

Aperçu détaillé des statistiques MySQL
Cet article fournit un aperçu complet des points de connaissance pertinents des informations statistiques MySQL à travers l'introduction du concept d'informations statistiques et des avantages des informations statistiques MYSQL. J'espère qu'il pourra aider les amis dans le besoin.
MySQL passera par le processus d'analyse SQL et d'optimisation des requêtes lors de l'exécution de SQL. L'analyseur décompose SQL en structures de données et les transmet aux étapes suivantes. L'optimiseur de requêtes trouve la meilleure solution pour exécuter les requêtes SQL. et génère un plan d'exécution. L'optimiseur de requêtes détermine comment SQL est exécuté, en s'appuyant sur les statistiques de la base de données. Ci-dessous, nous présentons le contenu pertinent des statistiques innodb dans MySQL 5.7.
Le stockage des statistiques MySQL est divisé en deux types, les statistiques non persistantes et persistantes.
1. Informations statistiques non persistantes
Les informations statistiques non persistantes sont stockées en mémoire Si la base de données est redémarrée, les informations statistiques seront perdues. Il existe deux manières de définir des statistiques non persistantes :
| ||||||||||||||
|
2 Paramètres de la table CREATE/ALTER, STATS_PERSISTENT=0 | ||||||||||||||
1 Exécuter ANALYZE TABLE | ||||||||||||||
2 Lorsque innodb_stats_on_metadata=ON, exécutez SHOW TABLE STATUS, SHOW INDEX, interrogez TABLES sous INFORMATION_SCHEMA, STATISTICS | ||||||||||||||
3 Lorsque la fonction --auto-rehash est activée, utilisez le client MySQL pour vous connecter
|
||||||||||||||
4 Table pour la première fois Ouvert | ||||||||||||||
| ||||||||||||||
innodb_index_stats | |
database_name |
数据库名 |
table_name |
表名 |
index_name |
索引名 |
last_update |
统计信息最后一次更新时间 |
stat_name |
统计信息名 |
stat_value |
统计信息的值 |
sample_size |
采样大小 |
stat_description |
类型说明 |
| 1 INNODB_STATS_AUTO_RECALC=ON, 10% des données du tableau sont modifiées |
| 2 Ajouter un nouvel index |
| innodb_table_stats | |
| database_name | Nom de la base de données |
| nom_table | Nom de la table |
| last_update | Heure de la dernière mise à jour des statistiques |
| n_rows | Le nombre de lignes dans le tableau |
| clustered_index_size | Le nombre de pages dans l'index clusterisé |
| sum_of_other_index_sizes | Autres pages d'index Nombre de |
| innodb_index_stats | |
| database_name | Nom de la base de données td> |
| nom_table | Nom de la table |
| index_name | Nom de l'index |
| last_update | Heure de la dernière mise à jour des statistiques |
| nom_stat | Nom des statistiques | tr>
| La valeur des informations statistiques | |
| sample_size | Taille d'échantillonnage |
| stat_description | Description du type td> |
Pour mieux comprendre innodb_index_stats, créez un tableau de test pour explication :
CREATE TABLE t1 ( a INT, b INT, c INT, d INT, e INT, f INT, PRIMARY KEY (a, b), KEY i1 (c, d), UNIQUE KEY i2uniq (e, f) ) ENGINE=INNODB;
Écrivez les données comme suit :
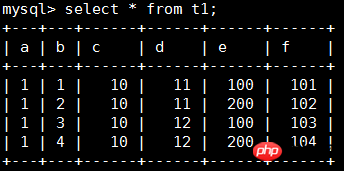
Pour afficher les informations statistiques de la table t1, vous devez vous concentrer sur les champs stat_name et stat_value
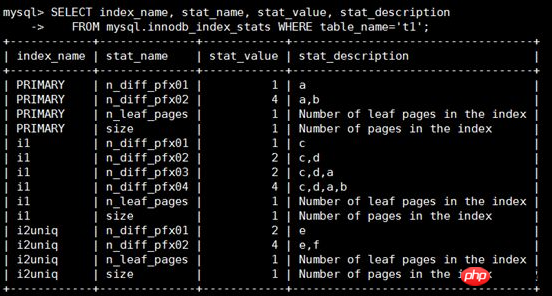
Quand tat_name=size: stat_value indique le nombre de pages indexées
Quand stat_name=n_leaf_pages : stat_value représente le nombre de nœuds feuilles
Quand stat_name=n_diff_pfxNN : stat_value représente le nombre de valeurs uniques sur le champ d'index Voici un. explication détaillée :
1. n_diff_pfx01 représente le nombre après le distinct de la première colonne de l'index. Par exemple, la colonne a de PRIMARY n'a qu'une seule valeur 1, donc lorsque index_name='PRIMARY' et stat_name=' n_diff_pfx01', stat_value=1.
2. n_diff_pfx02 représente le nombre après la distincte des deux premières colonnes de l'index. Par exemple, les colonnes e et f de i2uniq ont 4 valeurs, donc quand index_name='i2uniq' et stat_name='n_diff_pfx02. ', valeur_stat=4.
3. Pour les index non uniques, l'index de clé primaire sera ajouté après les colonnes d'origine, telles que index_name='i1' et stat_name='n_diff_pfx03', et la colonne de clé primaire a sera ajoutée après les colonnes d'index d'origine c et d, (le résultat distinct de c, d, a) est 2.
Comprendre la signification spécifique de stat_name et stat_value peut nous aider à déterminer pourquoi un index approprié n'est pas utilisé lors de l'exécution de SQL. Par exemple, la stat_value d'un certain index n_diff_pfxNN est beaucoup plus petite que la valeur réelle de l'optimiseur de requête. considère l’indice comme sélectif. S’il est mauvais, cela peut conduire à utiliser un mauvais indice.
3. Gestion des informations statistiques inexactes
Nous avons vérifié le plan d'exécution et constaté que l'index correct n'a pas été utilisé. Si cela est dû à une grande différence dans les informations statistiques dans innodb_index_stats, cela peut être le cas. être traité des manières suivantes :
1. Mettre à jour manuellement les informations statistiques. Notez que des verrous de lecture seront ajoutés lors de l'exécution :
ANALYZETABLE TABLE_NAME;
2. les informations sont toujours inexactes après la mise à jour, pensez à en ajouter d'autres. La page de données d'échantillonnage de table peut être modifiée de deux manières :
a) Variable globale INNODB_STATS_PERSISTENT_SAMPLE_PAGES, la valeur par défaut est 20
b) Une seule ; table peut spécifier l'échantillonnage de la table :
ALTER TABLE TABLE_NAME STATS_SAMPLE_PAGES=40;
Après le test, la valeur maximale de STATS_SAMPLE_PAGES est ici de 65535. Si elle dépasse, une erreur sera signalée.
Actuellement, MySQL ne fournit pas de fonction d'histogramme. Dans certains cas (comme une distribution inégale des données), la simple mise à jour des informations statistiques ne permet pas nécessairement d'obtenir un plan d'exécution précis. Les index ne peuvent être spécifiés que via des indices d'index. La nouvelle version 8.0 ajoutera une fonction d'histogramme, attendons avec impatience que MySQL devienne de plus en plus puissant !
Recommandations associées :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1205
24
52
1205
24

 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
