

Explication détaillée du robot NodeJS

1. Processus d'exploration
Notre objectif ultime est d'explorer les ventes quotidiennes de Lima Financial Management et de savoir quels produits sont vendus et quels utilisateurs de chaque produit sont utilisés à quel moment acheté. Tout d'abord, présentons les principales étapes du crawl :
1. Analyse structurelle
Nous souhaitons explorer les données de la page. La première étape consiste bien sûr à analyser la structure de la page et ce qu'il faut explorer. Page, quelle est la structure de la page, nécessite-t-elle une connexion ? Existe-t-il une interface ajax, quel type de données est renvoyée, etc.
2. Exploration des données
Après avoir analysé clairement les pages et les ajax à explorer, il est temps d'explorer les données. Les données des pages Web actuelles sont grossièrement divisées en pages de synchronisation et interfaces ajax. La capture synchrone des données de page nous oblige à analyser d'abord la structure de la page Web. Python capture les données généralement via une correspondance d'expressions régulières pour obtenir les données requises ; le nœud dispose d'un outil cheerio qui peut convertir le contenu de la page obtenu en un objet jquery. peut utiliser la puissante API dom de jquery pour obtenir des données liées aux nœuds. En fait, si vous regardez le code source, l'essence de ces API est une correspondance régulière. Les données de l'interface Ajax sont généralement au format json et sont relativement simples à traiter.
3. Stockage des données
Après les données capturées, un simple filtrage sera effectué et les données requises seront d'abord enregistrées pour une analyse et un traitement ultérieurs. Bien sûr, nous pouvons utiliser des bases de données telles que MySQL et Mongodb pour stocker des données. Ici, pour plus de commodité, nous utilisons directement le stockage de fichiers.
4. Analyse des données
Parce que nous souhaitons finalement afficher les données, nous devons traiter et analyser les données originales selon certaines dimensions, puis les renvoyer au client. Ce processus peut être traité pendant le stockage ou pendant l'affichage, le front-end envoie une requête et l'arrière-plan récupère les données stockées et les traite à nouveau. Cela dépend de la manière dont nous souhaitons afficher les données.
5. Affichage des résultats
Après tant de travail, il n'y a aucune sortie d'affichage, comment s'en contenter ? Nous revenons à notre ancienne activité, et tout le monde devrait être familier avec la page d'affichage frontale. L'affichage des données est plus intuitif et facilite l'analyse des statistiques.
2. Introduction aux bibliothèques couramment utilisées pour les robots d'exploration
1. Superagent
Superagent est une bibliothèque http légère et un module proxy de demande client très pratique dans nodejs. devez faire des requêtes réseau telles que get, post, head, etc., essayez-le.
2. Cheerio
Cheerio peut être compris comme une version Node.js de jquery, qui est utilisée pour récupérer des données à partir de pages Web à l'aide du sélecteur CSS. La méthode d'utilisation est exactement la même que celle de jquery. .
3. Async
Async est une boîte à outils de contrôle de processus qui fournit une fonction asynchrone directe et puissante mapLimit(arr, limit, iterator, callback). Nous utilisons principalement cette méthode. l'API sur le site officiel.
4. arr-del
arr-del est un outil que j'ai écrit moi-même pour supprimer des éléments d'un tableau. Vous pouvez effectuer une suppression unique en transmettant un tableau constitué de l'index des éléments du tableau à supprimer.
5. arr-sort
arr-sort est un outil de tri de tableaux que j'ai écrit moi-même. Le tri peut être basé sur un ou plusieurs attributs et les attributs imbriqués sont pris en charge. De plus, le sens de tri peut être spécifié dans chaque condition et des fonctions de comparaison peuvent être transmises.
3. Analyse de la structure des pages
Passons d'abord en revue nos idées d'exploration. Les produits sur Lima Financial Management Online sont principalement à terme fixe et Lima Treasury (les derniers produits de gestion financière d'Everbright Bank sont difficiles à traiter et ont des montants d'investissement de départ élevés, donc presque personne ne les achète, il n'y a donc pas de statistiques ici). Régulièrement nous pouvons explorer l'interface ajax de la page de gestion financière : https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=0. (Mise à jour : régulièrement en rupture de stock dans un avenir proche, vous ne pourrez peut-être pas voir les données) Les données sont présentées dans la figure ci-dessous :
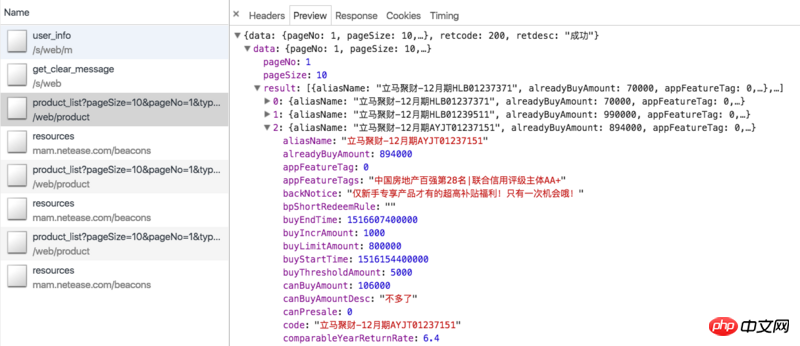
Cela inclut tous les produits actuellement en vente en ligne. Pour les produits périodiques, les données ajax ne contiennent que des informations liées au produit lui-même, telles que l'identifiant du produit, le montant levé, les ventes en cours, le taux de rendement annualisé, le nombre de jours d'investissement, etc. , mais aucune information sur les utilisateurs qui ont acheté le produit. Nous devons donc utiliser le paramètre id pour explorer immédiatement la page de détails du produit, comme Jucai - numéro de décembre HLB01239511. La page de détails comporte une colonne de dossiers d'investissement, qui contient les informations dont nous avons besoin, comme le montre la figure ci-dessous :
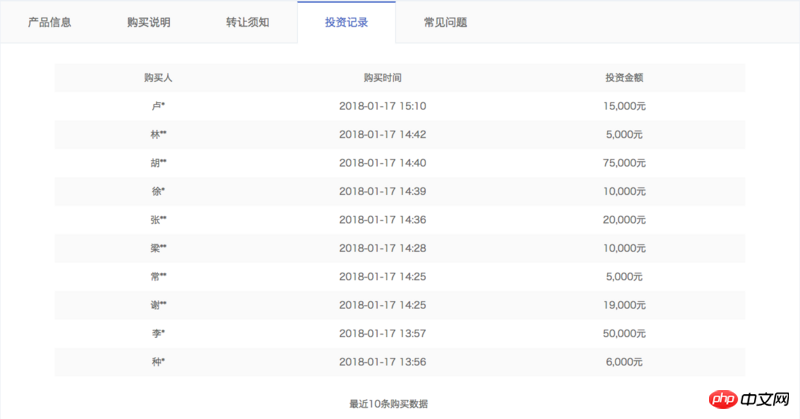
Cependant, la page de détails nous oblige à nous connecter. Il ne peut être consulté que dans le statut, ce qui nous oblige à apporter des cookies pour visiter, et les cookies ont des limites de validité. Comment conserver nos cookies dans l'état connecté ? Veuillez voir ci-dessous.
En fait, Lima Treasury dispose également d'une interface ajax similaire : https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=1, mais les données pertinentes à l'intérieur sont codées en dur et n'ont aucun sens. De plus, il n’y a aucune information sur l’enregistrement d’investissement sur la page de détails du coffre-fort. Cela nous oblige à explorer l'interface ajax de la page d'accueil mentionnée au début : https://www.lmlc.com/s/web/home/user_buying. Mais plus tard, j'ai découvert que cette interface est mise à jour toutes les trois minutes, ce qui signifie que l'arrière-plan demande des données au serveur toutes les trois minutes. Il y a 10 éléments de données à la fois, donc si le nombre d'enregistrements de produits achetés dépasse 10 dans un délai de trois minutes, les données seront omises. Il n'y a aucun moyen de contourner ce problème, donc les statistiques du Trésor de Lima seront inférieures aux statistiques réelles.
4. Analyse du code du robot
1. Obtenir le cookie de connexion
Étant donné que la page de détails du produit nécessite une connexion, nous devons d'abord obtenir le cookie de connexion. La méthode getCookie est la suivante :
function getCookie() {
superagent.post('https://www.lmlc.com/user/s/web/logon')
.type('form')
.send({
phone: phone,
password: password,
productCode: "LMLC",
origin: "PC"
})
.end(function(err, res) {
if (err) {
handleErr(err.message);
return;
}
cookie = res.header['set-cookie']; //从response中得到cookie
emitter.emit("setCookeie");
})
}Les paramètres de téléphone et de mot de passe sont transmis à partir de la ligne de commande, qui sont le numéro de compte et le mot de passe utilisés pour se connecter immédiatement à Financial Management avec le numéro de téléphone mobile. Nous utilisons un superagent pour simuler la demande d'interface de connexion instantanée à la gestion financière : https://www.lmlc.com/user/s/web/logon. Transmettez les paramètres correspondants. Dans le rappel, nous obtenons les informations set-cookie de l'en-tête et envoyons un événement setCookeie. Parce que nous avons mis en place un événement d'écoute : emitter.on("setCookie", requestData), une fois le cookie obtenu, nous exécuterons la méthode requestData.
2. Crawling Ajax de la page de gestion financière
Le code de la méthode requestData est le suivant :
function requestData() {
superagent.get('https://www.lmlc.com/web/product/product_list?pageSize=100&pageNo=1&type=0')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
// 在这里清空数据,避免一个文件被同时写入
if(clearProd){
fs.writeFileSync('data/prod.json', JSON.stringify([]));
clearProd = false;
}
let addData = JSON.parse(pres.text).data;
let formatedAddData = formatData(addData.result);
let pageUrls = [];
if(addData.totalPage > 1){
handleErr('产品个数超过100个!');
return;
}
for(let i=0,len=addData.result.length; i<len; i++){
if(+new Date() < addData.result[i].buyStartTime){
if(preIds.indexOf(addData.result[i].id) == -1){
preIds.push(addData.result[i].id);
setPreId(addData.result[i].buyStartTime, addData.result[i].id);
}
}else{
pageUrls.push('https://www.lmlc.com/web/product/product_detail.html?id=' + addData.result[i].id);
}
}
function setPreId(time, id){
cache[id] = setInterval(function(){
if(time - (+new Date()) < 1000){
// 预售产品开始抢购,直接修改爬取频次为1s,防止丢失数据
clearInterval(cache[id]);
clearInterval(timer);
delay = 1000;
timer = setInterval(function(){
requestData();
}, delay);
// 同时删除id记录
let index = preIds.indexOf(id);
sort.delArrByIndex(preIds, [index]);
}
}, 1000)
}
// 处理售卖金额信息
let oldData = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
for(let i=0, len=formatedAddData.length; i<len; i++){
let isNewProduct = true;
for(let j=0, len2=oldData.length; j<len2; j++){
if(formatedAddData[i].productId === oldData[j].productId){
isNewProduct = false;
}
}
if(isNewProduct){
oldData.push(formatedAddData[i]);
}
}
fs.writeFileSync('data/prod.json', JSON.stringify(oldData));
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log((`理财列表ajax接口爬取完毕,时间:${time}`).warn);
if(!pageUrls.length){
delay = 32*1000;
clearInterval(timer);
timer = setInterval(function(){
requestData();
}, delay);
return
}
getDetailData();
});
}Le code est très long, et la fonction getDetailData le code sera analysé plus tard.
L'interface ajax demandée est une interface de pagination, car généralement le nombre total de produits en vente ne dépassera pas 10. Ici nous fixons le paramètre pageSize à 100, afin que tous les produits puissent être obtenus en même temps.
clearProd est un signal de réinitialisation global à 0 heures chaque jour, les données prod (produit régulier) et utilisateur (utilisateur de la page d'accueil) seront effacées.
Parce que parfois les produits sont rarement vendus lors de ventes urgentes, comme à 10 heures tous les jours, les données seront donc mises à jour rapidement à 10 heures chaque jour. Nous devons augmenter la fréquence d'exploration pour éviter. perte de données. Par conséquent, pour les produits en prévente, c'est-à-dire que buyStartTime est supérieur à l'heure actuelle, nous devons l'enregistrer et définir une minuterie. Lorsque la vente commence, ajustez la fréquence d'exploration à 1 fois/seconde, voir la méthode setPreId.
S'il n'y a aucun produit à vendre, c'est-à-dire que pageUrls est vide, nous définirons la fréquence d'exploration à un maximum de 32 secondes.
Cette partie du code de la fonction requestData enregistre principalement s'il y a de nouveaux produits. Si tel est le cas, créez un nouvel objet, enregistrez les informations sur le produit et transférez-le vers le tableau prod. La structure de données prod.json est la suivante :
[{
"productName": "立马聚财-12月期HLB01230901",
"financeTotalAmount": 1000000,
"productId": "201801151830PD84123120",
"yearReturnRate": 6.4,
"investementDays": 364,
"interestStartTime": "2018年01月23日",
"interestEndTime": "2019年01月22日",
"getDataTime": 1516118401299,
"alreadyBuyAmount": 875000,
"records": [
{
"username": "刘**",
"buyTime": 1516117093472,
"buyAmount": 30000,
"uniqueId": "刘**151611709347230,000元"
},
{
"username": "刘**",
"buyTime": 1516116780799,
"buyAmount": 50000,
"uniqueId": "刘**151611678079950,000元"
}]
}]est un tableau d'objets, chaque objet représente un nouveau produit et l'attribut records enregistre les informations de vente.
3. Explorez la page de détails du produit
Jetons un coup d'œil au code de getDetailData :
function getDetailData(){
// 请求用户信息接口,来判断登录是否还有效,在产品详情页判断麻烦还要造成五次登录请求
superagent
.post('https://www.lmlc.com/s/web/m/user_info')
.set('Cookie', cookie)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
let retcode = JSON.parse(pres.text).retcode;
if(retcode === 410){
handleErr('登陆cookie已失效,尝试重新登陆...');
getCookie();
return;
}
var reptileLink = function(url,callback){
// 如果爬取页面有限制爬取次数,这里可设置延迟
console.log( '正在爬取产品详情页面:' + url);
superagent
.get(url)
.set('Cookie', cookie)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
var $ = cheerio.load(pres.text);
var records = [];
var $table = $('.buy-records table');
if(!$table.length){
$table = $('.tabcontent table');
}
var $tr = $table.find('tr').slice(1);
$tr.each(function(){
records.push({
username: $('td', $(this)).eq(0).text(),
buyTime: parseInt($('td', $(this)).eq(1).attr('data-time').replace(/,/g, '')),
buyAmount: parseFloat($('td', $(this)).eq(2).text().replace(/,/g, '')),
uniqueId: $('td', $(this)).eq(0).text() + $('td', $(this)).eq(1).attr('data-time').replace(/,/g, '') + $('td', $(this)).eq(2).text()
})
});
callback(null, {
productId: url.split('?id=')[1],
records: records
});
});
};
async.mapLimit(pageUrls, 10 ,function (url, callback) {
reptileLink(url, callback);
}, function (err,result) {
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log(`所有产品详情页爬取完毕,时间:${time}`.info);
let oldRecord = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
let counts = [];
for(let i=0,len=result.length; i<len; i++){
for(let j=0,len2=oldRecord.length; j<len2; j++){
if(result[i].productId === oldRecord[j].productId){
let count = 0;
let newRecords = [];
for(let k=0,len3=result[i].records.length; k<len3; k++){
let isNewRec = true;
for(let m=0,len4=oldRecord[j].records.length; m<len4; m++){
if(result[i].records[k].uniqueId === oldRecord[j].records[m].uniqueId){
isNewRec = false;
}
}
if(isNewRec){
count++;
newRecords.push(result[i].records[k]);
}
}
oldRecord[j].records = oldRecord[j].records.concat(newRecords);
counts.push(count);
}
}
}
let oldDelay = delay;
delay = getNewDelay(delay, counts);
function getNewDelay(delay, counts){
let nowDate = (new Date()).toLocaleDateString();
let time1 = Date.parse(nowDate + ' 00:00:00');
let time2 = +new Date();
// 根据这次更新情况,来动态设置爬取频次
let maxNum = Math.max(...counts);
if(maxNum >=0 && maxNum <= 2){
delay = delay + 1000;
}
if(maxNum >=8 && maxNum <= 10){
delay = delay/2;
}
// 每天0点,prod数据清空,排除这个情况
if(maxNum == 10 && (time2 - time1 >= 60*1000)){
handleErr('部分数据可能丢失!');
}
if(delay <= 1000){
delay = 1000;
}
if(delay >= 32*1000){
delay = 32*1000;
}
return delay
}
if(oldDelay != delay){
clearInterval(timer);
timer = setInterval(function(){
requestData();
}, delay);
}
fs.writeFileSync('data/prod.json', JSON.stringify(oldRecord));
})
});
}Nous demandons d'abord à l'interface d'informations utilisateur pour déterminer si la connexion est toujours disponible, car il est difficile de juger sur la page de détails du produit et cela entraînera cinq demandes de connexion. Faire une demande avec des cookies est très simple. Il suffit de définir le cookie que nous avons reçu avant la publication : .set('Cookie', cookie). Si le retcode renvoyé par l'arrière-plan est 410, cela signifie que le cookie de connexion a expiré et que getCookie() doit être à nouveau exécuté. Cela garantit que le robot est toujours connecté.
La méthode async mapLimit effectuera des requêtes simultanées pour les pageUrls, avec une concurrence de 10. La méthode reptileLink sera exécutée pour chaque pageUrl. Attendez que toutes les exécutions asynchrones soient terminées avant d'exécuter la fonction de rappel. Le paramètre result de la fonction de rappel est un tableau composé des données renvoyées par chaque fonction reptileLink.
La fonction reptileLink permet d'obtenir les informations de la liste des enregistrements d'investissement de la page de détails du produit. uniqueId est une chaîne composée du nom d'utilisateur connu, des paramètres buyTime et buyAmount, qui est utilisée pour éliminer les doublons.
Le rappel d'async écrit principalement les dernières informations d'enregistrement d'investissement dans l'objet produit correspondant et génère en même temps un tableau de comptes. Le tableau counts est un tableau composé du nombre de nouveaux enregistrements de ventes pour chaque produit analysé cette fois-ci, et est transmis à la fonction getNewDelay avec le délai. getNewDelay ajuste dynamiquement la fréquence d'exploration et les comptes sont la seule base pour ajuster le délai. Si le délai est trop important, cela peut entraîner une perte de données ; s'il est trop petit, cela augmentera la charge sur le serveur et l'administrateur pourra bloquer l'adresse IP. Ici, la valeur maximale du délai est définie sur 32 et la valeur minimale est 1.
4. Exploration Ajax des utilisateurs de la page d'accueil
Tout d'abord, commençons par le code :
function requestData1() {
superagent.get(ajaxUrl1)
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
let newData = JSON.parse(pres.text).data;
let formatNewData = formatData1(newData);
// 在这里清空数据,避免一个文件被同时写入
if(clearUser){
fs.writeFileSync('data/user.json', '');
clearUser = false;
}
let data = fs.readFileSync('data/user.json', 'utf-8');
if(!data){
fs.writeFileSync('data/user.json', JSON.stringify(formatNewData));
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log((`首页用户购买ajax爬取完毕,时间:${time}`).silly);
}else{
let oldData = JSON.parse(data);
let addData = [];
// 排重算法,如果uniqueId不一样那肯定是新生成的,否则看时间差如果是0(三分钟内请求多次)或者三分钟则是旧数据
for(let i=0, len=formatNewData.length; i<len; i++){
let matchArr = [];
for(let len2=oldData.length, j=Math.max(0,len2 - 20); j<len2; j++){
if(formatNewData[i].uniqueId === oldData[j].uniqueId){
matchArr.push(j);
}
}
if(matchArr.length === 0){
addData.push(formatNewData[i]);
}else{
let isNewBuy = true;
for(let k=0, len3=matchArr.length; k<len3; k++){
let delta = formatNewData[i].time - oldData[matchArr[k]].time;
if(delta == 0 || (Math.abs(delta - 3*60*1000) < 1000)){
isNewBuy = false;
// 更新时间,这样下一次判断还是三分钟
oldData[matchArr[k]].time = formatNewData[i].time;
}
}
if(isNewBuy){
addData.push(formatNewData[i]);
}
}
}
fs.writeFileSync('data/user.json', JSON.stringify(oldData.concat(addData)));
let time = (new Date()).format("yyyy-MM-dd hh:mm:ss");
console.log((`首页用户购买ajax爬取完毕,时间:${time}`).silly);
}
});
}L'exploration de user.js est similaire à celle de prod.js. Je veux principalement parler de la façon de perdre du poids. Le format de données user.json est le suivant :
[
{
"payAmount": 5067.31,
"productId": "jsfund",
"productName": "立马金库",
"productType": 6,
"time": 1548489,
"username": "郑**",
"buyTime": 1516118397758,
"uniqueId": "5067.31jsfund郑**"
}, {
"payAmount": 30000,
"productId": "201801151830PD84123120",
"productName": "立马聚财-12月期HLB01230901",
"productType": 0,
"time": 1306573,
"username": "刘**",
"buyTime": 1516117199684,
"uniqueId": "30000201801151830PD84123120刘**"
}]和产品详情页类似,我们也生成一个uniqueId参数用来排除,它是payAmount、productId、username参数的拼成的字符串。如果uniqueId不一样,那肯定是一条新的记录。如果相同那一定是一条新记录吗?答案是否定的。因为这个接口数据是三分钟更新一次,而且给出的时间是相对时间,即数据更新时的时间减去购买的时间。所以每次更新后,即使是同一条记录,时间也会不一样。那如何排重呢?其实很简单,如果uniqueId一样,我们就判断这个buyTime,如果buyTime的差正好接近180s,那么几乎可以肯定是旧数据。如果同一个人正好在三分钟后购买同一个产品相同的金额那我也没辙了,哈哈。
5. 零点整合数据
每天零点我们需要整理user.json和prod.json数据,生成最终的数据。代码:
let globalTimer = setInterval(function(){
let nowTime = +new Date();
let nowStr = (new Date()).format("hh:mm:ss");
let max = nowTime;
let min = nowTime - 24*60*60*1000;
// 每天00:00分的时候写入当天的数据
if(nowStr === "00:00:00"){
// 先保存数据
let prod = JSON.parse(fs.readFileSync('data/prod.json', 'utf-8'));
let user = JSON.parse(fs.readFileSync('data/user.json', 'utf-8'));
let lmlc = JSON.parse(JSON.stringify(prod));
// 清空缓存数据
clearProd = true;
clearUser = true;
// 不足一天的不统计
// if(nowTime - initialTime < 24*60*60*1000) return
// 筛选prod.records数据
for(let i=0, len=prod.length; i<len; i++){
let delArr1 = [];
for(let j=0, len2=prod[i].records.length; j<len2; j++){
if(prod[i].records[j].buyTime < min || prod[i].records[j].buyTime >= max){
delArr1.push(j);
}
}
sort.delArrByIndex(lmlc[i].records, delArr1);
}
// 删掉prod.records为空的数据
let delArr2 = [];
for(let i=0, len=lmlc.length; i<len; i++){
if(!lmlc[i].records.length){
delArr2.push(i);
}
}
sort.delArrByIndex(lmlc, delArr2);
// 初始化lmlc里的立马金库数据
lmlc.unshift({
"productName": "立马金库",
"financeTotalAmount": 100000000,
"productId": "jsfund",
"yearReturnRate": 4.0,
"investementDays": 1,
"interestStartTime": (new Date(min)).format("yyyy年MM月dd日"),
"interestEndTime": (new Date(max)).format("yyyy年MM月dd日"),
"getDataTime": min,
"alreadyBuyAmount": 0,
"records": []
});
// 筛选user数据
for(let i=0, len=user.length; i<len; i++){
if(user[i].productId === "jsfund" && user[i].buyTime >= min && user[i].buyTime < max){
lmlc[0].records.push({
"username": user[i].username,
"buyTime": user[i].buyTime,
"buyAmount": user[i].payAmount,
});
}
}
// 删除无用属性,按照时间排序
lmlc[0].records.sort(function(a,b){return a.buyTime - b.buyTime});
for(let i=1, len=lmlc.length; i<len; i++){
lmlc[i].records.sort(function(a,b){return a.buyTime - b.buyTime});
for(let j=0, len2=lmlc[i].records.length; j<len2; j++){
delete lmlc[i].records[j].uniqueId
}
}
// 爬取金库收益,写入前一天的数据,清空user.json和prod.json
let dateStr = (new Date(nowTime - 10*60*1000)).format("yyyyMMdd");
superagent
.get('https://www.lmlc.com/web/product/product_list?pageSize=10&pageNo=1&type=1')
.end(function(err,pres){
// 常规的错误处理
if (err) {
handleErr(err.message);
return;
}
var data = JSON.parse(pres.text).data;
var rate = data.result[0].yearReturnRate||4.0;
lmlc[0].yearReturnRate = rate;
fs.writeFileSync(`data/${dateStr}.json`, JSON.stringify(lmlc));
})
}
}, 1000);globalTimer是个全局定时器,每隔1s执行一次,当时间为00:00:00时,clearProd和clearUser全局参数为true,这样在下次爬取过程时会清空user.json和prod.json文件。没有同步清空是因为防止多处同时修改同一文件报错。取出user.json里的所有金库记录,获取当天金库相关信息,生成一条立马金库的prod信息并unshift进prod.json里。删除一些无用属性,排序数组最终生成带有当天时间戳的json文件,如:20180101.json。
五、前端展示
1、整体思路
前端总共就两个页面,首页和详情页,首页主要展示实时销售额、某一时间段内的销售情况、具体某天的销售情况。详情页展示某天的具体某一产品销售情况。页面有两个入口,而且比较简单,这里我们采用gulp来打包压缩构建前端工程。后台用express搭建的,匹配到路由,从data文件夹里取到数据再分析处理再返回给前端。
2、前端用到的组件介绍
Echarts
Echarts是一个绘图利器,百度公司不可多得的良心之作。能方便的绘制各种图形,官网已经更新到4.0了,功能更加强大。我们这里主要用到的是直方图。
DataTables
Datatables是一款jquery表格插件。它是一个高度灵活的工具,可以将任何HTML表格添加高级的交互功能。功能非常强大,有丰富的API,大家可以去官网学习。
Datepicker
Datepicker是一款基于jquery的日期选择器,需要的功能基本都有,主要样式比较好看,比jqueryUI官网的Datepicker好看太多。
3、gulp配置
gulp配置比较简单,代码如下:
var gulp = require('gulp');
var uglify = require("gulp-uglify");
var less = require("gulp-less");
var minifyCss = require("gulp-minify-css");
var livereload = require('gulp-livereload');
var connect = require('gulp-connect');
var minimist = require('minimist');
var babel = require('gulp-babel');
var knownOptions = {
string: 'env',
default: { env: process.env.NODE_ENV || 'production' }
};
var options = minimist(process.argv.slice(2), knownOptions);
// js文件压缩
gulp.task('minify-js', function() {
gulp.src('src/js/*.js')
.pipe(babel({
presets: ['es2015']
}))
.pipe(uglify())
.pipe(gulp.dest('dist/'));
});
// js移动文件
gulp.task('move-js', function() {
gulp.src('src/js/*.js')
.pipe(babel({
presets: ['es2015']
}))
.pipe(gulp.dest('dist/'))
.pipe(connect.reload());
});
// less编译
gulp.task('compile-less', function() {
gulp.src('src/css/*.less')
.pipe(less())
.pipe(gulp.dest('dist/'))
.pipe(connect.reload());
});
// less文件编译压缩
gulp.task('compile-minify-css', function() {
gulp.src('src/css/*.less')
.pipe(less())
.pipe(minifyCss())
.pipe(gulp.dest('dist/'));
});
// html页面自动刷新
gulp.task('html', function () {
gulp.src('views/*.html')
.pipe(connect.reload());
});
// 页面自动刷新启动
gulp.task('connect', function() {
connect.server({
livereload: true
});
});
// 监测文件的改动
gulp.task('watch', function() {
gulp.watch('src/css/*.less', ['compile-less']);
gulp.watch('src/js/*.js', ['move-js']);
gulp.watch('views/*.html', ['html']);
});
// 激活浏览器livereload友好提示
gulp.task('tip', function() {
console.log('\n<----- 请用chrome浏览器打开 http://localhost:5000 页面,并激活livereload插件 ----->\n');
});
if (options.env === 'development') {
gulp.task('default', ['move-js', 'compile-less', 'connect', 'watch', 'tip']);
}else{
gulp.task('default', ['minify-js', 'compile-minify-css']);
}开发和生产环境都是将文件打包到dist目录。不同的是:开发环境只是编译es6和less文件;生产环境会再压缩混淆。支持livereload插件,在开发环境下,文件改动会自动刷新页面。
相关推荐:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nodejs est-il un framework backend ?
Apr 21, 2024 am 05:09 AM
Nodejs est-il un framework backend ?
Apr 21, 2024 am 05:09 AM
Node.js peut être utilisé comme framework backend car il offre des fonctionnalités telles que des performances élevées, l'évolutivité, la prise en charge multiplateforme, un écosystème riche et une facilité de développement.
 Comment connecter Nodejs à la base de données MySQL
Apr 21, 2024 am 06:13 AM
Comment connecter Nodejs à la base de données MySQL
Apr 21, 2024 am 06:13 AM
Pour vous connecter à une base de données MySQL, vous devez suivre ces étapes : Installez le pilote mysql2. Utilisez mysql2.createConnection() pour créer un objet de connexion contenant l'adresse de l'hôte, le port, le nom d'utilisateur, le mot de passe et le nom de la base de données. Utilisez connection.query() pour effectuer des requêtes. Enfin, utilisez connection.end() pour mettre fin à la connexion.
 Quelles sont les variables globales dans nodejs
Apr 21, 2024 am 04:54 AM
Quelles sont les variables globales dans nodejs
Apr 21, 2024 am 04:54 AM
Les variables globales suivantes existent dans Node.js : Objet global : global Module principal : processus, console, nécessiter Variables d'environnement d'exécution : __dirname, __filename, __line, __column Constantes : undefined, null, NaN, Infinity, -Infinity
 Quelle est la différence entre les fichiers npm et npm.cmd dans le répertoire d'installation de nodejs ?
Apr 21, 2024 am 05:18 AM
Quelle est la différence entre les fichiers npm et npm.cmd dans le répertoire d'installation de nodejs ?
Apr 21, 2024 am 05:18 AM
Il existe deux fichiers liés à npm dans le répertoire d'installation de Node.js : npm et npm.cmd. Les différences sont les suivantes : différentes extensions : npm est un fichier exécutable et npm.cmd est un raccourci de fenêtre de commande. Utilisateurs Windows : npm.cmd peut être utilisé à partir de l'invite de commande, npm ne peut être exécuté qu'à partir de la ligne de commande. Compatibilité : npm.cmd est spécifique aux systèmes Windows, npm est disponible multiplateforme. Recommandations d'utilisation : les utilisateurs Windows utilisent npm.cmd, les autres systèmes d'exploitation utilisent npm.
 Y a-t-il une grande différence entre nodejs et java ?
Apr 21, 2024 am 06:12 AM
Y a-t-il une grande différence entre nodejs et java ?
Apr 21, 2024 am 06:12 AM
Les principales différences entre Node.js et Java résident dans la conception et les fonctionnalités : Piloté par les événements ou piloté par les threads : Node.js est piloté par les événements et Java est piloté par les threads. Monothread ou multithread : Node.js utilise une boucle d'événements monothread et Java utilise une architecture multithread. Environnement d'exécution : Node.js s'exécute sur le moteur JavaScript V8, tandis que Java s'exécute sur la JVM. Syntaxe : Node.js utilise la syntaxe JavaScript, tandis que Java utilise la syntaxe Java. Objectif : Node.js convient aux tâches gourmandes en E/S, tandis que Java convient aux applications de grande entreprise.
 Nodejs est-il un langage de développement back-end ?
Apr 21, 2024 am 05:09 AM
Nodejs est-il un langage de développement back-end ?
Apr 21, 2024 am 05:09 AM
Oui, Node.js est un langage de développement backend. Il est utilisé pour le développement back-end, notamment la gestion de la logique métier côté serveur, la gestion des connexions à la base de données et la fourniture d'API.
 Comment déployer le projet nodejs sur le serveur
Apr 21, 2024 am 04:40 AM
Comment déployer le projet nodejs sur le serveur
Apr 21, 2024 am 04:40 AM
Étapes de déploiement de serveur pour un projet Node.js : Préparez l'environnement de déploiement : obtenez l'accès au serveur, installez Node.js, configurez un référentiel Git. Créez l'application : utilisez npm run build pour générer du code et des dépendances déployables. Téléchargez le code sur le serveur : via Git ou File Transfer Protocol. Installer les dépendances : connectez-vous en SSH au serveur et installez les dépendances de l'application à l'aide de npm install. Démarrez l'application : utilisez une commande telle que node index.js pour démarrer l'application ou utilisez un gestionnaire de processus tel que pm2. Configurer un proxy inverse (facultatif) : utilisez un proxy inverse tel que Nginx ou Apache pour acheminer le trafic vers votre application
 Lequel choisir entre nodejs et java ?
Apr 21, 2024 am 04:40 AM
Lequel choisir entre nodejs et java ?
Apr 21, 2024 am 04:40 AM
Node.js et Java ont chacun leurs avantages et leurs inconvénients en matière de développement Web, et le choix dépend des exigences du projet. Node.js excelle dans les applications en temps réel, le développement rapide et l'architecture de microservices, tandis que Java excelle dans la prise en charge, les performances et la sécurité de niveau entreprise.
