

Explication détaillée de 5 structures de données Redis

Dans cet article, nous partageons principalement avec vous des explications détaillées sur 5 structures de données Redis. Nous espérons que les cas et les codes de l'article pourront aider tout le monde.
2.1.1 Commande globale
1 Afficher toutes les clés clé*
2 Nombre total de clés dbsize (la commande dbsize ne calculera pas le nombre total de clés) Parcourez toutes les clés, mais obtenez directement le nombre total de clés intégrées dans Redis. La complexité temporelle est O(1), tandis que la commande key parcourra toutes les clés et la complexité temporelle est O(n). un grand nombre de clés, la ligne Il est interdit d'utiliser dans l'environnement ci-dessus)
3 Vérifier si la clé existe existe la clé renvoie 1 si elle existe, et 0 si elle n'existe pas
4 Supprimer la clé del key Renvoie le nombre de clés supprimées avec succès, si elle n'existe pas, renvoie 0
5 L'expiration de la clé expire la clé secondes La commande ttl renverra le temps d'expiration restant -1 La clé n'a pas de délai d'expiration défini -2 La clé n'existe pas
6 Type de structure de type de données de clé Type de retour de clé, n'existe pas et n'en renvoie aucun
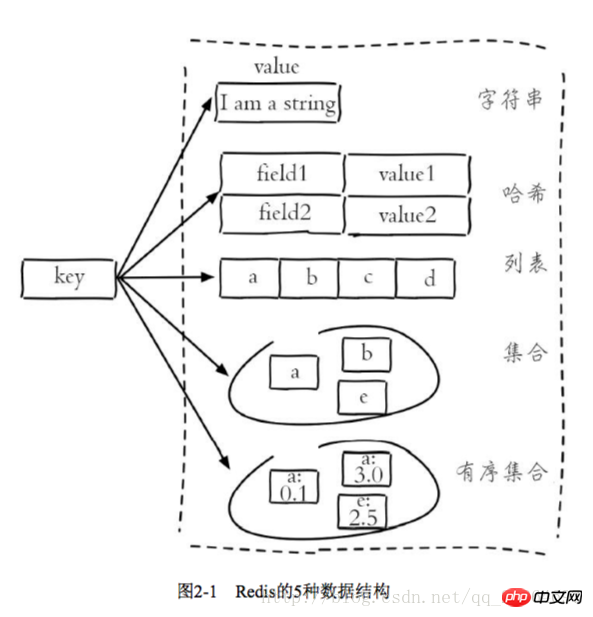
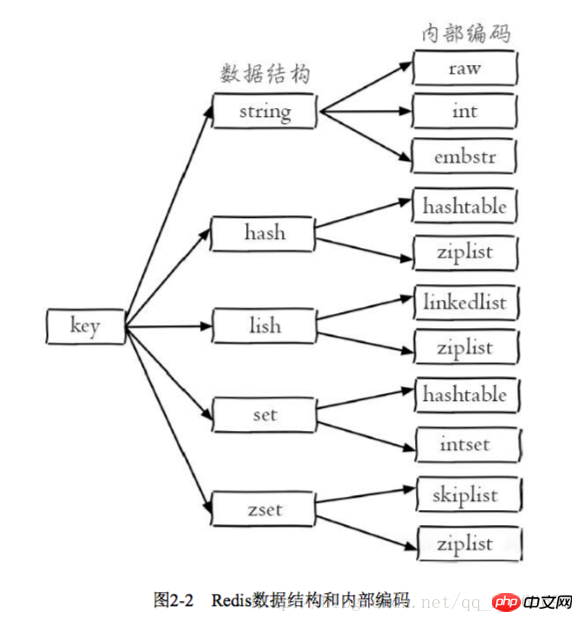
2.1.2 Structure des données et encodage interne
Chaque structure de données a sa propre implémentation d'encodage interne sous-jacente, et il s'agit de plusieurs implémentations, de sorte que Redis choisira l'encodage interne approprié dans le scénario approprié
Chaque structure de données a plus de deux implémentations d'encodage interne.Par exemple, la structure de données de liste comprend l'encodage interne de linkedlist et ziplist, vous pouvez interroger l'encodage interne via la commande d'encodage d'objet
La conception de Redis a. deux avantages : premièrement, il peut améliorer le codage interne sans affecter les structures de données et les commandes externes. Deuxièmement, plusieurs implémentations de codage interne peuvent exercer leurs avantages respectifs dans différents scénarios. Par exemple, ziplist économise de la mémoire, mais lorsqu'il y a de nombreux éléments de liste, les performances diminuent. À ce stade, Redis convertira l'implémentation interne du type de liste en liste liée
 en fonction des options de configuration 2.1. .3 Architecture à thread unique
en fonction des options de configuration 2.1. .3 Architecture à thread unique
Redis utilise une architecture à thread unique et des modèles de réutilisation multi-routes d'E/S pour obtenir des services de base de données de mémoire hautes performances
2 Pourquoi un seul thread peut-il s'exécuter si vite
Premièrement, accès à la mémoire pur, Redis met toutes les données en mémoire, et la réponse de la mémoire Le temps est d'environ 100 nanosecondes, ce qui est une base importante pour que Redis puisse atteindre 10 000 niveaux d'accès par seconde
Trois threads uniques évitent la consommation de commutation de thread et les conditions de course
Un seul thread apporte plusieurs avantages : Premièrement, un seul thread simplifie la mise en œuvre des structures de données et des algorithmes. Deuxièmement, le filetage unique évite la consommation causée par le changement de thread et les conditions de concurrence. Cependant, il existe des exigences pour l'exécution de chaque commande. Si le temps d'exécution d'une certaine commande est trop long, d'autres commandes seront bloquées. Redis est une base de données pour les scénarios d'exécution rapides. Un seul thread est au cœur de la compréhension de Redis. 🎜> 2.2 String
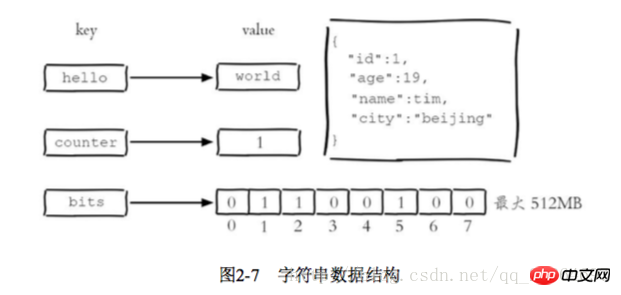
Le type chaîne de Redis est la base de plusieurs autres types. La valeur peut être une chaîne (json simple ou complexe, xml), un nombre (entier, virgule flottante). , Binaire (images, audio, vidéo), la valeur maximale ne peut pas dépasser 512 Mo > 1 Commandes communes
1 Définissez la valeur de la valeur de la clé deuxième délai d'expiration en millisecondes > Scénarios d'application : Puisque Redis est un. mécanisme de traitement de commande à thread unique, si plusieurs clients exécutent la valeur de clé setnx en même temps, selon les caractéristiques, un seul client peut la définir avec succès, ce qui peut être utilisé comme solution d'implémentation pour les verrous distribués
2 Récupérez la valeur get key si elle n'existe pas et retournez nil
 3 Définissez la valeur mset key value par lots
3 Définissez la valeur mset key value par lots
4 Récupérez la valeur mget key in lots 🎜>
Touche d'augmentation à 5 comptes
Il existe trois situations pour le résultat renvoyé
La valeur est un entier et le résultat après auto-incrémentation est renvoyé
Les clés n'existent pas, selon la valeur de 0, le résultat renvoyé est 1
et le derBy (numéro spécifié auto-croissant), derby Soustraire le nombre spécifié), incrbyfloat (incrémenter le nombre à virgule flottante)
2 Commandes peu courantes
1 Ajouter la valeur de la clé 2 Clé strlen de longueur de chaîne
3 Définir et renvoyer la valeur d'origine getset key value
4 Définir le caractère à la position spécifiée setrange key offset value
5 Récupérer une partie de la chaîne GetRANGE Key Début Fin
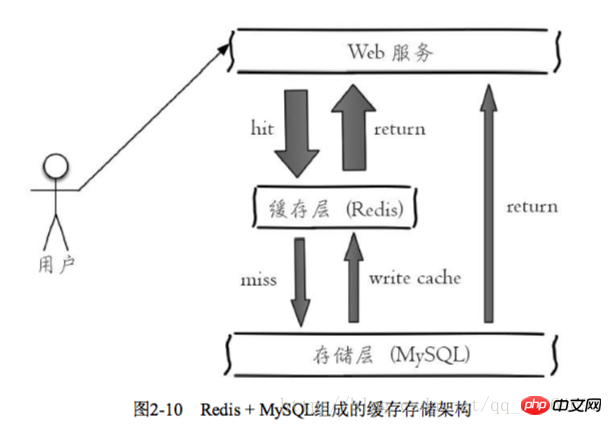
. Étant donné que Redis a la fonctionnalité de prendre en charge la simultanéité, la mise en cache peut généralement jouer un rôle dans l'accélération de la lecture et de l'écriture et dans la réduction de la pression back-end
: Méthode de dénomination du nom de clé : Nom de l'entreprise : Nom de l'objet : id : [ Attribut] comme nom de clé
Implémentation du pseudo-code :
2 comptages
Conseils de développement : Anti-triche, comptage selon différentes dimensions, la source de données des données est durable
UserInfo getUserInfo(long id){
userRedisKey="user:info:"+id
value=redis.get(userRedisKey);
UserInfo userInfo;
if(value!=null){
userInfo=deserialize(value)
}else{
userInfo=mysql.get(id)
if(userInfo!=null)
redis.setex(userRedisKey,3600,serizelize(userInfo))
}return userInfo
}
>
long incrVideoCounter(long id){
key="video:playCount:"+id;
return redis.incr(key)
}
4 Limite de vitesse
 2.3.1 Commande
2.3.1 Commande
1 Valeur définie
phoneNum="13800000000";
key="shortMsg:limit:"+phoneNum;
isExists=redis.set(key,1,"EX 60",NX);
if(isExists !=null ||redis.incr(key)<=5){
通过
}else{
限速
}
5 Définir ou obtenir la valeur du champ par lots Champ de clé hmget Valeur du champ de clé hmset
6 Déterminer si le champ existe Champ de clé hexists
Conseils de développement : si vous êtes sûr pour obtenir toutes les valeurs des champs. Vous pouvez utiliser la commande hscan. Cette commande parcourra progressivement le type de hachage
10 hincrby hincrby float
2.3.2 Encodage interne
Il existe deux types d'encodage interne :
ziplist (liste compressée) nombre d'éléments de hachage < ;hash- max-ziplist-entries, toutes les valeurs
Scène
UserInfo getUserInfo(long id){
userRedisKey="user:info:"+id;
userInfoMap=redis.hgetAll(userRedisKey);
userInfoMap userInfo;
if(userInfoMap!=null){
userInfo=transferMapToUserInfo(userInfoMap);
}else{
userInfo=mysql.get(id);
redis.hmset(userRedisKey,tranferUserInfoToMap(userInfo));
redis.expire(userRedisKey,3600);
}
return userInfo;
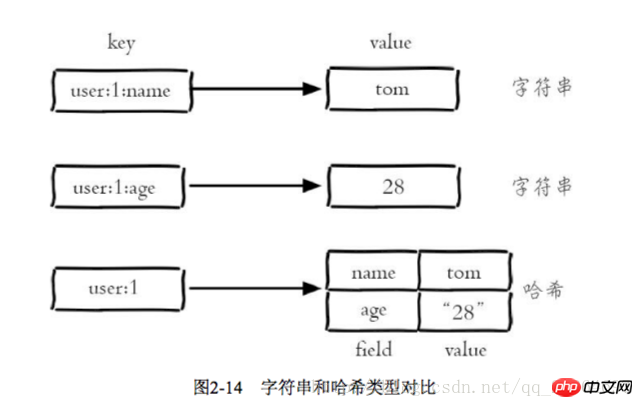
}哈希类型和关系型数据库两点不同:
1 哈希类型是稀疏的,而关系型数据库是完全结构化的
2 关系型数据库可以做复杂的查询,而Redis去模拟关系型复杂查询开发困难,维护成本高
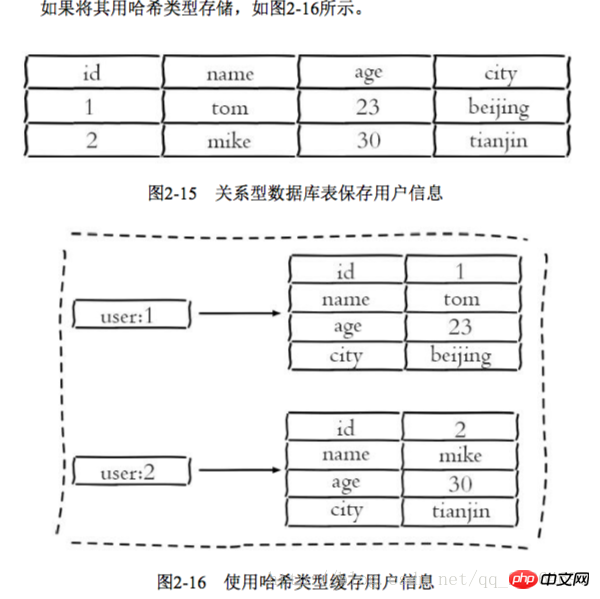
三种方法缓存用户信息
1 原声字符串类型:每个属性一个键

优点:简单直观,每个属性都支持更新操作
缺点:占用过多的键,内存占用量较大,同时用户信息内聚性比较差,所以一般不会在生产环境用
2 序列化字符串类型:将用户信息序列化后用一个键保存

优点:简化编程,如果合理的使用序列化可以提高内存的使用效率
缺点:序列化和反序列化有一定的开销,同时每次更新属性,都需要把数据取出来反序列化,更新后再序列化到Redis中
3 哈希类型:每个用户属性使用一对field-value,但是只用一个键保存
优点:简单直观,如果使用合理,可以减少内存空间的使用
缺点:要控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会消耗更多的内存
2.4 列表
列表类型用来存储多个有序的字符串,一个列表最多存储2的32次方-1个元素,列表是一种比较灵活的数据结构,它可以灵活的充当栈和队列的角色,在实际开发上有很多应用场景
列表有两个特点:第一、列表中的元素是有序的,这就意味着可以通过索引下标获取某个元素或者某个范围内的元素列表。第二、列表中的元素可以是重复的
2.4.1 命令
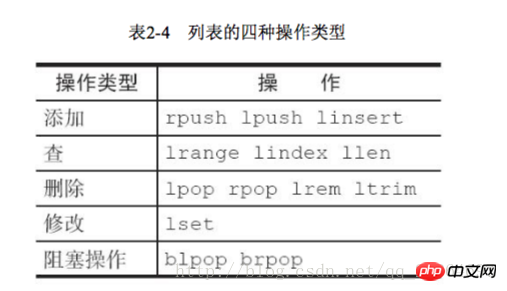
1 添加操作
1.1 从右边往左插入元素 rpush key value
1.2 从左往右插入元素 lpush key value
1.3 向某个元素前或者后插入元素 linsert key before|after pivot value
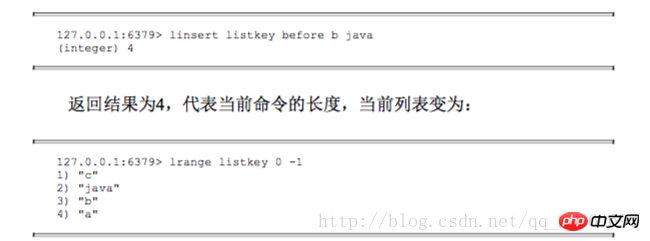
2 查找
1 获取指定范围内的元素列表 lrange key start end
Les indices d'index ont deux caractéristiques : premièrement, les indices d'index sont 0-n-1 de gauche à droite et -1--n de droite à gauche. Deuxièmement, l'option de fin de lrange se contient, ce n'est pas le cas. comme de nombreux langages de programmation qui n'incluent pas la fin
2 Obtenez l'élément lindex key index
3 Obtenez la longueur de la liste llen key
3 Supprimer
1 Pop l'élément du côté gauche de la liste touche lpop
2 Pop la touche rpop
5 Opération de blocage brpop blpop key timeout
3
2.4.2 Encodage interne
Il existe deux encodages internes pour types de liste
ziplist (liste compressée) : lorsque le nombre d'éléments de la liste est < list-max-ziplist-entries et list-max-ziplist-value (64 octets), Redis utilisera l'implémentation interne de la liste pour réduire l'utilisation de la mémoire
Lorsque les conditions de la ziplist ne peuvent pas être remplies, Redis utilisera la liste liée comme implémentation interne de la liste
2.4. 3 Scénarios d'utilisation
lpush+rpop=Queue(queue)
lpsh +ltrim=Capped Collection (collection limitée)
lpush+brpop=Message Queue(Message Queue)
2.5 Collection
Les ensembles sont utilisés pour stocker plusieurs éléments de chaîne différents des listes. sont des éléments en double et les éléments de l'ensemble ne sont pas ordonnés
2.5.1 Commandes
1 Opérations dans l'ensemble
1.1 Ajouter éléments sadd élément clé
1.2 Supprimer l'élément srem élément clé
1.3 Calculer le nombre d'éléments clé cicatrice
1.4 Déterminer si l'élément est dans l'élément clé sismember défini
1.5 Renvoie aléatoirement le nombre spécifié d'éléments de la clé srandmember de la collection
1.6 Extrait l'élément au hasard de la clé spop définie
1.7 Obtenir la clé smembers de tous les éléments
2 Opérations entre les ensembles
1 Trouver la clé de frittage d'intersection de plusieurs ensembles...
2 demandes Union de plusieurs ensembles clé suinon... Enregistrer
destination suionstore clé
🎜>
intset (ensemble d'entiers) : lorsque les éléments de l'ensemble sont tous des entiers et que le nombre d'éléments est inférieur à la configuration set-max-intset-entries (par défaut 512), Redis utilisera intset comme implémentation interne de l'ensemble , réduisant ainsi l'utilisation de la mémoire 
Table de hachage) Lorsque le type de collection ne peut pas répondre aux conditions de l'intset, Redis utilisera la table de hachage comme implémentation interne de la collection
2.5. 3 Scénarios d'utilisation
2 Ajouter un utilisateur au tag
sadd tag1:utilisateurs utilisateur:1 utilisateur:3
sadd tag1:users user:1 user:3
5 Calculer les tags d'intérêt commun aux utilisateurs
sinter user:1 tags user:2 tags
Conseils de développement : sadd=Tagging(tag) spop/srandmember =Élément aléatoire (générer des nombres aléatoires, comme la loterie)
spop/srandmember=Élément aléatoire (générer des nombres aléatoires, comme la loterie) sadd+sinter=Social Graph (besoins sociaux)
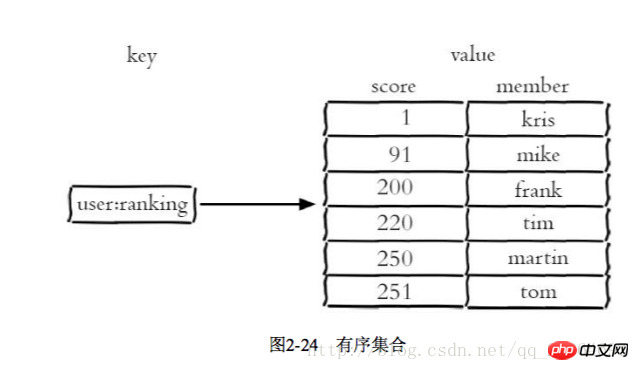
2.6 Ensemble ordonné
Un ensemble ordonné consiste à ajouter une partition à l'ensemble comme base de tri
2.6.1 Commande
1 Dans la collection
1Ajouter un membre zadd key score memeber
nx xx ch renvoie le nombre d'éléments et les scores de l'ensemble ordonné qui ont changé après cette opération, incr : augmenter le score
Les ensembles ordonnés fournissent un champ de tri par rapport aux ensembles, mais ils produisent aussi Compte tenu du coût, la complexité temporelle de zadd est O(log(n)), et la complexité temporelle de sadd est O(1)
2 Calculez le nombre de membres
Scard key
3 Calculer le score d'un membre zscore key member
4 Calculer le classement du membre zrank key member
5 Supprimer le membre zrem clé membre
6 Augmenter le score du membre zincrby clé incrément membre
7 Renvoie les membres dans la plage de classement spécifiée zrange clé début fin
8 Retourne aux membres spécifiés de la plage de scores zrangebysore key min max
9 Renvoie le nombre de membres dans la plage de scores spécifiée zcount key min max
10 Supprimer les éléments ascendants dans le classement spécifié zremrangebyrank key start end
11 Supprimer les membres de la plage de scores spécifiée zremrangebyscore key min max
2 Opérations entre les ensembles
1 Touche numérique de destination Intersection zinter store
2 Touche numérique de destination Union zunionstore
2.6.2 Encodage interne
Là existe deux encodages internes pour les types d'ensembles ordonnés : 🎜>
Ziplist (liste compressée) Lorsque l'ordre de la collection ordonnée est inférieur à la configuration ZSET-MAX-Ziplist-Entries et que la valeur de chaque élément est plus petite que la configuration ZSET-MAX-Ziplist-Value, Redis utilisera Ziplist En tant qu'implémentation interne des ensembles ordonnés, ziplist peut réduire efficacement l'utilisation de la mémoire
skiplist (skip list) Lorsque les conditions de la ziplist ne sont pas remplies, Les ensembles ordonnés utiliseront skiplist comme implémentation interne, donc ceci L'efficacité de lecture et d'écriture de ziplist diminuera
2.6.3 Scénarios d'utilisation
Un scénario d'utilisation typique pour les collections ordonnées est le système de classement. Par exemple, un site Web de vidéos doit classer les vidéos mises en ligne par les utilisateurs
1 Ajouter les likes de l'utilisateur zdd user:ranking:2016_03_15 mike 3
1 Puis zincrby user:ranking:2016_03_15 mike 1
2 Annuler les likes de l'utilisateur
; zrevrangebyrank user:ranking:2016_03_15 0 9
4 Afficher les informations et les scores de l'utilisateur
Cette fonction peut utiliser le nom de l'utilisateur comme clé suffixe et enregistrez les informations de l'utilisateur dans un type de hachage. En ce qui concerne le score de l'utilisateur et le classement, vous pouvez utiliser les deux fonctions zcore et zrank 2.7.1 Unique. Gestion des clés
1 clé renommer la clé nouvelle clé
2 renvoie aléatoirement une clé randomkey
3 expiration de la clé -1 la clé n'est pas définie Délai d'expiration -2 la clé n'existe pas
expire la clé secondes : La clé expire après secondes secondes 
expire key itmestamp La clé expire après le deuxième timestamp timestamp
3 La commande persist peut effacer le délai d'expiration du key
4 Pour les clés de type chaîne, l'exécution de la commande set supprimera le délai d'expiration. Ce problème est facilement négligé en développement
La commande 3 migrate est utilisée pour migrer les données entre les instances Redis
2.7.2 Traverser les clés
Redis fournit deux commandes pour parcourir toutes les clés respectivement. Ce sont les clés et scan
1 Parcours complet du modèle de touches
* Représente la correspondance avec n'importe quel caractère
. >
[] représente la correspondance d'un caractère
Une grande quantité peut facilement provoquer un blocage
2 Traversée progressive
Le scan peut être pensé comme scanner seulement une partie des clés d'un dictionnaire Jusqu'à ce que tous les dictionnaires du dictionnaire,
les commandes correspondantes soient HSAN, SSCAN, ZCAN
Le parcours progressif peut résoudre efficacement le problème d'obstruction que la commande de clés peut survenir. Lors de l'ajout ou de la suppression, il n'est pas garanti que les nouvelles clés transitent vers
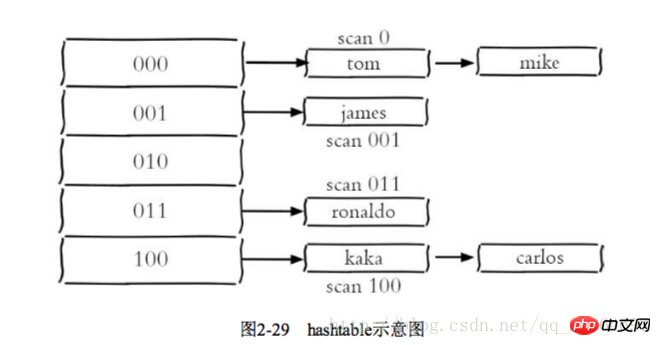 2.7.3 Gestion de la base de données
2.7.3 Gestion de la base de données
2.8 Revue de la fin de ce chapitre
Recommandations associées :
Structure de données Redis
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Redis, en tant que Message Middleware, prend en charge les modèles de consommation de production, peut persister des messages et assurer une livraison fiable. L'utilisation de Redis comme Message Middleware permet une faible latence, une messagerie fiable et évolutive.
