

Le contenu de cet article est de partager avec vous la mesure de distance et l'implémentation de Python. Les amis dans le besoin peuvent se référer au contenu de l'article
Réimprimé de : http://www.cnblogs.com/denny402/p/7027954.html
https://www.cnblogs.com/denny402 /p /7028832.html
1. Distance euclidienne La distance euclidienne est la méthode de calcul de distance la plus simple à comprendre, dérivée de l'espace euclidien La formule de distance entre deux points.
(1) La distance euclidienne entre deux points a(x1,y1) et b(x2,y2) sur le plan bidimensionnel : 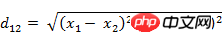 (2) Deux points a(x1) dans l'espace tridimensionnel ,y1,z1) et b(x2,y2,z2) Distance euclidienne :
(2) Deux points a(x1) dans l'espace tridimensionnel ,y1,z1) et b(x2,y2,z2) Distance euclidienne : 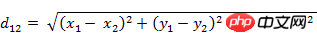 (3) Deux vecteurs à n dimensions a(x11,x12,…,x1n) et b( La distance euclidienne entre la mise en œuvre :
(3) Deux vecteurs à n dimensions a(x11,x12,…,x1n) et b( La distance euclidienne entre la mise en œuvre :
Méthode 1 : 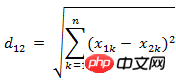


import numpy as np x=np.random.random(10) y=np.random.random(10)#方法一:根据公式求解d1=np.sqrt(np.sum(np.square(x-y)))#方法二:根据scipy库求解from scipy.spatial.distance import pdistX=np.vstack([x,y]) d2=pdist(X)
Vous pouvez deviner la méthode de calcul de cette distance à partir du nom. Imaginez que vous conduisez d’une intersection à une autre à Manhattan. La distance parcourue est-elle la distance en ligne droite entre les deux points ? Apparemment non, à moins que vous puissiez traverser le bâtiment. La distance parcourue réelle est cette « distance de Manhattan ». C'est aussi l'origine du nom distance de Manhattan. La distance de Manhattan est également appelée City Block distance (City Block distance). (1) Distance de Manhattan entre deux points a(x1, y1) et b(x2, y2) sur un plan bidimensionnel
(2) Deux vecteurs à n dimensions a(x11 ,x12 ,…,x1n) et b(x21,x22,…,x2n) Distance de Manhattan
Implémentation en python : 
 Avez-vous déjà joué aux échecs ? Le roi peut se déplacer vers n’importe laquelle des 8 cases adjacentes en un seul mouvement. Alors, combien d'étapes faut-il au roi pour passer de la grille (x1, y1) à la grille (x2, y2) ? Essayez de vous promener par vous-même. Vous constaterez que le nombre minimum d'étapes est toujours max( | x2-x1 | , | y2-y1 | ) étapes. Il existe une méthode de mesure de distance similaire appelée distance de Chebyshev.
Avez-vous déjà joué aux échecs ? Le roi peut se déplacer vers n’importe laquelle des 8 cases adjacentes en un seul mouvement. Alors, combien d'étapes faut-il au roi pour passer de la grille (x1, y1) à la grille (x2, y2) ? Essayez de vous promener par vous-même. Vous constaterez que le nombre minimum d'étapes est toujours max( | x2-x1 | , | y2-y1 | ) étapes. Il existe une méthode de mesure de distance similaire appelée distance de Chebyshev.
(2) Deux Les Distance de Chebyshev entre les vecteurs à n dimensions a(x11,x12,…,x1n) et b(x21,x22,…,x2n)
Une autre forme équivalente de cette formule est
import numpy as np x=np.random.random(10) y=np.random.random(10)#方法一:根据公式求解d1=np.sum(np.abs(x-y))#方法二:根据scipy库求解from scipy.spatial.distance import pdistX=np.vstack([x,y]) d2=pdist(X,'cityblock')
implémentation en python :
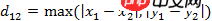
4. 闵可夫斯基距离(Minkowski Distance)
闵氏距离不是一种距离,而是一组距离的定义。
(1) 闵氏距离的定义
两个n维变量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:
也可写成

其中p是一个变参数。
当p=1时,就是曼哈顿距离
当p=2时,就是欧氏距离
当p→∞时,就是切比雪夫距离
根据变参数的不同,闵氏距离可以表示一类的距离。
(2)闵氏距离的缺点
闵氏距离,包括曼哈顿距离、欧氏距离和切比雪夫距离都存在明显的缺点。
举个例子:二维样本(身高,体重),其中身高范围是150~190,体重范围是50~60,有三个样本:a(180,50),b(190,50),c(180,60)。那么a与b之间的闵氏距离(无论是曼哈顿距离、欧氏距离或切比雪夫距离)等于a与c之间的闵氏距离,但是身高的10cm真的等价于体重的10kg么?因此用闵氏距离来衡量这些样本间的相似度很有问题。
简单说来,闵氏距离的缺点主要有两个:(1)将各个分量的量纲(scale),也就是“单位”当作相同的看待了。(2)没有考虑各个分量的分布(期望,方差等)可能是不同的。
python中的实现:
import numpy as np x=np.random.random(10) y=np.random.random(10)#方法一:根据公式求解,p=2d1=np.sqrt(np.sum(np.square(x-y)))#方法二:根据scipy库求解from scipy.spatial.distance import pdistX=np.vstack([x,y]) d2=pdist(X,'minkowski',p=2)
5. 标准化欧氏距离 (Standardized Euclidean distance )
(1)标准欧氏距离的定义
标准化欧氏距离是针对简单欧氏距离的缺点而作的一种改进方案。标准欧氏距离的思路:既然数据各维分量的分布不一样,好吧!那我先将各个分量都“标准化”到均值、方差相等吧。均值和方差标准化到多少呢?这里先复习点统计学知识吧,假设样本集X的均值(mean)为m,标准差(standard deviation)为s,那么X的“标准化变量”表示为: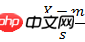
标准化后的值 = ( 标准化前的值 - 分量的均值 ) /分量的标准差
经过简单的推导就可以得到两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的标准化欧氏距离的公式:
如果将方差的倒数看成是一个权重,这个公式可以看成是一种加权欧氏距离(Weighted Euclidean distance)。
python中的实现:
import numpy as np x=np.random.random(10) y=np.random.random(10) X=np.vstack([x,y])#方法一:根据公式求解sk=np.var(X,axis=0,ddof=1) d1=np.sqrt(((x - y) ** 2 /sk).sum())#方法二:根据scipy库求解from scipy.spatial.distance import pdistd2=pdist(X,'seuclidean')
6. 马氏距离(Mahalanobis Distance)
(1)马氏距离定义
有M个样本向量X1~Xm,协方差矩阵记为S,均值记为向量μ,则其中样本向量X到u的马氏距离表示为:
而其中向量Xi与Xj之间的马氏距离定义为: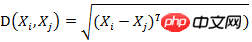
若协方差矩阵是单位矩阵(各个样本向量之间独立同分布),则公式就成了: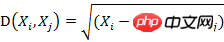
也就是欧氏距离了。
若协方差矩阵是对角矩阵,公式变成了标准化欧氏距离。
python 中的实现:
import numpy as np x=np.random.random(10) y=np.random.random(10)#马氏距离要求样本数要大于维数,否则无法求协方差矩阵#此处进行转置,表示10个样本,每个样本2维X=np.vstack([x,y]) XT=X.T#方法一:根据公式求解S=np.cov(X) #两个维度之间协方差矩阵SI = np.linalg.inv(S) #协方差矩阵的逆矩阵#马氏距离计算两个样本之间的距离,此处共有10个样本,两两组合,共有45个距离。n=XT.shape[0] d1=[]for i in range(0,n): for j in range(i+1,n): delta=XT[i]-XT[j] d=np.sqrt(np.dot(np.dot(delta,SI),delta.T)) d1.append(d) #方法二:根据scipy库求解from scipy.spatial.distance import pdist d2=pdist(XT,'mahalanobis')
马氏优缺点:
1)马氏距离的计算是建立在总体样本的基础上的,这一点可以从上述协方差矩阵的解释中可以得出,也就是说,如果拿同样的两个样本,放入两个不同的总体中,最后计算得出的两个样本间的马氏距离通常是不相同的,除非这两个总体的协方差矩阵碰巧相同;
2)在计算马氏距离过程中,要求总体样本数大于样本的维数,否则得到的总体样本协方差矩阵逆矩阵不存在,这种情况下,用欧式距离计算即可。
3)还有一种情况,满足了条件总体样本数大于样本的维数,但是协方差矩阵的逆矩阵仍然不存在,比如三个样本点(3,4),(5,6)和(7,8),这种情况是因为这三个样本在其所处的二维空间平面内共线。这种情况下,也采用欧式距离计算。
4)在实际应用中“总体样本数大于样本的维数”这个条件是很容易满足的,而所有样本点出现3)中所描述的情况是很少出现的,所以在绝大多数情况下,马氏距离是可以顺利计算的,但是马氏距离的计算是不稳定的,不稳定的来源是协方差矩阵,这也是马氏距离与欧式距离的最大差异之处。
优点:它不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关;由标准化数据和中心化数据(即原始数据与均值之差)计算出的二点之间的马氏距离相同。马氏距离还可以排除变量之间的相关性的干扰。缺点:它的缺点是夸大了变化微小的变量的作用。
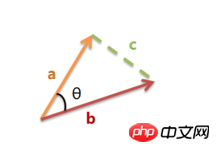
7. 夹角余弦(Cosine)
Cela peut aussi être appelé similarité cosinus. Le cosinus de l'angle en géométrie peut être utilisé pour mesurer la différence entre les directions de deux vecteurs. L' emprunte ce concept pour mesurer la différence entre des vecteurs échantillons.
(1) La formule cosinus de l'angle entre le vecteur A(x1, y1) et le vecteur B(x2, y2) dans l'espace bidimensionnel : 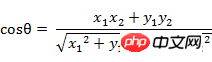
(2) Deux n dimensions points d'échantillonnage Le cosinus de l'angle entre a(x11,x12,…,x1n) et b(x21,x22,…,x2n)
De même, pour deux points d'échantillonnage à n dimensions a(x11,x12,…,x1n ) et b (x21,x22,…,x2n), vous pouvez utiliser un concept similaire au cosinus de l'angle pour mesurer le degré de similarité entre eux. 
C'est-à-dire : 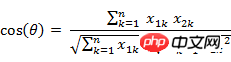
La plage de valeurs du cosinus est [-1,1]. Trouvez l'angle entre les deux vecteurs et obtenez la valeur du cosinus correspondant à l'angle. Cette valeur du cosinus peut être utilisée pour caractériser la similarité des deux vecteurs. Plus l'angle est petit, proche de 0 degré, plus la valeur du cosinus est proche de 1, et plus leurs directions sont cohérentes, plus elles sont similaires. Lorsque les directions de deux vecteurs sont complètement opposées, le cosinus de l'angle qui les sépare prend la valeur minimale -1. Lorsque la valeur du cosinus est 0, les deux vecteurs sont orthogonaux et l'angle inclus est de 90 degrés. Par conséquent, on peut voir que la similarité cosinusoïdale n’a rien à voir avec la norme du vecteur, mais seulement avec la direction du vecteur.
import numpy as np x=np.random.random(10) y=np.random.random(10)#方法一:根据公式求解d1=np.dot(x,y)/(np.linalg.norm(x)*np.linalg.norm(y))#方法二:根据scipy库求解from scipy.spatial.distance import pdist X=np.vstack([x,y]) d2=1-pdist(X,'cosine')
两个向量完全相等时,余弦值为1,如下的代码计算出来的d=1。
d=1-pdist([x,x],'cosine')
8. 皮尔逊相关系数(Pearson correlation)
(1) 皮尔逊相关系数的定义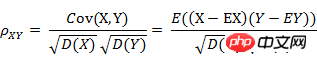
La similarité cosinus mentionnée précédemment n'est liée qu'à la direction du vecteur, mais elle sera affectée par la translation du vecteur dans la formule de l'angle cosinus, si x. est traduit en x+ 1, la valeur du cosinus changera. Comment obtenir l’invariance de traduction ? Cela nécessite l'utilisation du coefficient de corrélation de Pearson (corrélation de Pearson), parfois aussi directement appelé coefficient de corrélation .
Si la formule de l'angle cosinus s'écrit :
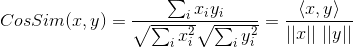
représente le cosinus de l'angle entre le vecteur x et le vecteur y, alors le le coefficient de corrélation de Pearson peut s'exprimer comme :
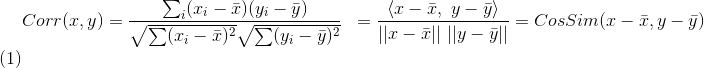
皮尔逊相关系数具有平移不变性和尺度不变性,计算出了两个向量(维度)的相关性。
在python中的实现:
import numpy as np x=np.random.random(10) y=np.random.random(10)#方法一:根据公式求解x_=x-np.mean(x) y_=y-np.mean(y) d1=np.dot(x_,y_)/(np.linalg.norm(x_)*np.linalg.norm(y_))#方法二:根据numpy库求解X=np.vstack([x,y]) d2=np.corrcoef(X)[0][1]
Le coefficient de corrélation est une méthode de mesure de la corrélation entre les variables aléatoires X et Y. La plage de valeurs du coefficient de corrélation est [-1,1]. Plus la valeur absolue du coefficient de corrélation est grande, plus la corrélation entre X et Y est élevée. Lorsque X et Y sont liés linéairement, le coefficient de corrélation prend la valeur 1 (corrélation linéaire positive) ou -1 (corrélation linéaire négative).
9. Distance de Hamming (Distance de Hamming)
(1) La définition de la distance de Hamming
Deux égales Le Hamming la distance entre les longues chaînes s1 et s2 est définie comme le nombre minimum de substitutions requises pour passer de l'une à l'autre. Par exemple, la distance de Hamming entre les chaînes « 1111 » et « 1001 » est de 2.
Application : codage d'informations (afin d'améliorer la tolérance aux pannes, la distance minimale de Hamming entre les codes doit être aussi grande que possible).
Implémentation en python :
import numpy as npfrom scipy.spatial.distance import pdist x=np.random.random(10)>0.5y=np.random.random(10)>0.5x=np.asarray(x,np.int32) y=np.asarray(y,np.int32)#方法一:根据公式求解d1=np.mean(x!=y)#方法二:根据scipy库求解X=np.vstack([x,y]) d2=pdist(X,'hamming')
10. 杰卡德相似系数(Jaccard similarity coefficient)
(1) 杰卡德相似系数
两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示。
杰卡德相似系数是衡量两个集合的相似度一种指标。
(2) 杰卡德距离
与杰卡德相似系数相反的概念是杰卡德距离(Jaccard distance)。杰卡德距离可用如下公式表示: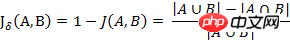
杰卡德距离用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度。
(3) 杰卡德相似系数与杰卡德距离的应用
可将杰卡德相似系数用在衡量样本的相似度上。
样本A与样本B是两个n维向量,而且所有维度的取值都是0或1。例如:A(0111)和B(1011)。我们将样本看成是一个集合,1表示集合包含该元素,0表示集合不包含该元素。
在python中的实现:
import numpy as npfrom scipy.spatial.distance import pdist x=np.random.random(10)>0.5y=np.random.random(10)>0.5x=np.asarray(x,np.int32) y=np.asarray(y,np.int32)#方法一:根据公式求解up=np.double(np.bitwise_and((x != y),np.bitwise_or(x != 0, y != 0)).sum()) down=np.double(np.bitwise_or(x != 0, y != 0).sum()) d1=(up/down) #方法二:根据scipy库求解X=np.vstack([x,y]) d2=pdist(X,'jaccard')
11. 布雷柯蒂斯距离(Bray Curtis Distance)
Bray Curtis距离主要用于生态学和环境科学,计算坐标之间的距离。该距离取值在[0,1]之间。它也可以用来计算样本之间的差异。
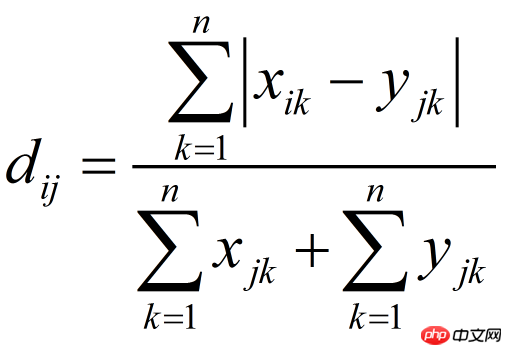
Échantillon de données :
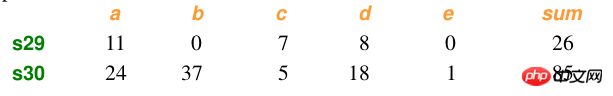
Calcul :
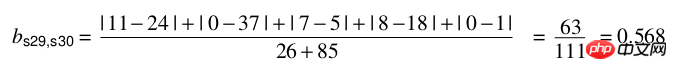
Implémentation en python :
import numpy as npfrom scipy.spatial.distance import pdist x=np.array([11,0,7,8,0]) y=np.array([24,37,5,18,1])#方法一:根据公式求解up=np.sum(np.abs(y-x)) down=np.sum(x)+np.sum(y) d1=(up/down) #方法二:根据scipy库求解X=np.vstack([x,y]) d2=pdist(X,'braycurtis')
相关推荐:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



