
 développement back-end
Tutoriel Python
Comment résoudre le problème 403 dans les robots d'exploration
développement back-end
Tutoriel Python
Comment résoudre le problème 403 dans les robots d'exploration
Comment résoudre le problème 403 dans les robots d'exploration

Lors de l'écriture d'un robot en Python, html.getcode() rencontrera le problème de l'accès 403 interdit, qui est une interdiction des robots automatisés sur le site Web. Cet article présente principalement comment résoudre le problème 403 des robots d'exploration dans Angular2 Advanced. L'éditeur pense que c'est plutôt bon, je vais donc le partager avec vous maintenant et le donner comme référence. Suivons l'éditeur pour y jeter un œil
Pour résoudre ce problème, vous devez utiliser le module python urllib2 module
urllib2 module Il s'agit d'un module avancé d'exploration de robots. Il existe de nombreuses méthodes
Par exemple, connect url=http://blog.csdn.net/qysh123
Il peut y avoir un problème d'accès interdit 403 pour cette connexion
Pour résoudre ce problème, les étapes suivantes sont requises :
<span style="font-size:18px;">req = urllib2.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36")
req.add_header("GET",url)
req.add_header("Host","blog.csdn.net")
req.add_header("Referer","http://blog.csdn.net/")</span>User-Agent est un attribut spécifique au navigateur. Vous pouvez afficher le code source via le navigateur pour voir
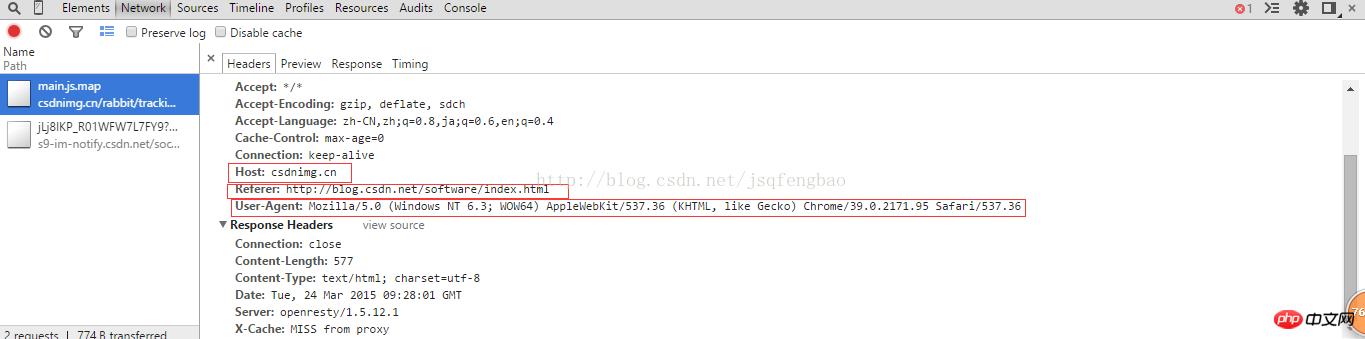
puis html=urllib2. .urlopen(req)
print html.read()
peut télécharger tout le code de la page Web sans problème d'accès 403 interdit.
Pour les problèmes ci-dessus, il peut être encapsulé dans une fonction pour une utilisation facile à l'avenir. Le code spécifique :
- .
#-*-coding:utf-8-*- import urllib2 import random url="http://blog.csdn.net/qysh123/article/details/44564943" my_headers=["Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14", "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)" ] def get_content(url,headers): ''''' @获取403禁止访问的网页 ''' randdom_header=random.choice(headers) req=urllib2.Request(url) req.add_header("User-Agent",randdom_header) req.add_header("Host","blog.csdn.net") req.add_header("Referer","http://blog.csdn.net/") req.add_header("GET",url) content=urllib2.urlopen(req).read() return content print get_content(url,my_headers)Copier après la connexion
La fonction aléatoire est utilisée pour obtenir automatiquement les informations User-Agent du type de navigateur qui ont été écrites. Dans la fonction personnalisée, vous devez écrire votre. propre hôte, référent, GET Information, etc., après avoir résolu ces problèmes, vous pouvez accéder en douceur et les informations d'accès 403 n'apparaîtront plus.Bien sûr, si la fréquence d'accès est trop rapide, certains sites Web seront quand même filtrés. Pour résoudre ce problème, vous devez utiliser une méthode IP proxy. . . Résolvez-le spécifiquement par vous-même
Recommandations associées :
Le robot d'exploration Python résout l'erreur d'accès interdit 403
Erreur HTTP Python3 403 : Interdit
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
En ce qui concerne le problème de la suppression de l'interpréteur Python qui est livré avec des systèmes Linux, de nombreuses distributions Linux préinstalleront l'interpréteur Python lors de l'installation, et il n'utilise pas le gestionnaire de packages ...
 Que dois-je faire si le module '__builtin__' n'est pas trouvé lors du chargement du fichier de cornichon dans Python 3.6?
Apr 02, 2025 am 07:12 AM
Que dois-je faire si le module '__builtin__' n'est pas trouvé lors du chargement du fichier de cornichon dans Python 3.6?
Apr 02, 2025 am 07:12 AM
Chargement des fichiers de cornichons dans Python 3.6 Rapport de l'environnement Erreur: modulenotFoundError: NomoduLenamed ...
 Debian Strings est-il compatible avec plusieurs navigateurs
Apr 02, 2025 am 08:30 AM
Debian Strings est-il compatible avec plusieurs navigateurs
Apr 02, 2025 am 08:30 AM
"Debianstrings" n'est pas un terme standard, et sa signification spécifique n'est pas encore claire. Cet article ne peut pas commenter directement la compatibilité de son navigateur. Cependant, si "DebianStrings" fait référence à une application Web exécutée sur un système Debian, sa compatibilité du navigateur dépend de l'architecture technique de l'application elle-même. La plupart des applications Web modernes se sont engagées à compatibilité entre les navigateurs. Cela repose sur les normes Web suivantes et l'utilisation de technologies frontales bien compatibles (telles que HTML, CSS, JavaScript) et les technologies back-end (telles que PHP, Python, Node.js, etc.). Pour s'assurer que l'application est compatible avec plusieurs navigateurs, les développeurs doivent souvent effectuer des tests croisés et utiliser la réactivité
 La modification XML nécessite-t-elle une programmation?
Apr 02, 2025 pm 06:51 PM
La modification XML nécessite-t-elle une programmation?
Apr 02, 2025 pm 06:51 PM
La modification du contenu XML nécessite une programmation, car elle nécessite une recherche précise des nœuds cibles pour ajouter, supprimer, modifier et vérifier. Le langage de programmation dispose de bibliothèques correspondantes pour traiter XML et fournit des API pour effectuer des opérations sûres, efficaces et contrôlables comme les bases de données de fonctionnement.
 La vitesse de conversion est-elle rapide lors de la conversion du XML en PDF sur le téléphone mobile?
Apr 02, 2025 pm 10:09 PM
La vitesse de conversion est-elle rapide lors de la conversion du XML en PDF sur le téléphone mobile?
Apr 02, 2025 pm 10:09 PM
La vitesse du XML mobile à PDF dépend des facteurs suivants: la complexité de la structure XML. Méthode de conversion de configuration du matériel mobile (bibliothèque, algorithme) Méthodes d'optimisation de la qualité du code (sélectionnez des bibliothèques efficaces, optimiser les algorithmes, les données de cache et utiliser le multi-threading). Dans l'ensemble, il n'y a pas de réponse absolue et elle doit être optimisée en fonction de la situation spécifique.
 Comment modifier le contenu des commentaires dans XML
Apr 02, 2025 pm 06:15 PM
Comment modifier le contenu des commentaires dans XML
Apr 02, 2025 pm 06:15 PM
Pour les petits fichiers XML, vous pouvez remplacer directement le contenu d'annotation par un éditeur de texte; Pour les fichiers volumineux, il est recommandé d'utiliser l'analyseur XML pour le modifier pour garantir l'efficacité et la précision. Soyez prudent lors de la suppression des commentaires XML, le maintien des commentaires aide généralement à coder la compréhension et la maintenance. Les conseils avancés fournissent un exemple de code Python pour modifier les commentaires à l'aide de l'analyseur XML, mais l'implémentation spécifique doit être ajustée en fonction de la bibliothèque XML utilisée. Faites attention aux problèmes d'encodage lors de la modification des fichiers XML. Il est recommandé d'utiliser le codage UTF-8 et de spécifier le format de codage.
 Y a-t-il une application mobile qui peut convertir XML en PDF?
Apr 02, 2025 pm 08:54 PM
Y a-t-il une application mobile qui peut convertir XML en PDF?
Apr 02, 2025 pm 08:54 PM
Une application qui convertit le XML directement en PDF ne peut être trouvée car ce sont deux formats fondamentalement différents. XML est utilisé pour stocker des données, tandis que PDF est utilisé pour afficher des documents. Pour terminer la transformation, vous pouvez utiliser des langages de programmation et des bibliothèques telles que Python et ReportLab pour analyser les données XML et générer des documents PDF.
 Comment définir un type d'énumération à Protobuf et associer des constantes de chaîne?
Apr 02, 2025 pm 03:36 PM
Comment définir un type d'énumération à Protobuf et associer des constantes de chaîne?
Apr 02, 2025 pm 03:36 PM
Problèmes de définition de l'énumération constante de la chaîne à Protobuf Lorsque vous utilisez Protobuf, vous rencontrez souvent des situations où vous devez associer le type d'énumération aux constantes de chaîne ...
