

1. Introduction
Lorsque nous utilisons des programmes d'exploration pour explorer des pages Web, l'exploration de pages statiques est généralement relativement simple, et nous avons déjà écrit de nombreux cas. Mais comment explorer des pages chargées dynamiquement à l’aide de js ?
Il existe plusieurs méthodes d'exploration des pages js dynamiques :
Réalisé via Selenium+phantomjs.
phantomjs est un navigateur sans tête, Selenium est un cadre de test automatisé, demandez la page via le navigateur sans tête, attendez que js se charge, puis obtenez les données via des tests automatisés sélénium. Parce que les navigateurs sans tête consomment beaucoup de ressources, ils manquent de performances.
Framework Scrapy-splash :
Splash, en tant que service de rendu js, est développé léger basé sur Twisted et Moteur de navigateur QT et fournit une API http directe. Les fonctionnalités rapides et légères facilitent le développement distribué.
Les frameworks Splash et Scrapy Crawler sont intégrés. Les deux sont compatibles entre eux et ont une meilleure efficacité d'exploration.
Le service Splash est basé sur le conteneur Docker, nous devons donc d'abord installer le conteneur Docker.
2.1 Installation de Docker (version Windows 10 Home)
S'il s'agit de la version Win 10 Professional ou d'autres systèmes d'exploitation, il est plus facile à installer. Pour installer Docker dans la version Windows 10 Home, vous avez besoin. pour utiliser la boîte à outils (nécessite la dernière version) des outils à installer.
Concernant l'installation de docker, référez-vous à la documentation : Installation de Docker sur WIN10
2.2 Installation de Splash
docker pull scrapinghub/splash
2.3 Démarrage du service Splash
docker run -p 8050:8050 scrapinghub/splash
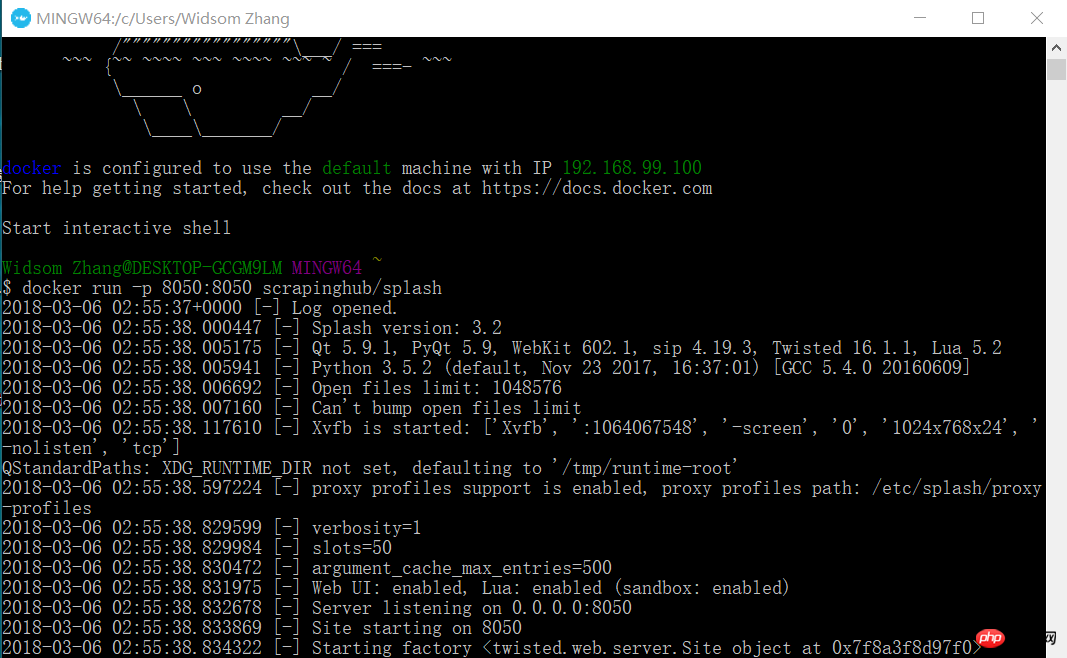
À ce moment, ouvrez votre navigateur et entrez 192.168.99.100:8050. Vous verrez une interface comme celle-ci.
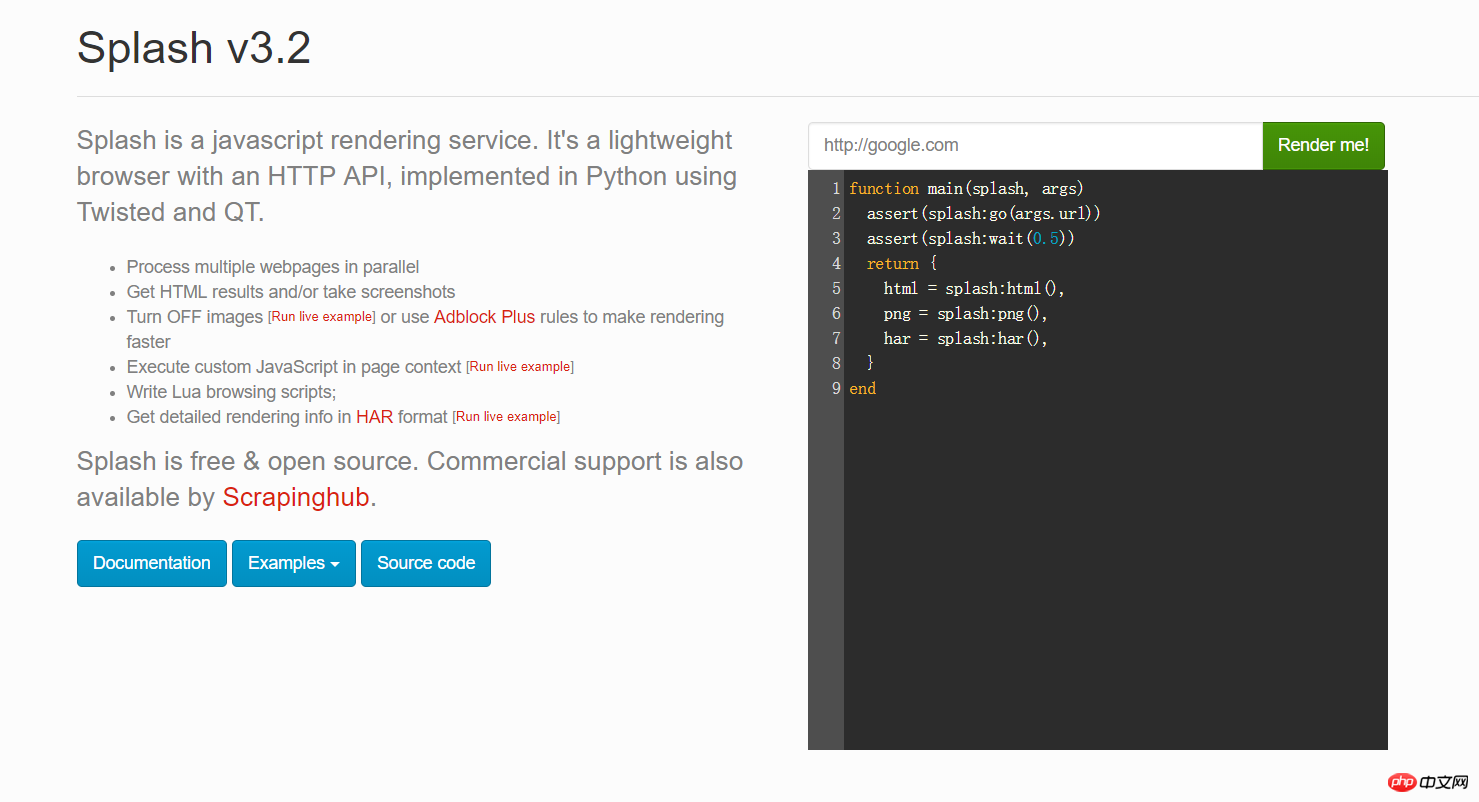
Vous pouvez saisir n'importe quelle URL dans la case rouge de l'Les frameworks Scrapy et Scrapy-splash chargent rapidement les pages js ci-dessus et cliquer sur Rendu moi pour voir à quoi elle ressemblera après le rendu
2.4 Installer python Le package scrapy-splash
pip install scrapy-splash
En raison des besoins professionnels, nous explorons certains sites Web d'actualités étrangers, tels que Google Actualités. Mais j'ai découvert qu'il s'agissait en fait de code js. J'ai donc commencé à utiliser le framework scrapy-splash et à coopérer avec le service de rendu js de Splash pour obtenir des données. Plus précisément, regardez le code suivant :
3.1 informations de configuration settings.py
# 渲染服务的urlSPLASH_URL = 'http://192.168.99.100:8050'# 去重过滤器DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'# 使用Splash的Http缓存HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'SPIDER_MIDDLEWARES = { 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}#下载器中间件DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}# 请求头DEFAULT_REQUEST_HEADERS = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
}# 管道ITEM_PIPELINES = { 'news.pipelines.NewsPipeline': 300,
}3.2 définition du champ des éléments
class NewsItem(scrapy.Item): # 标题
title = scrapy.Field() # 图片的url链接
Les frameworks Scrapy et Scrapy-splash chargent rapidement les pages js_url = scrapy.Field() # 新闻来源
source = scrapy.Field() # 点击的url
action_url = scrapy.Field()3.3 Code Spider
dans le répertoire spider, créez un fichier new_spider.py avec le contenu suivant :
from scrapy import Spiderfrom scrapy_splash import SplashRequestfrom news.items import NewsItemclass GoolgeNewsSpider(Spider):
name = "google_news"
start_urls = ["https://news.google.com/news/headlines?ned=cn&gl=CN&hl=zh-CN"] def start_requests(self):
for url in self.start_urls: # 通过SplashRequest请求等待1秒
yield SplashRequest(url, self.parse, args={'wait': 1}) def parse(self, response):
for element in response.xpath('//p[@class="qx0yFc"]'):
actionUrl = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/@href').extract_first()
title = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/text()').extract_first()
source = element.xpath('.//span[@class="IH8C7b Pc0Wt"]/text()').extract_first()
Les frameworks Scrapy et Scrapy-splash chargent rapidement les pages jsUrl = element.xpath('.//img[@class="lmFAjc"]/@src').extract_first()
item = NewsItem()
item['title'] = title
item['Les frameworks Scrapy et Scrapy-splash chargent rapidement les pages js_url'] = Les frameworks Scrapy et Scrapy-splash chargent rapidement les pages jsUrl
item['action_url'] = actionUrl
item['source'] = source yield item3.4 code pipelines.py
Stockez les données de l'élément dans la base de données mysql.
Créer une base de données db_news
CREATE DATABASE db_news
Créer une table tb_news
CREATE TABLE tb_google_news(
id INT AUTO_INCREMENT,
title VARCHAR(50),
Les frameworks Scrapy et Scrapy-splash chargent rapidement les pages js_url VARCHAR(200),
action_url VARCHAR(200),
source VARCHAR(30), PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8;Classe NewsPipeline
class NewsPipeline(object):
def __init__(self):
self.conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='root', db='db_news',charset='utf8')
self.cursor = self.conn.cursor() def process_item(self, item, spider):
sql = '''insert into tb_google_news (title,Les frameworks Scrapy et Scrapy-splash chargent rapidement les pages js_url,action_url,source) values(%s,%s,%s,%s)'''
self.cursor.execute(sql, (item["title"], item["Les frameworks Scrapy et Scrapy-splash chargent rapidement les pages js_url"], item["action_url"], item["source"]))
self.conn.commit() return item def close_spider(self):
self.cursor.close()
self.conn.close()3.5 Exécuter Scrapy Crawler
Exécuté sur la console :
scrapy crawl google_news
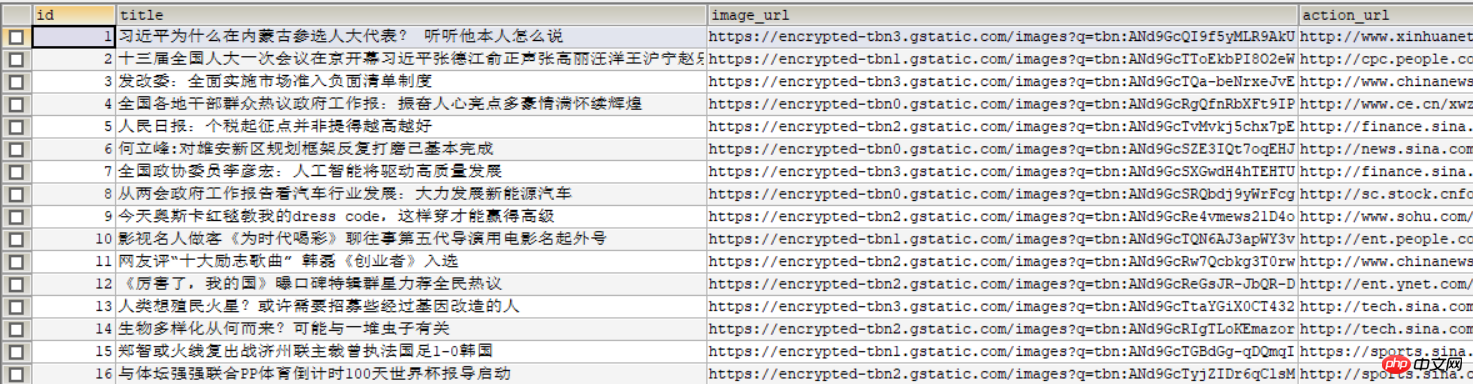
L'Les frameworks Scrapy et Scrapy-splash chargent rapidement les pages js suivante est affichée dans la base de données :
Recommandations associées :
Introduction de base aux commandes Scrapy
Tutoriel d'installation de Scrapy
Introduction au framework Scrapy Crawler
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



