
 développement back-end
tutoriel php
Explication détaillée de l'exemple de processus d'exécution pcntl_fork
développement back-end
tutoriel php
Explication détaillée de l'exemple de processus d'exécution pcntl_fork
Explication détaillée de l'exemple de processus d'exécution pcntl_fork

Cet article partage principalement avec vous un exemple du processus d'exécution pcntl_fork. Le concept de processus est un processus, qui contient principalement trois éléments :
1. Un programme exécutable
2. Toutes les données associées au processus (y compris les variables, l'espace mémoire, les tampons, etc.) ;
3. Le contexte d'exécution du programme ;
peut être considéré comme
On peut simplement comprendre qu'un processus représente un processus d'exécution d'un programme exécutable. un état dans. La gestion des processus par le système d'exploitation s'effectue généralement via la table de processus. Chaque entrée de la table de processus enregistre l'état d'un processus dans le système d'exploitation actuel.
Dans le cas d'un seul processeur, un seul processus occupe le processeur à un moment précis, mais il peut y avoir plusieurs processus actifs (en attente d'exécution ou d'exécution continue) dans le système en même temps. Un registre appelé compteur de programme (pc) indique l'emplacement de la prochaine instruction à exécuter par le processus occupant actuellement le CPU. Lorsque le temps CPU alloué à un processus est épuisé, le système d'exploitation enregistre la valeur du registre lié au processus dans l'entrée correspondante du processus dans la table des processus du contexte du processus qui prendra le relais du CPU ; ce processus est lu à partir de la table de processus et met à jour le registre correspondant (ce processus est appelé "
Changement de contexte (changement de contexte de processus)". Le changement de contexte réel doit impliquer plus de données, ce qui n'a rien à voir avec fork. Pas plus de détails. La principale chose à retenir est que le registre du programme indique où le programme a été exécuté. C'est une partie importante du contexte du processus. Le processus qui est extrait du CPU doit enregistrer la valeur de celui-ci. (Le processus qui est transféré dans la CPU doit également être basé sur la table de processus. Mettez à jour ce registre avec les informations de contexte d'exécution de ce processus qui y sont enregistrées).
Après le fork, le système d'exploitation copiera un processus enfant qui est exactement le même que le processus parent, bien qu'il s'agisse d'une relation père-fils, du point de vue. du système d'exploitation, ils ressemblent plus à des relations frères, ces deux processus partagent l'espace de code, mais l'espace de données est indépendant l'un de l'autre. Le contenu de l'espace de données du processus enfant est une copie complète du processus parent, et le contenu de l'espace de données du processus enfant est une copie complète du processus parent. Le pointeur d'instruction est exactement le même, mais il n'y a qu'une seule différence. Si le fork réussit, le contenu de l'espace de données du processus enfant est une copie complète du processus parent. La valeur de retour de fork est 0. La valeur de retour de fork. dans le processus parent se trouve le numéro de processus du processus enfant. Si fork échoue, le processus parent renverra une erreur. On peut imaginer que les deux processus se sont exécutés en même temps et au même rythme. Après le fork, ils effectuent respectivement des tâches différentes, c'est-à-dire qu'ils bifurquent. C'est pourquoi le fork est appelé fork. Quant au processus qui s'exécute en premier, cela est lié à l'algorithme de planification de la plate-forme du système d'exploitation, et ce problème n'est pas important dans les applications pratiques. Si les processus parent et enfant doivent travailler ensemble, il peut être résolu en contrôlant la structure syntaxique.
2
Le processus enfant peut hériter des éléments du processus parent avant fork, mais après pcntl_fork(), le processus enfant et le le processus parent n'a rien de relation d'héritage. Les éléments créés dans le processus enfant appartiennent au processus enfant, et les éléments créés dans le processus parent appartiennent au processus parent. Ils peuvent être complètement considérés comme deux processus indépendants.
3
Après avoir utilisé pcntl_fork() dans le segment du programme, le programme a bifurqué et deux processus ont été dérivés. Lequel est spécifique ? La première chose à exécuter dépend de l’algorithme de planification du système.Ici, nous pouvons penser que lors de l'exécution de "pid=pcntl_fork();", le système génère un sous-processus qui est exactement le même que le programme principal. Le pid obtenu dans la phrase "pid=pcntl_fork();" du processus est le pid du processus enfant lui-même ; une fois le processus enfant terminé, le pid obtenu dans la phrase "pid=pcntl_fork();" est le pid du processus parent lui-même. Le programme a donc deux lignes de sortie.
4
La fonction pcntl_fork() copie le PCB du processus actuel et renvoie le pid du processus enfant dérivé au processus parent . Les processus parent et enfant En parallèle, l'ordre d'impression des instructions dépend entièrement de l'algorithme de planification du système, et le contenu de l'impression est contrôlé par la variable pid. Parce que nous savons que pcntl_fork() renvoie le pid du processus enfant dérivé au processus parent, qui est un entier positif ; alors que la variable pid du processus enfant dérivé n'a pas été modifiée, cette différence nous permet de voir leurs différentes sorties.
5
Exemple
- Le processus qui dérive le processus enfant, c'est-à-dire le processus parent, a le même pid ;
- Pour le processus enfant, la fonction fork() lui renvoie 0, mais son propre pid ne sera jamais 0, la raison pour laquelle la fonction fork() lui renvoie 0 ; car il peut être utilisé à tout moment Appelez getpid() pour obtenir votre propre pid
- Après fork, à moins que la synchronisation ne soit utilisée entre les processus parent et enfant, il est impossible de déterminer qui est court en premier ou qui termine en premier. Il est faux de penser que le processus parent revient de fork seulement après la fin du processus enfant. Ce n'est pas le cas de fork, mais de vfork.
<?php$lock = new swoole_lock(SWOOLE_MUTEX);echo "[主进程]create lock\n";$lock->lock();$res = pcntl_fork();if ($res>0)
{ echo "1\n"; $lock->unlock();
sleep(1); echo "222";
}
else{ echo "[子进程] Wait Lock\n"; $lock->lock(); echo "[子进程] Get Lock\n"; $lock->unlock(); exit("[子进程] exit\n");
}echo "[主进程]release lock\n";unset($lock);echo "[主进程]exit\n";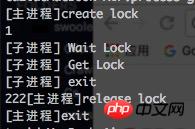
Weibo Qzone WeChat pcntl_fork implémente PHP multi-processus,
Introduction détaillée à pcntl_fork dans php multi-processus
php Utilisation de pcntl_fork et pcntl_fork
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Exemples SVM en Python
Jun 11, 2023 pm 08:42 PM
Exemples SVM en Python
Jun 11, 2023 pm 08:42 PM
Support Vector Machine (SVM) en Python est un puissant algorithme d'apprentissage supervisé qui peut être utilisé pour résoudre des problèmes de classification et de régression. SVM fonctionne bien lorsqu'il s'agit de données de grande dimension et de problèmes non linéaires, et est largement utilisé dans l'exploration de données, la classification d'images, la classification de textes, la bioinformatique et d'autres domaines. Dans cet article, nous présenterons un exemple d'utilisation de SVM pour la classification en Python. Nous utiliserons le modèle SVM de la bibliothèque scikit-learn
 Exemple de démarrage de VUE3 : création d'un lecteur vidéo simple
Jun 15, 2023 pm 09:42 PM
Exemple de démarrage de VUE3 : création d'un lecteur vidéo simple
Jun 15, 2023 pm 09:42 PM
Alors que la nouvelle génération de frameworks front-end continue d'émerger, VUE3 est apprécié comme un framework front-end rapide, flexible et facile à utiliser. Ensuite, apprenons les bases de VUE3 et créons un simple lecteur vidéo. 1. Installez VUE3 Tout d'abord, nous devons installer VUE3 localement. Ouvrez l'outil de ligne de commande et exécutez la commande suivante : npminstallvue@next. Ensuite, créez un nouveau fichier HTML et introduisez VUE3 : <!doctypehtml>
 Découvrez des exemples de bonnes pratiques de conversion de pointeur dans Golang
Feb 24, 2024 pm 03:51 PM
Découvrez des exemples de bonnes pratiques de conversion de pointeur dans Golang
Feb 24, 2024 pm 03:51 PM
Golang est un langage de programmation puissant et efficace qui peut être utilisé pour développer diverses applications et services. Dans Golang, les pointeurs sont un concept très important, qui peut nous aider à exploiter les données de manière plus flexible et plus efficace. La conversion de pointeur fait référence au processus d'opérations de pointeur entre différents types. Cet article utilisera des exemples spécifiques pour découvrir les meilleures pratiques de conversion de pointeur dans Golang. 1. Concepts de base Dans Golang, chaque variable a une adresse, et l'adresse est l'emplacement de la variable en mémoire.
 Exemple d'algorithme VAE en Python
Jun 11, 2023 pm 07:58 PM
Exemple d'algorithme VAE en Python
Jun 11, 2023 pm 07:58 PM
VAE est un modèle génératif, son nom complet est VariationalAutoencoder, qui se traduit en chinois par auto-encodeur variationnel. Il s'agit d'un algorithme d'apprentissage non supervisé qui peut être utilisé pour générer de nouvelles données, telles que des images, de l'audio, du texte, etc. Comparés aux auto-encodeurs ordinaires, les VAE sont plus flexibles et plus puissants et peuvent générer des données plus complexes et plus réalistes. Python est l'un des langages de programmation les plus utilisés et l'un des principaux outils d'apprentissage en profondeur. En Python, il existe de nombreux excellents outils d'apprentissage automatique et profonds.
 La relation entre le nombre d'instances Oracle et les performances de la base de données
Mar 08, 2024 am 09:27 AM
La relation entre le nombre d'instances Oracle et les performances de la base de données
Mar 08, 2024 am 09:27 AM
La relation entre le nombre d'instances Oracle et les performances de la base de données La base de données Oracle est l'un des systèmes de gestion de bases de données relationnelles les plus connus du secteur et est largement utilisée dans le stockage et la gestion de données au niveau de l'entreprise. Dans la base de données Oracle, l'instance est un concept très important. L'instance fait référence à l'environnement d'exécution de la base de données Oracle en mémoire. Chaque instance possède une structure de mémoire et un processus d'arrière-plan indépendants, qui sont utilisés pour traiter les demandes des utilisateurs et gérer les opérations de la base de données. Le nombre d'instances a un impact important sur les performances et la stabilité de la base de données Oracle.
 Exemple de développement d'un robot d'exploration Web simple PHP
Jun 13, 2023 pm 06:54 PM
Exemple de développement d'un robot d'exploration Web simple PHP
Jun 13, 2023 pm 06:54 PM
Avec le développement rapide d’Internet, les données sont devenues l’une des ressources les plus importantes à l’ère de l’information d’aujourd’hui. En tant que technologie qui obtient et traite automatiquement les données du réseau, les robots d'exploration Web attirent de plus en plus d'attention et d'applications. Cet article explique comment utiliser PHP pour développer un robot d'exploration Web simple et réaliser la fonction d'obtention automatique de données réseau. 1. Présentation de Web Crawler Le robot d'exploration Web est une technologie qui obtient et traite automatiquement les ressources réseau. Son principal processus de travail consiste à simuler le comportement du navigateur, à accéder automatiquement aux adresses URL spécifiées et à extraire toutes les informations.
 Erreurs courantes et solutions en cas d'échec du fork dans PHP PCNTL
Feb 28, 2024 am 11:06 AM
Erreurs courantes et solutions en cas d'échec du fork dans PHP PCNTL
Feb 28, 2024 am 11:06 AM
Erreurs courantes et solutions en cas d'échec de fork dans PHPPCNTL Lorsque vous utilisez l'extension PHPPCNTL pour la gestion des processus, vous rencontrez souvent le problème de l'échec de fork. Fork est une méthode de création d'un processus enfant. Dans certains cas, l'opération fork peut échouer en raison de certaines erreurs. Cet article présentera quelques erreurs courantes de défaillance de fork et les solutions correspondantes, et fournira des exemples de code spécifiques pour aider les lecteurs à mieux comprendre et gérer ces problèmes. 1. Message d'erreur possible en cas de mémoire insuffisante : Can
 Exemples d'utilisation du code de vérification dans le framework Gin
Jun 23, 2023 am 08:10 AM
Exemples d'utilisation du code de vérification dans le framework Gin
Jun 23, 2023 am 08:10 AM
Avec la popularité d'Internet, les codes de vérification sont devenus un processus nécessaire pour la connexion, l'enregistrement, la récupération du mot de passe et d'autres opérations. Dans le framework Gin, implémenter la fonction de code de vérification est devenu extrêmement simple. Cet article expliquera comment utiliser une bibliothèque tierce pour implémenter la fonction de code de vérification dans le framework Gin et fournira un exemple de code pour référence aux lecteurs. 1. Installer les bibliothèques dépendantes Avant d'utiliser le code de vérification, nous devons installer une bibliothèque tierce goCaptcha. Pour installer goCaptcha, vous pouvez utiliser la commande goget : $goget-ugithub
