

Qu'est-ce que la collecte ? Il s'agit d'utiliser des programmes PHP pour capturer des informations provenant d'autres sites Web dans notre propre base de données et notre propre site Web. Cet article partage principalement avec vous trois méthodes de collecte de données en PHP, en espérant vous aider.
Technologie de production et de collecte PHP :
De la socket inférieure à la fonction d'opération de fichier de haut niveau, il existe un total de 3 méthodes pour réaliser la collecte.
1. Utilisez la technologie socket pour collecter :
La collection de sockets est le niveau le plus bas. Elle établit simplement une longue connexion, puis nous devons construire nous-mêmes la chaîne de protocole http pour envoyer la requête.
Par exemple, si vous souhaitez récupérer le contenu de cette page, http://tv.youku.com/?spm=a2hww.20023042.topNav.5~1~3!2~A, utilisez socket pour écrire comme suit :
<?php
//连接,$error错误编号,$errstr错误的字符串,30s是连接超时时间
$fp=fsockopen("www.youku.com",80,$errno,$errstr,30);
if(!$fp) die("连接失败".$errstr);
//构造http协议字符串,因为socket编程是最底层的,它还没有使用http协议
$http="GET /?spm=a2hww.20023042.topNav.5~1~3!2~A HTTP/1.1\r\n"; // \r\n表示前面的是一个命令
$http.="Host:www.youku.com\r\n"; //请求的主机
$http.="Connection:close\r\n\r\n"; // 连接关闭,最后一行要两个\r\n
//发送这个字符串到服务器
fwrite($fp,$http,strlen($http));
//接收服务器返回的数据
$data='';
while (!feof($fp)) {
$data.=fread($fp,4096); //fread读取返回的数据,一次读取4096字节
}
//关闭连接
fclose($fp);
var_dump($data);
?>Le résultat imprimé est le suivant, y compris les informations d'en-tête renvoyées et le code source de la page :

2. Utilisez curl_un ensemble de fonctions
curl encapsule le protocole HTTP dans de nombreuses fonctions. Vous pouvez directement transmettre les paramètres correspondants. , ce qui réduit la difficulté d'écriture des chaînes du protocole HTTP.
Prérequis : L'extension curl doit être activée dans php.ini.
//生成一个curl对象 $curl=curl_init(); //设置URL和相应的选项 curl_setopt($curl, CURLOPT_URL, "http://www.youku.com"); curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); //将curl_exec()获取的信息以字符串返回,而不是直接输出。 //执行curl操作 $data=curl_exec($curl); var_dump($data);
Le résultat imprimé est le suivant, incluant uniquement le code source de la page : 
3. Utiliser directement file_get_contents (niveau supérieur)
Prérequis : Définir l'adresse url qui permet d'ouvrir un réseau dans php.ini.

//使用file_get_contents()
$data=file_get_contents("http://www.youku.com");
var_dump($data);
Sélection de 3 méthodes
Les trois méthodes ci-dessus sont principalement utilisées pour la communication entre réseaux. Parmi eux, les deux derniers sont les plus couramment utilisés : Si vous souhaitez collecter une grande quantité de données par lots, utilisez le second [CURL], qui a de bonnes performances et stabilité .
Utilisez la troisième méthode lorsque vous envoyez quelques demandes occasionnellement mais pas fréquemment.
Extension : Comment briser l'anti-sangsue des images ?
Par exemple, les photos du site 7060 sont protégées des hotlinking : les photos sont visibles sur son site, mais ne sont pas accessibles en dehors du site.
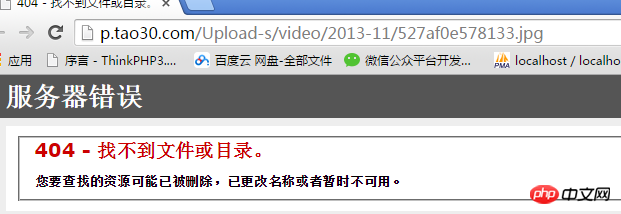
Principe : Il existe un élément référent dans le protocole HTTP, qui représente l'adresse source de la requête. Le serveur. déterminera si Si cette demande ne provient pas de ce site Web, elle sera filtrée :
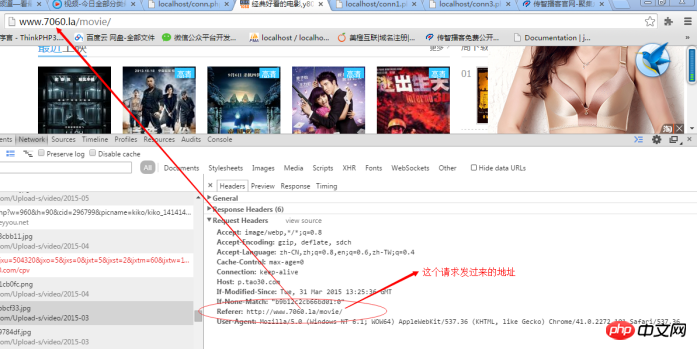
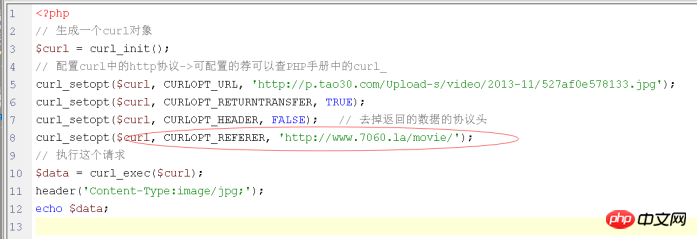
Solution : Simulez-la vous-même lors de l'envoi de HTTP Juste référent :
Extension : Certaines collectes de données doivent d'abord être connectées. Vous pouvez utiliser la simulation. simulation d'essai pour vous connecter. Collection sous le statut :
a. Connectez-vous d'abord à l'aide du navigateur. Après la connexion, il y aura SESSIONID
dans le COOKIE du navigateur. .b. 发PHP发HTTP协议时,把浏览器中的SESSIONID放到PHP的HTTP协议请求里,这样就在以登录的状态发请求。
总结:所有客户端发过来的数据都可以被模拟,所以服务器上的程序必须要必要的地方过滤客户端的数据。
什么时候用以上东西?接口开发时、采集时。
二、数据采集
例如我要采集这个url里的所有美国电影的信息,
http://list.youku.com/category/show/c_96_a_%E7%BE%8E%E5%9B%BD_s_1_d_1_p_3.html
则先要知道电影所在的节点的结构,我们使用firebug查看。
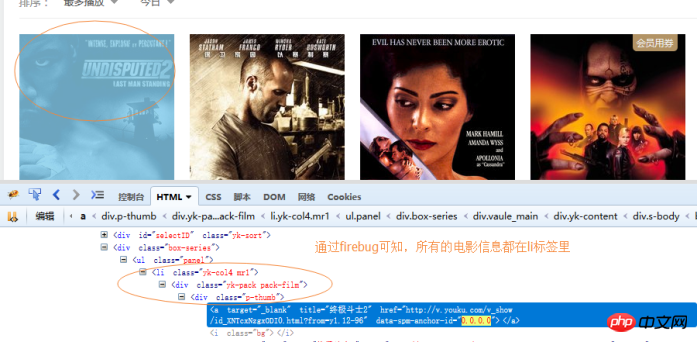
然后开始写代码:完整代码如下
/**
* 发一个GET请求获取数据
*/
function get($url)
{
global $curl;
// 配置curl中的http协议->可配置的荐可以查PHP手册中的curl_
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, TRUE);
curl_setopt($curl, CURLOPT_HEADER, FALSE);
// 执行这个请求
return curl_exec($curl);
}
// 生成一个curl对象
$curl = curl_init();
$url='http://list.youku.com/category/show/c_96_a_%E7%BE%8E%E5%9B%BD_s_1_d_1_p_3.html';
$data=get($url);
// 匹配电影所在位置
$list_preg = '/<li class="yk-col4 mr1">.+<\/li>/Us';
// 匹配img标签上的src和alt
$img_preg = '/<img class="quic" _src="(.*)" src="(.*)" alt="(.*)" \/>/U';
//匹配电影的url
$video_preg='/<a href="(.*)" title="(.*)" target="(.*)"><\/a>/U';
//把所有的li存到$list里,$list是个二维数组
preg_match_all($list_preg,$data,$list);
//var_dump($list);
foreach ($list[0] as $k => $v) { //这里$v就是每一个li标签
/* 获取图片及电影名称
preg_match($img_preg,$v,$img); //把匹配到的图片的信息存到$img里
var_dump($img);
*/
/*获取电影地址
preg_match($video_preg,$v,$video); //把匹配到的电影的信息存到$video里
var_dump($video);
*/
preg_match($img_preg,$v,$img);
preg_match($video_preg,$v,$video);
echo $img[0].'<a href="'.$video[1].'">'.$video[2].'</a>';
}测试:
打印$list;

打印$img

打印$video

最终效果:
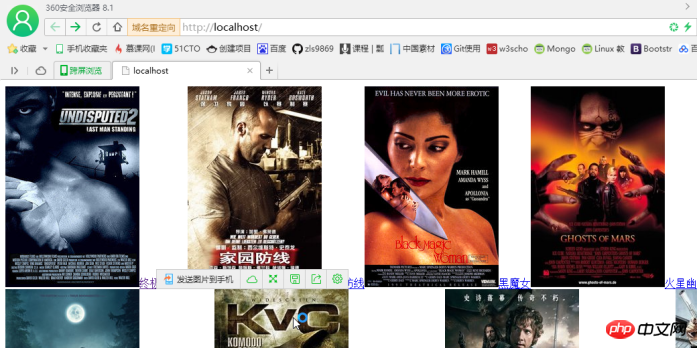
如果需要把图片拷贝到硬盘上,则在foreach循环里加上以下代码:
$imgData = get($img[1]);
// 把图片文件写到硬盘上【下载】
// 因为操作系统是GBK的,所以要把UTF8转成GBK
is_dir('./youkuimg/') ? '': mkdir('./youkuimg/');
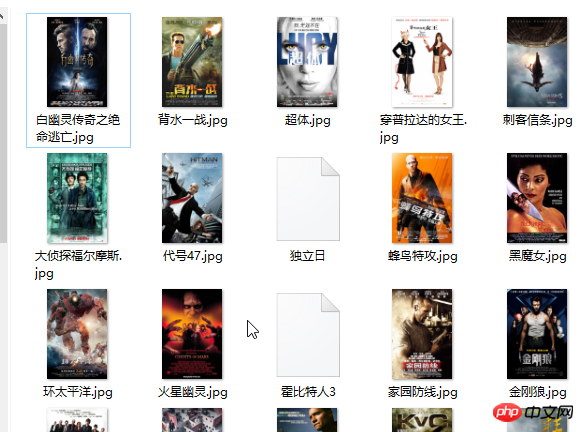
file_put_contents('./youkuimg/'.mb_convert_encoding($img[3], 'gbk', 'utf-8').'.jpg', $imgData);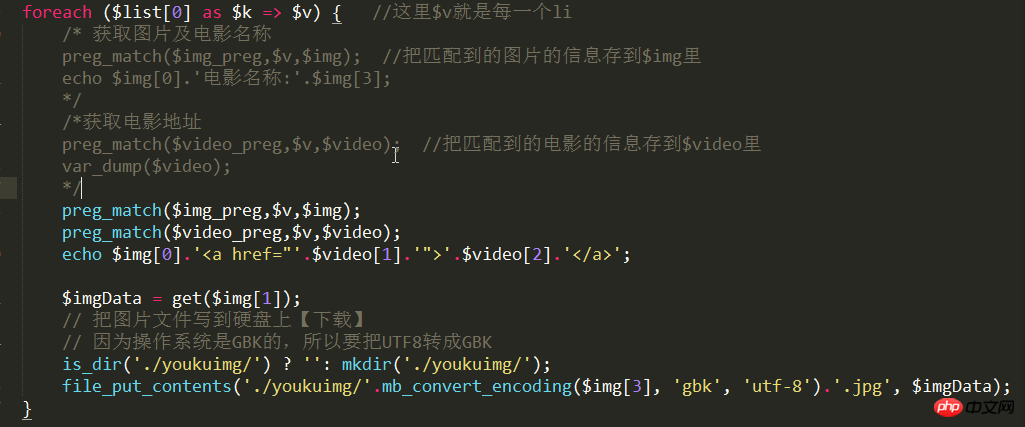
效果如下:在当前目录下的youkuimg目录下就会有下载好的图片。
my github: https://github.com/lensh
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelles sont les technologies de collecte de données ?
Quelles sont les technologies de collecte de données ?
 Comment ouvrir le fichier php
Comment ouvrir le fichier php
 Comment supprimer les premiers éléments d'un tableau en php
Comment supprimer les premiers éléments d'un tableau en php
 Que faire si la désérialisation php échoue
Que faire si la désérialisation php échoue
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Comment télécharger du HTML
Comment télécharger du HTML
 Comment résoudre les caractères tronqués en PHP
Comment résoudre les caractères tronqués en PHP








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



