
 base de données
tutoriel mysql
Explication détaillée des exemples d'opérations de table de données MySQL
base de données
tutoriel mysql
Explication détaillée des exemples d'opérations de table de données MySQL
Explication détaillée des exemples d'opérations de table de données MySQL

Cet article partage principalement avec vous des exemples détaillés de fonctionnement d'une table de données MySQL. J'espère qu'il pourra vous aider. Voyons d'abord comment créer une table de données.
Créer un tableau
Forme de syntaxe de base :
create table 【if not exists】 表名 (字段列表 【,索引或约束列表】) 【表选项列表】;
Format de paramètre de champ :
Type de nom de champ [Attribut de champ 1 Attribut de champ 2 …..]
Instructions :
1. Vous pouvez choisir vous-même le nom du champ
2 Le type est le type de données appris auparavant : int, tinyint, float, double, char(6), varchar(25), text ; , dateheure.
3. Il peut y avoir plusieurs attributs de champ (selon des besoins spécifiques), séparés directement par des espaces ; les principaux sont les suivants :
| 属性名称 | 含义 |
|---|---|
| auto_increment: | 只用于整数类型,让该字段的值自动获得一个增长值。通常用于做一个表的第一个字段的设定,并且通常还当做主键(primary key) |
| primary key: | 用于设定该字段为主键,此时该字段的值就可以“唯一确定”一行数据 |
| unique key: | 设定该字段是“唯一的”,也就是不重复的。 |
| not null: | 用于设定该字段不能为空(null),如果没有设定,则默认是可为空的。 |
| comment : | 字段说明文字 |
Index
-
L'index est une « table de données » cachée automatiquement maintenue au sein du système. Sa fonction est d'accélérer considérablement la recherche de données !
Les données de ce tableau de données masquées sont automatiquement triées et la vitesse de recherche est basée sur cela.
Le formulaire est :
索引类型(要建立索引的字段名)
| Type d'index | Formulaire< / th> | Signification | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| La clé d'index ordinaire | (nom du champ) | est a C'est juste un index. Cela n'a aucun autre effet. Cela ne peut qu'accélérer la recherche. | ||||||||||||||||||
| Index unique | clé unique (nom du champ)< /td> | C'est un index, et vous pouvez également définir la valeur de son champ pour qu'elle ne soit pas répétée (unicité) | ||||||||||||||||||
| Index de clé primaire | < td>clé primaire (nom du champ)est un index, et elle a également pour fonction de distinguer n'importe quelle ligne de données dans la table (en fait, elle est également unique. Elle en a en fait un peu plus). fonctions que l'index unique : l'unicité peut être vide, mais la clé primaire ne peut pas être vide | |||||||||||||||||||
| Index texte intégral | texte intégral (nom du champ)<. /td> |
| ||||||||||||||||||
| Clé étrangère (nom du champ) | fait référence à d'autres tables ( correspondant aux noms de champs dans d'autres tables) |

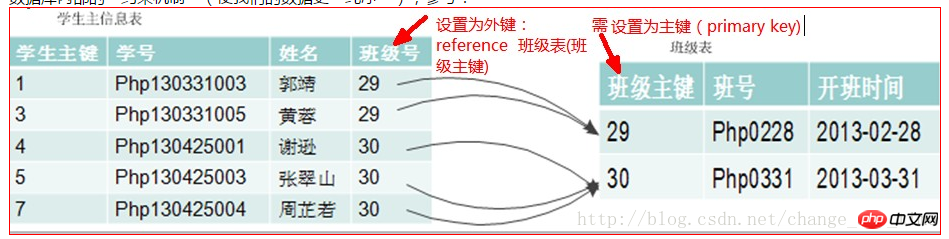

| 约束类型 | 形式 | 含义 |
|---|---|---|
| 主键约束 | primary key ( 字段名) | 使该设定字段的值可以用于“唯一确定一行数据”,其实就是“主键”的意思。 |
| 唯一约束 | unique key ( 字段名) | 使该设定字段的值具有“唯一性”,自然也是可区分的。 |
| 外键约束 | foreign key ( 字段名) references 其他表名(对应其他表中的字段名) | 使该设定字段的值,必须在其谁定的对应表中的对应字段中已经有该值了。 |
| 非空约束 | not null | 其实就是设定一个字段时写的那个“not null”属性。这个约束只能写在字段属性上 |
| 默认约束 | default XX值 | 其实就是设定一个字段时写的那个“default 默认值”属性,这个约束只能写在字段属性上。 |
| 检查约束 | check(某种判断语句) |
比如:
create table tab1 ( age tinyint,check (age>=0 and age <100) /*这就是检查约束*/ )#目前相关版本还不支持,就是说只分析,但会被忽略。
其实,主键约束,唯一约束,外键约束,只是“同一件事情的2个不同角度的说法”,他们同时也称为“主键索引”,“唯一索引”,“外键索引”。
表选项列表
表选项就是,创建一个表的时候,对该表的整体设定,主要有如下几个:
1、 charset = 要使用的字符编码,
2、 engine = 要使用的存储引擎(也叫表类型),
3、auto_increment = 设定当前表的自增长字段的初始值,默认是1
4、comment =‘该表的一些说明文字’
说明:
1,设定的字符编码是为了跟数据库设定的不一样。如果一样,就不需要设定了:因为其会自动使用数据库级别的设定;
2,engine(存储引擎)在代码层面,就是一个名词:InnoDB, MyIsam, BDB, archive, Memory。默认是InnoDB。
存储引擎
存储引擎是将数据存储到硬盘的“机制”。
不同的存储引擎,其实主要是从2个大的层面来设计存储机制:
尽可能快的速度;
尽可能多的功能;
选择不同的存储引擎,就是上述性能和功能的“权衡”。
大体如下: 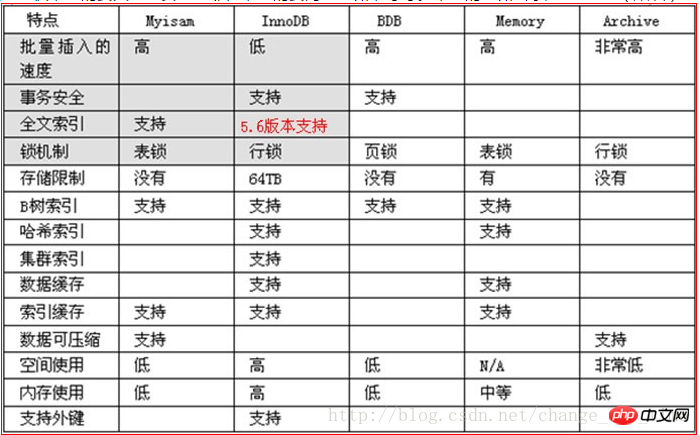
演示: 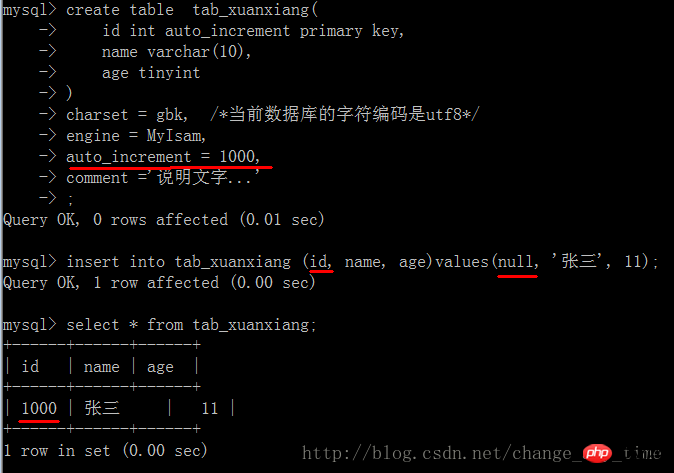
修改表
几点说明:
修改表,是指修改表的结构——正如创建表也是设定表的结构。
创建表能做的事,修改表几乎都能做——但很不推荐去修改表,而是应该在创建表的时候就基本确定表的结构。
大体来说:
1:可以对字段进行:添加,删除,修改;
2:可以对索引进行:添加,删除表的选项,通常“都是修改”,即使不写任何表选项,他们都有其默认值。
常见几个:
| 操作类型 | 表达式 |
|---|---|
| 添加字段 | alter table 表名 add [column] 新字段名 字段类型 [字段属性列表] |
| 修改字段(并可改名) | alter table 表名 change [column] 旧字段名 新字段名 新字段类型 [新字段属性列表] |
| 删除字段 | alter table 表名 drop [column] 字段名 |
| 添加普通索引 | alter table 表名 add key [索引名] (字段名1[,字段名2,…]) |
| 添加唯一索引(约束) | alter table 表名 add unique key (字段名1[,字段名2,…]) |
| 添加主键索引(约束) | alter table 表名 add primary key (字段名1[,字段名2,…]) |
| 修改表名 | alter table 旧表名 rename [to] 新表名 |
| 删除表 | drop table 【if exists】 表名 |
其他表的相关语句:
| 操作类型 | 表达式 |
|---|---|
| 显示当前数据库中的所有表 | show tables |
| 显示某表的结构 | desc 表名; 或:describe 表名 |
| 显示某表的创建语句 | show create table 表名 |
| 重命名表 | rename table 旧表名 to 新表名 |
| 从已有表复制表结构 | create table [if not exists] 新表名 like 原表名 |
演示复制表结构:
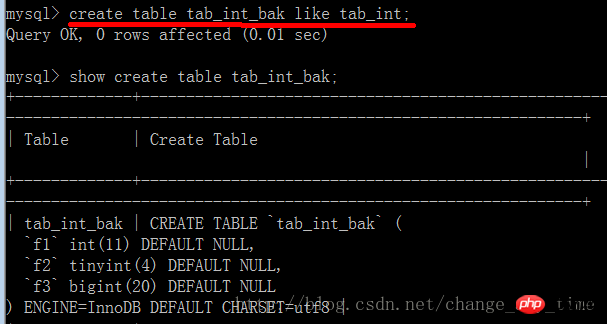
创建表tab_int,显示表创建语句
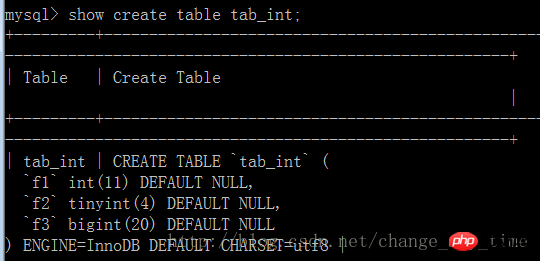
将tab_int复制给tab_int_bak,显示tab_int_bak表创建语句,与tab_int一致

相关推荐:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
La construction d'une base de données SQL comprend 10 étapes: sélectionner des SGBD; Installation de SGBD; créer une base de données; créer une table; insérer des données; récupération de données; Mise à jour des données; supprimer des données; gérer les utilisateurs; sauvegarde de la base de données.
