

Le contenu de cet article concerne l'exploration et l'analyse des données des utilisateurs Zhihu au niveau d'un million par le robot d'exploration PHP. Il a une certaine valeur de référence. Maintenant, je le partage avec vous. Les amis dans le besoin peuvent s'y référer
.
Cet article présente principalement des informations pertinentes sur l'exploration et l'analyse des données utilisateur Zhihu au niveau d'un million de PHP. Les amis qui en ont besoin peuvent se référer au. suivant
Préparation avant développement
Installation du système Linux (Ubuntu14 .04 ), installez un Ubuntu sous la machine virtuelle VMWare
Installez PHP5.6 ou supérieur ; >
L'extension curl de PHP est prise en charge par PHP et vous permet d'interagir avec des bibliothèques permettant à différents serveurs de se connecter et de communiquer en utilisant différents types de protocoles.
Ce programme capture les données utilisateur de Zhihu Pour pouvoir accéder à la page personnelle de l'utilisateur, celui-ci doit être connecté avant d'y accéder. Lorsque nous cliquons sur un lien d'avatar d'utilisateur sur la page du navigateur pour accéder à la page du centre personnel de l'utilisateur, la raison pour laquelle nous pouvons voir les informations de l'utilisateur est que lorsque nous cliquons sur le lien, le navigateur vous aide à rassembler les cookies locaux et à les soumettre ensemble. vers une nouvelle page, afin que vous puissiez accéder à la page du centre personnel de l'utilisateur. Par conséquent, avant d'accéder à la page personnelle, vous devez obtenir les informations sur les cookies de l'utilisateur, puis apporter les informations sur les cookies à chaque demande curl. Pour obtenir des informations sur les cookies, j'ai utilisé mon propre cookie. Vous pouvez voir vos informations sur les cookies sur la page :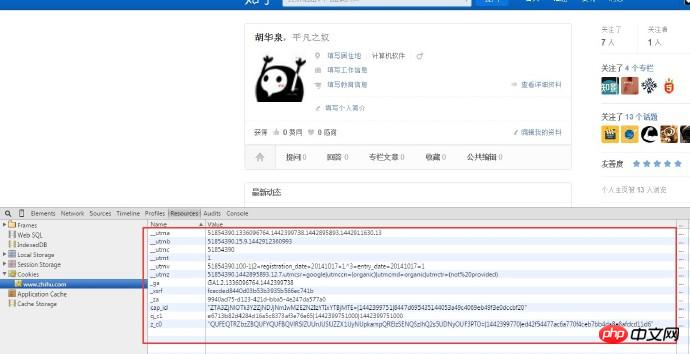 . Copiez-les un par un pour former une chaîne de cookie sous la forme "__utma=?;__utmb=?;". Cette chaîne de cookie peut ensuite être utilisée pour envoyer des demandes.
. Copiez-les un par un pour former une chaîne de cookie sous la forme "__utma=?;__utmb=?;". Cette chaîne de cookie peut ensuite être utilisée pour envoyer des demandes.
|
1 2 3 4 5 6 7 8 9 |
$url = 'http://www.zhihu.com/people/mora-hu/about'; //此处mora-hu代表用户ID $ch = curl_init($url); //初始化会话 curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_COOKIE, $this->config_arr['user_cookie']); //设置请求COOKIE curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //将curl_exec()获取的信息以文件流的形式返回,而不是直接输出。 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $result = curl_exec($ch); return $result; //抓取的结果 Copier après la connexion |
Exécutez le code ci-dessus pour obtenir la page du centre personnel de l'utilisateur mora-hu. En utilisant ce résultat, puis en utilisant des expressions régulières pour traiter la page, vous pouvez obtenir le nom, le sexe et d'autres informations que vous devez capturer.
1. Anti-hotlinking pour les images
Lors de la régularisation des résultats renvoyés et de la sortie des informations personnelles, il a été constaté que l'avatar de l'utilisateur était affiché. sur la page ne peut pas être ouvert. Après avoir examiné les informations, j'ai découvert que c'était parce que Zhihu avait protégé les images contre les hotlinks. La solution est de forger un référent dans l'en-tête de la requête lors de la demande d'une image.
Après avoir utilisé l'expression régulière pour obtenir le lien vers l'image, envoyez une autre demande Cette fois, apportez la source de la demande d'image, en indiquant que la demande est transmise depuis le site Zhihu. Des exemples spécifiques sont les suivants :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | function getImg($url, $u_id)
{
if (file_exists('./images/' . $u_id . ".jpg"))
{
return "images/$u_id" . '.jpg';
}
if (empty($url))
{
return '';
}
$context_options = array(
'http' =>
array(
'header' => "Referer:http://www.zhihu.com"//带上referer参数
)
);
$context = stream_context_create($context_options);
$img = file_get_contents('http:' . $url, FALSE, $context);
file_put_contents('./images/' . $u_id . ".jpg", $img);
return "images/$u_id" . '.jpg';
}Copier après la connexion |
2. Explorez plus d'utilisateurs
Après avoir récupéré vos informations personnelles, vous devez accéder aux abonnés de l'utilisateur et à la liste des utilisateurs suivis pour obtenir plus d'informations sur les utilisateurs. Visitez ensuite couche par couche. Vous pouvez voir que dans la page du centre personnel, il y a deux liens comme suit :
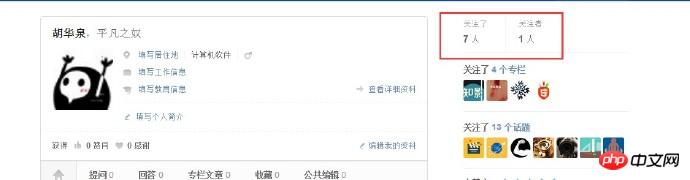
Il y a deux liens ici, l'un pour suivre, l'autre pour les abonnés, avec " Lien "Suivre" à titre d'exemple. Utilisez une correspondance régulière pour faire correspondre le lien correspondant. Après avoir obtenu l'URL, utilisez curl pour apporter le cookie et envoyer une autre demande. Après avoir parcouru la page de liste que l'utilisateur a suivie, vous pouvez obtenir la page suivante :
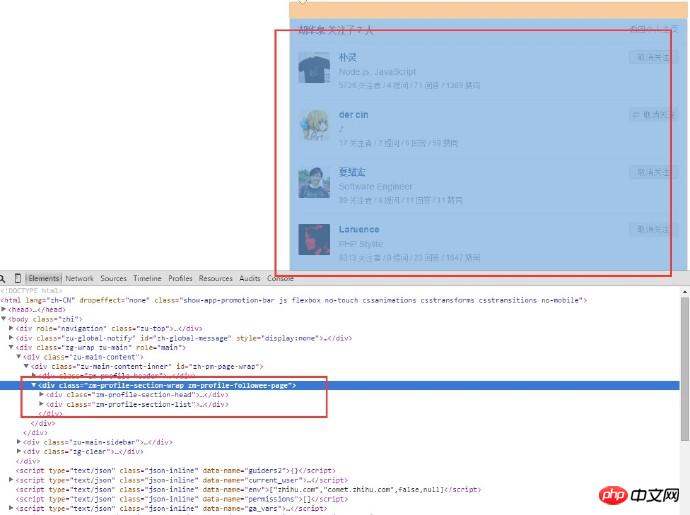
Analyser le html du Structure de la page, parce que nous n'avons besoin que d'obtenir les informations de l'utilisateur, nous n'avons besoin que d'encadrer le contenu p de cette pièce, et le nom de l'utilisateur est entièrement dedans. On peut voir que l'URL de la page que suit l'utilisateur est :

L'URL des différents utilisateurs est presque la même, la différence réside dans le nom d'utilisateur. Utilisez une correspondance régulière pour obtenir la liste des noms d'utilisateur, épelez les URL une par une, puis envoyez les requêtes une par une (bien sûr, une par une est plus lente, il existe une solution ci-dessous, qui sera discutée plus tard). Après être entré dans la page du nouvel utilisateur, répétez les étapes ci-dessus et continuez dans cette boucle jusqu'à ce que vous atteigniez la quantité de données souhaitée.
3. Nombre de fichiers statistiques Linux
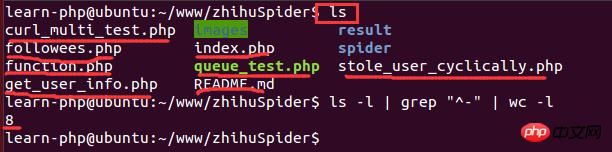
Une fois le script exécuté pendant un certain temps, vous devez voir combien d'images ont été obtenu. Lors de la comparaison de la quantité de données Lorsqu'elle est volumineuse, il est un peu lent d'ouvrir le dossier et d'afficher le nombre d'images. Le script est exécuté dans l'environnement Linux, vous pouvez donc utiliser les commandes Linux pour compter le nombre de fichiers :
1 | ls-l | grep"^-"wc -l Copier après la connexion |
Parmi eux, ls -l est une longue liste d'informations de fichier dans le répertoire (les fichiers ici peuvent être des répertoires, des liens, des fichiers de périphérique, etc.) ; grep "^-" filtre les informations de sortie de longue liste, " ^-" ne conserve que Pour les fichiers généraux, si seul le répertoire est conservé, il s'agit de "^d" ; wc -l est le nombre de lignes d'informations de sortie statistique. Voici un exemple fonctionnel :
4. Traitement des données en double lors de l'insertion dans MySQL
Programme en cours d'exécution Après un certain temps, il a été constaté que de nombreuses données utilisateur étaient dupliquées, elles devaient donc être traitées lors de l'insertion de données utilisateur en double. La solution est la suivante :
1) Vérifiez si les données existent déjà dans la base de données avant de les insérer dans la base de données
2) Ajoutez un index unique et utilisez INSERT INTO...ON DUPLICATE ; KEY UPDATE...
3) Ajoutez un index unique, utilisez INSERT INGNORE INTO lors de l'insertion...
4) Ajoutez un index unique, utilisez REPLACE INTO lors de l'insertion...
La première solution C'est la solution la plus simple mais aussi la moins efficace, elle n'est donc pas adoptée. Les résultats d'exécution des deuxième et quatrième solutions sont les mêmes. La différence est que lorsque vous rencontrez les mêmes données, INSERT INTO ... ON DUPLICATE KEY UPDATE est mis à jour directement, tandis que REPLACE INTO supprime d'abord les anciennes données puis insère la nouvelle. . Au cours de ce processus, l'index doit également être maintenu, la vitesse est donc lente. J'ai donc choisi la deuxième option entre deux et quatre. La troisième option, INSERT INGNORE, ignorera les erreurs qui se produisent lors de l'exécution de l'instruction INSERT et n'ignorera pas les problèmes de syntaxe, mais ignorera l'existence de la clé primaire. Dans ce cas, il est préférable d'utiliser INSERT INGNORE. Finalement, compte tenu du nombre de données en double à enregistrer dans la base de données, la deuxième solution a été retenue dans le programme.
5. Utilisez curl_multi pour réaliser une capture de page multithread
Au début, un seul processus et une seule boucle étaient utilisés pour capturer données, ce qui était très lent. Après avoir raccroché et exploré toute la nuit, je n'ai pu capturer que 2 W de données, j'ai donc réfléchi à la possibilité de demander plusieurs utilisateurs à la fois lorsque j'entrais dans une nouvelle page utilisateur et que je faisais une demande curl. la bonne chose curl_multi. Des fonctions telles que curl_multi peuvent demander plusieurs URL en même temps au lieu de les demander une par une. Ceci est similaire à la fonction d'un processus dans le système Linux pour ouvrir plusieurs threads pour exécution. Voici un exemple d'utilisation de curl_multi pour implémenter un robot multithread :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | $mh = curl_multi_init(); //返回一个新cURL批处理句柄
for ($i = 0; $i < $max_size; $i++)
{
$ch = curl_init(); //初始化单个cURL会话
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_URL, 'http://www.zhihu.com/people/' . $user_list[$i] . '/about');
curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$requestMap[$i] = $ch;
curl_multi_add_handle($mh, $ch); //向curl批处理会话中添加单独的curl句柄
}
$user_arr = array();
do {
//运行当前 cURL 句柄的子连接
while (($cme = curl_multi_exec($mh, $active)) == CURLM_CALL_MULTI_PERFORM);
if ($cme != CURLM_OK) {break;}
//获取当前解析的cURL的相关传输信息
while ($done = curl_multi_info_read($mh))
{
$info = curl_getinfo($done['handle']);
$tmp_result = curl_multi_getcontent($done['handle']);
$error = curl_error($done['handle']);
$user_arr[] = array_values(getUserInfo($tmp_result));
//保证同时有$max_size个请求在处理
if ($i < sizeof($user_list) && isset($user_list[$i]) && $i < count($user_list))
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_URL, 'http://www.zhihu.com/people/' . $user_list[$i] . '/about');
curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$requestMap[$i] = $ch;
curl_multi_add_handle($mh, $ch);
$i++;
}
curl_multi_remove_handle($mh, $done['handle']);
}
if ($active)
curl_multi_select($mh, 10);
} while ($active);
curl_multi_close($mh);
return $user_arr;Copier après la connexion |
6. HTTP 429 Trop de requêtes
En utilisant la fonction curl_multi, vous pouvez envoyer plusieurs requêtes en même temps, mais pendant le processus d'exécution, 200 les demandes sont envoyées en même temps. À ce moment-là, il a été constaté que de nombreuses demandes ne pouvaient pas être renvoyées, c'est-à-dire qu'une perte de paquets a été découverte. Pour une analyse plus approfondie, utilisez la fonction curl_getinfo pour imprimer les informations de chaque requête. Cette fonction renvoie un tableau associatif contenant les informations de réponse HTTP. L'un des champs est http_code, qui représente le code d'état HTTP renvoyé par la requête. J'ai vu que le code http de nombreuses requêtes était 429. Ce code retour signifie que trop de requêtes ont été envoyées. J'ai deviné que Zhihu avait mis en œuvre une protection anti-crawler, je l'ai donc testé sur d'autres sites Web et j'ai constaté qu'il n'y avait aucun problème lors de l'envoi de 200 requêtes à la fois, ce qui a prouvé que Zhihu avait mis en œuvre une protection à cet égard. des demandes ponctuelles est limitée. J'ai donc continué à réduire le nombre de requêtes et j'ai constaté qu'il n'y avait aucune perte de paquets à 5. Cela montre que dans ce programme, vous ne pouvez envoyer que jusqu'à 5 requêtes à la fois. Même si ce n'est pas beaucoup, c'est une petite amélioration.
7. Utilisez Redis pour enregistrer les utilisateurs visités
Au cours du processus de capture des utilisateurs, il a été constaté que certains utilisateurs avaient déjà été visités. De plus, ses abonnés et utilisateurs suivants ont déjà été obtenus. Bien que le traitement répété des données soit effectué au niveau de la base de données, le programme utilisera toujours curl pour envoyer des requêtes, donc l'envoi de requêtes répétées entraînera une surcharge réseau importante. Une autre chose est que les utilisateurs à capturer doivent être temporairement enregistrés au même endroit pour la prochaine exécution. Au début, ils ont été placés dans un tableau. Plus tard, j'ai découvert que plusieurs processus devaient être ajoutés au programme. programmation, les sous-processus partageront le code du programme, la bibliothèque de fonctions, mais les variables utilisées par le processus sont complètement différentes de celles utilisées par les autres processus. Les variables entre différents processus sont séparées et ne peuvent pas être lues par d'autres processus, les tableaux ne peuvent donc pas être utilisés. Par conséquent, j'ai pensé à utiliser le cache Redis pour enregistrer les utilisateurs traités et les utilisateurs à capturer. De cette façon, chaque fois que l'exécution est terminée, l'utilisateur est poussé dans une file d'attente déjà_request_queue, et les utilisateurs à capturer (c'est-à-dire la liste des abonnés et des utilisateurs suivis de chaque utilisateur) sont poussés dans la file d'attente request_queue, puis avant à chaque exécution, l'utilisateur est poussé dans la file d'attente déjà_request_queue. Placez un utilisateur dans request_queue, puis déterminez s'il se trouve dans déjà_request_queue. Si c'est le cas, passez au suivant, sinon continuez l'exécution.
Exemple d'utilisation de redis en PHP :
1 2 3 4 5 6 7 8 | <?php
$redis = new Redis();
$redis->connect('127.0.0.1', '6379');
$redis->set('tmp', 'value');
if ($redis->exists('tmp'))
{
echo $redis->get('tmp') . "\n";
}Copier après la connexion |
8. Utilisez l'extension pcntl de PHP pour implémenter le multi-processus
Après avoir utilisé la fonction curl_multi pour implémenter le multi-threading afin de capturer les informations utilisateur, le programme s'est exécuté pour une nuit, la donnée finale obtenue est de 10W. Toujours incapable d'atteindre mon objectif idéal, j'ai continué à optimiser et j'ai découvert plus tard qu'il existe une extension pcntl en PHP qui peut réaliser une programmation multi-processus. Voici un exemple de multiprogrammation :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
//PHP多进程demo
//fork10个进程
for ($i = 0; $i < 10; $i++) {
$pid = pcntl_fork();
if ($pid == -1) {
echo "Could not fork!\n";
exit(1);
}
if (!$pid) {
echo "child process $i running\n";
//子进程执行完毕之后就退出,以免继续fork出新的子进程
exit($i);
}
}
//等待子进程执行完毕,避免出现僵尸进程
while (pcntl_waitpid(0, $status) != -1) {
$status = pcntl_wexitstatus($status);
echo "Child $status completed\n";
}Copier après la connexion |
9、在Linux下查看系统的cpu信息
实现了多进程编程之后,就想着多开几条进程不断地抓取用户的数据,后来开了8调进程跑了一个晚上后发现只能拿到20W的数据,没有多大的提升。于是查阅资料发现,根据系统优化的CPU性能调优,程序的最大进程数不能随便给的,要根据CPU的核数和来给,最大进程数最好是cpu核数的2倍。因此需要查看cpu的信息来看看cpu的核数。在Linux下查看cpu的信息的命令:
1 | cat /proc/cpuinfo Copier après la connexion |
Les résultats sont les suivants :
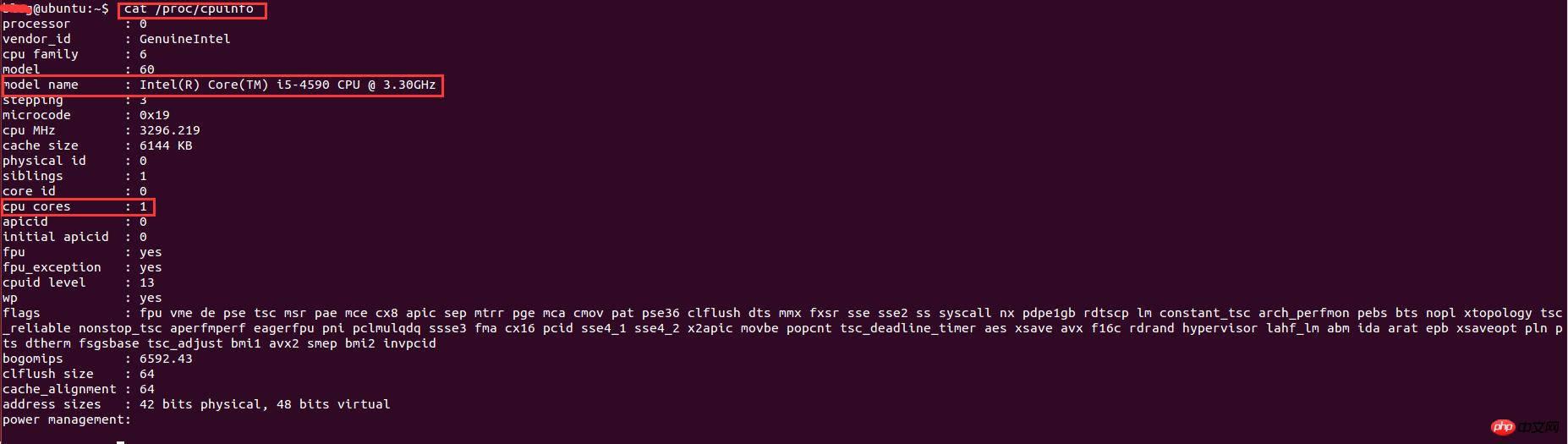
Parmi eux, le nom du modèle représente les informations sur le type de processeur et les cœurs de processeur représentent le nombre de cœurs de processeur. Le nombre de cœurs ici est de 1. Comme il fonctionne sous une machine virtuelle, le nombre de cœurs de processeur alloués est relativement faible, donc seuls 2 processus peuvent être ouverts. Le résultat final a été que 1,1 million de données utilisateur ont été capturées en un seul week-end.
10. Problèmes de connexion Redis et MySQL dans la programmation multi-processus
Dans des conditions multi-processus, après une exécution du programme pendant un certain temps Pendant une période de temps, les données sont trouvées. Elles ne peuvent pas être insérées dans la base de données et une erreur de mysql avec trop de connexions sera signalée. La même chose est vraie pour Redis.
L'exécution du code suivant échouera :
1 2 3 4 5 6 7 8 9 10 11 12 13 | <?php
for ($i = 0; $i < 10; $i++) {
$pid = pcntl_fork();
if ($pid == -1) {
echo "Could not fork!\n";
exit(1);
}
if (!$pid) {
$redis = PRedis::getInstance();
// do something
exit;
}
}Copier après la connexion |
La raison fondamentale est que lorsque chaque processus enfant est créé, il a hérité d'une copie identique du processus parent. Les objets peuvent être copiés, mais les connexions créées ne peuvent pas être copiées dans plusieurs. Le résultat est que chaque processus utilise la même connexion Redis et fait sa propre chose, provoquant finalement des conflits inexplicables.
Solution : >Le programme ne peut pas garantir pleinement que le processus parent ne créera pas d'instance de connexion Redis avant le processus fork. Par conséquent, la seule façon de résoudre ce problème est de recourir au processus enfant lui-même. Imaginez, si l'instance obtenue dans le processus enfant est uniquement liée au processus actuel, alors ce problème n'existera pas. La solution consiste donc à modifier légèrement la méthode statique d'instanciation de classe Redis et à la lier à l'ID de processus actuel.
Le code modifié est le suivant :
1 2 3 4 5 6 7 8 9 10 | <?php
public static function getInstance() {
static $instances = array();
$key = getmypid();//获取当前进程ID
if ($empty($instances[$key])) {
$inctances[$key] = new self();
}
return $instances[$key];
}Copier après la connexion |
11. Temps d'exécution du script de statistiques PHP
Parce que je veux savoir combien de temps prend chaque processus, j'ai écrit une fonction pour compter le temps d'exécution du script :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | function microtime_float()
{
list($u_sec, $sec) = explode(' ', microtime());
return (floatval($u_sec) + floatval($sec));
}
$start_time = microtime_float();
//do something
usleep(100);
$end_time = microtime_float();
$total_time = $end_time - $start_time;
$time_cost = sprintf("%.10f", $total_time);
echo "program cost total " . $time_cost . "s\n";Copier après la connexion |
Ce qui précède est l'intégralité du contenu de cet article pour votre référence. J'espère qu'il sera utile à votre étude.
Recommandations associées :
Utilisez le robot d'exploration PHP pour analyser les prix des logements à Nanjing
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Qu'est-ce que la rigidité de l'utilisateur
Qu'est-ce que la rigidité de l'utilisateur
 Comment ouvrir le fichier php
Comment ouvrir le fichier php
 Comment supprimer les premiers éléments d'un tableau en php
Comment supprimer les premiers éléments d'un tableau en php
 Que faire si la désérialisation php échoue
Que faire si la désérialisation php échoue
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Comment télécharger du HTML
Comment télécharger du HTML
 Comment résoudre les caractères tronqués en PHP
Comment résoudre les caractères tronqués en PHP








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



