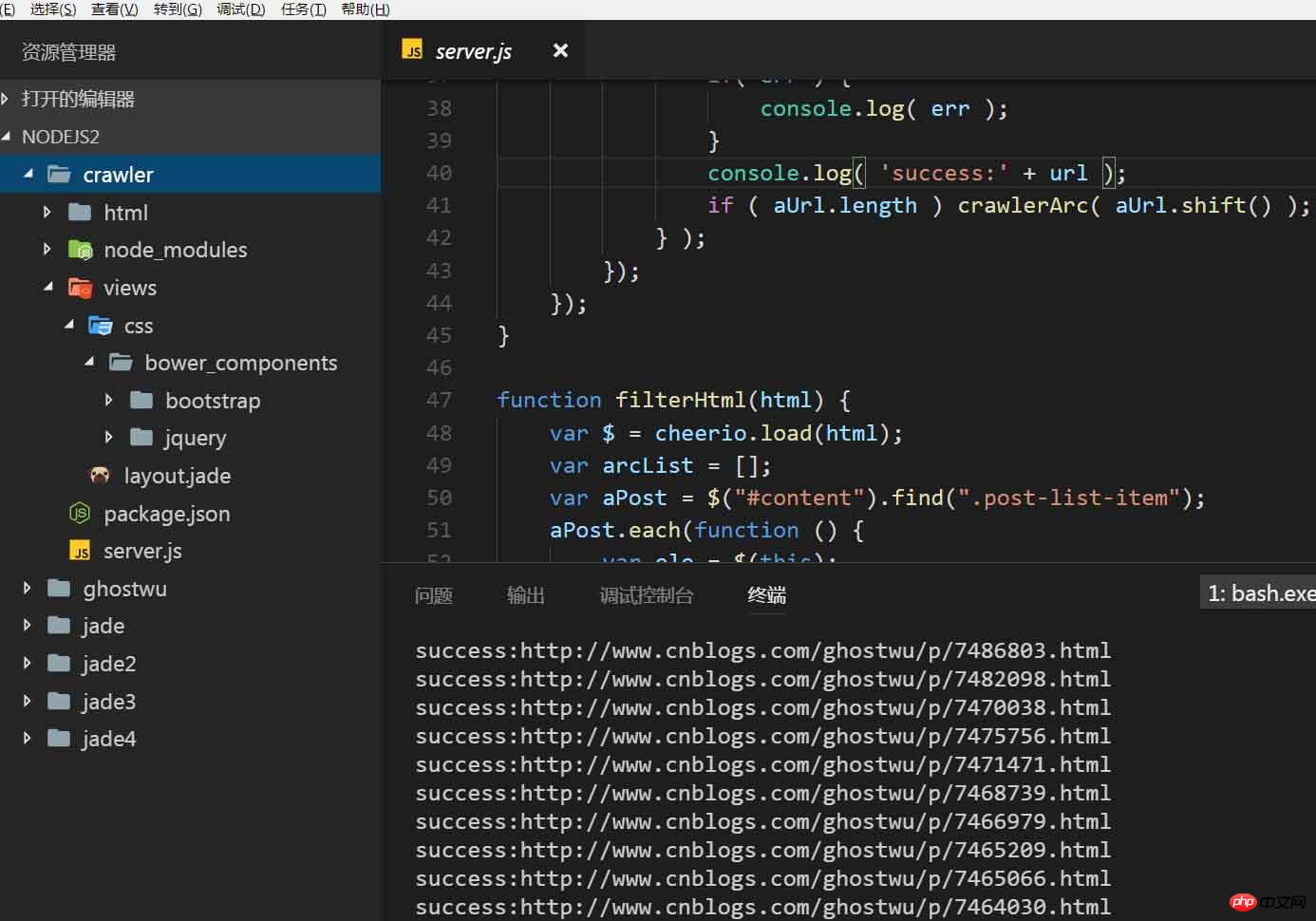
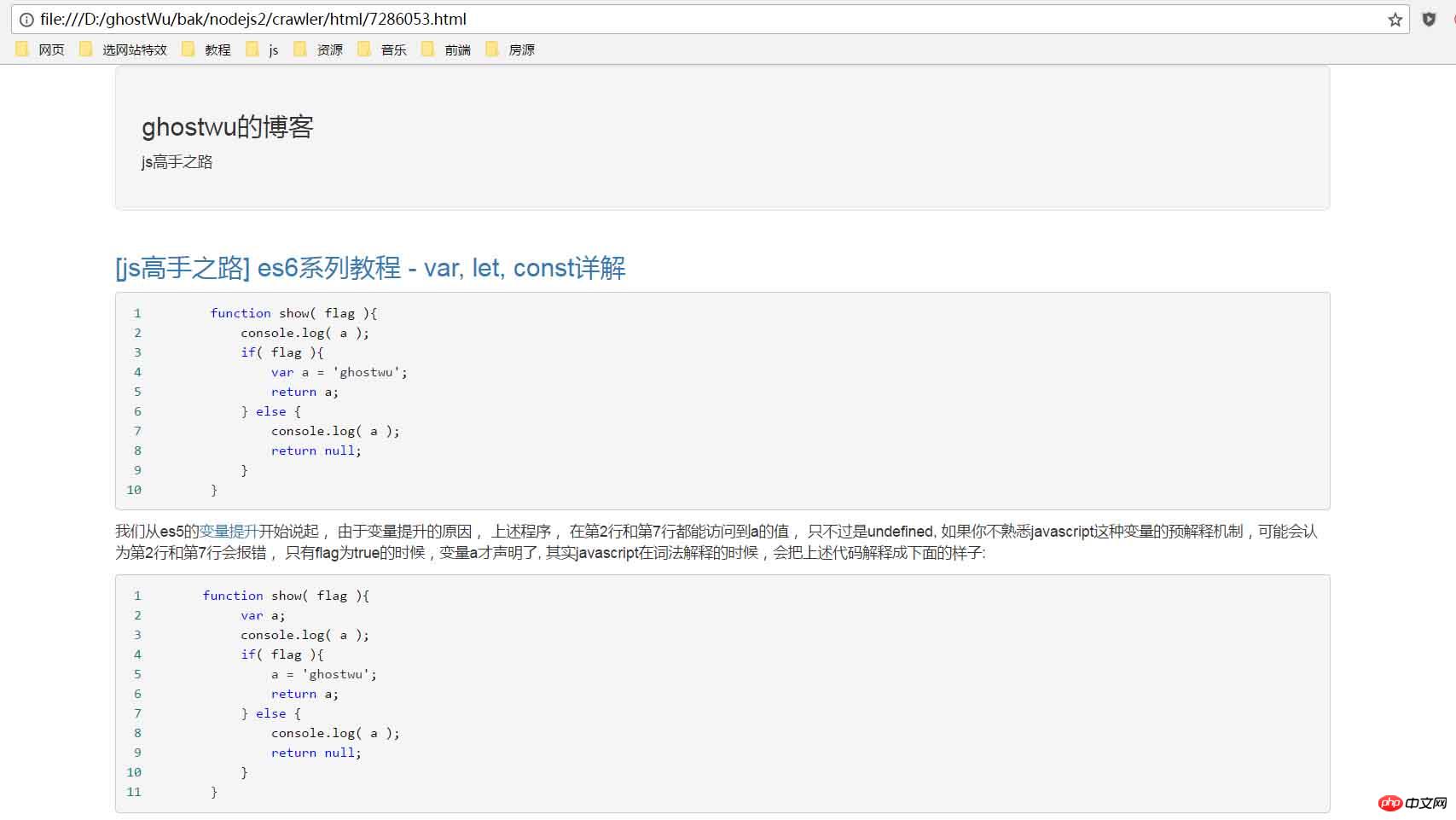
D'accord, ensuite, nous allons vous expliquer les principales fonctions de cet article :
1. Récupérez les articles, récupérez principalement le titre, le contenu, le lien hypertexte et l'identifiant de l'article (utilisé pour générer des fichiers HTML statiques)
2. fichiers html basés sur le modèle jade
1. Comment explorer les articles ?
C'est très simple, presque la même chose que la mise en œuvre de l'exploration de la liste d'articles ci-dessus
function crawlerArc( url ){
var html = '';
var str = '';
var arcDetail = {};
http.get(url, function (res) {
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
arcDetail = filterArticle( html );
str = jade.renderFile('./views/layout.jade', arcDetail );
fs.writeFile( './html/' + arcDetail['id'] + '.html', str, function( err ){
if( err ) {
console.log( err );
}
console.log( 'success:' + url );
if ( aUrl.length ) crawlerArc( aUrl.shift() );
} );
});
});
}Le paramètre url est l'adresse de l'article après l'exploration. le contenu de l'article, appelez filterArticle(html) pour filtrer les informations requises sur l'article (identifiant, titre, lien hypertexte, contenu), puis utilisez l'API renderFile de jade pour remplacer le contenu du modèle
Après le contenu du modèle. est remplacé, ce sera certainement le cas. Il est nécessaire de générer un fichier html, utilisez donc writeFile pour écrire le fichier. Lors de l'écriture du fichier, utilisez l'identifiant comme nom du fichier html. Il s'agit de l'implémentation de la génération d'un fichier html statique,
L'étape suivante consiste à générer un fichier html statique en boucle, qui est la ligne suivante :
if ( aUrl.length ) crawlerArc( aUrl.shift() );
aUrl enregistre l'url de tous les articles de mon blog, à chaque fois après collecter un article, supprimer l'URL de l'article en cours, laisser sortir l'URL de l'article suivant et continuer à collecter
Code d'implémentation complet server.js :
var fs = require( 'fs' );
var http = require( 'http' );
var cheerio = require( 'cheerio' );
var jade = require( 'jade' );
var aList = [];
var aUrl = [];
function filterArticle(html) {
var $ = cheerio.load( html );
var arcDetail = {};
var title = $( "#cb_post_title_url" ).text();
var href = $( "#cb_post_title_url" ).attr( "href" );
var re = /\/(\d+)\.html/;
var id = href.match( re )[1];
var body = $( "#cnblogs_post_body" ).html();
return {
id : id,
title : title,
href : href,
body : body
};
}
function crawlerArc( url ){
var html = '';
var str = '';
var arcDetail = {};
http.get(url, function (res) {
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
arcDetail = filterArticle( html );
str = jade.renderFile('./views/layout.jade', arcDetail );
fs.writeFile( './html/' + arcDetail['id'] + '.html', str, function( err ){
if( err ) {
console.log( err );
}
console.log( 'success:' + url );
if ( aUrl.length ) crawlerArc( aUrl.shift() );
} );
});
});
}
function filterHtml(html) {
var $ = cheerio.load(html);
var arcList = [];
var aPost = $("#content").find(".post-list-item");
aPost.each(function () {
var ele = $(this);
var title = ele.find("h2 a").text();
var url = ele.find("h2 a").attr("href");
ele.find(".c_b_p_desc a").remove();
var entry = ele.find(".c_b_p_desc").text();
ele.find("small a").remove();
var listTime = ele.find("small").text();
var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
listTime = listTime.match(re)[0];
arcList.push({
title: title,
url: url,
entry: entry,
listTime: listTime
});
});
return arcList;
}
function nextPage( html ){
var $ = cheerio.load(html);
var nextUrl = $("#pager a:last-child").attr('href');
if ( !nextUrl ) return getArcUrl( aList );
var curPage = $("#pager .current").text();
if( !curPage ) curPage = 1;
var nextPage = nextUrl.substring( nextUrl.indexOf( '=' ) + 1 );
if ( curPage < nextPage ) crawler( nextUrl );
}
function crawler(url) {
http.get(url, function (res) {
var html = '';
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
aList.push( filterHtml(html) );
nextPage( html );
});
});
}
function getArcUrl( arcList ){
for( var key in arcList ){
for( var k in arcList[key] ){
aUrl.push( arcList[key][k]['url'] );
}
}
crawlerArc( aUrl.shift() );
}
var url = 'http://www.cnblogs.com/ghostwu/';
crawler( url );Fichier layout.jade :
doctype html
html
head
meta(charset='utf-8')
title jade+node.js express
link(rel="stylesheet", href='./css/bower_components/bootstrap/dist/css/bootstrap.min.css')
body
block header
p.container
p.well.well-lg
h3 ghostwu的博客
p js高手之路
block container
p.container
h3
a(href="#{href}" rel="external nofollow" ) !{title}
p !{body}
block footer
p.container
footer 版权所有 - by ghostwuPlans de suivi :
1. Utiliser mongodb pour le stockage
2. Prise en charge de la collecte de points d'arrêt
3. . Collectez des images
4, collectionnez des romans
etc....
Recommandations associées :
À propos de la méthode d'exécution. instructions php sur les fichiers HTML statiques
exemple php de la manière la plus simple de générer des pages HTML statiques
Utilisez xmldom pour générer des pages HTML statiques sur le côté serveur
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment mettre en œuvre un système de reconnaissance vocale en ligne à l'aide de WebSocket et JavaScript
Dec 17, 2023 pm 02:54 PM
Comment mettre en œuvre un système de reconnaissance vocale en ligne à l'aide de WebSocket et JavaScript
Dec 17, 2023 pm 02:54 PM
Comment utiliser WebSocket et JavaScript pour mettre en œuvre un système de reconnaissance vocale en ligne Introduction : Avec le développement continu de la technologie, la technologie de reconnaissance vocale est devenue une partie importante du domaine de l'intelligence artificielle. Le système de reconnaissance vocale en ligne basé sur WebSocket et JavaScript présente les caractéristiques d'une faible latence, d'un temps réel et d'une multiplateforme, et est devenu une solution largement utilisée. Cet article explique comment utiliser WebSocket et JavaScript pour implémenter un système de reconnaissance vocale en ligne.
 WebSocket et JavaScript : technologies clés pour mettre en œuvre des systèmes de surveillance en temps réel
Dec 17, 2023 pm 05:30 PM
WebSocket et JavaScript : technologies clés pour mettre en œuvre des systèmes de surveillance en temps réel
Dec 17, 2023 pm 05:30 PM
WebSocket et JavaScript : technologies clés pour réaliser des systèmes de surveillance en temps réel Introduction : Avec le développement rapide de la technologie Internet, les systèmes de surveillance en temps réel ont été largement utilisés dans divers domaines. L'une des technologies clés pour réaliser une surveillance en temps réel est la combinaison de WebSocket et de JavaScript. Cet article présentera l'application de WebSocket et JavaScript dans les systèmes de surveillance en temps réel, donnera des exemples de code et expliquera leurs principes de mise en œuvre en détail. 1. Technologie WebSocket
 Comment utiliser JavaScript et WebSocket pour mettre en œuvre un système de commande en ligne en temps réel
Dec 17, 2023 pm 12:09 PM
Comment utiliser JavaScript et WebSocket pour mettre en œuvre un système de commande en ligne en temps réel
Dec 17, 2023 pm 12:09 PM
Introduction à l'utilisation de JavaScript et de WebSocket pour mettre en œuvre un système de commande en ligne en temps réel : avec la popularité d'Internet et les progrès de la technologie, de plus en plus de restaurants ont commencé à proposer des services de commande en ligne. Afin de mettre en œuvre un système de commande en ligne en temps réel, nous pouvons utiliser les technologies JavaScript et WebSocket. WebSocket est un protocole de communication full-duplex basé sur le protocole TCP, qui peut réaliser une communication bidirectionnelle en temps réel entre le client et le serveur. Dans le système de commande en ligne en temps réel, lorsque l'utilisateur sélectionne des plats et passe une commande
 Comment mettre en œuvre un système de réservation en ligne à l'aide de WebSocket et JavaScript
Dec 17, 2023 am 09:39 AM
Comment mettre en œuvre un système de réservation en ligne à l'aide de WebSocket et JavaScript
Dec 17, 2023 am 09:39 AM
Comment utiliser WebSocket et JavaScript pour mettre en œuvre un système de réservation en ligne. À l'ère numérique d'aujourd'hui, de plus en plus d'entreprises et de services doivent fournir des fonctions de réservation en ligne. Il est crucial de mettre en place un système de réservation en ligne efficace et en temps réel. Cet article explique comment utiliser WebSocket et JavaScript pour implémenter un système de réservation en ligne et fournit des exemples de code spécifiques. 1. Qu'est-ce que WebSocket ? WebSocket est une méthode full-duplex sur une seule connexion TCP.
 JavaScript et WebSocket : créer un système efficace de prévisions météorologiques en temps réel
Dec 17, 2023 pm 05:13 PM
JavaScript et WebSocket : créer un système efficace de prévisions météorologiques en temps réel
Dec 17, 2023 pm 05:13 PM
JavaScript et WebSocket : Construire un système efficace de prévisions météorologiques en temps réel Introduction : Aujourd'hui, la précision des prévisions météorologiques revêt une grande importance pour la vie quotidienne et la prise de décision. À mesure que la technologie évolue, nous pouvons fournir des prévisions météorologiques plus précises et plus fiables en obtenant des données météorologiques en temps réel. Dans cet article, nous apprendrons comment utiliser la technologie JavaScript et WebSocket pour créer un système efficace de prévisions météorologiques en temps réel. Cet article démontrera le processus de mise en œuvre à travers des exemples de code spécifiques. Nous
 Tutoriel JavaScript simple : Comment obtenir le code d'état HTTP
Jan 05, 2024 pm 06:08 PM
Tutoriel JavaScript simple : Comment obtenir le code d'état HTTP
Jan 05, 2024 pm 06:08 PM
Tutoriel JavaScript : Comment obtenir le code d'état HTTP, des exemples de code spécifiques sont requis Préface : Dans le développement Web, l'interaction des données avec le serveur est souvent impliquée. Lors de la communication avec le serveur, nous devons souvent obtenir le code d'état HTTP renvoyé pour déterminer si l'opération a réussi et effectuer le traitement correspondant en fonction de différents codes d'état. Cet article vous apprendra comment utiliser JavaScript pour obtenir des codes d'état HTTP et fournira quelques exemples de codes pratiques. Utilisation de XMLHttpRequest
 Comment utiliser insertBefore en javascript
Nov 24, 2023 am 11:56 AM
Comment utiliser insertBefore en javascript
Nov 24, 2023 am 11:56 AM
Utilisation : En JavaScript, la méthode insertBefore() est utilisée pour insérer un nouveau nœud dans l'arborescence DOM. Cette méthode nécessite deux paramètres : le nouveau nœud à insérer et le nœud de référence (c'est-à-dire le nœud où le nouveau nœud sera inséré).
 JavaScript et WebSocket : créer un système de traitement d'images en temps réel efficace
Dec 17, 2023 am 08:41 AM
JavaScript et WebSocket : créer un système de traitement d'images en temps réel efficace
Dec 17, 2023 am 08:41 AM
JavaScript est un langage de programmation largement utilisé dans le développement Web, tandis que WebSocket est un protocole réseau utilisé pour la communication en temps réel. En combinant les puissantes fonctions des deux, nous pouvons créer un système efficace de traitement d’images en temps réel. Cet article présentera comment implémenter ce système à l'aide de JavaScript et WebSocket, et fournira des exemples de code spécifiques. Tout d’abord, nous devons clarifier les exigences et les objectifs du système de traitement d’images en temps réel. Supposons que nous disposions d'un appareil photo capable de collecter des données d'image en temps réel.
