

Cet article présente principalement comment la technologie Web peut réaliser la surveillance de mouvement, la détection de mouvement, également généralement appelée détection de mouvement, qui est souvent utilisée pour la vidéo de surveillance sans surveillance et l'alarme automatique. Les images collectées par la caméra à différentes fréquences d'images seront calculées et comparées par le processeur selon un certain algorithme. Lorsque l'image change, par exemple si quelqu'un passe et que l'objectif est déplacé, le nombre obtenu à partir des résultats du calcul et de la comparaison sera. dépasser le seuil et indiquer que le système peut automatiquement effectuer le traitement correspondant
Introduction à la surveillance mobile à l'aide de la technologie Web
De la citation ci-dessus, on peut conclure que « mobile surveillance" nécessite les éléments suivants :
Un ordinateur doté d'une caméra est utilisé pour déterminer le mouvement de l'algorithme. Traitement post-mouvement
Remarque : Tous les cas impliqués dans cet article sont basé sur les versions les plus récentes des navigateurs Chrome/Firefox pour PC/Mac. Certains cas nécessitent d'être complétés avec l'appareil photo, toutes les captures d'écran sont enregistrées localement.
L'autre partie ne veut pas vous parler et vous lance un lien :
Boîtier complet
Ce boitier a les deux fonctions suivantes :
La photo sera prise 1 seconde après la prise du POST et la musique s'arrêtera après 1 seconde d'immobilité. S'il y a un mouvement, l'état de lecture reprendra
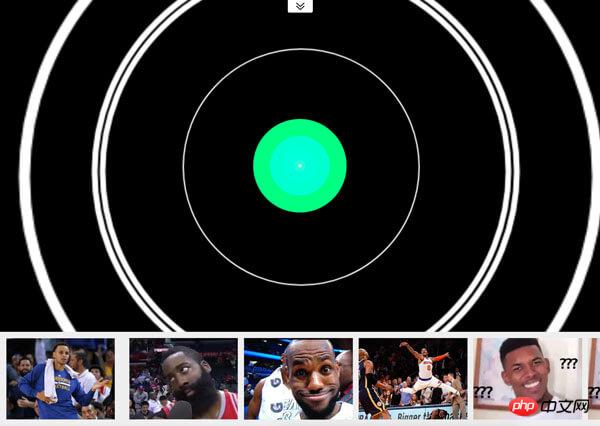
Le cas ci-dessus peut ne pas refléter directement l'effet et le principe réels de la « surveillance mobile ».
Différence de pixels
Le côté gauche du boîtier est la source vidéo, tandis que le le côté droit est C'est le traitement des pixels après le mouvement (pixélation, juger du mouvement et ne garder que le vert, etc.).
Parce qu'elle est basée sur la technologie Web, la source vidéo utilise WebRTC et le traitement des pixels utilise Canvas.
Source vidéo
Ne s'appuie pas sur Flash ou Silverlight, nous utilisons l'API navigator.getUserMedia() dans WebRTC (Web Real-Time Communications), qui permet au web applications Obtenez les flux de la caméra et du microphone de l'utilisateur.
L'exemple de code est le suivant :
<!-- 若不加 autoplay,则会停留在第一帧 -->
<video id="video" autoplay></video>
// 具体参数含义可看相关文档。
const constraints = {
audio: false,
video: {
width: 640,
height: 480
}
}
navigator.mediaDevices.getUserMedia(constraints)
.then(stream => {
// 将视频源展示在 video 中
video.srcObject = stream
})
.catch(err => {
console.log(err)
})Pour des problèmes de compatibilité, Safari 11 commence à prendre en charge WebRTC. Voir caniuse pour plus de détails.
Traitement des pixels
Après avoir obtenu la source vidéo, nous avons le matériel pour juger si l'objet bouge. Bien entendu, aucun algorithme de reconnaissance avancé n'est utilisé ici. Il utilise simplement la différence de pixels entre deux captures d'écran consécutives pour déterminer si l'objet a bougé (à proprement parler, il s'agit d'un changement dans l'image).
Captures d'écran
Exemple de code pour obtenir des captures d'écran de la source vidéo :
const video = document.getElementById('video')
const canvas = document.createElement('canvas')
const ctx = canvas.getContext('2d')
canvas.width = 640
canvas.height = 480
// 获取视频中的一帧
function capture () {
ctx.drawImage(video, 0, 0, canvas.width, canvas.height)
// ...其它操作
}Obtenez la différence entre captures d'écran Différence
Pour la différence de pixels entre les deux images, la collision de « détection de pixels » mentionnée dans ce billet de blog « « Attendez une minute, laissez-moi toucher ! » - Détection de collision 2D commune » par Alveolar Lab Algorithms sont une solution. Cet algorithme détermine s'il y a une collision en vérifiant si la transparence des pixels à la même position de deux toiles hors écran est supérieure à 0 en même temps. Bien sûr, ici nous devons le changer en "si les pixels à la même position sont différents (ou si la différence est inférieure à un certain seuil)" pour déterminer s'il est déplacé ou non.
Mais la méthode ci-dessus est un peu lourde et inefficace. Ici, nous utilisons ctx.globalCompositeOperation = 'difference' pour spécifier la méthode de synthèse des nouveaux éléments sur le canevas (c'est-à-dire la deuxième capture d'écran et la première capture d'écran) afin d'obtenir la différence entre les deux. deux captures d'écran.
Lien d'expérience>>
Exemple de code :
function diffTwoImage () {
// 设置新增元素的合成方式
ctx.globalCompositeOperation = 'difference'
// 清除画布
ctx.clearRect(0, 0, canvas.width, canvas.height)
// 假设两张图像尺寸相等
ctx.drawImage(firstImg, 0, 0)
ctx.drawImage(secondImg, 0, 0)
}
Différence entre les deux images
Après avoir vécu les cas ci-dessus, avez-vous envie de jouer au « jeu QQ « Trouvons la différence » » à l'époque. De plus, ce cas peut également s'appliquer aux deux situations suivantes :
Lorsque vous ne connaissez pas la différence entre les deux ébauches de conception que le designer vous a données avant et après
Quand on veut voir la différence de rendu d'une même page web par deux navigateurs, lorsqu'il s'agit d'une "action"
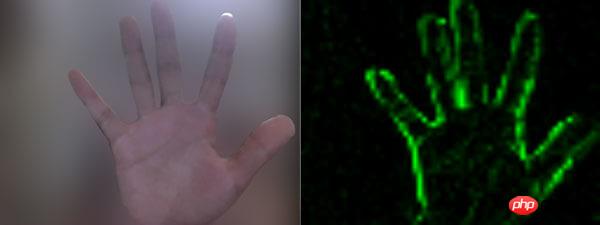
Par ce qui précède Cas « différence de deux images » Obtenu à partir du centre : Le noir signifie que le pixel à cette position n'a pas changé, et plus le pixel est clair, plus le « mouvement » est important à ce point. Par conséquent, lorsqu'il y a des pixels brillants après avoir combiné deux captures d'écran consécutives, il s'agit d'une « action ». Mais afin de rendre le programme moins « sensible », on peut fixer un seuil. Lorsque le nombre de pixels lumineux est supérieur au seuil, une « action » est considérée comme s'étant produite. Bien entendu, on peut également éliminer les pixels « pas assez lumineux » pour éviter au maximum l'influence des environnements extérieurs (comme les lumières, etc.).
想要获取 Canvas 的像素信息,需要通过 ctx.getImageData(sx, sy, sw, sh),该 API 会返回你所指定画布区域的像素对象。该对象包含 data、width、height。其中 data 是一个含有每个像素点 RGBA 信息的一维数组,如下图所示。

含有 RGBA 信息的一维数组
获取到特定区域的像素后,我们就能对每个像素进行处理(如各种滤镜效果)。处理完后,则可通过 ctx.putImageData() 将其渲染在指定的 Canvas 上。
扩展:由于 Canvas 目前没有提供“历史记录”的功能,如需实现“返回上一步”操作,则可通过 getImageData 保存上一步操作,当需要时则可通过 putImageData 进行复原。
示例代码:
let imageScore = 0
const rgba = imageData.data
for (let i = 0; i < rgba.length; i += 4) {
const r = rgba[i] / 3
const g = rgba[i + 1] / 3
const b = rgba[i + 2] / 3
const pixelScore = r + g + b
// 如果该像素足够明亮
if (pixelScore >= PIXEL_SCORE_THRESHOLD) {
imageScore++
}
}
// 如果明亮的像素数量满足一定条件
if (imageScore >= IMAGE_SCORE_THRESHOLD) {
// 产生了移动
}在上述案例中,你也许会注意到画面是『绿色』的。其实,我们只需将每个像素的红和蓝设置为 0,即将 RGBA 的 r = 0; b = 0 即可。这样就会像电影的某些镜头一样,增加了科技感和神秘感。
体验地址>>
const rgba = imageData.data
for (let i = 0; i < rgba.length; i += 4) {
rgba[i] = 0 // red
rgba[i + 2] = 0 // blue
}
ctx.putImageData(imageData, 0, 0)
将 RGBA 中的 R 和 B 置为 0
跟踪“移动物体”
有了明亮的像素后,我们就要找出其 x 坐标的最小值与 y 坐标的最小值,以表示跟踪矩形的左上角。同理,x 坐标的最大值与 y 坐标的最大值则表示跟踪矩形的右下角。至此,我们就能绘制出一个能包围所有明亮像素的矩形,从而实现跟踪移动物体的效果。
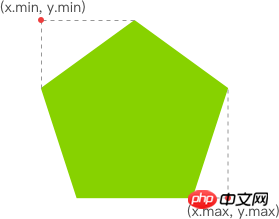
Comment la technologie Web réalise la surveillance mobile
体验链接>>
示例代码:
function processDiff (imageData) {
const rgba = imageData.data
let score = 0
let pixelScore = 0
let motionBox = 0
// 遍历整个 canvas 的像素,以找出明亮的点
for (let i = 0; i < rgba.length; i += 4) {
pixelScore = (rgba[i] + rgba[i+1] + rgba[i+2]) / 3
// 若该像素足够明亮
if (pixelScore >= 80) {
score++
coord = calcCoord(i)
motionBox = calcMotionBox(montionBox, coord.x, coord.y)
}
}
return {
score,
motionBox
}
}
// 得到左上角和右下角两个坐标值
function calcMotionBox (curMotionBox, x, y) {
const motionBox = curMotionBox || {
x: { min: coord.x, max: x },
y: { min: coord.y, max: y }
}
motionBox.x.min = Math.min(motionBox.x.min, x)
motionBox.x.max = Math.max(motionBox.x.max, x)
motionBox.y.min = Math.min(motionBox.y.min, y)
motionBox.y.max = Math.max(motionBox.y.max, y)
return motionBox
}
// imageData.data 是一个含有每个像素点 rgba 信息的一维数组。
// 该函数是将上述一维数组的任意下标转为 (x,y) 二维坐标。
function calcCoord(i) {
return {
x: (i / 4) % diffWidth,
y: Math.floor((i / 4) / diffWidth)
}
}在得到跟踪矩形的左上角和右下角的坐标值后,通过 ctx.strokeRect(x, y, width, height) API 绘制出矩形即可。
ctx.lineWidth = 6 ctx.strokeRect( diff.motionBox.x.min + 0.5, diff.motionBox.y.min + 0.5, diff.motionBox.x.max - diff.motionBox.x.min, diff.motionBox.y.max - diff.motionBox.y.min )

这是理想效果,实际效果请打开 体验链接
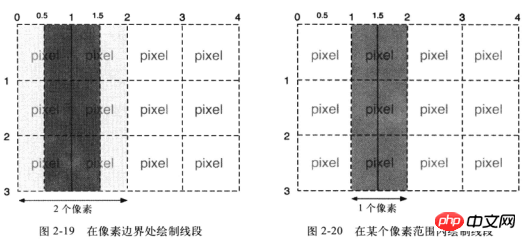
扩展:为什么上述绘制矩形的代码中的
x、y要加0.5呢?一图胜千言:
性能缩小尺寸
在上一个章节提到,我们需要通过对 Canvas 每个像素进行处理,假设 Canvas 的宽为 640,高为 480,那么就需要遍历 640 * 480 = 307200 个像素。而在监测效果可接受的前提下,我们可以将需要进行像素处理的 Canvas 缩小尺寸,如缩小 10 倍。这样需要遍历的像素数量就降低 100 倍,从而提升性能。
体验地址>>
示例代码:
const motionCanvas // 展示给用户看 const backgroundCanvas // offscreen canvas 背后处理数据 motionCanvas.width = 640 motionCanvas.height = 480 backgroundCanvas.width = 64 backgroundCanvas.height = 48

尺寸缩小 10 倍
定时器
我们都知道,当游戏以『每秒60帧』运行时才能保证一定的体验。但对于我们目前的案例来说,帧率并不是我们追求的第一位。因此,每 100 毫秒(具体数值取决于实际情况)取当前帧与前一帧进行比较即可。
另外,因为我们的动作一般具有连贯性,所以可取该连贯动作中幅度最大的(即“分数”最高)或最后一帧动作进行处理即可(如存储到本地或分享到朋友圈)。
延伸
至此,用 Web 技术实现简易的“移动监测”效果已基本讲述完毕。由于算法、设备等因素的限制,该效果只能以 2D 画面为基础来判断物体是否发生“移动”。而微软的 Xbox、索尼的 PS、任天堂的 Wii 等游戏设备上的体感游戏则依赖于硬件。以微软的 Kinect 为例,它为开发者提供了可跟踪最多六个完整骨骼和每人 25 个关节等强大功能。利用这些详细的人体参数,我们就能实现各种隔空的『手势操作』,如画圈圈诅咒某人。
下面几个是通过 Web 使用 Kinect 的库:
DepthJS:以浏览器插件形式提供数据访问。
Node-Kinect2: 以 Nodejs 搭建服务器端,提供数据比较完整,实例较多。
ZigFu : supporte H5, U3D, Flash, et possède une API relativement complète.
Kinect-HTML5 : Kinect-HTML5 utilise C# pour créer un serveur et fournir des données de couleur, des données de profondeur et des données osseuses.
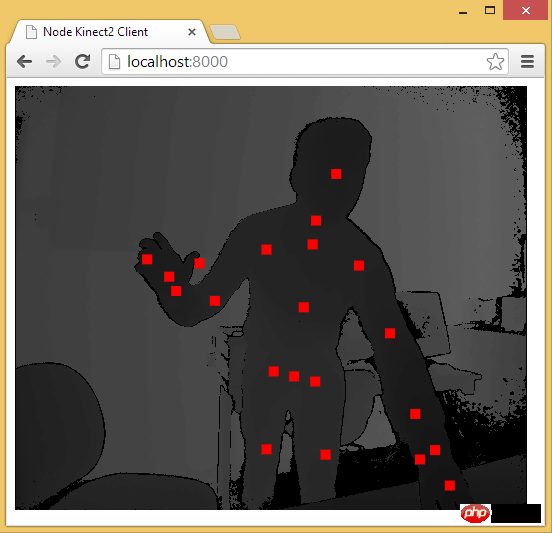
Obtenir des données squelettiques via Node-Kinect2
Recommandations associées :
surveillance globale des opérations ajax , Solutions à l'échec de la session utilisateur
10 contenus recommandés dans la catégorie de surveillance du temps
Catégorie de surveillance du temps d'exécution de la page PHP Timer
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comparez les similitudes et les différences entre deux colonnes de données dans Excel
Comparez les similitudes et les différences entre deux colonnes de données dans Excel
 Tutoriel de récupération des icônes de mon ordinateur Win10
Tutoriel de récupération des icônes de mon ordinateur Win10
 utilisation de la fonction de tri
utilisation de la fonction de tri
 Comment installer le pilote d'imprimante sous Linux
Comment installer le pilote d'imprimante sous Linux
 Comment débloquer les restrictions d'autorisation Android
Comment débloquer les restrictions d'autorisation Android
 Marquage de couleur du filtre en double Excel
Marquage de couleur du filtre en double Excel
 qu'est-ce que l'optimisation
qu'est-ce que l'optimisation
 Comment réparer la base de données SQL
Comment réparer la base de données SQL
 Comment utiliser l'ajout en python
Comment utiliser l'ajout en python








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



