

Requête complexe d'instruction de requête MySQL
MySQL est un système de gestion de base de données relationnelle. Une base de données relationnelle stocke les données dans différentes tables au lieu de placer toutes les données dans un seul grand entrepôt, ce qui augmente la vitesse et la flexibilité. Il existe souvent de nombreuses requêtes complexes dans MySQL Afin de faire gagner du temps à chacun, l'éditeur a résumé quelques requêtes complexes couramment utilisées.
Requête complexe MySQL
1. Requête de groupe :
Mots clés : GROUPE PAR
2. L'instruction BY est utilisée pour combiner la fonction récapitulative (telle que SUM) pour regrouper l'ensemble de résultats selon une ou plusieurs colonnes. La fonction récapitulative doit souvent être ajoutée. Instruction GROUP BY.
Le tableau suivant présente deux tableaux, l'un est emp et l'autre est dept, nous allons opérer les requêtes suivantes sur ces deux tables, comme indiqué ci-dessous :
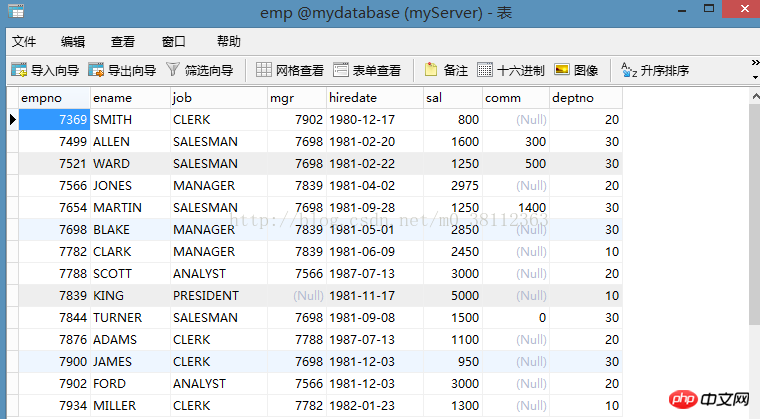
Première table : empTableau
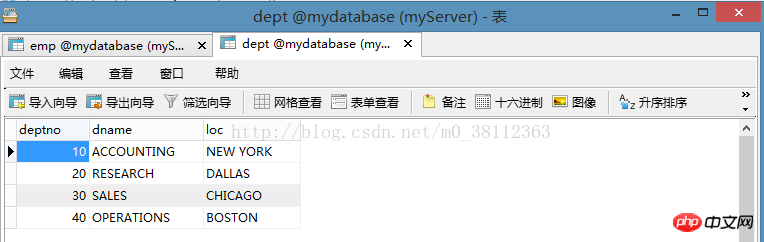
Le deuxième : départTable
Maintenant nous interrogeons le salaire total de chaque département dans emp, l'instruction est la suivante :
SELECT deptno,SUM(sal)FROM emp GROUP BY deptno;
Les résultats sont les suivants :
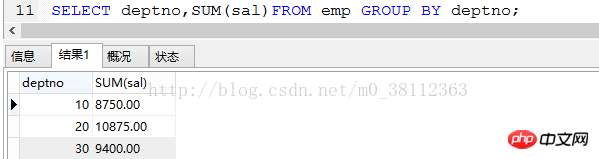
Remarque : Ici, nous recherchons le salaire total (sal) de chaque département, il doit donc être regroupé en fonction du numéro de département (deptno), donc sum() est utilisé pour la somme
3. ayant :
Où et avoir font tous deux des jugements conditionnels Avant d'introduire avoir, jetons un coup d'œil à la différence entre où et avoir
La fonction de Where est de supprimer les lignes qui ne remplissent pas la condition Where avant de regrouper les résultats de la requête, c'est-à-dire de filtrer les données avant de regrouper. La condition 🎜> ne peut pas contenir la fonction d'agrégation , utilisez donc la condition Where Afficher les lignes spécifiques. avoir est utilisé pour filtrer les groupes qui remplissent les conditions, c'est-à-dire filtrer les données après le regroupement les conditions incluent souvent des fonctions d'agrégation , utilisez avoir.
Les conditions affichent des groupes spécifiques ou vous pouvez regrouper à l'aide de plusieurs critères de regroupement. Par exemple : Nous souhaitons interroger les numéros de département dont le salaire total est supérieur à 10 000 dans la table emp. L'instruction est la suivante : <.>SÉLECTIONNER
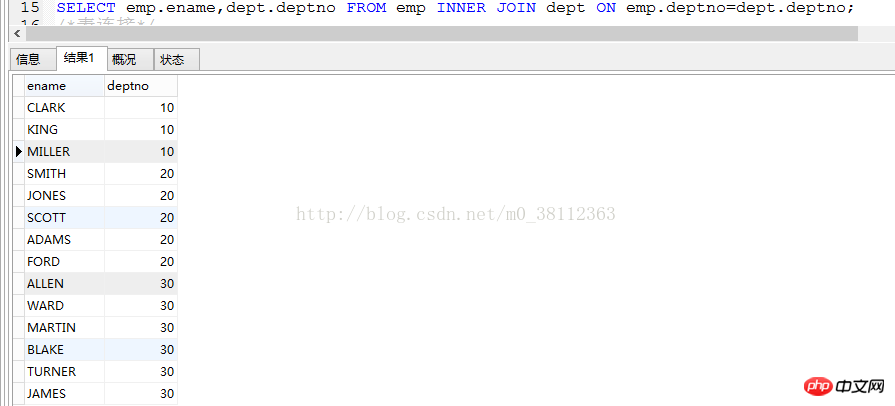
deptno,SUM(sal)FROM emp GROUP BY deptno HAVING SUM(sal)>10000; Les résultats sont les suivants : De cette façon, il on constate que le salaire total est supérieur à Le numéro de département de 10 000 est 20 (le salaire total est également affiché pour compréhension). 2. Requête de table de jointure : Selon deux La relation entre les colonnes d'une ou plusieurs tables, interrogez les données de ces tables 1. ): Syntaxe : sélectionnez le nom du champ 1, le nom du champ 2 de la table1 [INNER] join table2 ON table1.Field name=table2.Field name; Remarque : les jointures internes sont supprimées des résultats. Tous les lignes qui n'ont pas de lignes correspondantes dans d'autres tables connectées ne peuvent être interrogées que pour les informations appartenant aux tables connectées, de sorte que les jointures internes peuvent perdre des informations, et intérieur peut être omis. Par exemple : on connecte deux tables emp et dept, requête ename et deptno, l'instruction est la suivante : SELECT emp.ename,dept.deptno FROM emp INNER JOIN dept ON emp.deptno=dept.deptno; Aussi Une façon d'écrire : SELECT emp.ename,dept.deptno from emp,deptwhere emp.deptno=dept.deptno; Remarque : Il s'avère qu'il y a un numéro de service de 40 dans la table dept, mais il a disparu après la requête. C'est parce qu'il n'y a pas de valeur de 40 dans le champ deptno dans emp, Ainsi, la table dept est automatiquement supprimée lors de l'utilisation de la jointure interne. Enregistrements avec une valeur de champ deptno de 40. 2. Jointure externe : 2.1 : Jointure externe gauche : L'ensemble de résultats conserve toutes les lignes du tableau de gauche, mais uniquement les lignes du deuxième tableau qui correspondent au premier tableau. Les lignes vides correspondantes du deuxième tableau sont mises en valeurs NULL. 2.2 : Jointure externe droite : Le jeu de résultats conserve toutes les lignes de la table de droite, mais ne contient que les lignes de la deuxième table qui correspondent à la première table. Les lignes vides correspondantes du deuxième tableau sont mises en valeurs NULL. La jointure externe gauche et la jointure externe droite peuvent obtenir le même effet en échangeant les positions des deux tables. Maintenant, nous effectuons des requêtes qui utilisent le regroupement et la jointure de tables ensemble Par exemple : Nous voulons interroger le salaire total de chaque département de emp et correspondre au nom du département dans la table des départements Analysez cette phrase : Le champ de requête est sal (salaire total) de chaque département dans emp. Ici, nous devons utiliser une requête de groupe, mais nous devons également interroger le nom du département (dname) du département correspondant. dname est dans la table dept, nous devrions donc connecter les tables emp et dept. Idée 1 : Nous interrogeons d'abord tous les champs dont nous avons besoin avant de procéder au regroupement, alors connectez-vous d'abord puis groupez, l'instruction est la suivante : SELECT e.deptno,d.dname,SUM(e.sal) FROM emp e INNER JOIN dept d ON e.deptno= d.deptno GROUP BY d.deptno;) (Notez que est utilisé ici. L'alias de emp est e, et l'alias de dept est d) La deuxième façon d'écrire : SELECT e.deptno,d .dname,SUM(e.sal) FROM emp e ,dept d WHEREe.deptno=d.deptno GROUP BY d.deptno; Les résultats de ces deux méthodes d'écriture sont les mêmes, comme suit : Idée 2 : Nous souhaitons interroger le salaire total de chaque département de emp, traiter cet ensemble de résultats comme un tableau ( ici appelé table 1), puis laissez la table 1 se connecter à la table du département Rechercher le nom du département correspondant (dname) Étape 1 : SELECT deptno,SUM(sal) ; FROM emp GROUP BY deptno; Cette instruction interroge la table emp Le salaire total de chaque département dans , maintenant nous le connectons à la table dept : Étape 2 : SELECT xin.*,d .dname FROM(SELECT deptno,SUM(sal) FROM emp GROUP BY deptno) xin INNER JOIN dept d ON xin.deptno =d.deptno; De cette façon, vous pouvez interroger le résultat souhaité, notez que xin ici est un alias, le résultat est le suivant : Le code ici semble très long, mais en fait l'idée est très claire. Traitez simplement le premier résultat de la requête comme une table pour vous connecter à une autre table. Cette idée n'est pas facile de faire des erreurs. Vous deviendrez très compétent en écriture avec plus. pratique. 3. Pagination : Mots clés : LIMIT Syntaxe : select * from tableName limite de condition numéro de page actuel * capacité de la page - 1, Capacité de la page ; La limite générale est utilisée avec la commande par Par exemple, nous voulons interroger 5 à 10 dans la table emp dans ordre croissant par numéro de département. Enregistrements, chaque page affiche 5 enregistrements, l'énoncé est le suivant : SELECT *FROM emp ORDER BY deptno LIMIT 4,5; De cette façon, vous pouvez interroger les résultats souhaités. Notez que le dernier paramètre 5 est la capacité de la page, qui est le nombre de lignes à afficher sur cette page (c'est-à-dire, la barre d'enregistrement de la ligne du début à la ligne de fin de cette page Numéro). Par exemple, si l'on souhaite interroger 17 pages d'enregistrements, chaque page affiche 10 enregistrements : LIMITE 17*10-1,10; Quatre : IN Mot clé : In Si le résultat de la valeur de retour de la sous-requête est plus d'une condition, IN doit être utilisé et ne peut pas être utilisé"="; Remarque : LIMIT est placé à la fin . Recommandations associées : Comment résoudre le problème du fichier my.ini manquant dans MySQL5. 7 Un résumé des problèmes d'exécution entre MySQL Max et Where Un aperçu détaillé des statistiques MySQL


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Compétences de traitement de structures de données volumineuses de PHP
May 08, 2024 am 10:24 AM
Compétences de traitement de structures de données volumineuses de PHP
May 08, 2024 am 10:24 AM
Compétences en matière de traitement de la structure des Big Data : Chunking : décomposez l'ensemble de données et traitez-le en morceaux pour réduire la consommation de mémoire. Générateur : générez des éléments de données un par un sans charger l'intégralité de l'ensemble de données, adapté à des ensembles de données illimités. Streaming : lisez des fichiers ou interrogez les résultats ligne par ligne, adapté aux fichiers volumineux ou aux données distantes. Stockage externe : pour les ensembles de données très volumineux, stockez les données dans une base de données ou NoSQL.
 Comment optimiser les performances des requêtes MySQL en PHP ?
Jun 03, 2024 pm 08:11 PM
Comment optimiser les performances des requêtes MySQL en PHP ?
Jun 03, 2024 pm 08:11 PM
Les performances des requêtes MySQL peuvent être optimisées en créant des index qui réduisent le temps de recherche d'une complexité linéaire à une complexité logarithmique. Utilisez PreparedStatements pour empêcher l’injection SQL et améliorer les performances des requêtes. Limitez les résultats des requêtes et réduisez la quantité de données traitées par le serveur. Optimisez les requêtes de jointure, notamment en utilisant des types de jointure appropriés, en créant des index et en envisageant l'utilisation de sous-requêtes. Analyser les requêtes pour identifier les goulots d'étranglement ; utiliser la mise en cache pour réduire la charge de la base de données ; optimiser le code PHP afin de minimiser les frais généraux.
 Comment utiliser la sauvegarde et la restauration MySQL en PHP ?
Jun 03, 2024 pm 12:19 PM
Comment utiliser la sauvegarde et la restauration MySQL en PHP ?
Jun 03, 2024 pm 12:19 PM
La sauvegarde et la restauration d'une base de données MySQL en PHP peuvent être réalisées en suivant ces étapes : Sauvegarder la base de données : Utilisez la commande mysqldump pour vider la base de données dans un fichier SQL. Restaurer la base de données : utilisez la commande mysql pour restaurer la base de données à partir de fichiers SQL.
 Comment insérer des données dans une table MySQL en utilisant PHP ?
Jun 02, 2024 pm 02:26 PM
Comment insérer des données dans une table MySQL en utilisant PHP ?
Jun 02, 2024 pm 02:26 PM
Comment insérer des données dans une table MySQL ? Connectez-vous à la base de données : utilisez mysqli pour établir une connexion à la base de données. Préparez la requête SQL : Écrivez une instruction INSERT pour spécifier les colonnes et les valeurs à insérer. Exécuter la requête : utilisez la méthode query() pour exécuter la requête d'insertion en cas de succès, un message de confirmation sera généré.
 Comment corriger les erreurs mysql_native_password non chargé sur MySQL 8.4
Dec 09, 2024 am 11:42 AM
Comment corriger les erreurs mysql_native_password non chargé sur MySQL 8.4
Dec 09, 2024 am 11:42 AM
L'un des changements majeurs introduits dans MySQL 8.4 (la dernière version LTS en 2024) est que le plugin « MySQL Native Password » n'est plus activé par défaut. De plus, MySQL 9.0 supprime complètement ce plugin. Ce changement affecte PHP et d'autres applications
 Comment utiliser les procédures stockées MySQL en PHP ?
Jun 02, 2024 pm 02:13 PM
Comment utiliser les procédures stockées MySQL en PHP ?
Jun 02, 2024 pm 02:13 PM
Pour utiliser les procédures stockées MySQL en PHP : Utilisez PDO ou l'extension MySQLi pour vous connecter à une base de données MySQL. Préparez l'instruction pour appeler la procédure stockée. Exécutez la procédure stockée. Traitez le jeu de résultats (si la procédure stockée renvoie des résultats). Fermez la connexion à la base de données.
 Comment créer une table MySQL en utilisant PHP ?
Jun 04, 2024 pm 01:57 PM
Comment créer une table MySQL en utilisant PHP ?
Jun 04, 2024 pm 01:57 PM
La création d'une table MySQL à l'aide de PHP nécessite les étapes suivantes : Connectez-vous à la base de données. Créez la base de données si elle n'existe pas. Sélectionnez une base de données. Créer un tableau. Exécutez la requête. Fermez la connexion.
 La différence entre la base de données Oracle et MySQL
May 10, 2024 am 01:54 AM
La différence entre la base de données Oracle et MySQL
May 10, 2024 am 01:54 AM
La base de données Oracle et MySQL sont toutes deux des bases de données basées sur le modèle relationnel, mais Oracle est supérieur en termes de compatibilité, d'évolutivité, de types de données et de sécurité ; tandis que MySQL se concentre sur la vitesse et la flexibilité et est plus adapté aux ensembles de données de petite et moyenne taille. ① Oracle propose une large gamme de types de données, ② fournit des fonctionnalités de sécurité avancées, ③ convient aux applications de niveau entreprise ; ① MySQL prend en charge les types de données NoSQL, ② a moins de mesures de sécurité et ③ convient aux applications de petite et moyenne taille.
