
 développement back-end
Tutoriel Python
Enregistrement complet de l'écriture de robots d'exploration Python à partir de scratch_python
développement back-end
Tutoriel Python
Enregistrement complet de l'écriture de robots d'exploration Python à partir de scratch_python
Enregistrement complet de l'écriture de robots d'exploration Python à partir de scratch_python

Les neuf premiers articles ont été présentés en détail, des bases à l'écriture. Le dixième article concerne la perfection, alors enregistrons en détail comment écrire un programme d'exploration étape par étape. Veuillez le lire. >
Parlons d'abord du site Web de notre école :http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.htmlVérifier les résultats Vous devez vous connecter , puis les résultats de chaque matière sont affichés, mais seuls les résultats sont affichés sans les notes, qui sont la note moyenne pondérée.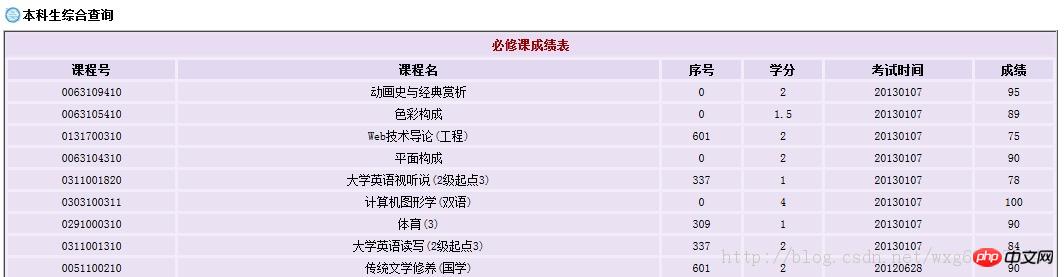
1. La veille de la bataille décisive
Préparons d'abord un outil : le plug-in HttpFox. Il s'agit d'un plug-in d'analyse du protocole http qui analyse l'heure et le contenu des requêtes et des réponses des pages, ainsi que le COOKIE utilisé par le navigateur.
2. Allez au plus profond des lignes ennemies

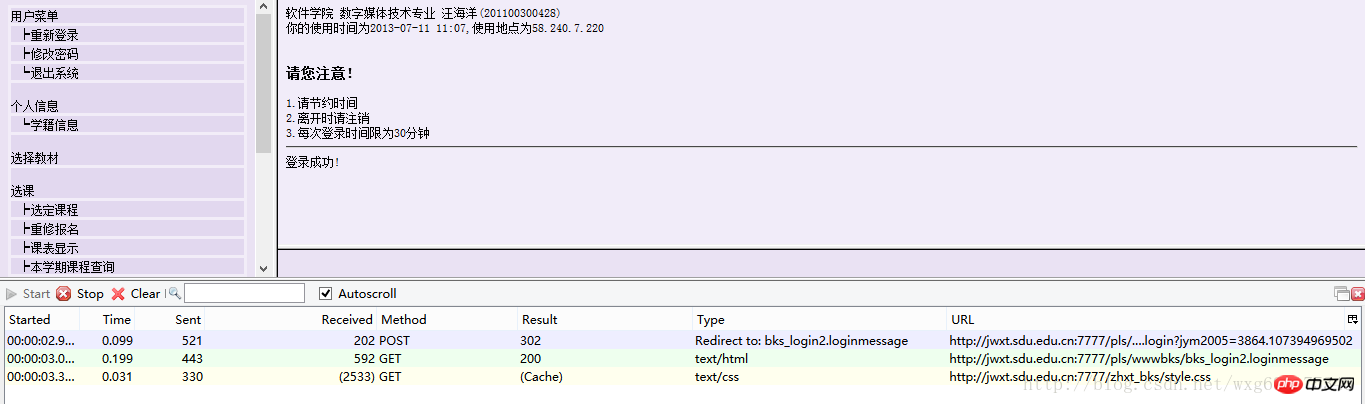
3. Hu Ding Jie Niu
À première vue, nous avons trois données, deux sont GET et une est POST, mais que sont-elles exactement ? ça, on ne le sait toujours pas. Nous devons donc examiner le contenu capturé un par un. Regardez d'abord les informations POST :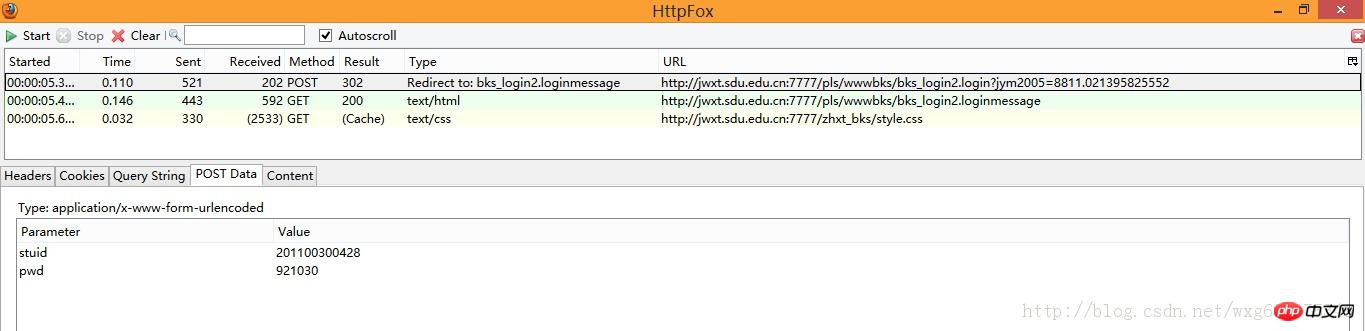
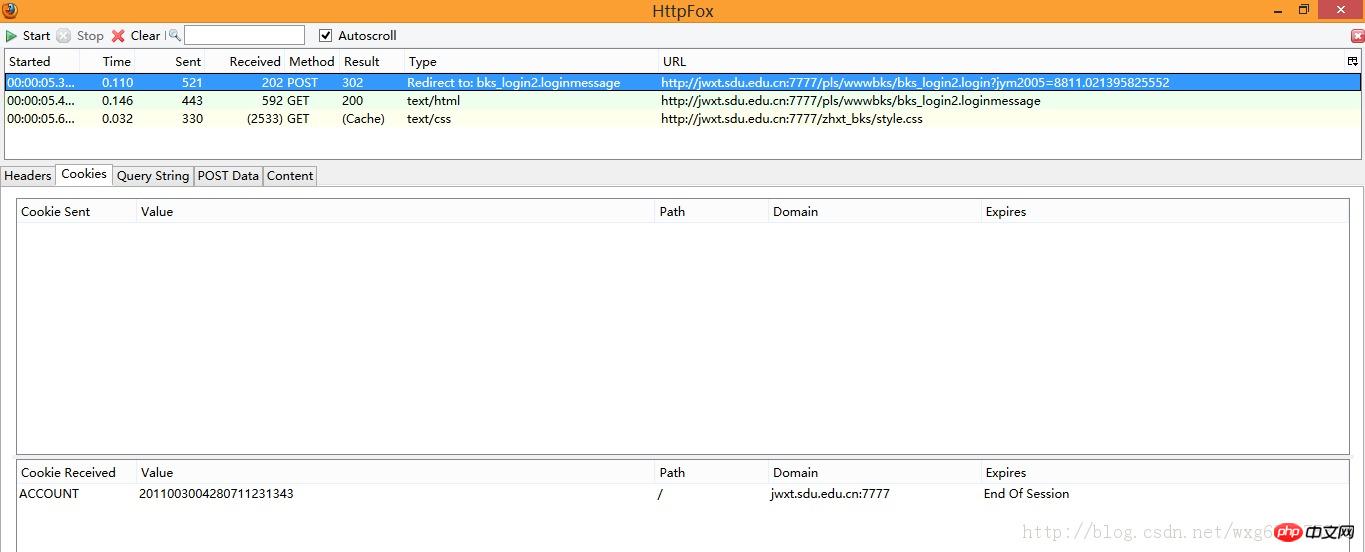
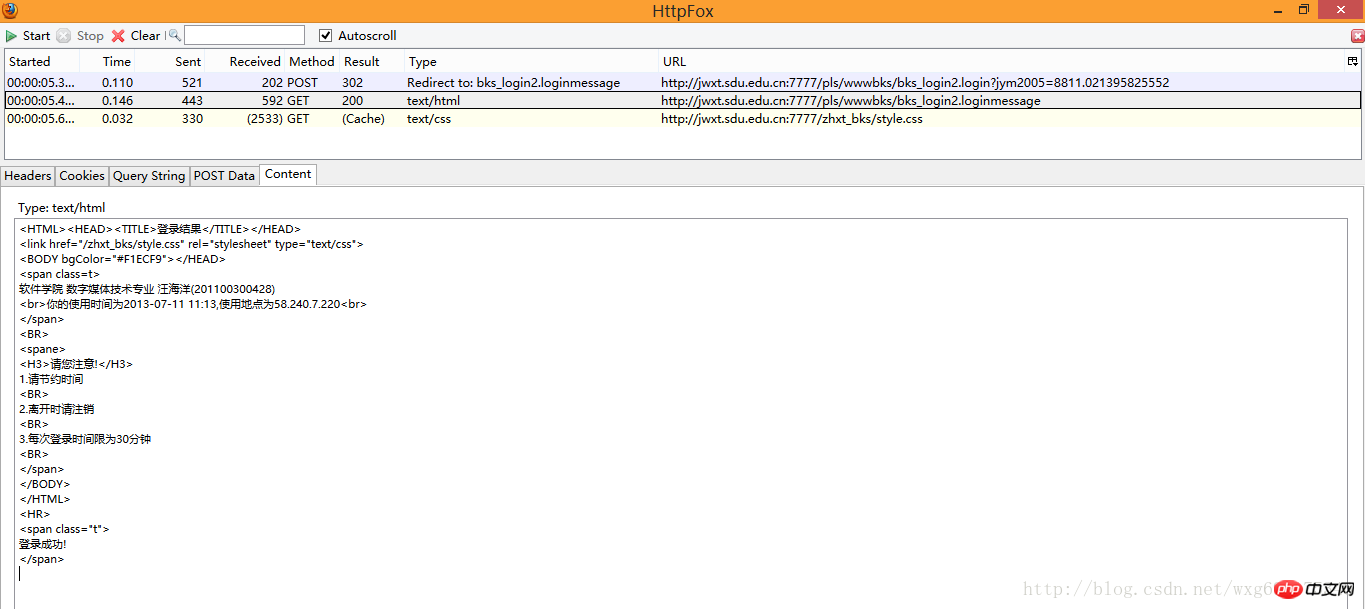
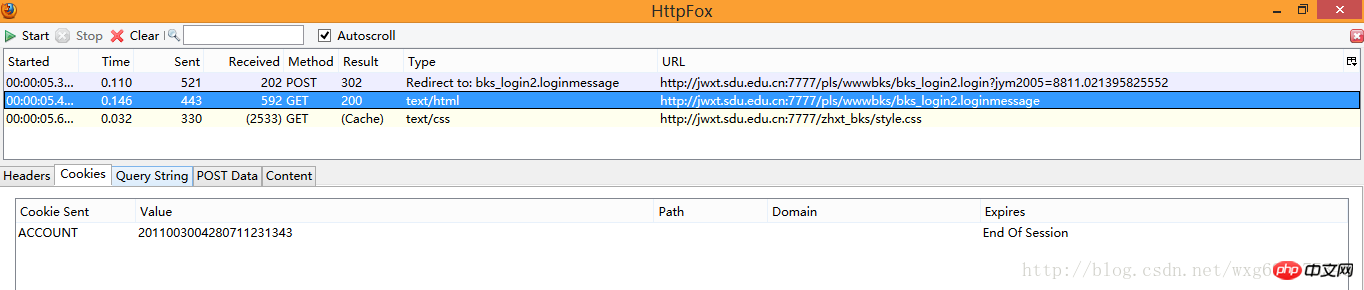
4. Répondez calmement

Évidemment, il est implémenté à l'aide d'un framework html, c'est-à-dire que l'adresse que nous voyons dans la barre d'adresse n'est pas l'adresse de soumission du formulaire à droite.
Alors, comment puis-je obtenir la vraie adresse -. -Cliquez avec le bouton droit pour afficher le code source de la page :
Oui, c'est vrai, celle avec name="w_right" est la page de connexion que nous voulons.
L'adresse originale du site Web est :
http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html
Donc, la forme réelle soumission L'adresse doit être :
http://jwxt.sdu.edu.cn:7777/zhxt_bks/xk_login.html
Après l'avoir saisie, il s'avère qu'elle est comme prévu :
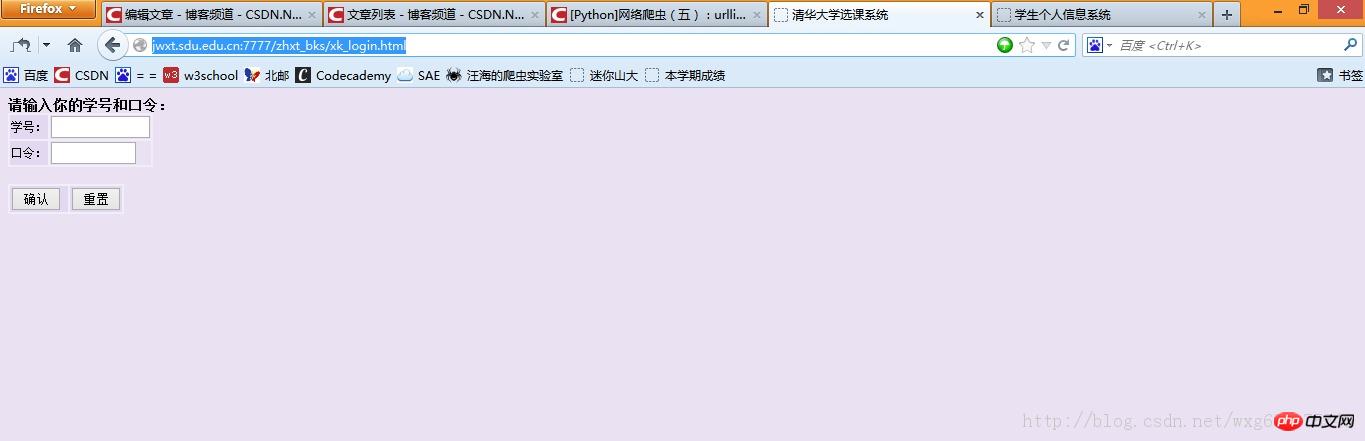
Merde, c'est le système de sélection de cours de l'Université Tsinghua. . . Je suppose que notre école était trop paresseuse pour créer une page, alors nous l'avons simplement empruntée. . En conséquence, le titre n’a même pas été modifié. . .
Mais cette page n'est toujours pas la page dont nous avons besoin, car la page à laquelle nos données POST sont soumises devrait être la page soumise dans l'ACTION du formulaire.
En d'autres termes, nous devons vérifier le code source pour savoir où les données POST sont envoyées :
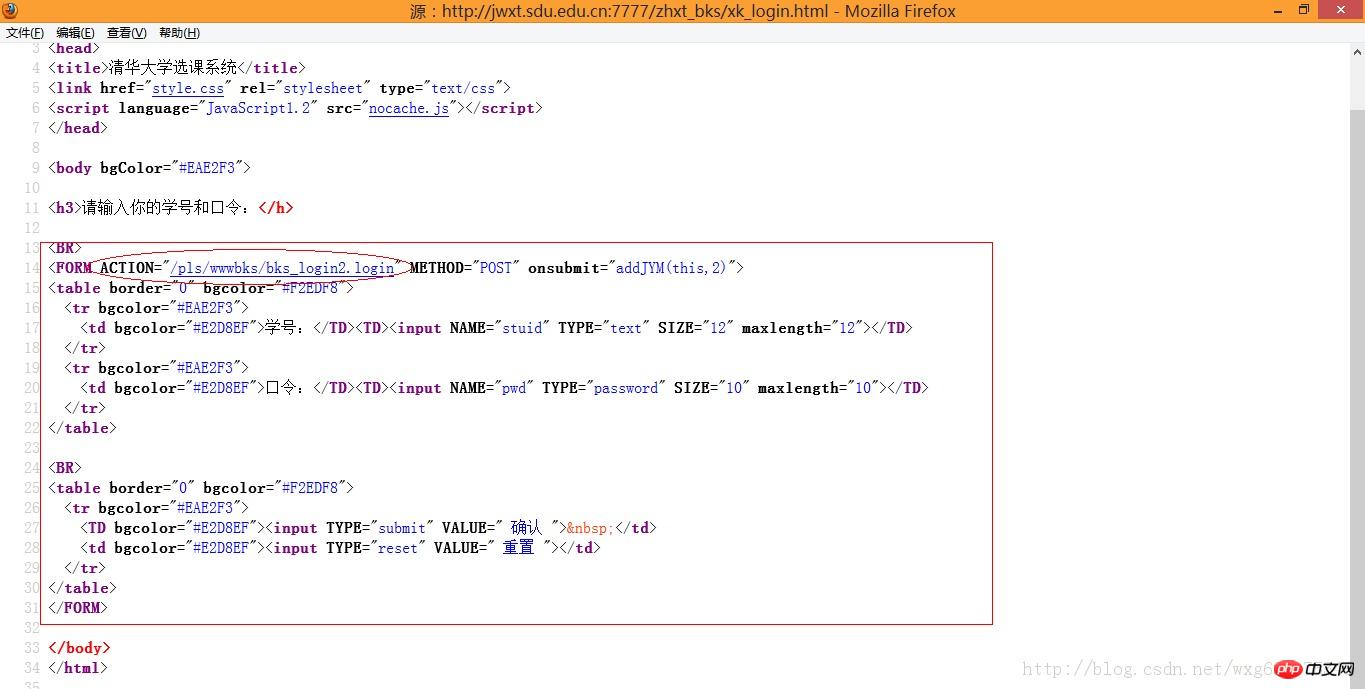
Eh bien, visuellement, c'est le Soumission POST L’adresse des données.
Organisez-le dans la barre d'adresse. L'adresse complète doit être la suivante :
http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login
(La façon de l'obtenir est très simple, cliquez sur le lien directement dans le navigateur Firefox pour voir l'adresse du lien)
5. d'une petite manière
La tâche suivante consiste à utiliser python pour simuler l'envoi de données POST et obtenir la valeur du cookie renvoyée.
Pour le fonctionnement des cookies, vous pouvez lire cet article de blog :
http://www.jb51.net/article/57144.htm
Nous préparons dans un premier temps un POST les données, préparez un cookie à recevoir, puis écrivez le code source comme suit :
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
#需要POST的数据#
postdata=urllib.urlencode({
'stuid':'201100300428',
'pwd':'921030'
})
#自定义一个请求#
req = urllib2.Request(
url = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login',
data = postdata
)
#访问该链接#
result = opener.open(req)
#打印返回的内容#
print result.read()Après cela, regardez l'effet de l'opération :
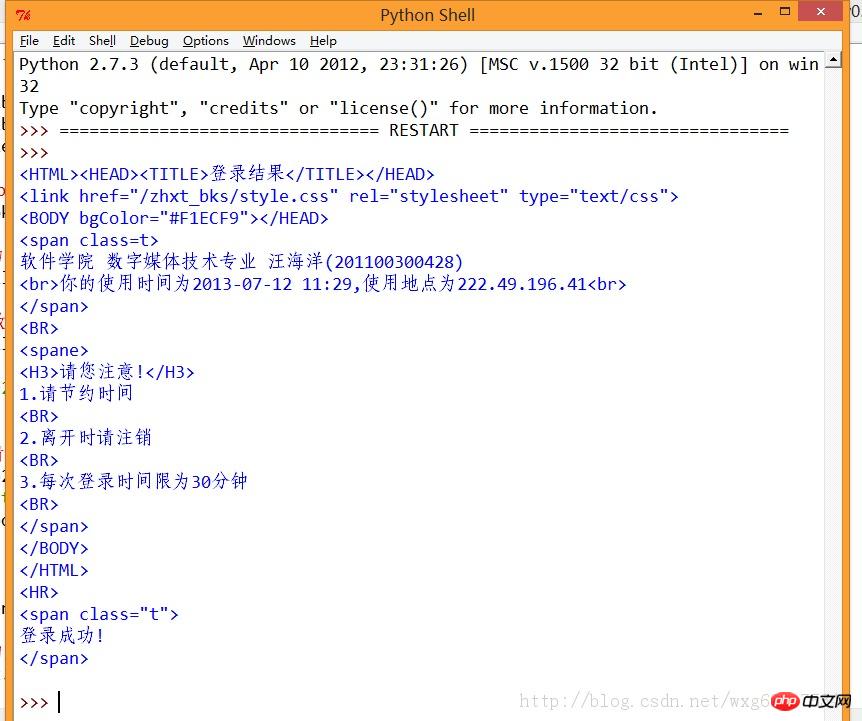
ok, de cette façon, nous avons simulé avec succès la connexion.
6. Remplacer une chose par une autre
La tâche suivante consiste à utiliser un robot pour obtenir les scores des élèves.
Regardons à nouveau le site Web source.
Après avoir activé HTTPFOX, cliquez pour afficher les résultats et constatez que les données suivantes ont été capturées :
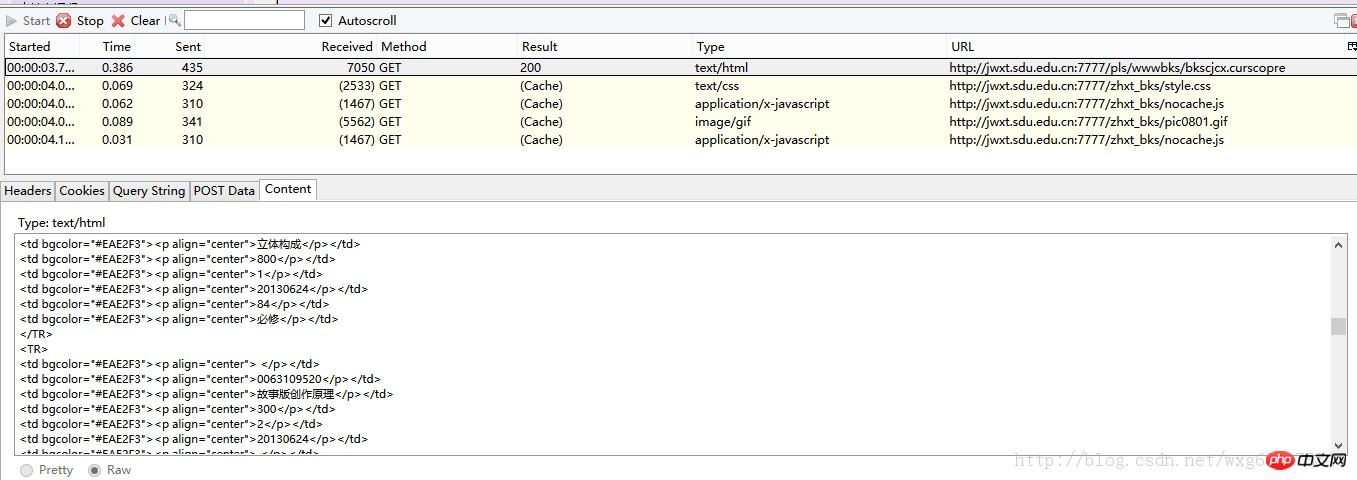
Cliquez sur la première donnée GET pour visualiser le contenu. On constate que le Contenu est le contenu de la partition obtenue.
Pour le lien de page obtenu, faites un clic droit pour afficher l'élément du code source de la page, et vous pourrez voir la page qui saute après avoir cliqué sur le lien (dans Firefox, il vous suffit de faire un clic droit et " Voir ce cadre". ):
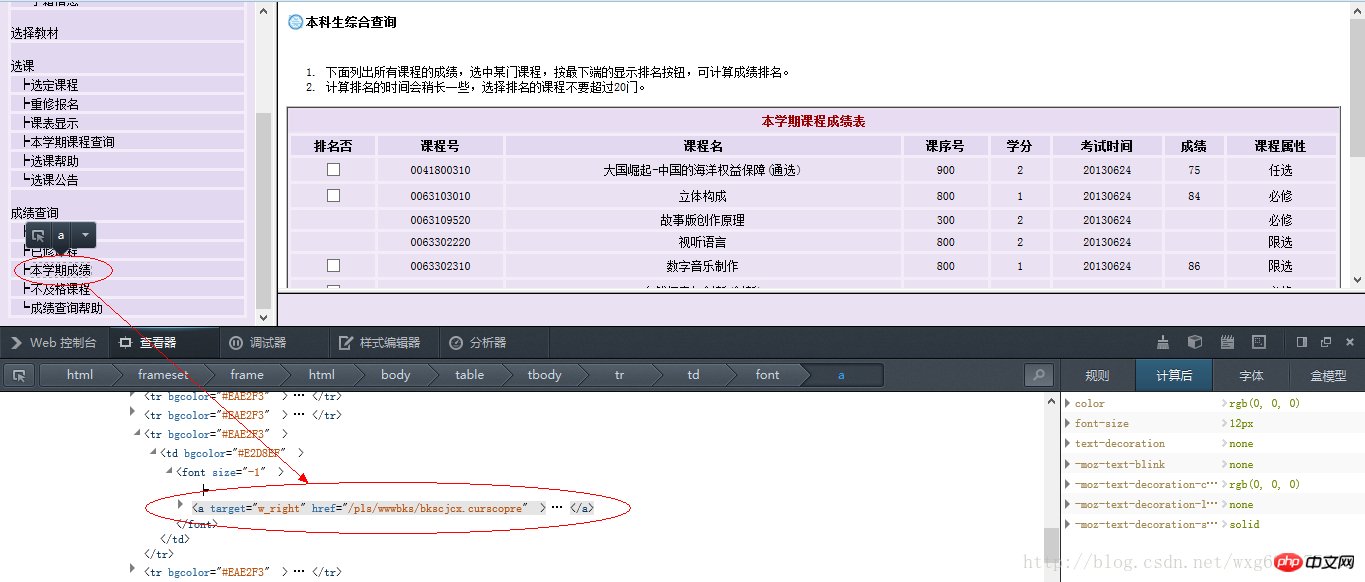
Vous pouvez obtenir le lien pour afficher les résultats comme suit :
http://jwxt .sdu.edu.cn : 7777/pls/wwwbks/bkscjcx.curscopre
7. Tout est prêt
Maintenant, tout est prêt, alors postulez simplement le lien vers le robot d'exploration, voyez si vous pouvez afficher la page de résultats.
Comme vous pouvez le voir sur httpfox, nous devons envoyer un cookie pour renvoyer les informations de score, nous utilisons donc python pour simuler l'envoi d'un cookie pour demander les informations de score :
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
#初始化一个CookieJar来处理Cookie的信息#
cookie = cookielib.CookieJar()
#创建一个新的opener来使用我们的CookieJar#
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
#需要POST的数据#
postdata=urllib.urlencode({
'stuid':'201100300428',
'pwd':'921030'
})
#自定义一个请求#
req = urllib2.Request(
url = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login',
data = postdata
)
#访问该链接#
result = opener.open(req)
#打印返回的内容#
print result.read()
#打印cookie的值
for item in cookie:
print 'Cookie:Name = '+item.name
print 'Cookie:Value = '+item.value
#访问该链接#
result = opener.open('http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre')
#打印返回的内容#
print result.read()Appuyez sur F5 pour exécuter et jeter un œil aux données capturées :

Comme il n'y a pas de problème de cette manière, utilisez des expressions régulières pour convertir légèrement les données. traitez-le et retirez les crédits et les scores correspondants.
8. Obtenez-le à portée de main
Une telle quantité de code source HTML n'est évidemment pas propice à notre traitement. Nous utiliserons des expressions régulières pour. extraire les données nécessaires.
Pour des tutoriels sur les expressions régulières, vous pouvez consulter ce billet de blog :
http://www.jb51.net/article/57150.htm
Prenons un regardez les résultats Le code source :
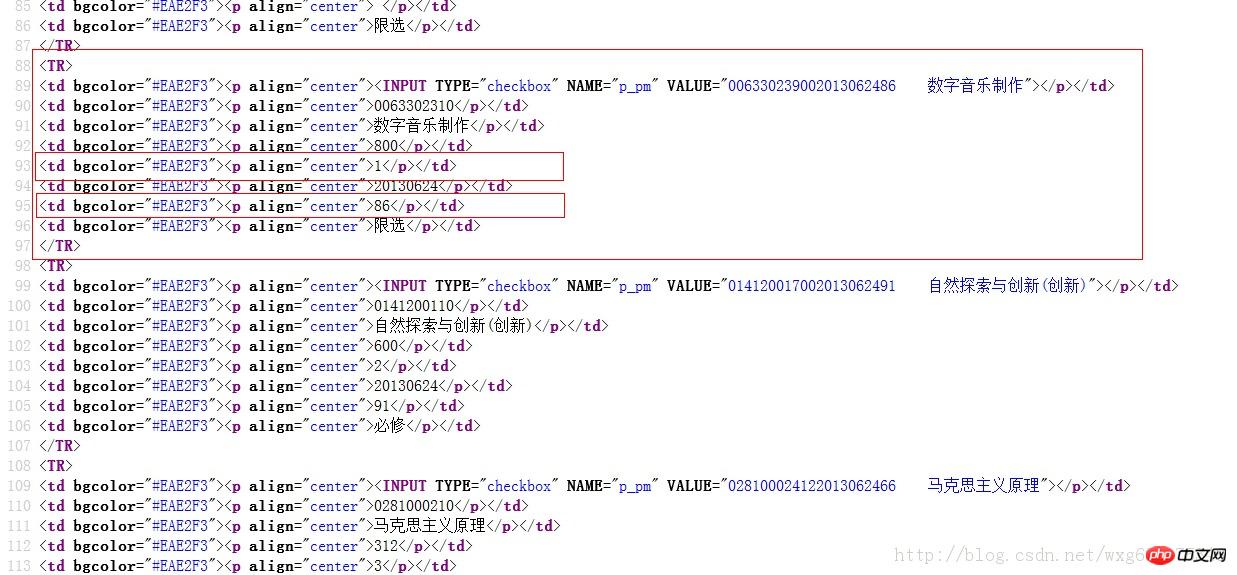
Dans ce cas, utiliser des expressions régulières est simple.
Nous allons ranger un peu le code, puis utiliser des expressions régulières pour extraire les données :
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
import re
class SDU_Spider:
# 申明相关的属性
def __init__(self):
self.loginUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login' # 登录的url
self.resultUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre' # 显示成绩的url
self.cookieJar = cookielib.CookieJar() # 初始化一个CookieJar来处理Cookie的信息
self.postdata=urllib.urlencode({'stuid':'201100300428','pwd':'921030'}) # POST的数据
self.weights = [] #存储权重,也就是学分
self.points = [] #存储分数,也就是成绩
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookieJar))
def sdu_init(self):
# 初始化链接并且获取cookie
myRequest = urllib2.Request(url = self.loginUrl,data = self.postdata) # 自定义一个请求
result = self.opener.open(myRequest) # 访问登录页面,获取到必须的cookie的值
result = self.opener.open(self.resultUrl) # 访问成绩页面,获得成绩的数据
# 打印返回的内容
# print result.read()
self.deal_data(result.read().decode('gbk'))
self.print_data(self.weights);
self.print_data(self.points);
# 将内容从页面代码中抠出来
def deal_data(self,myPage):
myItems = re.findall('<TR>.*?<p.*?<p.*?<p.*?<p.*?<p.*?>(.*?)</p>.*?<p.*?<p.*?>(.*?)</p>.*?</TR>',myPage,re.S) #获取到学分
for item in myItems:
self.weights.append(item[0].encode('gbk'))
self.points.append(item[1].encode('gbk'))
# 将内容从页面代码中抠出来
def print_data(self,items):
for item in items:
print item
#调用
mySpider = SDU_Spider()
mySpider.sdu_init()Le niveau est limité, et les expressions régulières sont un peu laides. L'effet de course est comme le montre la figure :
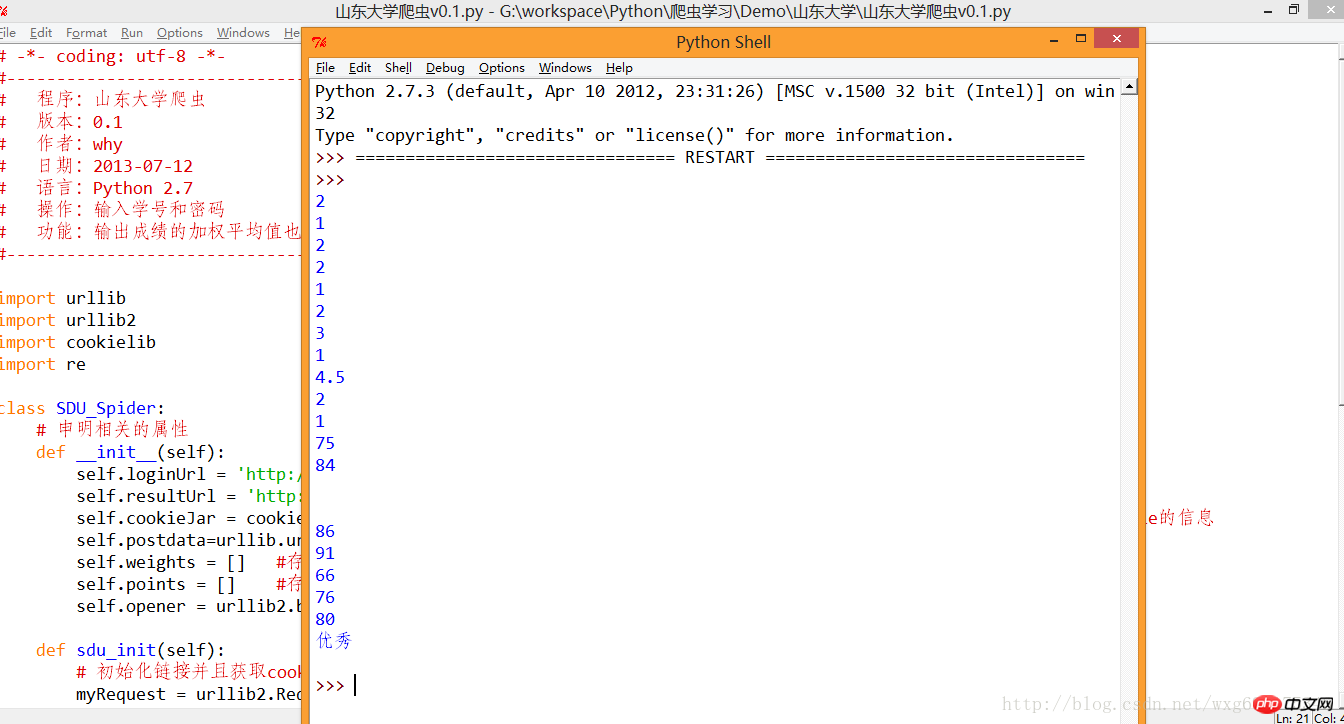
ok, la prochaine chose est juste le problème de traitement des données. .
9. Retour en triomphe
Le code complet est le suivant À ce stade, un projet de robot complet est terminé.
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
import re
import string
class SDU_Spider:
# 申明相关的属性
def __init__(self):
self.loginUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login' # 登录的url
self.resultUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre' # 显示成绩的url
self.cookieJar = cookielib.CookieJar() # 初始化一个CookieJar来处理Cookie的信息
self.postdata=urllib.urlencode({'stuid':'201100300428','pwd':'921030'}) # POST的数据
self.weights = [] #存储权重,也就是学分
self.points = [] #存储分数,也就是成绩
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookieJar))
def sdu_init(self):
# 初始化链接并且获取cookie
myRequest = urllib2.Request(url = self.loginUrl,data = self.postdata) # 自定义一个请求
result = self.opener.open(myRequest) # 访问登录页面,获取到必须的cookie的值
result = self.opener.open(self.resultUrl) # 访问成绩页面,获得成绩的数据
# 打印返回的内容
# print result.read()
self.deal_data(result.read().decode('gbk'))
self.calculate_date();
# 将内容从页面代码中抠出来
def deal_data(self,myPage):
myItems = re.findall('<TR>.*?<p.*?<p.*?<p.*?<p.*?<p.*?>(.*?)</p>.*?<p.*?<p.*?>(.*?)</p>.*?</TR>',myPage,re.S) #获取到学分
for item in myItems:
self.weights.append(item[0].encode('gbk'))
self.points.append(item[1].encode('gbk'))
#计算绩点,如果成绩还没出来,或者成绩是优秀良好,就不运算该成绩
def calculate_date(self):
point = 0.0
weight = 0.0
for i in range(len(self.points)):
if(self.points[i].isdigit()):
point += string.atof(self.points[i])*string.atof(self.weights[i])
weight += string.atof(self.weights[i])
print point/weight
#调用
mySpider = SDU_Spider()
mySpider.sdu_init()Recommandations associées :
Comment utiliser le robot d'exploration Python pour obtenir ces précieux articles de blog
Exemple de partage de robot d'exploration dynamique python
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: Une base de données Python évolutive de haut niveau légère HaDIDB (HaDIDB) est une base de données légère écrite en Python, avec un niveau élevé d'évolutivité. Installez HaDIDB à l'aide de l'installation PIP: PiPinStallHaDIDB User Management Créer un utilisateur: CreateUser () pour créer un nouvel utilisateur. La méthode Authentication () authentifie l'identité de l'utilisateur. FromHadidb.OperationMportUserUser_OBJ = User ("Admin", "Admin") User_OBJ.
 Python: Explorer ses applications principales
Apr 10, 2025 am 09:41 AM
Python: Explorer ses applications principales
Apr 10, 2025 am 09:41 AM
Python est largement utilisé dans les domaines du développement Web, de la science des données, de l'apprentissage automatique, de l'automatisation et des scripts. 1) Dans le développement Web, les cadres Django et Flask simplifient le processus de développement. 2) Dans les domaines de la science des données et de l'apprentissage automatique, les bibliothèques Numpy, Pandas, Scikit-Learn et Tensorflow fournissent un fort soutien. 3) En termes d'automatisation et de script, Python convient aux tâches telles que les tests automatisés et la gestion du système.
 Le plan Python de 2 heures: une approche réaliste
Apr 11, 2025 am 12:04 AM
Le plan Python de 2 heures: une approche réaliste
Apr 11, 2025 am 12:04 AM
Vous pouvez apprendre les concepts de programmation de base et les compétences de Python dans les 2 heures. 1. Apprenez les variables et les types de données, 2. Flux de contrôle maître (instructions et boucles conditionnelles), 3. Comprenez la définition et l'utilisation des fonctions, 4. Démarrez rapidement avec la programmation Python via des exemples simples et des extraits de code.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
En tant que professionnel des données, vous devez traiter de grandes quantités de données provenant de diverses sources. Cela peut poser des défis à la gestion et à l'analyse des données. Heureusement, deux services AWS peuvent aider: AWS Glue et Amazon Athena.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Les étapes pour démarrer un serveur Redis incluent: Installez Redis en fonction du système d'exploitation. Démarrez le service Redis via Redis-Server (Linux / MacOS) ou Redis-Server.exe (Windows). Utilisez la commande redis-Cli Ping (Linux / MacOS) ou redis-Cli.exe Ping (Windows) pour vérifier l'état du service. Utilisez un client redis, tel que redis-cli, python ou node.js pour accéder au serveur.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
