

Le contenu présenté dans cet article est un résumé des entretiens PHP, qui a une certaine valeur de référence. Maintenant, je le partage avec tout le monde. Les amis dans le besoin peuvent s'y référer
table
type
touches_possibles
clé
key_len
ref
lignes
Extra
Préparation de l'environnement

CREATE TABLE people( id bigint auto_increment primary key, zipcode char(32) not null default '', address varchar(128) not null default '', lastname char(64) not null default '', firstname char(64) not null default '', birthdate char(10) not null default '' ); CREATE TABLE people_car( people_id bigint, plate_number varchar(16) not null default '', engine_number varchar(16) not null default '', lasttime timestamp );
insert into people (zipcode,address,lastname,firstname,birthdate) values ('230031','anhui','zhan','jindong','1989-09-15'), ('100000','beijing','zhang','san','1987-03-11'), ('200000','shanghai','wang','wu','1988-08-25') insert into people_car (people_id,plate_number,engine_number,lasttime) values (1,'A121311','12121313','2013-11-23 :21:12:21'), (2,'B121311','1S121313','2011-11-23 :21:12:21'), (3,'C121311','1211SAS1','2012-11-23 :21:12:21')
EXPLIQUER l'introduction
alter table people add key(zipcode,firstname,lastname);
id
Query-1 explain select zipcode,firstname,lastname from people;

id est utilisé pour identifier séquentiellement le entier Pour l'instruction SELELCT dans la requête, grâce à la simple requête imbriquée ci-dessus, vous pouvez voir que l'instruction avec l'ID le plus grand est exécutée en premier. Cette valeur peut être NULL si cette ligne est utilisée pour décrire le résultat de l'union d'autres lignes, comme l'instruction UNION :
Query-2 explain select zipcode from (select * from people a) b;

select_type
Query-3 explain select * from people where zipcode = 100000 union select * from people where zipcode = 200000;
Les types d'instructions SELECT peuvent être les suivants. 
SIMPLE
.
PRIMARY
dans une requête imbriquée est Le plus externe L'instruction SELECT est l'instruction SELECT la plus en avant dans une requête UNION. Voir
Requête-2et Requête-3.
UNIONLe deuxième et les suivants dans UNION Instruction SELECT. Voir
Requête-3.
DERIVED
FROM sous-instruction dans la table dérivée Instruction SELECT Instruction SELECT dans la phrase. Voir
Requête-2.
RÉSULTAT SYNDICAL
一个UNION查询的结果。见Query-3。 DEPENDENT UNION 顾名思义,首先需要满足UNION的条件,及UNION中第二个以及后面的SELECT语句,同时该语句依赖外部的查询。 Query-4中select id from people where zipcode = 200000的select_type为DEPENDENT UNION。你也许很奇怪这条语句并没有依赖外部的查询啊。 这里顺带说下MySQL优化器对IN操作符的优化,优化器会将IN中的uncorrelated subquery优化成一个correlated subquery(关于correlated subquery参见这里)。 类似这样的语句会被重写成这样: 所以Query-4实际上被重写成这样: 题外话:有时候MySQL优化器这种太过“聪明” 的做法会导致WHERE条件包含IN()的子查询语句性能有很大损失。可以参看《高性能MySQL第三版》6.5.1关联子查询一节。 SUBQUERY 子查询中第一个SELECT语句。 DEPENDENT SUBQUERY 和DEPENDENT UNION相对UNION一样。见Query-5。 除了上述几种常见的select_type之外还有一些其他的这里就不一一介绍了,不同MySQL版本也不尽相同。 显示的这一行信息是关于哪一张表的。有时候并不是真正的表名。 可以看到如果指定了别名就显示的别名。 还有 注意:MySQL对待这些表和普通表一样,但是这些“临时表”是没有任何索引的。 type列很重要,是用来说明表与表之间是如何进行关联操作的,有没有使用索引。MySQL中“关联”一词比一般意义上的要宽泛,MySQL认为任何一次查询都是一次“关联”,并不仅仅是一个查询需要两张表才叫关联,所以也可以理解MySQL是如何访问表的。主要有下面几种类别。 const 当确定最多只会有一行匹配的时候,MySQL优化器会在查询前读取它而且只读取一次,因此非常快。const只会用在将常量和主键或唯一索引进行比较时,而且是比较所有的索引字段。people表在id上有一个主键索引,在(zipcode,firstname,lastname)有一个二级索引。因此Query-8的type是const而Query-9并不是: 注意下面的Query-10也不能使用const table,虽然也是主键,也只会返回一条结果。 system 这是const连接类型的一种特例,表仅有一行满足条件。 eq_ref eq_ref类型是除了const外最好的连接类型,它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY。 需要注意InnoDB和MyISAM引擎在这一点上有点差别。InnoDB当数据量比较小的情况type会是All。我们上面创建的people 和 people_car默认都是InnoDB表。 我们创建两个MyISAM表people2和people_car2试试: 我想这是InnoDB对性能权衡的一个结果。 eq_ref可以用于使用 = 操作符比较的带索引的列。比较值可以为常量或一个使用在该表前面所读取的表的列的表达式。如果关联所用的索引刚好又是主键,那么就会变成更优的const了: ref 这个类型跟eq_ref不同的是,它用在关联操作只使用了索引的最左前缀,或者索引不是UNIQUE和PRIMARY KEY。ref可以用于使用=或<=>操作符的带索引的列。 为了说明我们重新建立上面的people2和people_car2表,仍然使用MyISAM但是不给id指定primary key。然后我们分别给id和people_id建立非唯一索引。 然后再执行下面的查询: 看上面的Query-15,Query-16和Query-17,Query-18我们发现MyISAM在ref类型上的处理也是有不同策略的。 对于ref类型,在InnoDB上面执行上面三条语句结果完全一致。 fulltext 链接是使用全文索引进行的。一般我们用到的索引都是B树,这里就不举例说明了。 ref_or_null 该类型和ref类似。但是MySQL会做一个额外的搜索包含NULL列的操作。在解决子查询中经常使用该联接类型的优化。(详见这里)。 注意Query-20使用的并不是ref_or_null,而且InnnoDB这次表现又不相同(数据量大的情况下有待验证)。 index_merger 该联接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。关于索引合并优化看这里。 unique_subquery 该类型替换了下面形式的IN子查询的ref: unique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。 index_subquery 该联接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引:<br/> range 只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。在该类型中ref列为NULL。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range: 注意在我的测试中:发现只有id是主键或唯一索引时type才会为range。 这里顺便挑剔下MySQL使用相同的range来表示范围查询和列表查询。 但事实上这两种情况下MySQL如何使用索引是有很大差别的: 我们不是挑剔:这两种访问效率是不同的。对于范围条件查询,MySQL无法使用范围列后面的其他索引列了,但是对于“多个等值条件查询”则没有这个限制了。 ——出自《高性能MySQL第三版》 index 该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小。这个类型通常的作用是告诉我们查询是否使用索引进行排序操作。 至于什么情况下MySQL会利用索引进行排序,等有时间再仔细研究。最典型的就是order by后面跟的是主键。 ALL Le moyen le plus lent est l'analyse complète de la table. En général : les performances des types de connexion ci-dessus diminuent dans l'ordre (système>const), différentes versions de MySQL, différents moteurs de stockage et même des volumes de données différents peuvent fonctionner différemment. La colonne possible_keys indique quel index MySQL peut utiliser pour trouver la table D'ACCORD. La colonne clé affiche la clé (index) que MySQL a réellement décidé d'utiliser. Si aucun index n'est sélectionné, la clé est NULL. Pour forcer MySQL à utiliser ou ignorer l'index sur la colonne possible_keys, utilisez FORCE INDEX, USE INDEX ou IGNORE INDEX dans la requête. La colonne key_len affiche la longueur de clé que MySQL a décidé d'utiliser. Si la clé est NULL, la longueur est NULL. La longueur de l'index utilisé. Plus la longueur est courte, mieux c'est sans perdre en précision. La colonne ref indique quelle colonne ou constante est utilisée avec la clé dans le tableau Sélectionnez les lignes dans . la colonne lignes montre ce que MySQL pense devoir faire quand exécution de la requête Nombre de lignes à vérifier. Notez qu’il s’agit d’une estimation. <br/>Extra est une autre colonne très importante dans la sortie EXPLAIN. afficher des informations détaillées sur MySQL pendant le processus de requête. Il contient beaucoup d'informations, je ne sélectionne que quelques points clés à introduire. Utilisation du tri de fichiers indique qu'une table temporaire est utilisé. Généralement, voir cela indique que la requête doit être optimisée. Même si l'utilisation de tables temporaires ne peut être évitée, l'utilisation de tables temporaires sur disque dur doit être évitée autant que possible. N'existe pas MYSQL optimise LEFT JOIN, Une fois il trouve une ligne qui correspond aux critères LEFT JOIN, il ne cherche plus. Utilisation de l'index Indique que la requête couvre le index Oui, c'est une bonne chose. MySQL filtre les enregistrements indésirables directement à partir de l'index et renvoie les accès. Ceci est effectué par la couche de service MySQL, mais il n'est pas nécessaire de revenir à la table pour interroger les enregistrements. Utilisation de la condition d'index Voici MySQL 5.6 à venir out La nouvelle fonctionnalité est appelée "index condition push". Pour faire simple, MySQL était à l'origine incapable d'effectuer des opérations telles que sur les index, mais il le peut désormais. Cela réduit les opérations d'E/S inutiles, mais il ne peut être utilisé que sur des index secondaires. Utiliser Where Utiliser la clause WHERE pour restreindre Quelles lignes correspondront au tableau suivant ou seront renvoyées à l'utilisateur. Remarque : L'utilisation de Where apparaît dans la colonne Extra signifie que le serveur MySQL renvoie le moteur de stockage à la couche de service et applique ensuite le filtrage des conditions WHERE. Le contenu de sortie d'EXPLAIN a été essentiellement introduit. Il dispose également d'une commande étendue appelée EXPLAIN EXTENDED, qui peut être combinée avec la commande EXPLAIN. Commande AFFICHER LES AVERTISSEMENTS. Voir quelques informations supplémentaires. L'une des choses les plus utiles est que vous pouvez voir le SQL après reconstruction par l'optimiseur MySQL. Ok, c'est tout pour EXPLIQUER. En fait, ces contenus sont disponibles en ligne, mais vous serez plus impressionné en les pratiquant vous-même. La section suivante présentera SHOW PROFILE, les journaux de requêtes lentes et certains outils tiers. <br/> OAuth concerne l'autorisation. La norme est largement utilisée dans le monde entier. La version actuelle est la version 2.0. Cet article fournit une explication concise et populaire des idées de conception et du processus de fonctionnement d'OAuth 2.0. Le principal document de référence est la RFC 6749. Afin de comprendre les scénarios applicables d'OAuth, permettez-moi de donner un exemple hypothétique. Il existe un site Web « d'impression en nuage » qui peut imprimer les photos stockées par les utilisateurs sur Google. Pour utiliser ce service, les utilisateurs doivent laisser « Cloud Print » lire leurs photos stockées sur Google. Le problème est que Google n'autorisera "Cloud Print" à lire ces photos qu'avec l'autorisation de l'utilisateur. Alors, comment « Cloud Printing » obtient-il l’autorisation de l’utilisateur ? La méthode traditionnelle consiste pour l'utilisateur à indiquer à "Cloud Print" son nom d'utilisateur et son mot de passe Google, et ce dernier peut lire les photos de l'utilisateur. Cette approche présente plusieurs inconvénients sérieux. (1) "Cloud Printing" enregistrera le mot de passe de l'utilisateur pour les services ultérieurs, ce qui est très dangereux. (2) Google doit déployer une connexion par mot de passe, et nous savons qu'une simple connexion par mot de passe n'est pas sûre. (3) "Cloud Print" a le droit d'obtenir toutes les données de l'utilisateur stockées dans Google, et les utilisateurs ne peuvent pas limiter la portée et la période de validité de l'autorisation "Cloud Print". (4) Ce n'est qu'en changeant le mot de passe que l'utilisateur peut reprendre le pouvoir accordé à "Cloud Printing". Cependant, cela invaliderait toutes les autres applications tierces autorisées par l'utilisateur. (5) Tant qu'une application tierce est craquée, cela entraînera la fuite des mots de passe des utilisateurs et la fuite de toutes les données protégées par mot de passe. OAuth est né pour résoudre les problèmes ci-dessus. Avant d'expliquer OAuth 2.0 en détail, vous devez comprendre plusieurs noms spéciaux. Ils sont cruciaux pour comprendre les explications suivantes, en particulier les différentes images. (1) Application tierce : Application tierce, également appelée « client » dans cet article, c'est-à-dire « cloud printing » dans l'exemple du précédent section ". (2)Service HTTP : fournisseur de services HTTP, appelé « fournisseur de services » dans cet article, qui est Google dans l'exemple de la section précédente. (3) Propriétaire de la ressource : Propriétaire de la ressource, également appelé « utilisateur » dans cet article. (4)User Agent : Agent utilisateur, dans cet article fait référence au navigateur. (5)Serveur d'autorisation : Serveur d'authentification, c'est-à-dire un serveur spécialement utilisé par le fournisseur de services pour gérer l'authentification. (6)Serveur de ressources : Serveur de ressources, c'est-à-dire le serveur sur lequel le fournisseur de services stocke les ressources générées par l'utilisateur. Lui et le serveur d'authentification peuvent être le même serveur ou des serveurs différents. Après avoir connu les termes ci-dessus, il n'est pas difficile de comprendre que la fonction d'OAuth est de permettre au « client » d'obtenir l'autorisation de « l'utilisateur » de manière sûre et contrôlable et d'interagir avec le "prestataire de services". OAuth met en place une couche d'autorisation entre le « client » et le « fournisseur de services ». Le « client » ne peut pas se connecter directement au « fournisseur de services », mais peut uniquement se connecter à la couche d'autorisation pour distinguer l'utilisateur du client. Le jeton utilisé par le « client » pour se connecter à la couche d'autorisation est différent du mot de passe de l'utilisateur. Les utilisateurs peuvent spécifier la portée de l'autorisation et la période de validité du jeton de couche d'autorisation lors de la connexion. Une fois que le « client » s'est connecté à la couche d'autorisation, le « fournisseur de services » ouvre les informations stockées de l'utilisateur au « client » en fonction de la portée de l'autorité et de la période de validité du jeton. Le processus de fonctionnement d'OAuth 2.0 est présenté ci-dessous, extrait de la RFC 6749. (A) Une fois que l'utilisateur a ouvert le client, le client demande à l'utilisateur de donner son autorisation. (B) L'utilisateur s'engage à accorder l'autorisation au client. (C) Le client utilise l'autorisation obtenue à l'étape précédente pour demander un token auprès du serveur d'authentification. (D) Une fois que le serveur d'authentification a authentifié le client, il confirme qu'il est correct et accepte d'émettre le jeton. (E) Le client utilise le jeton pour s'appliquer au serveur de ressources afin d'obtenir des ressources. (F)资源服务器确认令牌无误,同意向客户端开放资源。 不难看出来,上面六个步骤之中,B是关键,即用户怎样才能给于客户端授权。有了这个授权以后,客户端就可以获取令牌,进而凭令牌获取资源。 下面一一讲解客户端获取授权的四种模式。 客户端必须得到用户的授权(authorization grant),才能获得令牌(access token)。OAuth 2.0定义了四种授权方式。 授权码模式(authorization code) 简化模式(implicit) 密码模式(resource owner password credentials) 客户端模式(client credentials) 授权码模式(authorization code)是功能最完整、流程最严密的授权模式。它的特点就是通过客户端的后台服务器,与"服务提供商"的认证服务器进行互动。 它的步骤如下: (A)用户访问客户端,后者将前者导向认证服务器。 (B)用户选择是否给予客户端授权。 (C)假设用户给予授权,认证服务器将用户导向客户端事先指定的"重定向URI"(redirection URI),同时附上一个授权码。 (D)客户端收到授权码,附上早先的"重定向URI",向认证服务器申请令牌。这一步是在客户端的后台的服务器上完成的,对用户不可见。 (E)认证服务器核对了授权码和重定向URI,确认无误后,向客户端发送访问令牌(access token)和更新令牌(refresh token)。 下面是上面这些步骤所需要的参数。 A步骤中,客户端申请认证的URI,包含以下参数: response_type:表示授权类型,必选项,此处的值固定为"code" client_id:表示客户端的ID,必选项 redirect_uri:表示重定向URI,可选项 scope:表示申请的权限范围,可选项 state:表示客户端的当前状态,可以指定任意值,认证服务器会原封不动地返回这个值。 下面是一个例子。 C步骤中,服务器回应客户端的URI,包含以下参数: code:表示授权码,必选项。该码的有效期应该很短,通常设为10分钟,客户端只能使用该码一次,否则会被授权服务器拒绝。该码与客户端ID和重定向URI,是一一对应关系。 state:如果客户端的请求中包含这个参数,认证服务器的回应也必须一模一样包含这个参数。 下面是一个例子。 D步骤中,客户端向认证服务器申请令牌的HTTP请求,包含以下参数: grant_type:表示使用的授权模式,必选项,此处的值固定为"authorization_code"。 code:表示上一步获得的授权码,必选项。 redirect_uri:表示重定向URI,必选项,且必须与A步骤中的该参数值保持一致。 client_id:表示客户端ID,必选项。 下面是一个例子。 E步骤中,认证服务器发送的HTTP回复,包含以下参数: access_token:表示访问令牌,必选项。 token_type:表示令牌类型,该值大小写不敏感,必选项,可以是bearer类型或mac类型。 expires_in:表示过期时间,单位为秒。如果省略该参数,必须其他方式设置过期时间。 refresh_token:表示更新令牌,用来获取下一次的访问令牌,可选项。 scope:表示权限范围,如果与客户端申请的范围一致,此项可省略。 下面是一个例子。 从上面代码可以看到,相关参数使用JSON格式发送(Content-Type: application/json)。此外,HTTP头信息中明确指定不得缓存。 简化模式(implicit grant type)不通过第三方应用程序的服务器,直接在浏览器中向认证服务器申请令牌,跳过了"授权码"这个步骤,因此得名。所有步骤在浏览器中完成,令牌对访问者是可见的,且客户端不需要认证。 它的步骤如下: (A)客户端将用户导向认证服务器。 (B)用户决定是否给于客户端授权。 (C)假设用户给予授权,认证服务器将用户导向客户端指定的"重定向URI",并在URI的Hash部分包含了访问令牌。 (D)浏览器向资源服务器发出请求,其中不包括上一步收到的Hash值。 (E)资源服务器返回一个网页,其中包含的代码可以获取Hash值中的令牌。 (F)浏览器执行上一步获得的脚本,提取出令牌。 (G)浏览器将令牌发给客户端。 下面是上面这些步骤所需要的参数。 A步骤中,客户端发出的HTTP请求,包含以下参数: response_type:表示授权类型,此处的值固定为"token",必选项。 client_id:表示客户端的ID,必选项。 redirect_uri:表示重定向的URI,可选项。 scope:表示权限范围,可选项。 state:表示客户端的当前状态,可以指定任意值,认证服务器会原封不动地返回这个值。 下面是一个例子。 C步骤中,认证服务器回应客户端的URI,包含以下参数: access_token:表示访问令牌,必选项。 token_type:表示令牌类型,该值大小写不敏感,必选项。 expires_in:表示过期时间,单位为秒。如果省略该参数,必须其他方式设置过期时间。 scope:表示权限范围,如果与客户端申请的范围一致,此项可省略。 state:如果客户端的请求中包含这个参数,认证服务器的回应也必须一模一样包含这个参数。 下面是一个例子。 在上面的例子中,认证服务器用HTTP头信息的Location栏,指定浏览器重定向的网址。注意,在这个网址的Hash部分包含了令牌。 根据上面的D步骤,下一步浏览器会访问Location指定的网址,但是Hash部分不会发送。接下来的E步骤,服务提供商的资源服务器发送过来的代码,会提取出Hash中的令牌。 密码模式(Resource Owner Password Credentials Grant)中,用户向客户端提供自己的用户名和密码。客户端使用这些信息,向"服务商提供商"索要授权。 在这种模式中,用户必须把自己的密码给客户端,但是客户端不得储存密码。这通常用在用户对客户端高度信任的情况下,比如客户端是操作系统的一部分,或者由一个著名公司出品。而认证服务器只有在其他授权模式无法执行的情况下,才能考虑使用这种模式。 它的步骤如下: (A)用户向客户端提供用户名和密码。 (B)客户端将用户名和密码发给认证服务器,向后者请求令牌。 (C)认证服务器确认无误后,向客户端提供访问令牌。 B步骤中,客户端发出的HTTP请求,包含以下参数: grant_type:表示授权类型,此处的值固定为"password",必选项。 username:表示用户名,必选项。 password:表示用户的密码,必选项。 scope:表示权限范围,可选项。 下面是一个例子。 C步骤中,认证服务器向客户端发送访问令牌,下面是一个例子。 上面代码中,各个参数的含义参见《授权码模式》一节。 整个过程中,客户端不得保存用户的密码。 客户端模式(Client Credentials Grant)指客户端以自己的名义,而不是以用户的名义,向"服务提供商"进行认证。严格地说,客户端模式并不属于OAuth框架所要解决的问题。在这种模式中,用户直接向客户端注册,客户端以自己的名义要求"服务提供商"提供服务,其实不存在授权问题。 它的步骤如下: (A)客户端向认证服务器进行身份认证,并要求一个访问令牌。 (B)认证服务器确认无误后,向客户端提供访问令牌。 A步骤中,客户端发出的HTTP请求,包含以下参数: granttype:表示授权类型,此处的值固定为"clientcredentials",必选项。 scope:表示权限范围,可选项。 认证服务器必须以某种方式,验证客户端身份。 B步骤中,认证服务器向客户端发送访问令牌,下面是一个例子。 上面代码中,各个参数的含义参见《授权码模式》一节。 如果用户访问的时候,客户端的"访问令牌"已经过期,则需要使用"更新令牌"申请一个新的访问令牌。 客户端发出更新令牌的HTTP请求,包含以下参数: granttype:表示使用的授权模式,此处的值固定为"refreshtoken",必选项。 refresh_token:表示早前收到的更新令牌,必选项。 scope:表示申请的授权范围,不可以超出上一次申请的范围,如果省略该参数,则表示与上一次一致。 下面是一个例子。 (完) <br/> yii2框架的安装我们在之前文章中已经提到下面我们开始了解YII2框架 强大的YII2框架网上指南:http://www.yii-china.com/doc/detail/1.html?postid=278或者<br/> http://www.yiichina.com/doc/guide/2.0<br/> Yii2的应用结构:<br/> 目录篇:<br/> <br/> <br/> <br/>3.console L'application console contient les commandes de console requises par le système. <br/> Parmi eux : config est une configuration générale. Ces configurations s'appliqueront au front et au backend ainsi qu'à la ligne de commande. mail correspond aux fichiers de mise en page liés au courrier électronique du front et du backend de l'application et de la ligne de commande. Les modèles sont des modèles de données qui peuvent être utilisés à la fois en front-end et en ligne de commande. C'est aussi la partie la plus importante du commun. <br/> Les fichiers contenus dans le répertoire public (Common) sont utilisés pour le partage entre d'autres applications. Par exemple, chaque application peut avoir besoin d'accéder à la base de données à l'aide d'ActiveRecord. Par conséquent, nous pouvons placer la classe du modèle AR dans le répertoire commun. De même, si certains assistants ou widgets sont utilisés dans plusieurs applications, nous devons également les placer dans un répertoire commun pour éviter la duplication de code. Comme nous l'expliquerons prochainement, les applications peuvent également partager des parties d'une configuration commune. Par conséquent, nous pouvons également stocker les configurations communes communes dans le répertoire de configuration. <br/>Lors du développement d'un projet à grande échelle avec un long cycle de développement, nous devons constamment ajuster la structure de la base de données. Pour cette raison, nous pouvons également utiliser la fonctionnalité de migration de base de données pour suivre les modifications de la base de données. Nous plaçons également tous les répertoires de migrations de bases de données dans le répertoire commun. <br/><br/>5.environment Chaque environnement Yii est un ensemble de fichiers de configuration, comprenant le script d'entrée index.php et divers fichiers de configuration. En fait, ils sont tous placés sous le répertoire /environments <br/> Répertoire dev Répertoire prod Fichier index.php Parmi eux, dev et prod ont la même structure, et contiennent respectivement 4 répertoires et 1 fichier : répertoire frontend, qui est utilisé pour les applications front-end et contient la configuration pour stocker les fichiers de configuration. Répertoire et répertoire Web qui stocke les scripts d'entrée Web répertoire backend, utilisé pour les applications en arrière-plan, le contenu est le même que celui du frontend répertoire de la console, utilisé pour L'application de ligne de commande contient uniquement le répertoire de configuration, car l'application de ligne de commande ne nécessite pas de script d'entrée Web, il n'y a donc pas de répertoire Web. le répertoire commun est utilisé pour les configurations d'environnement communes de diverses applications Web et applications de ligne de commande. Il contient uniquement le répertoire de configuration car différentes applications ne peuvent pas partager le même script d'entrée. Notez que le niveau de ce commun est inférieur au niveau de l’environnement. Autrement dit, son universalité n’est commune que dans un certain environnement, et non dans tous les environnements. Le fichier yii est le fichier de script d'entrée pour les applications en ligne de commande. Pour les répertoires web et config disséminés un peu partout, ils ont aussi un point commun. Tout répertoire Web stocke le script d'entrée de l'application Web, un index.php et une version de test d'index-test.php Tous les répertoires de configuration stockent les informations de configuration locale main-local.php et params-local.php <br/>6.vendor 1、入口文件路径:<br/> http://127.0.0.1/yii2/advanced/frontend/web/index.php 每个应用都有一个入口脚本 web/index.PHP,这是整个应用中唯一可以访问的 PHP 脚本。一个应用处理请求的过程如下: 1.用户向入口脚本 web/index.php 发起请求。 <br/>2.入口脚本加载应用配置并创建一个应用实例去处理请求。 <br/>3.应用通过请求组件解析请求的路由。 <br/>4.应用创建一个控制器实例去处理请求。 <br/>5.控制器创建一个操作实例并针对操作执行过滤器。 <br/>6.如果任何一个过滤器返回失败,则操作退出。 <br/>7.如果所有过滤器都通过,操作将被执行。 <br/>8.操作会加载一个数据模型,或许是来自数据库。<br/>9.操作会渲染一个视图,把数据模型提供给它。 <br/>10.渲染结果返回给响应组件。 <br/>11.响应组件发送渲染结果给用户浏览器 可以看到中间有模型-视图-控制器 ,即常说的MVC。入口脚本并不会处理请求,而是把请求交给了应用主体,在处理请求时,会用到控制器,如果用到数据库中的东西,就会去访问模型,如果处理请求完成,要返回给用户信息,则会在视图中回馈要返回给用户的内容。<br/> 2、为什么我们访问方法会出现url加密呢? 我们找到文件:vendor/yiisoft/yii2/web/UrlManager.php <br/> MVC篇: 一、控制器详解: 1、修改默认控制器和方法 修改全局控制器:打开vendor/yiisoft/yii2/web/Application.php eg: 2、建立控制器示例:StudentController.php //命名空间<br/> <br/> <br/><br/> //显示视图<br/> return $this->render('add'); 默认.php<br/> return $this->render('upda',["data"=>$data]); <br/><br/> } <br/>}<br/><br/> 二、模型层详解 简单模型建立: <br/> <br/><br/> 三、视图层详解首先在frontend下建立与控制器名一致的文件(小写)eg:student 在文件下建立文件<br/> eg:index.php<br/>每一个controller对应一个view的文件夹,但是视图文件yii不要求是HTML,而是php,所以每个视图文件php里面都是视图片段: 当然了,视图与模板之间还有数据传递以及继承覆盖的功能。<br/><br/><br/><br/><br/><br/> YII2框架数据的运用 1、数据库连接 简介 一个项目根据需要会要求连接多个数据库,那么在yii2中如何链接多数据库呢?其实很简单,在配置文件中稍加配置即可完成。 配置 打开数据库配置文件common\config\main-local.php,在原先的db配置项下面添加db2,配置第二个数据库的属性即可 [php] view plain copy 如上配置就可以完成yii2连接多个数据库的功能,但还是需要注意几个点 如果使用的数据库前缀 在建立模型时 这样: eg:这个库叫 haiyong_test return {{%test}}<br/> 应用 1.我们在hyii数据库中新建一个测试表test 2.通过gii生成模型,这里需要注意的就是数据库链接ID处要改成db2<br/> 3.查看生成的模型,比正常的model多了红色标记的地方 所以各位童鞋,如果使用多数据配置,在建db2的模型的时候,也要加上上图红色的代码。 好了,以上步骤就完成了,yii2的多数据库配置,配置完成之后可以和原因一样使用model或者数据库操作 2、数据操作: <br/>方式一:使用createCommand()函数<br/> 增加 <br/> 获取自增id [php] view plain copy 批量插入数据 [php] view plain copy 修改 [php] view plain copy 方式二:模型处理数据(优秀程序媛必备)!! <br/> 新增(因为save方法有点low)所以自己在模型层中定义:add和addAll方法<br/> 注意:!!!当setAttributes($attributes,fase);时不用设置rules规则,否则则需要设置字段规则;<br/> 删除<br/> 使用model::delete()进行删除 [php] view plain copy 直接删除:删除年龄为30的所有用户 [php] view plain copy 根据主键删除:删除主键值为1的用户<br/> [php] view plain copy <br/> <br/> <br/> <br/> <br/> 修改<br/> 使用model::save()进行修改 <br/> <br/> <br/> 直接修改:修改用户test的年龄为40<br/> <br/> <br/> 基础查询 <br/> <br/> 关联查询 <br/> <br/> <br/> 翻译 2015年07月30日 10:29:03 <br/> yii2 rbac 详解DbManager <br/> 1.yii config文件配置(我用的高级模板)(配置在common/config/main-local.php或者main.php) 'authManager' => [ 'class' => 'yiirbacDbManager', 'itemTable' => 'auth_item_child', ],<br/> 2.Bien sûr, le rôle par défaut peut également être défini dans la configuration, mais je je ne l'ai pas écrit. Rbac prend en charge deux classes, PhpManager et DbManager. Ici, j'utilise DbManager. yii migrate (exécutez cette commande pour générer la table utilisateur) <br/>yii migrate --migrationPath=@yii/rbac/migrations/ Exécutez cette commande pour générer la table de données d'autorisation dans la figure ci-dessous<br/>3.yii rbac exploite en réalité 4 tables <br/> 推荐文章 微信H5支付完整版含PHP回调页面.代码精简2018年2月 <br/>支付宝手机支付,本身有提供一个手机网站支付DEMO,是lotusphp版本的,里面有上百个文件,非常复杂.本文介绍的接口, <br/>只需通过一个PHP文件即可实现手机支付宝接口的付款,非常简洁,并兼容微信. <br/>代码在最下面. 注意事项(重要): <br/>一,支付宝接口已经升级了加密方式,现在申请的接口都是公钥加私钥的加密形式.公钥与私钥都需要申请者自己生成,而且是成对的,不能拆开用.并把公钥保存到支付宝平台,该公钥对应的私钥不需要保存在支付宝,只能自己保存,并放在api支付宝接口文件中使用.下面会提到. APPID 应该填哪个呢? 这个是指开放平台id,格式应该填2018或2016等日期开头的,不要填合作者pid,那个pid新版不需要的.APPID下面还对应一个网关.这个也要对应填写.正式申请通过的网关为https://openapi.alipay.com/gateway.do 如果你是沙箱测试账号, <br/>则填https://openapi.alipaydev.com/gateway.do 注意区别 <br/>密钥生成方式为, https://docs.open.alipay.com/291/105971 打开这个地址,下载该相应工具后,解压打开文件夹,运行“RSA签名验签工具.bat”这个文件后.打开效果如下图 <br/>如果你的网站是jsp的,密钥格式如下图,点击选择第一个pkcs8的,如果你的网站是php,asp等,则点击pkcs1 <br/>密钥长度统一为2048位. <br/>然后点击 生成密钥 <br/>然后,再点击打开密钥文件路径按钮.即可看到生成的密钥文件,打开txt文件.即可看到生成的公钥与私钥了. <br/>公钥复制后(注意不要换行),需提供给支付宝账号管理者,并上传到支付宝开放平台。如下图第二 <br/>界面示例: <br/> 二,如下,同步回调地址与异步回调地址的区别. <br/>同步地址是指用户付款成功,他自动跳转到这个地址,以get方式返回,你可以设置为跳转回会员中心,也可以转到网站首页或充值日志页面,通过$_GET 的获取支付宝发来的签名,金额等参数.然后进本地数据库验证支付是否正常. <br/>而异步回调地址指支付成功后,支付宝会自动多次的访问你的这个地址,以静默方式进行,用户感受不到地址的跳转.注意,异步回调地址中不能有问号,&等符号,可以放在根目录中.如果你设置为notify_url.php,则你也需要在notify_url.php这个文件中做个判断.比如如果用户付款成功了.则用户的余额则增加多少,充值状态由付款中.修改为付款成功等. 1 2 三,orderName 订单名称,注意编码,否则签名可能会失败 <br/>向支付宝发起支付请求时,有个orderName 订单名称参数.注意这个参数的编码,如果你的本页面是gb2312编码,$this->charset = ‘UTF-8’这个参数最好还是UTF-8,不需要修改.否则签名时,可能会出现各种问题.,可用下面的方法做个转码. 1 四,微信中如何使用支付宝 <br/>支付宝有方案,可以进这个页面把ap.js及pay.htm下载后,保存到你的支付文件pay.php文件所在的目录中. <br/>方案解释,会员在微信中打开你网站的页面,登录,并点击充值或购买链接时,他如果选择支付宝付款,则ap.js会自动弹出这个pay.htm页面,提示你在右上角选择用浏览器中打开,打开后,自动跳转到支付宝app中,不需要重新登录原网站的会员即可完成充值,并跳转回去. <br/>注意,在你的客户从微信转到手机浏览器后,并没有让你重新登录你的商城网站,这是本方案的优势所在. <br/>https://docs.open.alipay.com/203/105285/ 五,如果你申请的支付宝手机支付接口在审核中,则可以先申请一个沙箱测试账号,该账号申请后就可以使用非常方便.同时会提供你一个支付宝商家账号及买家测试账号.登录即可测试付款情况. 代码如下(参考) <br/>一.表单付款按钮所在页面代码 <br/> 二,pay.php页面代码(核心代码) 三,回调页面案例一,即notify_url.php文件. post回调, 四.异步回调案例2, 与上面三是重复的,可选择其中一个.本回调可直接放根目录中 如果你服务器不支持mysqli 就替换为mysql 测试回调时, 请先直接访问本页面,进行测试.订单号可以先写一个固定值. 参考原文 <br/>http://blog.csdn.net/jason19905/article/details/78636716 <br/>https://github.com/dedemao/alipay <br/> 抓包就是把网络数据包用软件截住或者纪录下来,这样做我们可以分析网络数据包,可以修改它然后发送一个假包给服务器,这种技术多应用于网络游戏外挂的制作方面或者密码截取等等 常用的几款抓包工具!<br/>标签: 软件测试软件测试方法软件测试学习<br/>原创来自于我们的微信公众号:软件测试大师 <br/>最近很多同学,说面试的时候被问道,有没有用过什么抓包工具,其实抓包工具并没有什么很难的工具,只要你知道你要用抓包是干嘛的,就知道该怎么用了!一般<br/>对于测试而言,并不需要我们去做断点或者是调试代码什么的,只需要用一些抓包工具抓取发送给服务器的请求,观察下它的请求时间还有发送内容等等,有时候,<br/>可能还会用到这个去观察某个页面下载组件消耗时间太长,找出原因,要开发做性能调优。那么下面就给大家推荐几款抓包工具,好好学习下,下次面试也可以拿来<br/>装一下了! <br/>1<br/>Flidder<br/>Fiddler是位于客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一 。 它能够记录客户端和服务器之间的所有 <br/>HTTP请求,可以针对特定的HTTP请求,分析请求数据、设置断点、调试web应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是<br/>web调试的利器。<br/>小编发现了有个兄台写的不错的文章,分享给大家,有兴趣的同学,可以自己去查阅并学习下,反正本小编花了点时间就学会了,原来就这么回事!作为测试学会这点真的是足够用了!<br/>学习链接如下:<br/>http://blog.csdn.net/ohmygirl/article/details/17846199<br/>http://blog.csdn.net/ohmygirl/article/details/17849983<br/>http://blog.csdn.net/ohmygirl/article/details/17855031 2<br/>Httpwatch<br/>火狐浏览器下有著名的httpfox,而HttpWatch则是IE下强大的网页数据分析工具。教程小编也不详述了,找到了一个超级棒的教程!真心很赞!要想学习的同学,可以点击链接去感受下!<br/>http://jingyan.baidu.com/article/5553fa820539ff65a339345d.html <br/>3其他浏览器的内置抓包工具<br/>如果用过Firefox的F12功能键,应该也知道这里也有网络抓包的工具,是内置在浏览器里面的,貌似现在每款浏览器都有这个内置的抓包工具,虽然没有上面两个工具强大,但是对于测试而言,我觉得是足够了!下面是一个非常详细的教程,大家可以去学习下。<br/>http://jingyan.baidu.com/article/3c343ff703fee20d377963e7.html 对于想学习点新知识去面试装逼的同学,小编只能帮你们到这里了,要想学习到新知识,除了动手指去点击这些链接,还需要你们去动脑好好学习下! <br/> <br/> 超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。 为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。 一、HTTP和HTTPS的基本概念 HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。 HTTPS : il s'agit d'un canal HTTP destiné à la sécurité. En termes simples, il s'agit d'une version sécurisée de HTTP, c'est-à-dire qu'une couche SSL est ajoutée à HTTPS. La base de sécurité de HTTPS est SSL, donc les détails du cryptage nécessitent. SSL. Les principales fonctions du protocole HTTPS peuvent être divisées en deux types : l'une consiste à établir un canal de sécurité des informations pour assurer la sécurité de la transmission des données ; l'autre est de confirmer l'authenticité du site Web ; 2. Quelle est la différence entre HTTP et HTTPS ? Les données transmises par le protocole HTTP ne sont pas cryptées, c'est-à-dire en texte brut, il est donc très dangereux d'utiliser le protocole HTTP pour transmettre des informations privées afin de garantir la confidentialité de ces données. peut être crypté et transmis, conçu par Netscape Le protocole SSL (Secure Sockets Layer) a été utilisé pour crypter les données transmises par le protocole HTTP, c'est ainsi qu'est né HTTPS. Pour faire simple, le protocole HTTPS est un protocole réseau construit à partir du protocole SSL+HTTP qui peut effectuer une transmission cryptée et une authentification d'identité. Il est plus sécurisé que le protocole http. Les principales différences entre HTTPS et HTTP sont les suivantes : 1. Le protocole https nécessite de demander un certificat auprès de CA. Généralement, il y a moins de certificats gratuits, donc certains frais sont requis. . 2. http est un protocole de transfert hypertexte et les informations sont transmises en texte brut, tandis que https est un protocole de transmission sécurisé et crypté SSL. 3. http et https utilisent des méthodes de connexion complètement différentes et utilisent des ports différents. Le premier est 80 et le second est 443. 4. La connexion http est très simple et sans état ; le protocole HTTPS est un protocole réseau construit à partir du protocole SSL+HTTP qui peut effectuer une transmission cryptée et une authentification d'identité, et est plus sécurisé que le protocole http. 3. Comment fonctionne HTTPS Nous savons tous que HTTPS peut crypter des informations pour empêcher que des informations sensibles ne soient obtenues par des tiers, c'est pourquoi de nombreux sites Web ou adresses e-mail de banques le sont Les services de niveau supérieur utiliseront le protocole HTTPS. 1. Le client initie une requête HTTPS Il n'y a rien à dire à ce sujet L'utilisateur saisit une URL https dans le navigateur puis se connecte au port 443 de. le serveur. 2. Configuration du serveur Un serveur qui utilise le protocole HTTPS doit disposer d'un ensemble de certificats numériques Vous pouvez le faire vous-même ou faire une demande auprès de l'organisation. est qu'il est émis par vous-même. Le certificat doit être vérifié par le client avant que vous puissiez continuer à y accéder. Si vous utilisez un certificat appliqué par une entreprise de confiance, la page d'invite ne s'affichera pas (startssl est un bon choix, avec un service gratuit d'un an). Ce certificat est en fait une paire de clé publique et de clé privée. Si vous ne comprenez pas la clé publique et la clé privée, vous pouvez l'imaginer comme une clé et un verrou, mais vous êtes le seul à le faire. Dans le monde qui possède cette clé, vous pouvez donner la serrure à d'autres, et d'autres peuvent utiliser cette serrure pour verrouiller des choses importantes et ensuite vous les envoyer. Parce que vous êtes le seul à posséder la clé, vous seul pouvez voir ce qui est verrouillé. par cette chose de serrure. 3. Transférer le certificat Ce certificat est en fait une clé publique, mais il contient de nombreuses informations, comme l'autorité émettrice du certificat, l'heure d'expiration. , etc. 4. Le client analyse le certificat Cette partie du travail est effectuée par le TLS du client. Il vérifiera d'abord si la clé publique est valide, par exemple. l'autorité émettrice et le délai d'expiration. Attendez, si une exception est trouvée, une boîte d'avertissement apparaîtra, indiquant qu'il y a un problème avec le certificat. S'il n'y a pas de problème avec le certificat, générez une valeur aléatoire, puis utilisez le certificat pour crypter la valeur aléatoire. Comme mentionné ci-dessus, verrouillez la valeur aléatoire avec un verrou, de sorte qu'à moins d'avoir une clé. , vous ne pouvez pas le voir. Le contenu verrouillé n'est pas disponible. 5. Transmission d'informations cryptées Cette partie transmet une valeur aléatoire cryptée avec un certificat Le but est de permettre au serveur d'obtenir cette valeur aléatoire à l'avenir, le client et la communication côté serveur peuvent être cryptés et déchiffrés grâce à cette valeur aléatoire. 6. Informations de décryptage du segment de service Une fois que le serveur l'a déchiffré avec la clé privée, il obtient la valeur aléatoire (clé privée) transmise par le client, puis transmet le contenu à travers Cette valeur est cryptée symétriquement. Le cryptage dit symétrique consiste à mélanger les informations et la clé privée via un certain algorithme, de sorte qu'à moins que la clé privée ne soit connue, le contenu ne peut pas être obtenu, ni le client ni le client. le serveur connaît la clé privée, donc tant que l'algorithme de cryptage est suffisamment puissant, la clé privée est suffisamment complexe et les données sont suffisamment sécurisées. 7. Transmettre des informations cryptées Cette partie des informations est l'information cryptée par la clé privée dans le segment de service et peut être restaurée sur le client. 8. Le client décrypte les informations Le client utilise la clé privée précédemment générée pour décrypter les informations transmises par le segment de service, puis obtient le contenu déchiffré. L'ensemble du processus Même si un tiers surveille les données, il ne peut rien faire. 6. Avantages du HTTPS C'est précisément parce que le HTTPS est très sécurisé que les attaquants ne peuvent pas trouver par où commencer. Du point de vue du webmaster, les avantages de. HTTPS Les avantages sont les suivants : 1. Aspect SEO Google a ajusté l'algorithme du moteur de recherche en août 2014, affirmant que « par rapport aux sites Web HTTP équivalents, l'utilisation du HTTPS est la suivante. Les sites Web cryptés seront mieux classés dans les résultats de recherche. » 2. Sécurité Bien que HTTPS ne soit pas absolument sécurisé, les organisations qui maîtrisent les certificats racines et les organisations qui maîtrisent les algorithmes de chiffrement peuvent également effectuer des opérations de type man-in-the-middle. attaques, mais HTTPS est toujours C'est la solution la plus sécurisée sous l'architecture actuelle et présente les principaux avantages suivants : (1), utilisez le protocole HTTPS pour authentifier les utilisateurs et les serveurs, en garantissant que les données sont envoyées au bon client et au bon serveur (2), le protocole HTTPS est construit à partir du protocole SSL+HTTP et peut être crypté Le protocole réseau pour la transmission et l'authentification de l'identité est plus sécurisé que le protocole HTTP, ce qui peut empêcher le vol ou la modification des données pendant la transmission et garantir l'intégrité des données. (3) HTTPS est la solution la plus sécurisée sous l'architecture actuelle. Bien qu'elle ne soit pas absolument sûre, elle augmente considérablement le coût des attaques de l'homme du milieu. 7. Inconvénients du HTTPS Bien que le HTTPS présente de grands avantages, il présente encore quelques inconvénients. Plus précisément, il y a les 2 points suivants : . 1. Aspects SEO Selon les données ACM CoNEXT, l'utilisation du protocole HTTPS prolongera le temps de chargement de la page de près de 50 %, augmentant de 10 % à 20 % la consommation électrique. De plus, le protocole HTTPS affectera également la mise en cache, augmentera la surcharge de données et la consommation d'énergie, et même les mesures de sécurité existantes seront affectées. De plus, la portée de cryptage du protocole HTTPS est également relativement limitée et a peu d'effet sur les attaques de pirates informatiques, les attaques par déni de service, le piratage de serveur, etc. La chose la plus critique est que le système de chaîne de crédit du certificat SSL n'est pas sécurisé, surtout lorsque certains pays peuvent contrôler le certificat racine de l'autorité de certification, des attaques de l'homme du milieu sont également possibles. 2. Aspects économiques (1) Les certificats SSL coûtent de l'argent Plus le certificat est puissant, plus il n'est pas nécessaire pour les sites Web personnels et petits. utilisation des sites Web. (2) Les certificats SSL doivent généralement être liés à une IP. Plusieurs noms de domaine ne peuvent pas être liés à la même IP. Les ressources IPv4 ne peuvent pas prendre en charge cette consommation (SSL a des extensions qui peuvent résoudre partiellement ce problème, mais cela. est plus gênant. Cela nécessite également la prise en charge du navigateur et du système d'exploitation (Windows XP ne prend pas en charge cette extension). Compte tenu de la capacité installée de XP, cette fonctionnalité est presque inutile). (3) La mise en cache des connexions HTTPS n'est pas aussi efficace que HTTP. Les sites Web à fort trafic ne l'utiliseront que si cela est nécessaire. Le coût du trafic est trop élevé. (4) Les ressources côté serveur de connexion HTTPS sont beaucoup plus élevées, et la prise en charge de sites Web avec un peu plus de visiteurs nécessite des coûts plus élevés si tout le HTTPS est utilisé, le coût moyen du VPS est basé sur l'hypothèse que la plupart des ressources informatiques. sont inactifs. Va monter. (5) La phase de prise de contact du protocole HTTPS prend du temps et a un impact négatif sur la vitesse de réponse du site Web. Il n'y a aucune raison de sacrifier l'expérience utilisateur sauf si cela est nécessaire. <br/> <br/> en utilisant msyql Lorsque vous faites requêtes floues, il est naturel d'utiliser l'instruction like. Normalement, lorsque la quantité de données est faible, il n'est pas facile de voir l'efficacité de la requête, mais lorsque la quantité de données atteint des millions ou des dizaines de millions, l'efficacité de. la question est que l'efficacité est facilement apparente. A cette époque, l’efficacité des requêtes devient très importante ! <br/><br/> <br/><br/>Généralement, la requête floue similaire s'écrit comme (le champ a été indexé) : <br/><br/>SELECT `column` FROM `table` WHERE `field` like '%keyword %';<br/><br/>En utilisant expliquer pour expliquer l'instruction ci-dessus, l'instruction SQL n'utilise pas d'index et il s'agit d'une recherche de table complète. Si la quantité de données est extrêmement importante, il est concevable que l'efficacité finale soit atteinte. sera comme ça <br/><br/>Comparez l'écriture suivante : <br/><br/>SELECT `column` FROM `table` WHERE `field` like 'keyword%';<br/><br/>Utilisez expliquer pour voir ceci l'écriture. Les instructions SQL utilisent des index et l'efficacité de la recherche est grandement améliorée ! <br/><br/> <br/><br/>Mais parfois, lorsque nous effectuons des requêtes floues, nous ne voulons pas que tous les mots-clés soient interrogés au début, donc s'il n'y a pas d'exigences particulières, "keywork%" ne l'est pas approprié. Toutes les requêtes floues <br/><br/> <br/><br/>Pour le moment, nous pouvons envisager d'utiliser d'autres méthodes <br/><br/>1, méthode LOCATE ('substr', str, pos) <br/> Copier. code <br/><br/>SELECT LOCATE('xbar',`foobar`); <br/>###renvoie 0 <br/><br/>SELECT LOCATE('bar',`foobarbar` <br/>##); # Return 4<br/><br/>SELECT LOCATE('bar',`foobarbar`,5);<br/>###Return 7<br/><br/>Copier le code<br/><br/>Remarque : renvoyer la substr in str La position de la première occurrence dans str. Si substr n'existe pas dans str, la valeur de retour est 0. Si pos existe, renvoie la position où substr apparaît pour la première fois après la pos-ème position dans str. Si substr n'existe pas dans str, la valeur de retour est 0. <br/><br/>SELECT `column` FROM `table` WHERE LOCATE('keyword', `field`)>0<br/><br/>Remarque : le mot-clé est le contenu à rechercher et le champ est le champ correspondant . Interrogez toutes les données avec la méthode mot-clé <br/><br/> <br/><br/>2.POSITION('substr' IN `field`) <br/><br/>position peut être considérée comme un alias de localisation, et sa fonction. est identique à la méthode Locate Same<br/><br/>SELECT `column` FROM `table` WHERE POSITION('keyword' IN `filed`)<br/><br/>3. <br/><br/>SELECT `column` FROM `table` WHERE INSTR(`field`, 'keyword' )>0 <br/><br/> <br/><br/>En plus des méthodes ci-dessus, il existe également une fonction FIND_IN_SET<br/><br/>FIND_IN_SET(str1,str2):<br/><br/>Renvoie l'index de position de str1 dans str2, où str2 doit être séparé par ",". <br/><br/>SELECT * FROM `personne` WHERE FIND_IN_SET('apply',`name`);<br/> original 30 avril 2013 , 15:36:36 🎜> A :UNIONopérateur Le <br/>L'opérateur UNION fonctionne en combinant deux autres tables de résultats telles que TABLE1 et TABLE2) et dérivez un tableau de résultats en éliminant toutes les lignes en double dans le tableau. Lorsque ALL est utilisé avec UNION (c'est-à-dire UNION ALL), aucune suppression lignes en double. Dans les deux cas, chaque ligne du tableau dérivé provient soit de TABLE1, soit de TABLE2. <br/>B: SAUFOpérateur<br/>Le SAUF l'opérateur élimine en incluant toutes les lignes qui se trouvent dans TABLE1 mais pas dans TABLE2 Un résultat le tableau est dérivé de toutes les lignes en double. Lorsque TOUS est utilisé avec SAUF (SAUF TOUS), pas d'élimination Répéter rangées. <br/>C : INTERSECTOpérateur<br/>Le L'opérateur INTERSECT élimine toutes les lignes de répétition pour dériver un tableau de résultats. Lorsque ALL est utilisé avec INTERSECT (INTERSECT ALL), n'élimine pas Répétez les lignes. Remarque : Plusieurs lignes de résultats de requête utilisant des mots d'opérateur doivent être cohérentes. Il est préférable de le changer par l'instruction suivante<br/>--Union des deux ensembles de résultats Les opérations, y compris les lignes en double, ne sont pas triées ; SELECT *FROM dbo. UNION TOUS SELECT* DEdbo.banjinew; -- Effectuer une opération d'intersection sur les deux jeux de résultats, en excluant les lignes en double, et trier selon les règles par défaut SELECT *FROM dbo.banji INTERSECT SELECT * FROM dbo.banjinew; --运算符通过包括所有在TABLE1中但不在TABLE2中的行并消除所有重复行而派生出一个结果表 SELECT * FROM dbo.banji EXCEPT SELECT * FROM dbo.banjinew;<br/>有些DBMS不支持except all和intersect all <br/> 1. 接口<br/> 在php编程语言中接口是一个抽象类型,是抽象方法的集合。接口通常以interface来声明。一个类通过实现接口的方式,从而来实现接口的方法(抽象方法)。<br/> 接口定义: 特别注意:<br/> * 类全部为抽象方法(不需要声明abstract) <br/> * 接口抽象方法是public <br/> * 成员(字段)必须是常量 2. 继承<br/> 继承自另一个类的类被称为该类的子类。这种关系通常用父类和孩子来比喻。子类将继 <br/>承父类的特性。这些特性由属性和方法组成。子类可以增加父类之外的新功能,因此子类也 <br/>被称为父类的“扩展”。<br/> 在PHP中,类继承通过extends关键字实现。继承自其他类的类成为子类或派生类,子 <br/>类所继承的类成为父类或基类。 特别注意:<br/> 有时候并不需要父类的字段和方法,那么可以通过子类的重写来修改父类的字段和方法。 通过重写调用父类的方法<br/> 有的时候,我们需要通过重写的方法里能够调用父类的方法内容,这个时候就必须使用<br/> 语法:父类名::方法()、parent::方法()即可调用。<br/>final关键字可以防止类被继承,有些时候只想做个独立的类,不想被其他类继承使用。 3. 抽象类和方法<br/>抽象类特性:<br/>* 抽象类不能产生实例对象,只能被继承; <br/>* 抽象方法一定在抽象类中,抽象类中不一定有抽象方法; <br/>* 继承一个抽象类时,子类必须重写父类中所有抽象方法; <br/>* 被定义为抽象的方法只是声明其调用方式(参数),并不实现。 3. 多态<br/>多态是指OOP 能够根据使用类的上下文来重新定义或改变类的性质或行为,或者说接口的多种不同的实现方式即为多态。<br/> Recommandations associées : <br/> Objet d'identification orienté objet PHP Idées de développement et analyse de cas de programmation orientée objet PHP Connaissances pratiques de base de l'objet PHP -orienté Ce qui précède est le contenu détaillé de l'introduction à l'héritage, au polymorphisme et à l'encapsulation orientés objet PHP. Pour plus d'informations, veuillez prêter attention aux autres articles connexes sur le site Web chinois de PHP ! Tag : Encapsulation polymorphe de PHP Article précédent : PHP implémente le partage de code de paiement de l'applet WeChat Article suivant : Session de contrôle de session PHP et introduction des cookies Recommandé pour vous 2018-02-1174 2018 - 02-1074 2018-02-1059 2018-01-0567 <br/> Le modèle MVC (Model-View-Controller) est l'un des modèles de ingénierie logicielle architecture logicielle qui transforment les logiciels. Le système est divisé en trois parties de base : modèle, vue et contrôleur. Le modèle MVC a été proposé pour la première fois par Trygve Reenskaug en 1978[1], qui est Un modèle de conception logicielle inventé par le centre de recherche Xerox Palo Alto (Xerox PARC) dans les années 1980 pour le langage de programmation Smalltalk. Le but du modèle MVC est de mettre en œuvre une conception de programme dynamique, de simplifier les modifications et extensions ultérieures du programme et de permettre la réutilisation de certaines parties du programme. De plus, ce mode rend la structure du programme plus intuitive en simplifiant la complexité. Le système logiciel sépare ses parties de base et donne également à chaque partie de base ses fonctions qui lui sont dues. Les professionnels peuvent être regroupés selon leur propre expertise : (Contrôleur) - Responsable de l'acheminement des demandes et de leur traitement. (Vue) - Les concepteurs d'interfaces conçoivent des interfaces graphiques. (Modèle) - Les programmeurs écrivent les fonctions que les programmes devraient avoir (implémenter des algorithmes, etc.), les experts en bases de données effectuent la gestion des données et la conception de bases de données (peuvent implémenter des fonction). Vue : Aucun véritable traitement n'a lieu dans la vue, que les données soient stockées en ligne ou dans une liste d'employés. En tant que vue, cela sert simplement à générer des données et à permettre à l'utilisateur de les manipuler. <br/>Modèle : <br/>Le modèle représente les données de l'entreprise et les règles métier. Parmi les trois composants de MVC, le modèle comporte le plus de tâches de traitement . Par exemple, il peut utiliser des objets composants tels que les EJB et ColdFusionComponents pour gérer les bases de données. Les données renvoyées par le modèle sont neutres, c'est-à-dire que le modèle n'a rien à voir avec le format des données, de sorte qu'un modèle peut fournir des données pour plusieurs vues . La duplication de code est réduite car le code appliqué au modèle ne doit être écrit qu'une seule fois et peut être réutilisé par plusieurs vues. <br/>Contrôleur : <br/>Contrôleur accepte les entrées de l'utilisateur et appelle des modèles et des vues pour compléter les besoins de l'utilisateur. . Ainsi, lorsque l'on clique sur un lien hypertexte dans une page Web et qu'un formulaire HTML est envoyé, le contrôleur lui-même ne génère rien et n'effectue aucun traitement. Il reçoit simplement la demande et décide quel composant de modèle appeler pour gérer la demande, puis détermine quelle vue utiliser pour afficher les données renvoyées. <br/> Avantages de MVC<br/>1. Faible couplage<br/> La couche vue et la couche métier sont séparées, ce qui permet le vue à modifier le code de couche sans avoir à recompiler le code du modèle et du contrôleur De même, les modifications apportées au processus métier ou aux règles métier d'une application nécessitent uniquement des modifications de la couche modèle de MVC. Le modèle étant séparé du contrôleur et de la vue, il est facile de modifier la couche de données et les règles métier de l'application. <br/>2. Haute réutilisabilité et applicabilité <br/> Avec l'avancement continu de la technologie, de plus en plus de méthodes sont désormais nécessaires pour accéder à l'application. Le modèle MVC vous permet d'utiliser une variété de styles de vues différents pour accéder au même code côté serveur. Il inclut n'importe quel navigateur WEB (HTTP) ou sans fil (wap). Par exemple, les utilisateurs peuvent commander un certain produit via un ordinateur ou un téléphone mobile. Bien que les méthodes de commande soient différentes, la manière de traiter les produits commandés est la même. Les données renvoyées par le modèle n'étant pas formatées, le même composant peut être utilisé par différentes interfaces. Par exemple, de nombreuses données peuvent être représentées par HTML, mais elles peuvent également être représentées par WAP, et les commandes requises pour ces représentations doivent modifier l'implémentation de la couche de vue, tandis que la couche de contrôle et la couche de modèle n'ont pas besoin de le faire. apporter des modifications. <br/>3. Coût du cycle de vie réduit <br/> MVC réduit le contenu technique du développement et de la maintenance des interfaces utilisateur. <br/>4. Déploiement rapide <br/>L'utilisation du modèle MVC peut réduire considérablement le temps de développement, ce qui oblige les programmeurs (développeurs Java) à se concentrer sur la logique métier, les programmeurs d'interface (développeurs HTML et JSP) se concentrent sur la présentation. <br/>5. Maintenabilité <br/> Séparer la couche de vue et la couche de logique métier rend également les applications WEB plus faciles à maintenir et à modifier. <br/>6. Propice à la gestion de l'ingénierie logicielle <br/> Étant donné que différentes couches remplissent leurs propres tâches, différentes applications à chaque couche ont certaines Les mêmes caractéristiques sont propice à la gestion du code du programme grâce à l’ingénierie et à l’outillage. Extension : WAP (Wireless Application Protocol) est Wireless Application Protocol est un protocole de communication réseau global. Le WAP fournit une norme commune pour l'Internet mobile et son objectif est d'introduire la richesse des informations et les services avancés de l'Internet dans les terminaux sans fil tels que les téléphones mobiles. Le WAP définit une plate-forme universelle qui convertit les informations actuelles du langage HTML sur Internet en informations décrites en WML (Wireless Markup Language), qui sont affichées sur l'écran du téléphone mobile. Le WAP nécessite uniquement la prise en charge des téléphones mobiles et des serveurs proxy WAP, et ne nécessite aucune modification des protocoles réseau du réseau de communication mobile existant, il peut donc être largement utilisé dans GSM, CDMA , TDMA, 3G et autres réseaux. L'accès Internet mobile devenant le nouveau chouchou de l'ère Internet, diverses exigences d'application pour le WAP sont apparues. Certains appareils portables, tels que les PDA, après avoir installé un micro-navigateur, utilisent le WAP pour accéder à Internet. Le fichier du micro-navigateur est très petit, ce qui permet de mieux résoudre les limitations liées à la petite mémoire des appareils portables et à la bande passante insuffisante du réseau sans fil. Bien que le WAP puisse prendre en charge HTHL et XML, WML est un langage spécialement conçu pour les petits écrans et les appareils portables sans clavier. WAP prend également en charge WMLScript. Ce langage de script est similaire à JavaScript, mais nécessite moins de mémoire et de processeur car il n'a fondamentalement aucun autre langage de script Contient des fonctionnalités inutiles . <br/> 11 <br/> Généralement, les navigateurs limiteront le nombre de requêtes simultanées (chargement de fichiers) sous un nom de domaine unique. , il y en a généralement au plus 4, puis le complément 5 sera bloqué jusqu'à ce qu'un fichier précédent soit chargé. Parce que les fichiers CDN sont stockés dans des zones différentes ( IP différentes), donc pour le navigateur C'est possible pour charger tous les fichiers nécessaires à la page en même temps (bien plus que 4), augmentant ainsi la vitesse de chargement de la page. Certains js ou bibliothèque de style css, comme jQuery, sont très couramment utilisées sur Internet de. Lorsqu'un utilisateur navigue sur l'une de vos pages web, il est très probable qu'il ait visité un autre site web via le CDN utilisé par votre site web. Il arrive que ce site web dispose également de If <. 🎜>jQuery est utilisé, alors le navigateur de l'utilisateur a déjà mis en cache le fichier jQuery (identique à IP< Si le (un fichier du même nom que 🎜> est mis en cache, le navigateur utilisera directement le fichier mis en cache et ne le chargera plus), il ne sera donc pas chargé à nouveau, améliorant ainsi indirectement la vitesse d'accès du site Web. 3. Haute efficacité NB Ni NB BaiduNBGoogle, non ? Un bon CDN offrira une plus grande efficacité, une latence réseau plus faible et un taux de perte de paquets plus faible. 4. Centre de données distribué Si votre site est situé à Pékin, lorsqu'un utilisateur de Hong Kong ou plus loin Quand En accédant à votre site, sa demande de données sera forcément très lente. Et les CDN permettront à l'utilisateur de charger les fichiers requis depuis le nœud le plus proche de lui, il est donc naturel que la vitesse de chargement soit améliorée. 5. Contrôle de version intégré Habituellement, pour CSS Les bibliothèques Fichiers et JavaScript ont toutes des numéros de version. Vous pouvez charger les fichiers requis à partir des CDN via un numéro de version spécifique. fichier, vous pouvez également utiliser latest pour charger la dernière version (non recommandé). 6. Analyse de l'utilisation Généralement CDN Fournisseurs ( tels que Baidu Cloud Acceleration) fournira des fonctions de statistiques de données, qui permettront d'en savoir plus sur les visites des utilisateurs sur leurs propres sites Web et d'apporter des ajustements opportuns et appropriés à leurs propres sites sur la base de données statistiques. 7. Empêcher efficacement le site Web d'être attaqué Dans des circonstances normales CDN Le fournisseur fournira également des services de sécurité du site Web. <br/> ? 3. L'interconnexion des FAI, c'est-à-dire l'interconnexion entre les fournisseurs de services Internet, comme l'interconnexion entre China Telecom et China Unicom. Lorsqu'un serveur de site Internet est déployé dans la salle informatique de l'opérateur A, et que les utilisateurs de l'opérateur B souhaitent accéder au site Internet, ils doivent passer par le point d'interconnexion entre A et B pour un accès cross-réseau. Du point de vue de l'architecture d'Internet, la bande passante d'interconnexion entre les différents opérateurs ne représente qu'une très faible proportion du trafic réseau de tout opérateur. Il s’agit donc souvent d’un point de congestion pour la transmission sur le réseau. <br/>4. Transmission de base longue distance. Le premier est le problème du délai de transmission longue distance, et le second est le problème de congestion du réseau fédérateur. Ces problèmes entraîneront une congestion dans la transmission du trafic World Wide Web. <br/>D'après l'analyse ci-dessus de la congestion du réseau, si les données sur le réseau sont fournies directement de la station source à l'utilisateur, une congestion de l'accès se produira très probablement. <br/>S'il existe une solution technique pour mettre en cache les données à l'endroit le plus proche de l'utilisateur afin que celui-ci puisse les obtenir à la vitesse la plus rapide, cela jouera un grand rôle dans la réduction de la pression de la bande passante d'exportation du site Web et dans la réduction de la transmission réseau. congestion. grand effet. CDN est exactement une telle solution technique. <br/> Le processus permettant aux utilisateurs d'accéder aux sites Web traditionnels (sans CDN) via un navigateur est le suivant. <br/> Si un CDN est utilisé, le processus deviendra le suivant. <br/> Après avoir introduit le CDN entre le site Web et l'utilisateur, l'utilisateur ne se sentira pas différent de celui d'origine. <br/>Les sites Web qui utilisent les services CDN doivent uniquement confier les droits de résolution de leurs noms de domaine au dispositif d'équilibrage de charge du CDN. Le dispositif d'équilibrage de charge CDN sélectionnera un serveur de cache approprié pour l'utilisateur, et l'utilisateur obtiendra ses propres informations. en accédant à ce serveur de cache les données requises. <br/>Étant donné que le serveur de cache est déployé dans la salle informatique des opérateurs de réseau et que ces opérateurs sont les fournisseurs de services réseau des utilisateurs, les utilisateurs peuvent accéder au site Web par le chemin le plus court et la vitesse la plus rapide. Par conséquent, CDN peut accélérer l’accès des utilisateurs et réduire la pression de charge sur le centre d’origine. <br/> <br/> Stratégie d'équilibrage de charge : 1. Round Robin : Chaque requête du réseau est distribuée tour à tour aux serveurs internes, de 1 à N puis recommence. Cet algorithme d'équilibrage convient aux situations dans lesquelles tous les serveurs du groupe de serveurs ont la même configuration matérielle et logicielle et où les demandes de service moyennes sont relativement équilibrées. 2. Weighted Round Robin : Selon les différentes capacités de traitement du serveur, différents poids sont attribués à chaque serveur afin qu'il puisse accepter les demandes de service avec les poids correspondants. Par exemple : le poids du serveur A est conçu pour être de 1, le poids de B est de 3 et le poids de C est de 6, alors les serveurs A, B et C recevront 10 %, 30 % et 60 % du service. demandes respectivement. Cet algorithme d'équilibrage garantit que les serveurs hautes performances sont davantage utilisés et empêche la surcharge des serveurs peu performants. 3. Balance aléatoire (Aléatoire) : Distribuez de manière aléatoire les requêtes du réseau vers plusieurs serveurs internes. 4. Aléatoire pondéré : cet algorithme d'équilibrage est similaire à l'algorithme de round-robin pondéré, mais il s'agit d'un processus de sélection aléatoire lors du traitement des demandes de partage. 5. Équilibrage du temps de réponse (Response Time) : le dispositif d'équilibrage de charge envoie une requête de détection (telle que Ping) à chaque serveur interne, puis décide lequel en fonction du temps de réponse le plus rapide de chaque serveur interne. la requête de détection. Un serveur pour répondre aux requêtes de service client. Cet algorithme d'équilibrage peut mieux refléter l'état de fonctionnement actuel du serveur, mais le temps de réponse le plus rapide fait uniquement référence au temps de réponse le plus rapide entre le périphérique d'équilibrage de charge et le serveur, et non au temps de réponse le plus rapide entre le client et le serveur. 6. Moins d'équilibrage de connexion : la durée pendant laquelle chaque service de demande client reste sur le serveur peut avoir une grande différence à mesure que le temps de travail augmente, si un simple algorithme de tournoi à tour de rôle ou d'équilibrage aléatoire est utilisé, le processus de connexion sur chaque serveur peut. varient considérablement et un véritable équilibrage de charge n’est pas atteint. L'algorithme d'équilibrage du nombre minimum de connexions comporte un enregistrement de données pour chaque serveur qui doit être chargé en interne, enregistrant le nombre de connexions en cours de traitement par le serveur. Lorsqu'il y a une nouvelle demande de connexion au service, la demande en cours sera attribuée au serveur. serveur avec le moins de connexions. Le serveur rend l'équilibre plus cohérent avec la situation réelle et la charge est plus équilibrée. Cet algorithme d'équilibrage convient aux services de traitement de requêtes à long terme, tels que FTP. 7. Équilibrage de la capacité de traitement : cet algorithme d'équilibrage attribuera les demandes de service au serveur avec la charge de traitement interne la plus légère (en fonction du modèle de processeur du serveur, du nombre de processeurs, de la taille de la mémoire et du nombre actuel de connexions, etc. ), car il prend en compte la puissance de traitement du serveur interne et les conditions de fonctionnement actuelles du réseau, cet algorithme d'équilibrage est relativement plus précis, particulièrement adapté à l'équilibrage de charge de couche 7 (couche application). 8. Équilibrage des réponses DNS (Flash DNS) : Sur Internet, qu'il s'agisse de requêtes HTTP, FTP ou autres, le client trouve généralement l'adresse IP exacte du serveur grâce à la résolution de nom de domaine. Sous cet algorithme d'équilibrage, les périphériques d'équilibrage de charge situés dans différents emplacements géographiques reçoivent une demande de résolution de nom de domaine du même client et résolvent le nom de domaine en adresse IP de leur serveur correspondant (c'est-à-dire le périphérique d'équilibrage de charge) en même temps. . L'adresse IP du serveur dans le même emplacement géographique) et la renvoie au client, le client continuera à demander des services avec la première adresse IP de résolution de nom de domaine reçue et ignorera les autres réponses d'adresse IP. Lorsque cette stratégie d’équilibrage convient à l’équilibrage de charge global, elle n’a aucun sens pour l’équilibrage de charge local. Méthodes et capacités de détection des pannes de service : 1. Détection ping : Détecter l'état du serveur et du système réseau via ping. Détecte approximativement si le système d'exploitation sur le réseau et le serveur est normal, mais il ne peut pas détecter les services d'application sur le serveur. 2. Détection d'ouverture TCP : chaque service ouvrira une connexion TCP et détectera si un certain port TCP sur le serveur (tel que le port Telnet 23, le port HTTP 80, etc.) est ouvert pour déterminer si le service est normal. 3. Détection d'URL HTTP : Par exemple, si une demande d'accès au fichier main.html est envoyée au serveur HTTP, si un message d'erreur est reçu, le serveur est considéré comme défaillant. <br/> <br/> 1. Cache de contenu dynamique 2. Cache du navigateur 3. cache 4. Cache proxy inverse 5. Cache distribué 6 . 🎜> Il existe de nombreuses méthodes d'implémentation pour la mise en cache des pages, telles que des moteurs de modèles comme Smarty ou des frameworks MVC comme Zend et Diango. Le contrôleur et la vue sont séparés, et le contrôleur peut facilement avoir son propre contrôle de cache. Habituellement, nous stockons le cache du contenu dynamique sur le disque Le disque offre un moyen peu coûteux de stocker un grand nombre de fichiers, alors ne vous inquiétez pas, l'élimination de la mise en cache en raison de problèmes d'espace est une approche simple et facile à déployer. Cependant, il est toujours possible qu'il y ait un grand nombre de fichiers de cache dans le répertoire de cache, ce qui oblige le processeur à passer beaucoup de temps à parcourir le répertoire. Pour résoudre ce problème, les hiérarchies de répertoires de cache peuvent être utilisées pour résoudre ce problème. que les sous-répertoires sous chaque répertoire sont Ou gardez le nombre de fichiers dans une petite plage. De cette manière, lorsqu'un grand nombre de fichiers cache sont stockés, la consommation de temps du processeur parcourant le répertoire peut être réduite. Lorsque les données du cache sont stockées dans des fichiers disque, il y a une surcharge d'E/S disque pour chaque charge de cache et contrôle d'expiration, et est également affectée par la charge du disque. Si la charge d'E/S disque est importante, le cache. fichier Il y aura un certain retard dans les opérations d'E/S. De plus, vous pouvez placer le cache dans la mémoire locale, ce qui peut être facilement implémenté à l'aide du module APC de PHP ou de l'extension de cache PHP XCache, afin qu'il n'y ait pas de disque I lors du chargement du cache /O opérations. Enfin, le cache peut également être stocké dans un serveur de cache indépendant Memcached peut être utilisé pour stocker facilement le cache sur d'autres serveurs via TCP. L'utilisation de memcached sera légèrement plus lente que l'utilisation de la mémoire locale, mais par rapport au stockage du cache dans la mémoire locale, l'utilisation de memcached pour implémenter la mise en cache présente deux avantages : La mémoire du serveur Web est précieuse, impossible de fournir une grande quantité d'espace pour la mise en cache HTML. L'utilisation d'un serveur de cache distinct offre une bonne évolutivité. Puisque nous parlons de cache, nous devons parler de contrôle d'expiration. Le contrôle d'expiration du cache est principalement basé sur la validité du cache. période Vérifiez, il existe deux mécanismes principaux : En fonction de l'heure de création du cache, de la durée de validité du cache et de l'heure actuelle, pour déterminer si elle a expiré. , c'est-à-dire si l'heure actuelle est éloignée de l'heure de création du cache. Si la durée dépasse la période de validité, le cache est considéré comme expiré. Juge basé sur le délai d'expiration du cache et l'heure actuelle. Il n'est pas facile de définir la période de validité du cache si elle est trop longue, même si le taux de réussite du cache est élevé, le contenu dynamique ne sera pas mis à jour à temps ; trop court, bien que le contenu dynamique soit mis à jour, en temps opportun, mais le taux de réussite du cache est réduit. Par conséquent, il est très important de fixer une période de validité raisonnable, mais plus important encore, nous devons être en mesure de comprendre quand la période de validité doit être modifiée, puis de trouver une valeur appropriée à tout moment. En plus de la période de validité du cache, le cache fournit également une méthode de contrôle pour vider le cache de force à tout moment . Dans certains cas, le contenu d'une certaine zone de la page doit être mis à jour à temps si l'intégralité du cache de la page est reconstruite à cause d'une zone. doit être mis à jour à temps, il semblera que cela n'en vaut pas la peine. Les frameworks de modèles populaires fournissent une prise en charge partielle sans cache, comme Smary. La méthode précédente doit contrôler dynamiquement l'utilisation du cache. La méthode statique génère du contenu statique à partir du contenu dynamique, puis permet aux utilisateurs de demander directement du contenu statique, améliorant considérablement le contenu statique. taux de débit. De même, le contenu statique doit également être mis à jour. Il existe généralement deux méthodes : Régénérer le contenu statique lorsque les données sont mises à jour. Régénérez régulièrement le contenu statique. Semblable au cache dynamique mentionné précédemment, les pages statiques n'ont pas besoin de mettre à jour la page entière. Chaque page partielle peut être mise à jour indépendamment grâce à la technologie d'inclusion de serveur (SSI), réduisant ainsi considérablement la reconstruction. . Surcharge de calcul et surcharge d’E/S disque pour la page entière, ainsi que surcharge d’E/S réseau pendant la distribution. De nos jours, les serveurs Web grand public prennent en charge la technologie SSI, comme Apache, lighttpd, etc. Dans une perspective de collusion, les gens sont habitués à considérer les navigateurs comme un simple logiciel sur leur PC, mais en fait, Les navigateurs sont importants pour le Web sites. Composants . Si vous mettez le contenu en cache sur le navigateur, vous pouvez non seulement réduire la charge informatique du serveur, mais également éviter le gaspillage inutile de transmission et de bande passante. Afin de stocker le contenu mis en cache côté navigateur, un répertoire est généralement créé dans le système de fichiers de l'utilisateur pour stocker les fichiers mis en cache, et chaque fichier mis en cache reçoit certaines balises nécessaires, telles que l'heure d'expiration, etc. De plus, les différents navigateurs présentent des différences subtiles dans la manière dont ils stockent les fichiers de cache. Le contenu du cache du navigateur est stocké côté navigateur et le contenu est généré par le serveur Web. Pour utiliser le cache du navigateur, le navigateur et le serveur Web doivent communiquer. est HTTP "Cache Négociation" dans . 当 Web 服务器接收到浏览器请求后,Web 服务器需要告知浏览器哪些内容可以缓存,一旦浏览器知道哪些内容可以缓存后,下次当浏览器需要请求这个内容时,浏览器便不会直接向服务器请求完整内容,二是询问服务器是否可以使用本地缓存,服务器在收到浏览的询问后回应是使用浏览器本地缓存还是将最新内容传回给浏览器。 Last-Modified Last-Modified 是一种协商方式。通过动态程序为 HTTP 相应添加最后修改时间的标记 此时,Web 服务器的响应头部会多出一条: 这代表 Web 服务器对浏览器的暗示,告诉浏览器当前请求内容的最后修改时间。收到 Web 服务器响应后,再次刷新页面,注意到发出的 HTTP 请求头部多了一段标记: 这表示浏览器询问 Web 服务器在该时间后是否有更新过请求的内容,此时,Web 服务器需要检查请求的内容在该时间后是否有过更新并反馈给浏览器,这其实就是缓存过期检查。 如果这段时间里请求的内容没有发生变化,服务器做出回应,此时,Web 服务器响应头部: 注意到此时的状态码是304,意味着 Web 服务器告诉浏览器这个内容没有更新,浏览器使用本地缓存。如下图所示: ETag HTTP/1.1 还支持ETag缓存协商方法,与最后过期时间不同的是,ETag不再采用内容的最后修改时间,而是采用一串编码来标记内容,称为ETag,如果一个内容的 ETag 没有变化,那么这个内容就一定没有更新。 ETag 由 Web 服务器生成,浏览器在获得内容的 ETag 后,会在下次请求该内容时,在 HTTP 请求头中附加上相应标记来询问服务器该内容是否发生了变化: 这时,服务器需要重新计算这个内容的 ETag,并与 HTTP 请求中的 ETag 进行对比,如果相同,便返回 304,若不同,则返回最新内容。如下图所示,服务器发现请求的 ETag 与重新计算的 ETag 不同,返回最新内容,状态码为200。 Last-Modified VS ETag 基于最后修改时间的缓存协商存在一些缺点,如有时候文件需频繁更新,但内容并没有发生变化,这种情况下,每次文件修改时间变化后,无论内容是否发生变化,都会重新获取全部内容。另外,在采用多台 Web 服务器时,用户请求可能在多台服务器间变化,而不同服务器上同一文件最后修改时间很难保证完全一样,便会导致重新获取所有内容。采用 ETag 方法就可以避免这些问题。 首先,原本使用浏览器缓存的动态内容,在使用浏览器缓存后,能否获得大的吞吐率提升,关键在于是否能避免一些额外的计算开销,同事,还取决于 HTTP 响应正文的长度,若 HTTP 响应较长,如较长的视频,则能带来大的吞吐率提到。 但使用浏览器缓存的最大价值并不在此,而在于减少带宽消耗。使用浏览器缓存后,如果 Web 服务器计算后发现可以使用浏览器端缓存,则返回的响应长度将大大减少,从而,大大减少带宽消耗。 The goal of caching in HTTP/1.1 is to eliminate the need to send requests in many cases. 在上面两图中,有个 对于主流浏览器,有三种请求页面方式: Ctrl + F5:强制刷新,使网页以及所有组件都直接向 Web 浏览器发送请求,并且不适用缓存协商,从而获取所有内容的最新版本。等价于按住 Ctrl 键后点击浏览器刷新按钮。 F5:允许浏览器在请求中附加必要的缓存协商,但不允许直接使用本地缓存,即让Last-Modified生效、Expires无效。等价于单击浏览器刷新按钮。 单击浏览器地址栏“转到”按钮或通过超链接跳转:浏览器对于所有没过期的内容直接使用本地缓存,Expires只对这种方式生效。等价于在地址栏输入 URL 后回车。 Expires指定的过期时间来源于 Web 服务器的系统时间,如果与用户本地时间不一致,就会影响到本地缓存的有效期检查。 一般情况下,操作系统都使用基于 GMT 的标准时间,然后通过时区来进行偏移计算,HTTP 中也使用 GMT 时间,所以,一般不会因为时区导致本地与服务器相差数个小时,但没人能保证本地时间与服务器一直,甚至有时服务器时间也是错误的。 针对这个问题,HTTP/1.1 添加了标记 Cache-Control,如上图1所示, HTTP 是浏览器与 Web 服务器沟通的语言,且是它们唯一的沟通方式,好好学学 HTTP 吧! 前面提到的动态内容缓存和静态化基本都是通过动态程序来实现的,下面讨论 Web 服务器自己实现缓存机制。 Web 服务器接收到 HTTP 请求后,需要解析 URL,然后将 URL 映射到实际内容或资源,这里的“映射”指服务器处理请求并生成响应内容的过程。很多时候,在一段时间内,一个 URL 对应一个唯一的响应内容,比如静态内容或更新不频繁的动态内容,如果将最终内容缓存起来,下次 Web 服务器接收到请求后可以直接将响应内容返回给浏览器,从而节省大量开销。现在,主流 Web 服务器都提供了对这种类型缓存的支持。 当使用 Web 服务器缓存时,如果直接命中,那么将省略后面的一系列操作,如 CPU 计算、数据库查询等,所以,Web 服务器缓存能带来较大性能提升,但对于普通 HTML 也,带来的性能提升较有限。 那么,缓存内容存储在什么位置呢?一般来说,本机内存和磁盘是主要选择,也可以采用分布式设计,存储到其它服务器的内存或磁盘中,这点跟前面提到的动态内容缓存类似,Apache、lighttpd 和 Nginx 都提供了支持,但配置上略有差别。 提到缓存,就不得不提有效期控制。与浏览器缓存相似,Web 服务器缓存过期检查仍然建立在 HTTP/1.1 协议上,要指定缓存有效期,仍然是在 HTTP 响应头中加入 这样一来,Web服务器就不会将这个动态内容缓存起来,当然,也有其它方法实现这个功能。 如果动态内容没有输出 Expires 标记,也可以采用 那么,是否可以使用 Web 服务器缓存取代动态程序自身的缓存机制呢?当然可以,但有些注意: 让动态程序依赖特定 Web 服务器,降低应用的可移植性。 Web 服务器缓存机制实质上是以 URL 为键的 key-value 结构缓存,所以,必须保证所有希望缓存的动态内容有唯一的 URL。 编写面向 HTTP 缓存友好的动态程序是唯一需要考虑的事。 对静态内容,特别是大量小文件站点, Web 服务器很大一部分开销花在了打开文件上,所以,可以考虑将打开后的文件描述符直接缓存到 Web 服务器的内存中,从而减少开销。但是,缓存文件描述符仅仅适用于静态内容,而且仅适用于小文件,对大文件,处理它们的开销主要在传送数据上,打开文件开销小,缓存文件描述符带来的收益小。 代理(Proxy),也称网络代理,是一种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接。提供代理服务的电脑系统或其它类型的网络终端称为代理服务器(Proxy Server)。 Ce qui précède est la définition du proxy donnée par Wikipédia. Dans ce cas, l'utilisateur est caché derrière le serveur proxy. Ensuite, le serveur proxy inverse est exactement le contraire. Le mécanisme est Reverse Proxy. De même, le serveur qui implémente ce mécanisme est appelé Reverse Proxy Server. Nous appelons généralement le serveur Web derrière le serveur proxy inverse le serveur back-end (serveur back-end). De manière correspondante, le serveur proxy inverse est appelé serveur frontal (serveur front-end). est exposé à Internet, le serveur Web principal y est connecté via le réseau interne et les utilisateurs accéderont indirectement au serveur Web via le serveur proxy inverse, ce qui apporte non seulement un certain degré de sécurité, mais permet également le cache- accélération basée. Il existe de nombreuses façons d'implémenter un proxy inverse, comme le serveur Nginx le plus courant qui peut être utilisé comme serveur proxy inverse. Pour que les navigateurs des utilisateurs et les serveurs Web fonctionnent correctement, ils doivent passer par le serveur proxy inverse. Par conséquent, le serveur proxy inverse a un grand contrôle. Les informations d'en-tête HTTP qui le traversent peuvent être réécrites par n'importe quel moyen, ou d'autres mécanismes personnalisés peuvent être utilisés pour intervenir directement dans la stratégie de cache. Comme nous le savons grâce au contenu précédent, les informations d'en-tête HTTP déterminent si le contenu peut être mis en cache. Par conséquent, afin d'améliorer les performances, le serveur proxy inverse peut modifier les informations d'en-tête HTTP des données qui le traversent pour déterminer quel contenu peut être mis en cache. mis en cache et qui ne peuvent pas être mis en cache. Le serveur proxy inverse fournit également la fonction de vider le cache. Cependant, contrairement au cache de contenu dynamique, dans le cache de contenu dynamique, nous pouvons supprimer activement la mise en cache. La méthode implémente les mises à jour avant l'expiration du cache, mais le mécanisme de mise en cache du proxy inverse basé sur HTTP n'est pas facile à mettre en œuvre. Le programme dynamique back-end ne peut pas supprimer activement un contenu mis en cache à moins que la zone de cache sur le serveur proxy inverse ne soit effacée. Il existe de nombreux systèmes de mise en cache distribués matures, tels que memcached. Afin de réaliser la mise en cache, nous ne placerons pas le contenu du cache sur le disque. Sur la base de ce principe, memcached utilise la mémoire physique comme zone de cache et utilise la valeur-clé pour stocker les données. Il s'agit d'une structure à index unique et d'une forme d'organisation des données. .Nous appelons chaque clé et la valeur correspondante un élément de données. Tous les éléments de données sont indépendants les uns des autres. Chaque élément de données utilise la clé comme index unique. Les utilisateurs peuvent lire ou mettre à jour cet élément de données via une clé. L'algorithme est utilisé pour concevoir la structure des données de stockage et un allocateur de mémoire soigneusement conçu est utilisé pour que la complexité du temps de requête des éléments de données atteigne O (1). memcached utilise un mécanisme d'élimination basé sur l'algorithme LRU (Lease Récemment Utilisé) pour éliminer les données. En même temps, le délai d'expiration peut également être défini pour les éléments de données. été discuté précédemment. En tant que système de cache distribué, memcached peut s'exécuter sur un serveur indépendant et le contenu dynamique est accessible via TCP Socket. Dans ce cas, le modèle de traitement simultané du réseau de memcached est très important. Memcached utilise la bibliothèque de fonctions libevent pour implémenter le modèle de concurrence réseau. Memcached peut être utilisé dans un environnement avec un grand nombre d'utilisateurs simultanés. Lors de l'utilisation du système de cache pour implémenter des opérations de lecture, cela équivaut à utiliser le "cache de pré-lecture" de la base de données, ce qui peut grandement améliorer le débit . Pour les opérations d'écriture, les systèmes de mise en cache peuvent également apporter d'énormes avantages. Les opérations d'écriture de données courantes incluent l'insertion, la mise à jour et la suppression. Ces opérations d'écriture sont souvent accompagnées de recherches et de mises à jour d'index, ce qui entraîne souvent une surcharge considérable. Lors de l'utilisation du cache distribué, nous pouvons stocker temporairement des données dans le cache, puis effectuer des opérations d'écriture par lots. En tant que système de cache distribué, memcached peut bien accomplir des tâches. En même temps, memcached fournit également des protocoles qui nous permettent d'obtenir son statut en temps réel, dont il existe. Il existe plusieurs informations importantes : Utilisation de l'espace : prêter attention à l'utilisation de l'espace du cache peut nous indiquer quand nous devons étendre le système de cache pour éviter l'élimination passive des données en raison de l'espace du cache étant plein. Taux de réussite du cache Trafic d'E/S : reflète la charge de travail du système de cache, à partir duquel vous pouvez savoir si Memcached est inactif ou occupé. Les capacités de traitement simultané, la capacité de l'espace de cache, etc. peuvent atteindre leurs limites et l'expansion est inévitable. Lorsqu'il y a plusieurs serveurs de cache, le problème auquel nous sommes confrontés est le suivant : comment équilibrer répartir les données du cache sur plusieurs serveurs de cache ? Dans ce cas, vous pouvez choisir une méthode de partitionnement basée sur les clés pour répartir uniformément les clés de tous les éléments de données sur différents serveurs, par exemple en utilisant la méthode du reste. Dans ce cas, lorsque nous étendons le système, en raison de changements dans l'algorithme de partitionnement, nous devrons migrer les données mises en cache d'un serveur de cache à un autre. En fait, il n'est pas du tout nécessaire d'envisager la migration <🎜. > Comme il s'agit de données mises en cache, reconstruisez simplement le cache. <br/> et pseudo-statique . Deuxièmement, PHP dispose de différents mécanismes de traitement pour générer des pages statiques. : PHP génère des fichiers HTML Pseudo-statique <br/> : Stocke le contenu dans la mémoire nosql (memcached), puis accède directement à la page lors de la lecture de mémoire. Statisation des grands sites Web dynamiques S'il s'agit d'un site Web dynamique, notamment un site Web qui utilise une , il est difficile d'augmenter efficacement la capacité d'accès simultané du site Web en augmentant le nombre de serveurs Web. Par exemple, Taobao et JD.com. Solution statique : rendre les sites Web dynamiques statiques. Par rapport aux deux autres pages (pages dynamiques et pages pseudo-statiques), elle est la plus rapide et n'a pas besoin d'extraire les données de la base de données. Elle est rapide et ne mettra pas de pression sur le serveur. Inconvénients : Comme les données sont stockées en HTML, le fichier est très volumineux. Et le problème le plus grave est que si vous modifiez le code source, vous devez modifier l'intégralité du code source. Vous ne pouvez pas modifier un seul endroit et les pages statiques de l'ensemble du site seront automatiquement modifiées. S'il s'agit d'un grand site Web contenant beaucoup de données, il occupera beaucoup d'espace sur le serveur et une nouvelle page HTML sera générée à chaque fois que du contenu est ajouté. La maintenance est gênante si vous n'êtes pas un professionnel. 2. Page dynamique Avantages : L'utilisation de l'espace est très faible, généralement pour les sites Web comptant des dizaines de milliers de sites Web. données, en utilisant des pages dynamiques, la taille du fichier peut être de seulement quelques M, tandis qu'en utilisant des pages statiques, elle peut être aussi petite que dix M, jusqu'à des dizaines de M ou même plus. Étant donné que la base de données est extraite de la base de données, si vous devez modifier certaines valeurs et changer directement la base de données, toutes les pages Web dynamiques seront automatiquement mises à jour. Cet avantage par rapport aux pages statiques est évident. Inconvénients : La vitesse d'accès des utilisateurs est lente, pourquoi est-il lent pour accéder aux pages dynamiques ? Ce problème commence par le mécanisme d'accès aux pages dynamiques. En effet, il existe un moteur d'interprétation sur notre serveur lorsqu'un utilisateur y accède, ce moteur d'interprétation traduira la page dynamique en une page statique, afin que tout le monde puisse la visualiser dans le navigateur. Afficher le code source. Et ce code source est le code source après traduction par le moteur d'interprétation. En plus de la lenteur d'accès, les données des pages dynamiques sont appelées depuis la base de données. Si plus de personnes visitent, la pression sur la base de données sera très forte. Cependant, la plupart des programmes dynamiques actuels utilisent une technologie de mise en cache. Mais de manière générale, les pages dynamiques exercent une plus grande pression sur le serveur. Dans le même temps, les sites Web dotés de pages dynamiques ont généralement des exigences plus élevées en matière de serveurs. Plus il y a de personnes qui visitent en même temps, plus la pression sur le serveur est forte. 3. Page pseudo-statique Grâce à la réécriture d'url, index.php devient index.html<br/> Page pseudo-statiqueDéfinition : "Fausse" page statique, essentiellement une page dynamique. Avantages : Par rapport aux pages statiques, il n'y a pas d'amélioration évidente de la vitesse, car c'est une "fausse" page statique, mais c'est en fait une page dynamique, et elle doit aussi être traduit en une page statique de. Le plus gros avantage est que cela permet aux moteurs de recherche de traiter vos pages Web comme des pages statiques. Inconvénients : Comme son nom l'indique, "pseudo-statique" signifie "pseudo-statique". Les moteurs de recherche ne la traiteront pas comme une page statique. logique empirique, et pas nécessairement exacte. Peut-être que les moteurs de recherche le considèrent directement comme une page dynamique. Résumé simple : L'accès aux pages statiques est le plus rapide ; Les pages dynamiques prennent peu de place et sont simples à maintenir ; la vitesse d'accès est lente, et si de nombreuses personnes les visitent, cela mettra la pression sur la base de données. Il n'y a pas de différence essentielle entre l'utilisation du statique pur et du pseudo-statique pour le référencement (Search Engine Optimization : Search Engine Optimization). L'utilisation de pseudo-statique occupera une certaine quantité d'utilisation du processeur, et une utilisation intensive entraînera une surcharge du processeur. <br/> Je suis entré en contact avec le concept des sprites CSS à plusieurs reprises au cours de cette période, l'une lorsque j'utilisais du CSS pour créer une porte coulissante, et l'autre lorsque j'utilisais YSlow. pour analyser les performances d'un site Web, le concept de sprites CSS a suscité un vif intérêt. J'ai recherché beaucoup d'informations sur Internet, mais malheureusement la plupart ne contenaient que quelques mots. Beaucoup d'entre eux étaient des traductions directes d'informations étrangères, et certains sites Web d'informations étrangères directement recommandés Malheureusement, je n'ai pas réussi la langue anglaise. et fondamentalement, je ne comprenais aucun sprite CSS, sans parler de la façon de l'utiliser. Enfin, je me suis inspiré d'un article de Blue Ideal, et après y avoir longuement réfléchi, j'ai enfin compris la connotation. J'utiliserai ma compréhension pour aider les autres à maîtriser les sprites CSS plus rapidement. Permettez-moi d'abord de présenter brièvement le concept Concernant son concept, il est partout sur Internet, je vais donc le mentionner brièvement ici. Que sont les sprites CSS Les sprites CSS sont littéralement traduits en sprites CSS, mais cette traduction n'est évidemment pas suffisante. En fait, c'est en fusionnant plusieurs images en une seule, puis via CSS. Quelques techniques de mise en page sur des pages Web. Les avantages de cette méthode sont également évidents, car s'il y a beaucoup d'images, cela augmentera les requêtes http, ce qui réduira sans aucun doute les performances du site Web, en particulier pour les sites Web contenant beaucoup d'images. Si vous pouvez utiliser des sprites CSS pour réduire le nombre d'images. nombre de photos, cela entraînera une amélioration de la vitesse. 下面我们来用一个实例来理解css sprites,受蓝色理想中的《制作一副扑克牌系列教程》启发。 我们仅仅只需要制作一个扑克牌,拿黑桃10为例子。 可以直接把蓝色理想中融合好的一幅大图作为背景,这也是css sprites的一个中心思想,就是把多个图片融进一个图里面。 这就是融合后的图,相信对PS熟悉的同学应该很容易的理解,通过PS我们就可以组合多个图为一个图。 现在我们书写html的结构: 在这里我们来分析强调几点: 一:card为这个黑桃十的盒子或者说快,对p了解的同学应该很清楚这点。 二:我用span,b,em三种标签分别代表三种不同类型的图片,span用来表标中间的图片,b用来表示数定,em用来表示数字下面的小图标。 三:class里面的声明有2种,一个用来定位黑桃10中间的图片的位置,一个用来定义方向(朝上,朝下)。 上面是p基本概念,这还不是重点,不过对p不太清楚的同学可以了解。 下面我们重点谈下定义CSS: span{display:block;width:20px;height:21px; osition:absolute;background:url(images/card.gif) no-repeat;} 这个是对span容器的CSS定义,其他属性就不说了,主要谈下如何从这个里面来理解css sprites。 背景图片,大家看地址就是最开始我们融合的一张大图,那么如何将这个大图中的指定位置显示出来呢?因为我们知道我们做的是黑桃10,这个大图其他的图像我们是不需要的,这就用到了css中的overflow:hidden; 但大家就奇怪了span的CSS定义里面没有overflow:hidden啊,别急,我们已经在定义card的CSS里面设置了(这是CSS里面的继承关系): .card{width:125px;height:170px; position:absolute;overflow:hidden;border:1px #c0c0c0 solid;} 理解到这点还不够,还要知道width:125px;height:170px; 这个可以理解成是对这个背景图片的准确切割,当然其实并不是切割,而是把多余其他的部分给隐藏了,这就是overflow:hidden的妙用。 通过以上的部分的讲解,你一定可以充分的把握css sprites的运用,通过这个所谓的“切割”,然后再通过CSS的定位技术将这些图准确的分散到这个card里面去! PS:CSS的定位技术,大家可以参考其他资料,例如相对定位和绝对定位,这里我们只能尝试用绝对定位。 最后我们来补充一点: 为什么要采取这样的结构? span这个容器是主要作用就是存放这张大的背景图片,并在里面实现”切割“,span里面切割后的背景是所有内容块里面通用的! 后面class为什么要声明2个属性? 很显然,一个是用来定位内容块的位置,一个是用来定义内容块中的图像的朝上和朝下,方位的! 下面我们附上黑桃10的完整源码: 最后感谢蓝色理想提供的参考资料! <br/> <br/> 1、前言 J'ai récemment utilisé le proxy inverse au travail et j'ai découvert qu'il existe de nombreuses façons de jouer avec le proxy réseau. Il y a beaucoup de choses à apprendre derrière le réseau. Avant cela, je n'utilisais qu'un logiciel proxy. Pour accéder à Google, j'utilisais un logiciel proxy et je devais configurer l'adresse proxy dans le navigateur. Je ne connaissais que le concept d’agence, mais je ne savais pas qu’il existait une agence forward et une agence inversée, j’ai donc rapidement découvert ce concept et complété mes connaissances. Tout d'abord, déterminez ce qu'est un proxy direct et ce qu'est un proxy inverse, puis comment les deux sont démontrés dans une utilisation réelle, et enfin résumez à quoi sert le proxy direct et ce que le proxy inverse peut faire. 2. Proxy Forward Le proxy Forward est comme un tremplin, le proxy accède à des ressources externes. Par exemple : Je suis un utilisateur, je ne peux pas accéder à un site Web, mais je peux accéder à un serveur proxy. Je pouvais accéder au site Web auquel je ne pouvais pas accéder, alors je me suis d'abord connecté au serveur proxy et je lui ai dit que j'avais besoin du contenu du site Web auquel je ne pouvais pas accéder. Le serveur proxy est allé le récupérer, puis l'a renvoyé. moi. Du point de vue du site Web, il n'y a qu'un seul enregistrement lorsque le serveur proxy vient récupérer le contenu. Parfois, on ne sait pas qu'il s'agit de la demande de l'utilisateur, et les informations de l'utilisateur sont également masquées selon que le proxy en informe le site Web ou non. pas. Le client doit configurer un serveur proxy de transfert. Bien entendu, le principe est de connaître l'adresse IP du serveur proxy de transfert et le port du programme proxy. Par exemple, si vous avez déjà utilisé ce type de logiciel tel que CCproxy, http://www.ccproxy.com/ vous devez configurer l'adresse proxy dans le navigateur. En résumé : Le proxy de transfert est un serveur situé entre le client et le serveur d'origine (serveur d'origine qui obtient le). contenu, le client envoie une requête au proxy et spécifie la cible (serveur d'origine), puis le proxy transmet la requête au serveur d'origine et renvoie le contenu obtenu au client. Le client doit définir certains paramètres spéciaux pour utiliser le proxy de transfert. Objectif du proxy direct : (1) Accéder à des ressources qui étaient initialement inaccessibles, telles que Google (2) Peut être mis en cache pour accélérer l'accès aux ressources (3) Autoriser l'accès client et authentifier l'accès à Internet (4) L'agent peut enregistrer les enregistrements d'accès des utilisateurs (comportement en ligne gestion), Masquer les informations utilisateur de l'extérieur Par exemple, utilisation de CCProxy : 3. 🎜> Premier contact direction proxy Le sentiment est que le client ignore l'existence du proxy, et le proxy inverse est transparent pour le monde extérieur. Les visiteurs ne savent pas qu'ils visitent un proxy. Parce que le client ne nécessite aucune configuration pour y accéder. peut être exprimée à l'aide de deux images de Zhihu : https://www.zhihu.com/question/24723688 nginx prend en charge la configuration du proxy inverse et réalise l'équilibrage de charge du site Web via le proxy inverse. . Dans cette partie, nous écrivons d'abord une configuration nginx, puis nous devons étudier en profondeur le module proxy et le module d'équilibrage de charge de nginx. Référence : Proxy, comme son nom l'indique, signifie utiliser un tiers pour effectuer ce que vous voulez faire en votre nom, et non par vous-même. Vous pouvez imaginer qu'il existe un serveur intermédiaire supplémentaire (serveur proxy) entre la machine locale et. le serveur cible Un proxy de transfert est un serveur (serveur proxy) situé entre le client et le serveur d'origine Le client doit d'abord effectuer certains réglages nécessaires. (le serveur proxy doit être connu). IP et port), envoie d'abord chaque requête au serveur proxy. Une fois que le serveur proxy l'a transmise au serveur réel et a obtenu le résultat de la réponse, il le renvoie au serveur proxy. client. >Une explication simple est que le serveur proxy remplace le client pour accéder au serveur cible (Masquer le client )Fonction : Un proxy inverse est tout le contraire, il agit comme le serveur d'origine du client, et Expliquez simplement, le serveur proxy remplace le serveur cible pour accepter et renvoyer la demande du client (Masquer le serveur cible) <🎜. > Masquer le serveur d'origine et empêcher le serveur Les attaques malveillantes, etc., font croire au client que le serveur proxy est le serveur d'origine <🎜. > <. 🎜>Fonction CDN Permet aux clients d'accéder à n'importe quel site Web via celui-ci et le client lui-même est caché, vous devez donc prendre des mesures de sécurité pour vous assurer que seuls les clients autorisés sont servis. solution accélérée par réseau CDN utilise le principe technique du proxy inverse, et sa technologie de base la plus critique est le Smart DNS, etc. mysql utilise la méthode de synchronisation maître-esclave pour séparer la lecture et l'écriture et réduire la pression sur le serveur principal. Cette pratique est désormais très courante dans l'industrie. La synchronisation maître-esclave peut essentiellement réaliser une synchronisation en temps réel. J'ai emprunté le schéma de synchronisation maître-esclave sur un autre site Web. <br/> <br/> Une fois la synchronisation maître-esclave terminée, le serveur maître écrira la déclaration de mise à jour Entrez dans le binlog et lisez à partir du thread IO du serveur (Notez ici qu'il n'y avait qu'un seul thread IO avant la version 5.6.3, mais après la version 5.6.3, il y a plusieurs threads à lire, et la vitesse sera naturellement être accéléré) Revenez en arrière et lisez le binlog du serveur maître et écrivez-le dans le journal de relais du serveur esclave. Ensuite, le thread SQL du serveur esclave exécutera le sql dans le journal de relais un par un. pour effectuer une récupération de données. <br/> relais signifie transmission, course de relais signifie course de relais <br/> Synchronisation maître-esclave La raison. pour le délai Nous savons qu'un serveur ouvre N liens pour que les clients se connectent De cette façon, il y aura de grandes opérations de mise à jour simultanées, mais il n'y a qu'un seul thread qui lit le binlog du serveur. Premièrement, lorsqu'un certain SQL prend un peu plus de temps à s'exécuter sur le serveur esclave ou parce qu'un certain SQL doit verrouiller la table, cela entraînera un retard important de SQL sur le serveur maître et ne sera pas synchronisé avec le serveur esclave. Cela conduit à une incohérence maître-esclave, c'est-à-dire un retard maître-esclave. <br/> 2. Solution au délai de synchronisation maître-esclave En fait, il n'existe pas de solution unique au problème maître-esclave. délai de synchronisation. Cette méthode est due au fait que tout le SQL doit être exécuté sur le serveur esclave, mais si le serveur maître continue à avoir des opérations de mise à jour écrites en continu, une fois qu'un retard se produit, la possibilité d'aggraver le délai sera plus grande. Bien sûr, nous pouvons prendre certaines mesures d'atténuation. a. Nous savons que le serveur maître étant responsable des opérations de mise à jour, il a des exigences de sécurité plus élevées que le serveur esclave. Certains paramètres peuvent être modifiés, tels que sync_binlog=1, innodb_flush_log_at_trx_commit. = 1 Paramètres de classe, et l'esclave n'a pas besoin d'une sécurité de données aussi élevée. Vous pouvez définir sync_binlog sur 0 ou désactiver binlog, innodb_flushlog, innodb_flush_log_at_trx_commit<🎜. > peut également être défini sur 0 pour améliorer l'efficacité d'exécution de SQL. Cela peut grandement améliorer l'efficacité . L'autre consiste à utiliser un meilleur périphérique matériel que la bibliothèque principale comme esclave. <br/> 3. Méthode pour déterminer le délai maître-esclave MySQL fournit La commande slave server status peut être visualisée via show slave status. Par exemple, vous pouvez consulter la valeur du paramètre Seconds_Behind_Master pour déterminer s'il existe un délai maître-esclave. <br/>Il existe plusieurs valeurs : <br/>NULL - indique que io_thread ou sql_thread a échoué, c'est-à-dire que l'état d'exécution du thread est Non, pas Oui.<br/>0 - Cette valeur est zéro, ce que nous sommes extrêmement impatients de voir, indiquant que l'état de réplication maître-esclave est normal <br/> <br/> > 1. Redis prend en charge des types de stockage de données plus riches, String, Hash, List, Set et Sorted Set. . Memcached ne prend en charge que les structures clé-valeur simples. <br/>> 2. Le stockage clé-valeur Memcached a une utilisation de la mémoire plus élevée que Redis qui utilise une structure de hachage pour le stockage clé-valeur. <br/>> 3. Redis fournit des fonctions de transaction, qui peuvent garantir l'atomicité d'une série de commandes <br/>> 4. Redis prend en charge la persistance des données et peut conserver les données en mémoire sur le disque <br/>> utilise un seul cœur, tandis que Memcached peut utiliser plusieurs cœurs, donc en moyenne Redis a des performances plus élevées que Memcached lors du stockage de petites données sur chaque cœur. <br/><br/>- Comment Redis parvient-il à la persistance ? <br/><br/>> 1. Persistance RDB, sauvegarde de l'état de Redis en mémoire sur le disque dur, ce qui équivaut à sauvegarder l'état de la base de données. <br/>> 2. Persistance AOF (Append-Only-File), la persistance AOF enregistre la base de données en enregistrant l'état d'écriture de l'exécution du verrouillage du serveur Redis. Équivalent aux commandes reçues par la base de données de sauvegarde, toutes les commandes écrites sur AOF sont enregistrées au format du protocole Redis. <br/> <br/> <br/> Apache HTTP est un serveur modulaire qui peut fonctionner sur presque tous les < largement utilisés. 🎜>Plateforme informatique. Il appartient au serveur d'applications. Apache prend en charge de nombreux modules et a des performances stables Apache lui-même est une analyse statique, adaptée au HTML statique. , images, etc., mais peut prendre en charge des pages dynamiques, etc. via des scripts étendus, des modules, etc. (Apche peut prendre en charge PHPcgiperl, mais vous devez utiliser Java, vous avez besoin de Tomcat pour prendre en charge Apache en arrière-plan et utiliser Les requêtes Java sont transmises par Apache à Tomcat ) . >Inconvénients : La configuration est relativement complexe et ne prend pas en charge les pages dynamiques. Tomcat est un serveur d'application (Java), il est juste un conteneur Servlet (JSP est également traduit par Servlet), qui peut être considéré comme Apache extension, mais peut s'exécuter indépendamment de Apache. Nginx est un HTTP<🎜 très léger écrit par les Russes > Serveur , Nginx , qui se prononce "moteur X" , est un HTTP <🎜 hautes performances > et serveur proxy inverse, également un serveur proxy IMAP/POP3/SMTP . 2. Comparaison l Les deux sont développés par l'organisation Apache l Les deuxHTTPFonction du servicel Les deux gratuits Différences : l Apache est spécifiquement utilisé pour fournir HTTP service et configuration associée (telle que l'hôte virtuel, le transfert URL, etc.), tandis que Tomcat est Apache est organisé en Java EEcompatible JSP, Servlet Un JSPserveur l Apache<🎜. > est un programme d'environnement de serveur Web , l'active en tant que Web Le serveur utilise , mais ne prend en charge que les pages Web statiques telles que (ASP, PHP, CGI, JSP) et autres pages dynamiques La page Web ne fonctionne pas. Si vous souhaitez exécuter JSP dans l'environnement Apache, vous avez besoin d'un interpréteur pour exécuter JSP Page Web, et cet interpréteur JSP est Tomcat. l Apache : se concentre sur HTTPServer , Tomcat : se concentre sur le moteur Servlet S'il est exécuté en mode Autonome, il est fonctionnellement le. pareil que Apache est équivalent, prenant en charge JSP, mais il n'est pas idéal pour les pages Web statiques < ; 🎜> Apache est un serveur Web, Tomcat est un serveur d'application (Java), c'est juste un Servlet (JSP se traduit aussi par Servlet) conteneur, qui peut être considéré comme une extension Apache, mais peut s'exécuter indépendamment de Apache. En utilisation réelle, Apache et Tomcat sont souvent intégrés et utilisé : Si le client demande une page statique, vous n'avez besoin que du serveur Apache pour répondre à la demande. Si le client demande une page dynamique, c'est le serveur Tomcat qui répond à la demande. Parce que JSP interprète le code côté serveur, donc l'intégration peut réduire Frais généraux de service de Tomcat. On peut comprendre que Tomcat est une extension de Apache. occupe moins de mémoire et de ressources l Anti-concurrency, nginx traite les requêtes de manière asynchrone et non bloquante, tandis que apache bloque , sous une concurrence élevée nginx peut maintenir une faible consommation de ressources et des performances élevées l Conception hautement modulaire, l'écriture des modules est relativement simple Fournir un équilibrage de chargel 2) Avantages de l ; Prend en charge les pages dynamiques ; l prend en charge de nombreux modules, couvrant essentiellement toutes les applications ; a des performances stables, tandis que nginx que . 3) Comparaison des avantages et inconvénients des deuxl Nginx Configuration simple l <🎜; > Nginx les performances de traitement statique sont plus de Apache 3 fois supérieures à ; Nginx doit être utilisé avec d'autres backends l Apache a plus de composants que Nginx Multiple est un modèle multi-processus synchrone, une connexion correspond à un processus ; ; nginx est asynchrone, plusieurs connexions (10 000 niveaux) peuvent correspondre à un seul processus l nginx gère bien les fichiers statiques , consomme moins de mémoire l Les requêtes dynamiques sont effectuées par apache, nginx ne convient que pour les requêtes statiques et inversées ; l Nginx convient aux serveurs frontaux et a de bonnes performances de charge <🎜 ; >l Nginx lui-même est un serveur proxy inverse et prend en charge l'équilibrage de charge l NginxAvantages : équilibrage de charge, proxy inverse, avantages du traitement de fichiers statiques. nginx gère les requêtes statiques plus rapidement que apache l <🎜 ; >Apache Avantages : Par rapport au serveur Tomcat, le traitement des fichiers statiques est son avantage et il est rapide. Apache est une analyse statique, adaptée au HTML statique, aux images, etc. Tomcat : analyse dynamique du conteneur, traitement des requêtes dynamiques et compilation de JSPServlet Conteneur, Nginx dispose d'un mécanisme de séparation dynamique. Les requêtes statiques peuvent être traitées directement via Nginx, et les requêtes dynamiques sont transmises au arrière-plan pour le traitement. Géré par Tomcat. Apache a des avantages, Nginx a une meilleure concurrence, CPUfaible utilisation de la mémoire, si réécriture Fréquent, alors Apache est plus adapté. <br/> <br/> <br/><br/>2. >Utilisez netstat -anp|grep 80 La commande top est un outil d'analyse des performances couramment utilisé sous Linux. Elle peut afficher l'utilisation des ressources de chaque processus du système en temps réel, similaire au gestionnaire de tâches de Windows. <br/> $ top -u oracle Linux afficher les processus et supprimer des processus<br/> 1. 在 LINUX 命令平台输入 1-2 个字符后按 Tab 键会自动补全后面的部分(前提是要有这个东西,例如在装了 tomcat 的前提下, 输入 tomcat 的 to 按 tab)。<br/>2. ps 命令用于查看当前正在运行的进程。<br/>grep 是搜索<br/>例如: ps -ef | grep java<br/>表示查看所有进程里 CMD 是 java 的进程信息<br/>ps -aux | grep java<br/>-aux 显示所有状态<br/>ps<br/>3. kill 命令用于终止进程<br/>例如: kill -9 [PID]<br/>-9 表示强迫进程立即停止<br/>通常用 ps 查看进程 PID ,用 kill 命令终止进程<br/>网上关于这两块的内容<br/> <br/> <br/> <br/> 优化手段主要有缓存、集群、异步等。 网站性能优化第一定律:优先考虑使用缓存。 1 2 <br/> <br/> <br/> 任何可以晚点做的事情都应该晚点再做。 摘自《大型网站技术架构》–李智慧 <br/> 手机网站支付主要应用于手机、掌上电脑等无线设备的网页上,通过网页跳转或浏览器自带的支付宝快捷支付实现买家付款的功能,资金即时到账。 1、您申请前必须拥有企业支付宝账号(不含个体工商户账号),且通过支付宝实名认证审核。<br/>2、如果您有已经建设完成的无线网站(非淘宝、天猫、诚信通网店),网站经营的商品或服务内容明确、完整(古玩、珠宝等奢侈品、投资类行业无法申请本产品)。<br/>3、网站必须已通过ICP备案,备案信息与签约商户信息一致。 假设我们已经成功申请到手机网站支付接口,在进行开发之前,需要使用公司账号登录支付宝开放平台。 1、开发者登录开放平台,点击右上角的“账户及密钥管理”。<br/> 2、选择“合作伙伴密钥”,即可查询到合作伙伴身份(PID),以2088开头的16位纯数字。<br/> 支付宝提供了DSA、RSA、MD5三种签名方式,本次开发中,我们使用RSA签名和加密,那就只配置RSA密钥就好了。 关于RSA加密的详解,参见《支付宝签名与验签》。 本节可以忽略,本节可以忽略,本节可以忽略!因为官方文档并没有提及应用环境配置的问题。 进入管理中心,对应用进行设置。<br/> return_url,支付完成后的回调url;notify_url,支付完成后通知的url。支付宝发送给两个url的参数是一样的,只不过一个是get,一个是post。 以上两种发起请求的方式中,return_url在Node端,notify_url在后端。我们也可以根据需要,把两个url都放在后端,或者都放在Node端,改变相应业务逻辑即可。 Node端发起支付请求有两种选择,一种是获取到后端给的参数后,通过request模块发起get请求,获取到支付宝返回的支付页面,然后显示到页面上;另一种是获取到后端给的参数后,把参数全部输出到页面中的form表单,然后通过js自动提交表单,获取到支付宝返回的支付页面(同时显示出来)。 理论上完全正确的请求,然而,获取到的支付页面,输出到页面上,却是乱码。没错,还是一个错误提示页面。<br/> 神奇的地方在于,在刷新页面多次后,正常了!!!啊嘞,这是什么鬼? 先解决乱码问题,看看报什么错! 很遗憾,无效!乱码依然是乱码。。。和沈晨帅哥讨论很久,最终决定换一种方案——利用表单提交。 开始时,打算把alidata直接输出到form表单的action中接口的后面,因为这样似乎最简便。但是,提交表单时,后面的参数全部被丢弃了。所以,不得不得把所有参数放在form表单中。Node端拆分了一下参数,组装成了一个alipayParam对象,这个工作也可以交给后端来做。 显然,request模拟表单提交和真实表单提交结果的不同,得出的结论是,request并不能完全模拟表单提交。或者,request可以模拟,而我不会-_-|||。 以上,大功告成?不!还有一个坑要填,因为微信屏蔽了支付宝!<br/>在电脑上,跳转支付宝支付页面正常,很完美!然而,在微信浏览器中测试时,却没有跳转,而是出现如下信息。<br/> 微信端支付宝支付,iframe改造<br/>http://www.cnblogs.com/jiqing9006/p/5584268.html 该办法的核心在于:把微信屏蔽的链接,赋值给iframe的src属性。 然而,在改造时,先是报错ILLEGAL_SIGN,于是利用urlencode处理了字符串。接着,又报错ILLEGAL_EXTERFACE,没有找到解决办法。 暂时放弃,以后如果有了解决办法再补上。 关于微信公众平台无法使用支付宝收付款的解决方案说明<br/>https://cshall.alipay.com/enterprise/help_detail.htm?help_id=524702 该方法的核心在于:确认支付时,提示用户打开外部系统浏览器,在系统浏览器中支付。 该页面会自动跳转到同一文件夹下的pay.htm,该文件官方已经提供,把其中的引入ap.js的路径修改一下即可。最终效果如下:<br/> 支付宝的支付流程和微信的支付流程,有很多相似之处。沈晨指出一点不同:支付宝支付完成后有return_url和notify_url;微信支付完成后只有notify_url。 研读了一下微信支付的开发文档,确实如此。微信支付完成后的通知也分成两路,一路通知到notify_url,另一路返回给调用支付接口的JS,同时发微信消息提示。也就是说,跳转return_url的工作我们需要自己做。 最后,感谢沈晨帅哥提供的思路和帮助,感谢体超帅哥辛苦改后端。 Alipay Open Platform<br/>https://openhome.alipay.com/platform/home.htm Alipay Open Platform-Paiement sur site mobile-Centre de documents<br/> https://doc.open.alipay.com/doc2/detail?treeId=60&articleId=103564&docType=1 Développement d'une interface de paiement Alipay WAP<br/>http://blog.csdn.net/tspangle/article /details/39932963 L'interface de paiement du site mobile wap h5 évoque le paiement par portefeuille Alipay Service marchand - Alipay connaît le mandat ! <br/>https://b.alipay.com/order/techService.htm Document de développement des paiements WeChat<br/>https://pay.weixin.qq.com/wiki/doc/api/ jsapi.php?chapter=7_1 Paiement Alipay sur WeChat, transformation iframe<br/>http://www.cnblogs.com/jiqing9006/p/5584268.html Comment percer Alipay sur WeChat Blockade<br/>http://blog.csdn.net/lee_sire/article/details/49530875 Sujet JavaScript (2) : Compréhension approfondie de l'iframe<br/>http://www .cnblogs.com/ fangjins/archive/2012/08/19/2645631.html Instructions sur la solution pour l'impossibilité d'utiliser Alipay pour recevoir et payer sur la plateforme publique WeChat<br/>https:// cshall.alipay.com/enterprise/help_detail.htm ?help_id=524702 <br/> Pour les sites Web à fort trafic d'aujourd'hui, des dizaines de millions, voire des centaines de millions de trafic chaque jour, comment résoudre le problème de trafic Voici quelques méthodes récapitulatives : Tout d'abord, confirmez si le ? le matériel du serveur est suffisant pour prendre en charge le trafic actuel. Les serveurs P4 ordinaires peuvent généralement prendre en charge jusqu'à 100 000 IP indépendantes par jour. Si le nombre de visites est supérieur à cela, vous devez d'abord configurer un serveur dédié plus performant pour résoudre le problème. Sinon, quelle que soit la manière dont vous l'optimisez, il l'est. impossible de résoudre complètement le problème de performances. Deuxièmement, optimisez l'accès à la base de données. Une raison importante de la charge excessive sur le serveur est que la charge du processeur est trop élevée. Ce n'est qu'en réduisant la charge sur le processeur du serveur que le goulot d'étranglement peut être efficacement résolu. L'utilisation de pages statiques peut minimiser la charge sur le processeur. Il est bien entendu préférable d'obtenir une statique complète de la réception, car il n'est pas du tout nécessaire d'accéder à la base de données. Cependant, pour les sites Web fréquemment mis à jour, la statique ne peut souvent pas satisfaire certaines fonctions. La technologie de mise en cache est une autre solution qui consiste à stocker des données dynamiques dans des fichiers de cache. Les pages Web dynamiques appellent directement ces fichiers sans avoir à accéder à la base de données. WordPress et Z-Blog utilisent largement cette technologie de mise en cache. J'ai également écrit un plug-in de compteur Z-Blog, qui repose également sur ce principe. S'il est effectivement inévitable d'accéder à la base de données, vous pouvez essayer d'optimiser la requête SQL de la base de données. Évitez d'utiliser des instructions telles que Select *from. Chaque requête ne renvoie que les résultats dont vous avez besoin, évitant ainsi un grand nombre de requêtes SQL en un temps record. période de temps. Troisièmement, les hotlinking externes sont interdits. Le hotlinking d'images ou de fichiers provenant de sites Web externes entraîne souvent beaucoup de pression de charge, donc le hotlinking externe de vos propres images ou fichiers doit être strictement limité. Heureusement, le hotlinking peut être contrôlé simplement par référence, et Apache lui-même peut le configurer pour interdire les hotlinks. , IIS dispose également de certains ISAPI tiers qui peuvent réaliser la même fonction. Bien sûr, de fausses références peuvent également être utilisées pour réaliser des hotlinks via du code, mais actuellement, peu de personnes simulent délibérément des références et des hotlinks. Vous pouvez l'ignorer pour l'instant ou utiliser des moyens non techniques pour le résoudre, comme l'ajout de filigranes. aux images. Quatrièmement, contrôlez le téléchargement de fichiers volumineux. Le téléchargement de fichiers volumineux nécessitera beaucoup de trafic, et pour les disques durs non SCSI, le téléchargement d'un grand nombre de fichiers consommera du processeur et réduira la réactivité du site Web. Par conséquent, essayez de ne pas proposer de téléchargements de fichiers volumineux dépassant 2 Mo. Si vous devez les fournir, il est recommandé de placer les fichiers volumineux sur un autre serveur. Il existe actuellement de nombreux sites Web Web 2.0 gratuits offrant des fonctions de partage d'images et de fichiers. Vous pouvez donc essayer de télécharger des images et des fichiers sur ces sites Web de partage. Cinquièmement, utilisez différents hôtes pour détourner le trafic principal. Placez les fichiers sur différents hôtes et fournissez différentes images à télécharger aux utilisateurs. Par exemple, si vous estimez que les fichiers RSS consomment beaucoup de trafic, utilisez des services tels que FeedBurner ou FeedSky pour placer la sortie RSS sur d'autres hôtes. De cette manière, la majeure partie de la pression du trafic liée à l'accès des autres personnes sera concentrée sur. L'hôte de FeedBurner et RSS n'occuperont pas trop de ressources. Sixièmement, utilisez un logiciel d'analyse et de statistiques du trafic. L'installation d'un logiciel d'analyse et de statistiques du trafic sur le site Web permet de savoir instantanément où une grande partie du trafic est consommée et quelles pages doivent être optimisées. Par conséquent, une analyse statistique précise est nécessaire pour résoudre le problème de trafic. Le logiciel d’analyse et de statistiques de trafic que je recommande est Google Analytics. Je pense que son effet est très bon lors de l'utilisation. Plus tard, je présenterai en détail le bon sens et les compétences liées à l'utilisation de Google Analytics. 1. Tableaux divisés 2. Séparation de la lecture et de l'écriture 3. Optimisation front-end. Nginx remplace Apache (équilibrage de charge frontal). Personnellement, je pense que l'essentiel est de savoir si l'architecture distribuée est en place. Cependant, après la construction de l'architecture distribuée, l'optimisation du cache est limitée. grandit, seules des machines à tas sont nécessaires pour augmenter la capacité. Vous trouverez ci-joint quelques expériences d'optimisation. Tout d'abord, apprenez à utiliser les instructions d'explication pour analyser les instructions de sélection et optimiser les index et les structures de tables. Deuxièmement, utilisez rationnellement les caches tels que Memcache pour réduire la charge de MySQL. Hiphop-php de Facebook. Compilez PHP pour améliorer l'efficacité du programme. <br/> Comparaison des concepts de conception de bases de données NoSQL et relationnelles <br/> Base de données relationnelle les tables stockent certaines structures de données formatées. La composition des champs de chaque tuple est la même. Même si tous les tuples ne nécessitent pas tous les champs, la base de données allouera tous les champs à chaque tuple. Cela peut faciliter des opérations telles que les connexions entre les tables, mais. d'un autre point de vue, c'est également un facteur de goulot d'étranglement en termes de performances des bases de données relationnelles. Les bases de données non relationnelles stockent des paires clé-valeur et leur structure n'est pas fixe. Chaque tuple peut ajouter certaines de ses propres paires clé-valeur selon les besoins, il n'est donc pas limité à une structure fixe. La structure peut réduire certains frais de temps et d’espace. <br/><br/>Caractéristiques : <br/>Ils peuvent gérer des quantités extrêmement importantes de données. <br/>Ils fonctionnent sur des clusters de serveurs PC bon marché. <br/>Ils éliminent les goulots d'étranglement en matière de performances. <br/>Pas d'opérations excessives. <br/>Support Bootstrap <br/><br/>Inconvénients : <br/>Mais certaines personnes admettent que sans un soutien officiel formel, cela peut être terrible si quelque chose ne va pas, du moins c'est ce que voient de nombreux managers. <br/>De plus, nosql n'a pas formé un certain standard. Divers produits émergent les uns après les autres, et le chaos interne est interne pour tester différents projets <🎜. > MySQL ou NoSQL : Comment choisir une base de données à l'ère de l'open source Résumé : MySQL, base de données relationnelle, compte un grand nombre de partisans. NoSQL, une base de données non relationnelle, est considérée comme une base de données révolutionnaire. Les deux semblent destinés à se battre, mais ils appartiennent tous deux à la famille open source, mais ils peuvent aller de pair, vivre en harmonie et travailler ensemble pour fournir de meilleurs services aux développeurs. Comment choisir : La réponse classique toujours correcte est toujours : l'analyse spécifique de problèmes spécifiques. <br/> MySQL est petit, rapide, peu coûteux, de structure stable, facile à interroger et peut garantir la cohérence des données, mais manque de flexibilité. NoSQL offre des performances élevées, une évolutivité élevée et une haute disponibilité. Il ne se limite pas à une structure fixe et réduit la surcharge de temps et d'espace, mais il est difficile de garantir la cohérence des données. Les deux ont un grand nombre d’utilisateurs et de supporters, et rechercher une combinaison des deux est sans aucun doute une bonne solution. L'auteur John Engates est le CTO du département d'hébergement de Rackspace et un partisan du cloud ouvert. Il nous apporte une analyse détaillée. http://www.csdn.net/article/2014-03-05/2818637-open-source-data-grows-choosing-mysql-nosql En choisir un ? Ou tu veux les deux ? Le fait que l'application doive être alignée sur une base de données relationnelle ou NoSQL (peut-être les deux) dépendra bien sûr de la nature des données générées ou récupérées. Comme pour la plupart des choses en technologie, il y a des compromis à faire lors de la prise de décision. Si l'évolutivité et les performances sont plus importantes que la cohérence des données sur 24 heures, alors NoSQL est un choix idéal (NoSQL s'appuie sur le modèle BASE - fondamentalement disponible, logiciel état, cohérence éventuelle). Mais si vous souhaitez garantir un "toujours cohérent", notamment pour les informations confidentielles et les informations financières, alors MySQL est probablement le meilleur choix (MySQL s'appuie sur le modèle ACID - Atomicité, Cohérence, Indépendance et Durabilité). En tant que base de données open source, les bases de données relationnelles et non relationnelles évoluent constamment. Nous pouvons nous attendre à ce qu'il y ait un grand nombre de bases de données basées sur ACID. et des modèles BASE. De nouvelles applications sont générées. Bien qu'un article relativement radical « La base de données relationnelle est morte » soit paru en 2009, nous savons tous dans notre cœur que la base de données relationnelle est en réalité toujours bien vivante. Vous ne pouvez pas encore vous passer d'une base de données relationnelle. Mais cela illustre aussi que des goulots d’étranglement sont bel et bien apparus dans les bases de données relationnelles lors du traitement des données WEB2.0. Alors, faut-il utiliser NoSQL ou une base de données relationnelle ? Je ne pense pas que nous ayons besoin de donner une réponse absolue. Nous devons décider de ce que nous utilisons en fonction de nos scénarios d'application. Si la base de données relationnelle peut très bien fonctionner dans votre scénario d'application et que vous maîtrisez très bien l'utilisation et la maintenance de la base de données relationnelle, alors je pense que vous n'avez pas besoin de migrer vers NoSQL, sauf si vous êtes un personne qui aime lancer. Si vous travaillez dans des domaines clés où les données sont reines, comme la finance et les télécommunications, vous utilisez actuellement la base de données Oracle pour offrir une grande fiabilité. À moins que vous ne rencontriez un goulot d'étranglement particulièrement important, ne vous précipitez pas pour essayer NoSQL. Cependant, dans les sites Web WEB2.0, la plupart des bases de données relationnelles présentent des goulots d'étranglement. Les développeurs consacrent beaucoup d'efforts à optimiser les E/S du disque et l'évolutivité des bases de données, comme le partitionnement de la base de données, la réplication maître-esclave, la réplication hétérogène, etc. Cependant, ces tâches nécessitent des capacités techniques plus élevées et plus difficiles. Si vous rencontrez ces situations, je pense que vous devriez essayer NoSQL. <br/> Par rapport à structuré En termes de données (c'est-à-dire des données de ligne, stockées dans la base de données, les données implémentées peuvent être logiquement exprimées à l'aide d'une structure de table bidimensionnelle), les données qui ne sont pas pratiques à exprimer à l'aide d'une table logique bidimensionnelle dans la base de données sont appelées non structurées données, y compris tous les formats de documents Office, textes, images, XML, HTML, rapports divers, images et informations audio/vidéo, etc. Une base de données non structurée fait référence à une base de données dont la longueur des champs est variable, et les enregistrements de chaque champ peuvent être composés de sous-champs répétables ou non répétables. Elle peut non seulement traiter des données structurées (telles que des nombres), des symboles et. autres informations) et est plus adapté au traitement de données non structurées (texte intégral, images, sons, films et télévision, hypermédia et autres informations). La base de données WEB non structurée est principalement produite pour des données non structurées. Par rapport aux bases de données relationnelles populaires du passé, sa plus grande différence est qu'elle dépasse les limites de la définition de la structure de la base de données relationnelle qui n'est pas facile à modifier et. la longueur fixe des données. , prend en charge les champs répétés, les sous-champs et les champs de longueur variable, et met en œuvre le traitement des données de longueur variable et des champs répétés ainsi que la gestion du stockage de longueur variable des éléments de données, tout en traitant des informations continues (y compris les données complètes). informations textuelles) et les informations non structurées (y compris diverses informations multimédias) présentent des avantages que les bases de données relationnelles traditionnelles ne peuvent égaler. Données structurées (c'est-à-dire des données de ligne, stockées dans la base de données et pouvant utiliser une structure de tableau bidimensionnel pour exprimer logiquement les données implémentées) Données non structurées, incluant tous formats de documents bureautiques, textes, images, XML, HTML, rapports divers, images et informations audio/vidéo, etc. Ce qu'on appelle les données semi-structurées sont des données entre des données entièrement structurées (telles que les données des bases de données relationnelles et des bases de données orientées objet) et des données totalement non structurées (telles que les sons, les fichiers image, etc.), les documents HTML sont des données semi-structurées. Elles sont généralement auto-descriptives, et la structure et le contenu des données sont mélangés sans distinction évidente. Données structurées : tableau bidimensionnel (relationnel) <br/> Données semi-structurées : arbre, graphe <br/> Données non structurées : Aucune Les modèles de données de RMDBS comprennent : modèle de données réseau, modèle de données hiérarchique, relationnel Autres : Données structurées : structure d'abord, puis données <br/> Données semi-structurées : données d'abord, puis structure Avec le développement de la technologie des réseaux, notamment Le développement rapide d'Internet et La technologie Intranet a entraîné une augmentation de jour en jour de la quantité de données non structurées. À cette époque, les limites des bases de données relationnelles, principalement utilisées pour gérer des données structurées, sont devenues de plus en plus évidentes. Par conséquent, la technologie des bases de données est entrée dans « l’ère des bases de données post-relationnelles » et s’est développée dans l’ère des bases de données non structurées basées sur des applications réseau. La base de données non structurée de mon pays est représentée par la base de données IBase de Beijing Guoxin Base (iBase) Software Co., Ltd. La base de données IBase est une base de données non structurée destinée aux utilisateurs finaux. Elle se situe au niveau international avancé dans les domaines du traitement des informations non structurées, des informations en texte intégral, des informations multimédias et des informations massives, ainsi que des applications Internet/Intranet. niveau dans la gestion et la gestion des données non structurées. Une percée dans la récupération de texte intégral. Il présente principalement les avantages suivants : (1) Dans les applications Internet, il existe un grand nombre de types de données complexes. iBase peut gérer diverses informations documentaires et multimédias via ses types de données de fichiers externes, et pour divers documents. les ressources d'information ayant une importance pour la récupération, telles que HTML, DOC, RTF, TXT, etc., offrent également de puissantes capacités de récupération de texte intégral. (2) Il utilise le mécanisme des sous-champs, des champs à valeurs multiples et des champs de longueur variable, permettant la création de nombreux types différents de champs au format non structuré ou arbitraire, brisant ainsi la structure de table très stricte du relationnel. bases de données, permettant de stocker et de gérer des données non structurées. (3) iBase définit à la fois les données non structurées et structurées comme des ressources, de sorte que l'élément de base d'une base de données non structurée est la ressource elle-même et que les ressources de la base de données peuvent contenir à la fois des informations structurées et non structurées. Par conséquent, les bases de données non structurées peuvent stocker et gérer une variété de données non structurées, réalisant ainsi la transformation de la gestion des données du système de base de données en gestion de contenu. (4) iBase adopte la pierre angulaire orientée objet pour intégrer étroitement les données commerciales de l'entreprise et la logique métier, et est particulièrement adapté à l'expression d'objets de données complexes et d'objets multimédias. (5) iBase est une base de données produite pour répondre aux besoins du développement d'Internet. Basé sur l'idée que le Web est une base de données massive d'un réseau étendu, il fournit un système de gestion de ressources en ligne iBase. Web, qui combine le serveur réseau (WebServer) et la base de données. Le serveur (Database Server) est directement intégré dans un tout, faisant du système de base de données et de la technologie de base de données une partie importante et intégrante du Web, dépassant les limites de la base de données uniquement. jouer un rôle backend dans le système Web, réalisant la combinaison organique et transparente de la base de données et du Web, fournissant ainsi la gestion de l'information et même les applications de commerce électronique sur Internet/Intranet ont ouvert un champ plus large. (6) iBase est entièrement compatible avec diverses bases de données de grande, moyenne et petite taille, et fournit une prise en charge de l'importation et des liens pour les bases de données relationnelles traditionnelles, telles que Oracle, Sybase, SQLServer, DB2, Informix, etc. Grâce à l'analyse ci-dessus, nous pouvons prédire qu'avec le développement rapide de la technologie des réseaux et de la technologie des applications réseau, les bases de données non structurées entièrement basées sur des applications Internet deviendront le successeur des bases de données hiérarchiques, des bases de données réseau et des bases de données relationnelles. et technologie chaude. Lors de la conception d'un système d'information, cela impliquera certainement le stockage des données. Généralement, nous utiliserons le système. Les informations sont stockées dans un. base de données relationnelle spécifiée. Nous classerons les données par entreprise, concevrons les tableaux correspondants, puis enregistrerons les informations correspondantes dans les tableaux correspondants. Par exemple, si nous construisons un système d'entreprise et devons enregistrer les informations de base sur les employés : numéro de poste, nom, sexe, date de naissance, etc., nous créerons un tableau du personnel correspondant. Mais toutes les informations du système ne peuvent pas correspondre aux champs d'un tableau. Tout comme l'exemple ci-dessus. Ce type de données est mieux géré en créant simplement une table correspondante. Comme les images, les sons, les vidéos, etc. Nous ne pouvons généralement pas connaître directement le contenu de ce type d'informations, et la base de données ne peut les enregistrer que dans un champ BLOB, ce qui est très gênant pour une récupération future. L'approche générale consiste à créer une table contenant trois champs (numéro, description du contenu varchar(1024), blob de contenu). La citation se fait par numéro et la recherche se fait par description du contenu. Il existe de nombreux outils de traitement de données non structurées, et le gestionnaire de contenu courant sur le marché en fait partie. Ce type de données est différent des deux catégories ci-dessus. Ce sont des données structurées, mais la structure change grandement. Parce que nous devons comprendre les détails des données, nous ne pouvons pas simplement les organiser dans un fichier et les traiter comme des données non structurées. Puisque la structure change considérablement, nous ne pouvons pas simplement créer un tableau qui y corresponde. Cet article traite principalement de deux méthodes couramment utilisées pour le stockage de données semi-structurées. 先举一个半结构化的数据的例子,比如存储员工的简历。不像员工基本信息那样一致每个员工的简历大不相同。有的员工的简历很简单,比如只包括教育情况;有的员工的简历却很复杂,比如包括工作情况、婚姻情况、出入境情况、户口迁移情况、党籍情况、技术技能等等。还有可能有一些我们没有预料的信息。通常我们要完整的保存这些信息并不是很容易的,因为我们不会希望系统中的表的结构在系统的运行期间进行变更。 这种方法通常是对现有的简历中的信息进行粗略的统计整理,总结出简历中信息所有的类别同时考虑系统真正关心的信息。对每一类别建立一个子表,比如上例中我们可以建立教育情况子表、工作情况子表、党籍情况子表等等,并在主表中加入一个备注字段,将其它系统不关心的信息和已开始没有考虑到的信息保存在备注中。 优点:查询统计比较方便。 缺点:不能适应数据的扩展,不能对扩展的信息进行检索,对项目设计阶段没有考虑到的同时又是系统关心的信息的存储不能很好的处理。 XML可能是最适合存储半结构化的数据了。将不同类别的信息保存在XML的不同的节点中就可以了。 优点:能够灵活的进行扩展,信息进行扩展式只要更改对应的DTD或者XSD就可以了。 缺点:查询效率比较低,要借助XPATH来完成查询统计,随着数据库对XML的支持的提升性能问题有望能够很好的解决。 <br/> 单链表<br/><br/> 1、链接存储方法<br/> 链接方式存储的线性表简称为链表(Linked List)。<br/> 链表的具体存储表示为:<br/> ① 用一组任意的存储单元来存放线性表的结点(这组存储单元既可以是连续的,也可以是不连续的)<br/> ② 链表中结点的逻辑次序和物理次序不一定相同。为了能正确表示结点间的逻辑关系,在存储每个结点值的同时,还必须存储指示其后继结点的地址(或位置)信息(称为指针(pointer)或链(link))<br/> 注意:<br/> 链式存储是最常用的存储方式之一,它不仅可用来表示线性表,而且可用来表示各种非线性的数据结构。<br/> <br/> 2、链表的结点结构<br/> ┌──┬──┐<br/> │data│next│<br/> └──┴──┘ <br/> data域--存放结点值的数据域<br/> next域--存放结点的直接后继的地址(位置)的指针域(链域)<br/>注意:<br/> ①链表通过每个结点的链域将线性表的n个结点按其逻辑顺序链接在一起的。<br/> ②每个结点只有一个链域的链表称为单链表(Single Linked List)。<br/> 【例】线性表(bat,cat,eat,fat,hat,jat,lat,mat)的单链表示如示意图<br/><br/> 单链表的反转是常见的面试题目。本文总结了2种方法。 单链表node的数据结构定义如下: 把当前链表的下一个节点pCur插入到头结点dummy的下一个节点中,就地反转。 dummy->1->2->3->4->5的就地反转过程: pCur是需要反转的节点。 prev连接下一次需要反转的节点 反转节点pCur 纠正头结点dummy的指向 pCur指向下一次要反转的节点 伪代码 1个头结点,2个指针,4行代码 注意初始状态和结束状态,体会中间的图解过程。 新建一个头结点,遍历原链表,把每个节点用头结点插入到新建链表中。最后,新建的链表就是反转后的链表。 pCur是要插入到新链表的节点。 pNex是临时保存的pCur的next。 pNex保存下一次要插入的节点 把pCur插入到dummy中 纠正头结点dummy的指向 pCur指向下一次要插入的节点 伪代码 <br/> MySQL官方对索引的定义:索引是帮助MySQL高效获取数据的数据结构。索引是在存储引擎中实现的,所以每种存储引擎中的索引都不一样。如MYISAM和InnoDB存储引擎只支持BTree索引;MEMORY和HEAP储存引擎可以支持HASH和BTREE索引。 这里仅针对常用的InnoDB存储引擎所支持的BTree索引进行介绍: 先创建一个新表,用于演示索引类型 这是最基本的索引,没有任何限制。 索引列的值必须唯一,可以有空值 是一种特殊的唯一索引,必须指定为 PRIMARY KEY,如我们常用的AUTO_INCREMENT自增主键 也称为组合索引,就是在多个字段上联合建立一个索引 这里一个组合索引,相当于在有如下三个索引: name; name,age; name,age,phoneNum; 这里或许有这样一个疑惑:为什么age或者age,phoneNum字段上没有索引。这是由于BTree索引因要遵守最左前缀原则,这个原则在后面详细展开。 创建索引简单,但是在哪些列上创建索引则需要好好思考。可以考虑在where字句中出现列或者join字句中出现的列上建索引 联合索引(name,age,phoneNum) ,B+树是按照从左到右的顺序来建立搜索树的。如('张三',18,'18668247652')来检索数据的时候,B+树会优先匹配name来确定搜索方向,name匹配成功再依次匹配age、phoneNum,最后检索到最终的数据。也就是说这种情况下是有三级索引,当name相同,查找age,age也相同时,去比较phoneNum;但是如果拿 (18,'18668247652')来检索时,B+树没有拿到一级索引,根本就无法确定下一步的搜索方向。('张三','18668247652')这种场景也是一样,当name匹配成功后,没有age这个二级索引,只能在name相同的情况下,去遍历所有的phoneNum。 B+树的数据结构决定了在使用索引的时候必须遵守最左前缀原则,在创建联合索引的时候,尽量将经常参与查询的字段放在联合索引的最左边。 一般情况下不建议使用like操作,如果非使用不可的话,需要注意:like '%abd%'不会使用索引,而like ‘aaa%’可以使用索引。这也是前面的最左前缀原则的一个使用场景。 mysql会按照联合索引从左往右进行匹配,直到遇到范围查询,如:>,<,between,like等就停止匹配,a = 1 and b =2 and c > 3 and d = 4,如果建立(a,b,c,d)顺序的索引,d是不会使用索引的。但如果联合索引是(a,b,d,c)的话,则a b d c都可以使用到索引,只是最终c是一个范围值。 order by排序有两种排序方式:using filesort使用算法在内存中排序以及使用mysql的索引进行排序;我们在部分不情况下希望的是使用索引。 如果ID是单列索引,则order by会使用索引 Si ID est un index à une seule colonne et que le nom n'est pas un index ou que le nom est également un index à une seule colonne, order by n'utilisera pas l'index. Parce qu'une requête Mysql ne sélectionnera qu'un seul index parmi plusieurs index et que l'index de la colonne ID est utilisé dans cette requête, pas l'index de la colonne de nom. Dans ce scénario, si vous souhaitez que order by utilise également l'index, créez un index conjoint (id, nom). Vous devez faire attention au principe du préfixe le plus à gauche ici. (nom, identifiant). Enfin, il convient de noter que mysql a une limite sur la taille des enregistrements triés : max_length_for_sort_data est par défaut à 1024, ce qui signifie que si la quantité de données à trier est supérieure à 1024 ; , order by n'utilisera pas l'index. Utilisez plutôt filesort. <br/> <br/> Il existe actuellement plusieurs types de sites Web distribués à grande échelle : 1. Les grands portails, tels que NetEase, Sina, etc. 2. Les sites Web SNS, tels que Xiaonei, Kaixin.com ; , etc. ; 3. Sites Web de commerce électronique : par exemple, Alibaba, JD.com, Gome Online, Autohome, etc. Besoins des clients : Créer un e-commerce de catégorie complète site Web (B2C), les utilisateurs peuvent acheter des marchandises en ligne, payer en ligne ou payer à la livraison Les utilisateurs peuvent communiquer avec le service client en ligne lors de l'achat ; J'espère soutenir le développement commercial dans 3 à 5 ans Il est prévu que le nombre d'utilisateurs atteigne 10 millions dans 3 à 5 ; ans Organisez régulièrement Double 11, Double 12, la Journée des hommes du 8 mars et d'autres activités Pour d'autres fonctions, veuillez vous référer aux sites Web ; comme JD.com ou Gome Online. Les clients sont des clients. Ils ne vous diront pas ce qu'ils veulent, ils vous diront seulement ce qu'ils veulent. Nous devons souvent guider et explorer les besoins des clients. Heureusement, un site Web de référence clair est fourni. Par conséquent, l'étape suivante consiste à effectuer de nombreuses analyses, à combiner l'industrie et les sites Web de référence pour fournir des solutions aux clients. Pour un site Web général, l'approche initiale consiste à utiliser trois serveurs, un pour déployer l'application, un pour déployer la base de données et un pour déployer le système de fichiers NFS. . Il s'agit d'une approche relativement traditionnelle ces dernières années. J'ai vu un site Web comptant plus de 100 000 membres, un portail vertical de conception de vêtements et de nombreuses photos. Un serveur est utilisé pour déployer des applications, des bases de données et du stockage d'images. Il y avait beaucoup de problèmes de performances. Comme indiqué ci-dessous : . C'est du moins à cela que cela ressemble ci-dessous. (2) Utiliser le mode actif et de sauvegarde de la base de données pour obtenir une sauvegarde des données et une haute disponibilité ; 4 Estimation de la capacité du système Estimation maximale : 2 à 3 fois le montant normal Calculer la capacité du système en fonction de la simultanéité (concurrence, nombre de transactions), de la capacité de stockage ; 🎜> ; . La mémoire et les E/S sont similaires. Les estimations ci-dessus sont fournies à titre de référence uniquement, car la configuration du serveur, la complexité de la logique métier, etc. ont toutes un impact. Ici, le CPU, le disque dur, le réseau, etc. ne sont plus évalués. Plan de déploiement de référence 2 : 6.2 Déploiement de cluster d'applications (distribué, en cluster, charge ; Équilibré) Le cache est stocké en fonction de l'emplacement Le ratio de cache est généralement de 1:4, vous pouvez envisager d'utiliser le cache. (Théoriquement, 1:2 est suffisant). Les stratégies d'expiration du cache suivantes peuvent être utilisées en fonction des caractéristiques de l'entreprise : (1) Expiration automatique du cache (2) Expiration du déclencheur de cache ; Le système est divisé en plusieurs sous-systèmes après un déploiement indépendant, des problèmes de gestion de session seront inévitablement rencontrés. . Une étape supplémentaire peut consister à établir un système complet d'authentification unique ou de gestion de compte basé sur une session distribuée. Description du processus : (1) Lorsque l'utilisateur se connecte pour la première fois, les informations de session (ID utilisateur et informations utilisateur) , tel que L'ID utilisateur est la clé et est écrit dans la session distribuée ; (2) Lorsque l'utilisateur se reconnecte, obtenez la session distribuée et voyez s'il y a des informations sur la session. Sinon, transférez-la vers la session distribuée. page de connexion ; ( 3) Généralement implémenté à l'aide du middleware Cache, il est recommandé d'utiliser Redis, il dispose donc d'une fonction de persistance, de sorte qu'une fois la session distribuée arrêtée, les informations de session puissent être chargées à partir du stockage persistant. ; (4) Enregistrez la session, vous pouvez définir la durée de conservation de la session, par exemple 15 minutes, et elle expirera automatiquement une fois dépassée Combiné avec le middleware de cache ; , la Session distribuée implémentée peut très bien simuler la session Session. Les grands sites Web doivent stocker des quantités massives de données afin d'obtenir un stockage massif de données, <🎜. >. . Par exemple, le sous-système d'adhésion dans ce cas peut être extrait en tant que service public. . C'est la configuration standard des systèmes distribués. Dans ce cas, la file d’attente des messages est principalement utilisée dans les liens d’achat et de livraison. 目前使用较多的MQ有Active MQ,Rabbit MQ,Zero MQ,MS MQ等,需要根据具体的业务场景进行选择。 除了以上介绍的业务拆分, 此处不详细介绍,大家可以问度娘/Google,有机会的话也可以分享给大家。 <br/> RESTful是"分布式超媒体应用"的架构风格<br/>1.采用URI标识资源;<br/><br/>2.使用“链接”关联相关的资源;<br/><br/>3.使用统一的接口;<br/><br/>4.使用标准的HTTP方法;<br/><br/>5.支持多种资源表示方式;<br/><br/> 6.无状态性; <br/> <br/> windows 最近要熟悉一下网站优化,包括前端优化,后端优化,涉及到的细节Opcode,Xdebuge等,都会浅浅的了解一下。 像类似于,刷刷CSDN博客的人气啦,完全是得心应手啊。 我测试了博客园,使用ab并不能刷访问量,为什么CSDN可以,因为两者统计的方式不同。 1 2 3 4 5 6 PV与来访者的数量成正比,但是PV并不直接决定页面的真实来访者数量。比如一个网站就你一个人进来,通过不断的刷新页面,也可以制造出非常高的PV。这也就是ab可以刷csdn访问的原因了。 UV是指不同的、通过互联网访问、浏览一个网页的自然人。类似于注册用户,保存session的形式 IP就不用说啦。类似于博客园,使用的统计方式就必须是IP啦 ab是Apache的自带的工具,如果是window安装的,找到Apache的bin目录,在系统全局变量中添加Path,然后就可以使用ab了 1 2 3 4 5 6 1 2 3 1 2 3 本文介绍ab测试,并没有恶意使用它。途中的博客地址,也只是测试过程中借用了一下,没有别的恶意。 原创 2015年10月19日 18:24:31 <br/> 安装ab工具 ubuntu安装ab apt-get install apache2-utils centos安装ab yum install httpd-tools ab 测试命令 ab -kc 1000-n 1000 http://localhost/ab.html(是服务器下的页面) <br/> Les journaux dans ySQL incluent : journal des erreurs, journal binaire, journal des requêtes générales, journal des requêtes lentes, etc. . Ici, nous introduisons principalement deux fonctions couramment utilisées : le journal des requêtes générales et le journal des requêtes lentes. 1) Journal général des requêtes : enregistre la connexion client établie et les instructions exécutées. 2) Journal des requêtes lentes : Enregistrez toutes les requêtes dont le temps d'exécution dépasse long_query_time secondes ou les requêtes qui n'utilisent pas d'index (1) Journal général des requêtes Lors de l'apprentissage de la requête générale de journal, vous devez connaître les commandes communes dans les deux bases de données : 1) afficher des variables telles que '%version%'; Le le rendu est le suivant : La commande ci-dessus affiche les éléments liés au numéro de version dans la base de données actuelle. 1) afficher des variables comme '%general%'; Vous pouvez vérifier si la requête de journal général actuelle est activée, si la valeur de general_log est ON signifie activé, OFF signifie désactivé ( est désactivé par défaut ). 1) afficher des variables telles que '%log_output%' ; Afficher le format de la sortie actuelle du journal des requêtes lentes, qui peut être FILE (stocké dans les données hostname.log dans le fichier de données de la base de données), ou TABLE (mysql.general_log stocké dans la base de données) Question : Comment activer la requête générale MySQL log, et comment définir les paramètres requis. Qu'en est-il du format de sortie de journal commun pour la sortie ? Activer la requête générale du journal : set global general_log=on; Désactiver la requête générale du journal : set globalgeneral_log=off; Définissez la sortie générale du journal en mode tableau : set globallog_output='TABLE'; Définissez la sortie générale du journal en mode fichier : set globallog_output='FILE '; Définir la sortie générale du journal en mode table et fichier : set global log_output='FILE,TABLE'; (Remarque : La commande ci-dessus ne prend effet qu'actuellement , lorsque MySQLLe redémarrage échoue, Si vous souhaitez qu'il prenne effet de manière permanente, vous devez configurer my.cnf) Le rendu de la sortie du journal est le suivant : Enregistrement dans la table mysql.general_log Les données sont les suivantes : Le format enregistré dans le .log local est le suivant : La configuration du fichier my.cnf est la suivante : general_log=1 # Une valeur de 1 signifie activer la requête de journal générale, une valeur de 0 signifie désactiver la requête de journal générale log_output =FILE,TABLE#Définir le format de sortie du journal général sur les fichiers et les tables (2) Journal des requêtes lentes Le journal des requêtes lentes de MySQL est celui fourni par MySQL Logging, utilisé pour enregistrer les instructions dont le temps de réponse dépasse le seuil dans MySQL, fait spécifiquement référence à SQL dont la durée d'exécution dépasse la valeur long_query_time , sera enregistré dans le journal des requêtes lentes (le journal peut être écrit dans un fichier ou une table de base de données, si les exigences de performances sont élevées. Si tel est le cas, il est recommandé d'écrire un fichier). Par défaut, la base de données MySQL n'active pas les journaux de requêtes lentes. La valeur par défaut de long_query_time est 10 (c'est-à-dire 10 secondes, généralement définie sur 1 seconde), c'est-à-dire que les instructions qui s'exécutent pendant plus de 10 secondes sont des instructions de requête lentes. De manière générale, les requêtes lentes se produisent dans les grandes tables (par exemple, la quantité de données dans une table est de plusieurs millions) et les champs des conditions de requête ne sont pas indexés pour le moment. les conditions de requête seront une analyse complète de la table, long_query_time prend du temps et est une instruction de requête lente. Question : Comment vérifier si le journal des requêtes lentes actuel est activé ? Entrez la commande dans MySQL : afficher les variables comme '%quer%'; Maîtrisez principalement les paramètres suivants : (1) La valeur de slow_query_log est ON pour activer le journal des requêtes lentes, et OFF est pour désactiver le journal des requêtes lentes. (2) La valeur de slow_query_log_file est le journal des requêtes lentes enregistré dans le fichier (Remarque : est nommé hostname.log par défaut, que le journal des requêtes lentes est écrit Dans le fichier spécifié, vous devez spécifier le format du journal de sortie de la requête lente sous forme de fichier. La commande appropriée est : show variables like '%log_output%'; (3) long_query_time spécifie le seuil de requête lente, c'est-à-dire que si le temps d'exécution de l'instruction dépasse le seuil, il s'agit d'une instruction de requête lente. La valeur par défaut est de 10 secondes. . (4) log_queries_not_using_indexes Si la valeur est définie sur ON, toutes les requêtes qui n'utilisent pas d'index seront enregistrées (Remarque : Si vous définissez simplement log_queries_not_using_indexes sur ON et slow_query_log est défini sur OFF, ce paramètre ne prendra pas effet à ce moment-là, c'est-à-dire que le principe pour que ce paramètre prenne effet est que la valeur de slow_query_log soit définie sur ON), et est généralement activé temporairement pendant le réglage des performances. Question : Définir le format du journal de sortie de la requête lente MySQL sur fichier ou table, ou les deux ? Utilisez la commande : show variables like '%log_output%'; Vous pouvez vérifier le format de sortie grâce à la valeur de log_output. La valeur ci-dessus est TABLE. Bien sûr, nous pouvons également définir le format de sortie sur texte, ou enregistrer du texte et des tables de base de données en même temps. La commande de configuration est la suivante : #Sortez le journal des requêtes lentes dans la table (c'est-à-dire mysql. slow_log) set globallog_output='TABLE'; #Le journal des requêtes lentes est uniquement généré sous forme de texte (c'est-à-dire : le fichier spécifié par slow_query_log_file) setglobal log_output=' FILE'; #Le journal des requêtes lentes est affiché à la fois dans le texte et dans le tableau setglobal log_output='FILE,TABLE' À propos des données du tableau du journal des requêtes lentes et des données dans le texte Analyse du format : L'enregistrement du journal des requêtes lentes se trouve dans la table myql.slow_log, le format est le suivant : L'enregistrement du journal des requêtes lentes est Dans le fichier hostname.log, le format est le suivant : Vous peut voir qu'il s'agit d'une table ou d'un fichier, il est spécifiquement enregistré : quelle instruction a provoqué la requête lente ( sql_text), l'heure de la requête (query_time), l'heure de verrouillage de la table (Lock_time) et le nombre de lignes analysées (rows_examined) de l'instruction de requête lente. Question : Comment interroger le nombre d'instructions de requête lentes actuelles ? Il existe une variable dans MySQL qui enregistre le nombre d'instructions de requête lentes actuelles : Entrez la commande : afficher l'état global comme '%slow%'; (Remarque : Pour toutes les commandes ci-dessus, si les paramètres sont définis via le shell MySQL, si MySQL est redémarré, tous les paramètres définis seront invalides . Si vous souhaitez que cela prenne effet de manière permanente, vous devez écrire les paramètres de configuration dans le fichier my.cnf). Points de connaissances supplémentaires : Comment utiliser l'outil d'analyse des journaux de requêtes lentes de MySQL, mysqldumpslow, pour analyser les journaux ? perlmysqldumpslow –s c –t 10 slow-query.log Les paramètres spécifiques sont les suivants : -s indique comment trier, c , t, l et r sont triés respectivement en fonction du nombre d'enregistrements, de l'heure, de l'heure de la requête et du nombre d'enregistrements renvoyés ac, at, al et ar représentent les flashbacks correspondants -t représente ; top. Les données suivantes indiquent combien d'éléments précédents sont renvoyés ; -g peut être suivi d'une correspondance d'expression régulière, qui n'est pas sensible à la casse. Les paramètres ci-dessus ont les significations suivantes : Count :414 La déclaration apparaît 414 fois Time=3.51 ; s (1454) Le temps d'exécution maximum est de 3,51 s et le temps total cumulé consommé est de 1454 s Lock=0.0s (0) Le temps d'attente maximum pour le verrou est de 0 s et le temps d'attente cumulé pour le verrou est 0s ; Rows=2194.9 (9097604) Le nombre maximum de lignes envoyées au client est 2194.9, et le nombre cumulé de fonctions envoyées au client est 90976404 http:/ /blog.csdn.net/a600423444/article/details/6854289 (Remarque : le script mysqldumpslow est écrit en langage Perl, l'utilisation spécifique de mysqldumpslow sera discutée plus tard) Question : actuellement en cours d'apprentissage Comment savoir que la requête lente définie est efficace ? C'est très simple. Nous pouvons générer manuellement une instruction de requête lente. Par exemple, si la valeur de notre requête lente log_query_time est définie sur 1, nous pouvons exécuter l'instruction suivante : selectsleep. (1); Cette instruction est l'instruction de requête lente. Ensuite, vous pouvez vérifier si cette instruction existe dans le fichier ou la table de sortie du journal correspondant. <br/> Réimprimé à 13:36:47 <br/> ThinkPHP简称TP,TP借鉴了Java思想,基于PHP5,充分利用了PHP5的特性,部署简单只需要一个入口文件,一起搞定,简单高效。中文文档齐全,入门超级简单。自带模板引擎,具有独特的数据验证和自动填充功能,框架更新速度比较速度。 优点:这个框架易使用 易学 安全 对bae sae支持很好提供的工具也很强大 可以支持比较大的项目开发 易扩展 全中文文档 总的来说这款框架适合非常适合国人使用 性能 上比CI还要强一些 缺点:配置对有些人来说有些复杂(其实是因为没有认真的读过其框架源码)文档有些滞后 有些组件未有文档说明。 CodeIgniter简称CI 简单配置,上手很快,全部的配置使用PHP脚本来配置,没有使用很多太复杂的设计模式,(MVC设计模式)执行性能和代码可读性上都不错。执行效率较高,具有基本的MVC功能,快速简洁,代码量少,框架容易上手,自带了很多简单好用的library。 框架适合中小型项目,大型项目也可以,只是扩展能力差。优点:这个框架的入门槛很底 极易学 极易用 框架很小 静态化非常容易 框架易扩展 文档比较详尽 缺点:在极易用的极小下隐藏的缺点即是不安全 功能不是太全 缺少非常多的东西 比如你想使用MongoDB你就得自己实现接口… 对数据的操作亦不是太安全 比如对update和delete操作等不够安全 暂不支持sae bae等(毕竟是欧洲)对大型项目的支持不行 小型项目会非常好。 CI和TP的对比(http://www.jcodecraeer.com/a/phpjiaocheng/2012/0711/309.html) Laravel的设计思想是很先进的,非常适合应用各种开发模式TDD, DDD和BDD(http://blog.csdn.net/bennes/article/details/47973129 TDD DDD BDD解释 ),作为一个框架,它为你准备好了一切,composer是个php的未来,没有composer,PHP肯定要走向没落。laravel最大的特点和处优秀之就是集合了php比较新的特性,以及各种各样的设计模式,Ioc容器,依赖注入等。因此laravel是一个适合学习的框架,他和其他的框架思想有着极大的不同,这也要求你非常熟练php,基础扎实。 优点:http://www.codeceo.com/article/why-laravel-best-php-framework.html Yii是一个基于组件的高性能的PHP的框架,用于开发大规模Web应用。Yii采用严格的OOP编写,并有着完善的库引用以及全面的教程。从MVC,DAO/ActiveRecord,widgets,caching,等级式RBAC,Web服务,到主体化,I18N和L10N,Yii提供了今日Web 2.0应用开发所需要的几乎一切功能。而且这个框架的价格也并不太高。事实上,Yii是最有效率的PHP框架之一。 <br/> 原创 2016年11月09日 17:58:50 <br/> 在PHP中,出现同名函数或是同名类是不被允许的。为防止编程人员在项目中定义的类名或函数名出现重复冲突,在PHP5.3中引入了命名空间这一概念。 1.命名空间,即将代码划分成不同空间,不同空间的类名相互独立,互不冲突。一个php文件中可以存在多个命名空间,第一个命名空间前不能有任何代码。内容空间声明后的代码便属于这个命名空间,例如: 2.调用不同空间内类或方法需写明命名空间。例如: 3.在命名空间内引入其他文件不会属于本命名空间,而属于公共空间或是文件中本身定义的命名空间。例: 首先定义一个1.php和2.php文件: 4.下面我们来看use的使用方法:(use以后引用可简写) 相关推荐: Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!Query-4 explain select * from people where id in (select id from people where zipcode = 100000 union select id from people where zipcode = 200000 );

SELECT ... FROM t1 WHERE t1.a IN (SELECT b FROM t2);
SELECT ... FROM t1 WHERE EXISTS (SELECT 1 FROM t2 WHERE t2.b = t1.a);
Query-5 explain select * from people o where exists (
select id from people where zipcode = 100000 and id = o.id union select id from people where zipcode = 200000 and id = o.id);

Query-6 explain select * from people where id = (select id from people where zipcode = 100000);

table
Query-7 explain select * from (select * from (select * from people a) b ) c;

<strong><em>N</em></strong>>N就是id值,指该id值对应的那一步操作的结果。type
Query-8 explain select * from people where id=1;

Query-9 explain select * from people where zipcode = 100000;

Query-10 explain select * from people where id >2;

Query-11 explain select * from (select * from people where id = 1 )b;

Query-12 explain select * from people a,people_car b where a.id = b.people_id;

CREATE TABLE people2(
id bigint auto_increment primary key,
zipcode char(32) not null default '',
address varchar(128) not null default '',
lastname char(64) not null default '',
firstname char(64) not null default '',
birthdate char(10) not null default '' )
ENGINE = MyISAM; CREATE TABLE people_car2(
people_id bigint,
plate_number varchar(16) not null default '',
engine_number varchar(16) not null default '',
lasttime timestamp
)ENGINE = MyISAM;
Query-13 explain select * from people2 a,people_car2 b where a.id = b.people_id;

Query-14 explain select * from people2 a,people_car2 b where a.id = b.people_id and b.people_id = 1;

reate index people_id on people2(id); create index people_id on people_car2(people_id);
Query-15 explain select * from people2 a,people_car2 b where a.id = b.people_id and a.id > 2;

Query-16 explain select * from people2 a,people_car2 b where a.id = b.people_id and a.id = 2;

Query-17 explain select * from people2 a,people_car2 b where a.id = b.people_id;

Query-18 explain select * from people2 where id = 1;

Query-19 mysql> explain select * from people2 where id = 2 or id is null;

Query-20 explain select * from people2 where id = 2 or id is not null;

value IN (SELECT primary_key FROM single_table WHERE some_expr)
value IN (SELECT key_column FROM single_table WHERE some_expr)
Query-21 explain select * from people where id = 1 or id = 2;
 <br/>
<br/>explain select * from people where id >1;

explain select * from people where id in (1,2);

Query-22 explain select * from people order by id;

possible_keys
ref
lignes
Extra
MySQL dispose de deux manières de générer des résultats ordonnés, via des opérations de tri ou à l'aide d'index, lors de l'utilisation filesort apparaît dans Extra, cela signifie que MySQL utilise ce dernier, mais notez que même si cela s'appelle filesort, cela ne signifie pas que les fichiers sont utilisés pour le tri. Le tri est effectué en mémoire autant que possible. Dans la plupart des cas, le tri des index est plus rapide, vous devriez donc généralement également envisager d'optimiser les requêtes à ce stade.
L'utilisation de temporaire
2. méthode d'autorisation de l'auteur

1. Scénarios d'application

2. Définition des noms
3. L'idée d'OAuth
4. Processus de fonctionnement

五、客户端的授权模式
六、授权码模式

GET /authorize?response_type=code&client_id=s6BhdRkqt3&state=xyz &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb HTTP/1.1 Host: server.example.com
HTTP/1.1 302 Found Location: https://client.example.com/cb?code=SplxlOBeZQQYbYS6WxSbIA &state=xyz
POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=authorization_code&code=SplxlOBeZQQYbYS6WxSbIA &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb
HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Cache-Control: no-store Pragma: no-cache { "access_token":"2YotnFZFEjr1zCsicMWpAA", "token_type":"example", "expires_in":3600, "refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA", "example_parameter":"example_value" }七、简化模式

GET /authorize?response_type=token&client_id=s6BhdRkqt3&state=xyz &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb HTTP/1.1 Host: server.example.com
HTTP/1.1 302 Found Location: http://example.com/cb#access_token=2YotnFZFEjr1zCsicMWpAA &state=xyz&token_type=example&expires_in=3600
八、密码模式

POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=password&username=johndoe&password=A3ddj3w
HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Cache-Control: no-store Pragma: no-cache { "access_token":"2YotnFZFEjr1zCsicMWpAA", "token_type":"example", "expires_in":3600, "refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA", "example_parameter":"example_value" }九、客户端模式

POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=client_credentials
HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Cache-Control: no-store Pragma: no-cache { "access_token":"2YotnFZFEjr1zCsicMWpAA", "token_type":"example", "expires_in":3600, "example_parameter":"example_value" }十、更新令牌
POST /token HTTP/1.1
Host: server.example.com
Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW
Content-Type: application/x-www-form-urlencoded
grant_type=refresh_token&refresh_token=tGzv3JOkF0XG5Qx2TlKWIA3. yii 配置文件
 <br/>
<br/>
 <br/> advance版本的特点是:根目录下预先分配了三个模块,分别是前台、后台、控制台模块。1.backend它主要用于管理后台,网站管理员来管理整个系统。<br/>
<br/> advance版本的特点是:根目录下预先分配了三个模块,分别是前台、后台、控制台模块。1.backend它主要用于管理后台,网站管理员来管理整个系统。<br/> <br/>assets 目录用于存放前端资源包PHP类。 这里不需要了解什么是前端资源包,只要大致知道是用于管理CSS、js等前端资源就可以了。config 用于存放本应用的配置文件,包含主配置文件 main.php 和全局参数配置文件 params.php 。models views controllers 3个目录分别用于存放数据模型类、视图文件、控制器类。这个是我们编码的核心,也是我们工作最多的目录。widgets 目录用于存放一些常用的小挂件的类文件。tests 目录用于存放测试类。web 目录从名字可以看出,这是一个对于Web服务器可以访问的目录。 除了这一目录,其他所有的目录不应对Web用户暴露出来。这是安全的需要。runtime 这个目录是要求权限为 chmod 777 ,即允许Web服务器具有完全的权限, 因为可能会涉及到写入临时文件等。 但是一个目录并未对Web用户可见。也就是说,权限给了,但是并不是Web用户可以访问到的。<br/> <br/>2.frontend
<br/>assets 目录用于存放前端资源包PHP类。 这里不需要了解什么是前端资源包,只要大致知道是用于管理CSS、js等前端资源就可以了。config 用于存放本应用的配置文件,包含主配置文件 main.php 和全局参数配置文件 params.php 。models views controllers 3个目录分别用于存放数据模型类、视图文件、控制器类。这个是我们编码的核心,也是我们工作最多的目录。widgets 目录用于存放一些常用的小挂件的类文件。tests 目录用于存放测试类。web 目录从名字可以看出,这是一个对于Web服务器可以访问的目录。 除了这一目录,其他所有的目录不应对Web用户暴露出来。这是安全的需要。runtime 这个目录是要求权限为 chmod 777 ,即允许Web服务器具有完全的权限, 因为可能会涉及到写入临时文件等。 但是一个目录并未对Web用户可见。也就是说,权限给了,但是并不是Web用户可以访问到的。<br/> <br/>2.frontend <br/>我们的目标最终用户提供的主要接口的前端应用。其实,前台和后台是一样的,只是我们逻辑上的一个划分.。<br/> 好了,现在问题来了。对于 frontend backend console 等独立的应用而言, 他们的内容放在各自的目录下面,他们的运作必然用到Yii框架等 vendor 中的程序。 他们是如何关联起来的?这个秘密,或者说整个Yii应用的目录结构的秘密, 就包含在一个传说中的称为入口文件的地方。<br/>
<br/>我们的目标最终用户提供的主要接口的前端应用。其实,前台和后台是一样的,只是我们逻辑上的一个划分.。<br/> 好了,现在问题来了。对于 frontend backend console 等独立的应用而言, 他们的内容放在各自的目录下面,他们的运作必然用到Yii框架等 vendor 中的程序。 他们是如何关联起来的?这个秘密,或者说整个Yii应用的目录结构的秘密, 就包含在一个传说中的称为入口文件的地方。<br/><?phpdefined('YII_DEBUG') or define('YII_DEBUG', true);
defined('YII_ENV') or define('YII_ENV', 'dev');
require(__DIR__ . '/../../vendor/autoload.php');
require(__DIR__ . '/../../vendor/yiisoft/yii2/Yii.php');
require(__DIR__ . '/../../common/config/bootstrap.php');
require(__DIR__ . '/../config/bootstrap.php');
$config = yii\helpers\ArrayHelper::merge(
require(__DIR__ . '/../../common/config/main.php'),
require(__DIR__ . '/../../common/config/main-local.php'),
require(__DIR__ . '/../config/main.php'),
require(__DIR__ . '/../config/main-local.php'));
$application = new yii\web\Application($config);$application->run();
 <br/><br/><br/>Ce qui suit est le dossier public global 4.common
<br/><br/><br/>Ce qui suit est le dossier public global 4.common <br/>
<br/> <br/> D'après le diagramme de structure des répertoires ci-dessus, vous pouvez voir qu'il y a 3 choses dans le répertoire environnement :
<br/> D'après le diagramme de structure des répertoires ci-dessus, vous pouvez voir qu'il y a 3 choses dans le répertoire environnement :  vendor 。 这个目录从字面的意思看,就是各种第三方的程序。 这是Composer安装的其他程序的存放目录,包含Yii框架本身,也放在这个目录下面。 如果你向composer.json 目录增加了新的需要安装的程序,那么下次调用Composer的时候, 就会把新安装的目录也安装在这个 vendor 下面。<br/><br/>下面也是一些不太常用的文件夹7.vagrant
vendor 。 这个目录从字面的意思看,就是各种第三方的程序。 这是Composer安装的其他程序的存放目录,包含Yii框架本身,也放在这个目录下面。 如果你向composer.json 目录增加了新的需要安装的程序,那么下次调用Composer的时候, 就会把新安装的目录也安装在这个 vendor 下面。<br/><br/>下面也是一些不太常用的文件夹7.vagrant  8.tests
8.tests  <br/>
<br/>入口文件篇:
 <br/>
<br/> return "$baseUrl/{$route}{$anchor}"; } else { $url = "$baseUrl?{$this->routeParam}=" . urlencode($route); if (!empty($params) && ($query = http_build_query($params)) !== '') { $url .= '&' . $query; } 将urlencode去掉就可以了 3、入口文件内容 入口文件流程如下: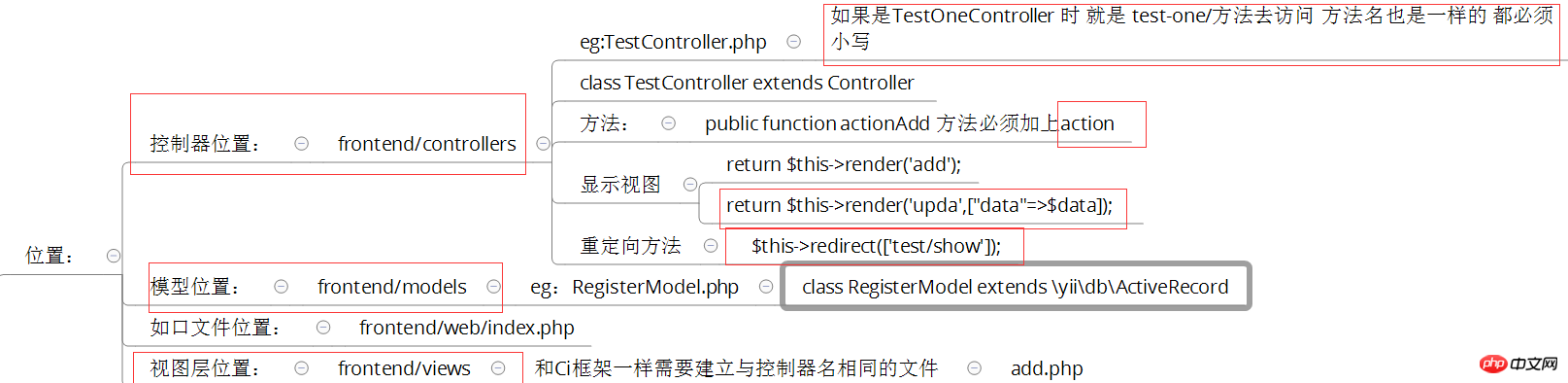 <br/>
<br/>public $defaultRoute = 'student/show';
修改前台或者后台控制器: eg :打开 frontend/config/main.php 中
'params' => $params, 'defaultRoute' => 'login/show',
namespace frontend\controllers;
use Yii;
use yii\web\Controller;
vendor/yiisoft/yii2/web/Controller.php
(该控制器继承的是\yii\base\Controller) \web\Controller.php中干了些什么
1、默认开启了 授权防止csrf攻击
2、响应Ajax请求的视图渲染
3、将参数绑定到动作(就是看是不是属于框架自己定义的方法,如果没有定义就走run方法解析)
4、检测方法(beforeAction)beforeAction() 方法会触发一个 beforeAction 事件,在事件中你可以追加事件处理操作;
5、重定向路径 以及一些http Response(响应) 的设置
<br/>
use yii\db\Query; //使用query查询
use yii\data\Pagination;//分页
use yii\data\ActiveDataProvider;//活动记录
use frontend\models\ZsDynasty;//自定义数据模型
class StudentController extends Controller {
$request = YII::$app->request;//获取请求组件
$request->get('id');//获取get方法数据
$request->post('id');//获取post方法数据
$request->isGet;//判断是不是get请求
$request->isPost;//判断是不是post请求
$request->userIp;//获取用户IP地址
$res = YII::$app->response;//获取响应组件
$res->statusCode = '404';//设置状态码
$this->redirect('http://baodu.com');//页面跳转
$res->sendFile('./b.jpg');//文件下载
$session = YII::$app->session;
$session->isActive;//判断session是否开启
$session->open();//开启session
//设置session值
$session->set('user','zhangsan');//第一个参数为键,第二个为值
$session['user']='zhangsan';
//获取session值
$session->get('user');
$session['user'];
//删除session值
$session-remove('user');
unset($session['user']);
$cookies = Yii::$app->response->cookies;//获取cookie对象
$cookie_data = array('name'=>'user','value'=>'zhangsan')//新建cookie数据
$cookies->add(new Cookie($cookie_data));
$cookies->remove('id');//删除cookie
$cookies->getValue('user');//获取cookie<?php
namespace frontend\models;
class ListtModel extends \yii\db\ActiveRecord {
public static function tableName()
{
return 'listt';
}
public function one(){
return $this->find()->asArray()->one();
}
}控制器引用
<?php namespace frontend\controllers; use Yii; use yii\web\controller; use frontend\models\ListtModel; class ListtController extends Controller{ public function actionAdd(){ $model=new ListtModel; $list=$model->one(); $data=$model->find()->asArray()->where("id=1")->all(); print_r($data); } } ?> <br/>
<br/> <br/> 而views下面会有一个默认的layouts文件夹,里面存放的就是布局文件,什么意思呢?:在控制器中,会有一个layout字段,如果制定他为一个layout视图文件,比如common.php,那么视图就会以他为主视图,其他的view视图片段都会作为显示片段嵌入到layout文件common.php中.而如果不明确重载layout字段,那么默认layout的值是main,意味着layouts的main.php是视图模板。控制器:
<br/> 而views下面会有一个默认的layouts文件夹,里面存放的就是布局文件,什么意思呢?:在控制器中,会有一个layout字段,如果制定他为一个layout视图文件,比如common.php,那么视图就会以他为主视图,其他的view视图片段都会作为显示片段嵌入到layout文件common.php中.而如果不明确重载layout字段,那么默认layout的值是main,意味着layouts的main.php是视图模板。控制器: <br/>common.php:
<br/>common.php: <br/><br/>layouts
<br/><br/>layouts 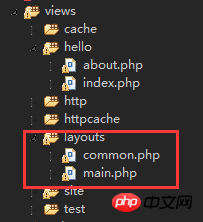 <br/>这样就达到了视图复用的作用。<br/> 控制器中写入$layout <br/>
<br/>这样就达到了视图复用的作用。<br/> 控制器中写入$layout <br/>//$layout="main" 系统默认文件
//$layout=null 会找父类中默认定义的main public $layout="common";
public function actionIndex(){
return $this->render('index');
}
将以下内容插入 common中 <?=$content;?>
它就是index文件中的内容
'db' => [
'class' => 'yii\db\Connection',
'dsn' => 'mysql:host=localhost;dbname=hyii2', //数据库hyii2
'username' => 'root',
'password' => 'pwhyii2',
'charset' => 'utf8',
],
'db2' => [
'class' => 'yii\db\Connection',
'dsn' => 'mysql:host=localhost;dbname=hyii', //数据库hyii
'username' => 'root',
'password' => 'pwhyii',
'charset' => 'utf8',
],


$id=Yii::$app->db->getLastInsertID();
Yii::$app->db->createCommand()->insert('user', [
'name' => 'test',
'age' => 30,
])->execute();Yii::$app->db->createCommand()->batchInsert('user', ['name', 'age'], [
['test01', 30],
['test02', 20],
['test03', 25],
])->execute();
删除[php] view plain copy
Yii::$app->db->createCommand()->delete('user', 'age = 30')->execute();Yii::$app->db->createCommand()->update('user', ['age' => 40], 'name = test')->execute();
查询[php] view plain copy
//createCommand(执行原生的SQL语句)
$sql= "SELECT u.account,i.* FROM sys_user as u left join user_info as i on u.id=i.user_id";
$rows=Yii::$app->db->createCommand($sql)->query();
查询返回多行:
$command = Yii::$app->db->createCommand('SELECT * FROM post');
$posts = $command->queryAll();
返回单行
$command = Yii::$app->db->createCommand('SELECT * FROM post WHERE id=1');
$post = $command->queryOne();
查询多行单值:
$command = Yii::$app->db->createCommand('SELECT title FROM post');
$titles = $command->queryColumn();
查询标量值/计算值:
$command = Yii::$app->db->createCommand('SELECT COUNT(*) FROM post');
$postCount = $command->queryScalar();
//入库一维数组
public function add($data)
{
$this->setAttributes($data);
$this->isNewRecord = true;
$this->save();
return $this->id;
}
//入库二维数组
public function addAll($data){
$ids=array();
foreach($data as $attributes)
{
$this->isNewRecord = true;
$this->setAttributes($attributes);
$this->save()&& array_push($ids,$this->id) && $this->id=0;
}
return $ids;
}
public function rules()
{
return [
[['title','content'],'required'
]];
}
控制器:
$ids=$model->addAll($data);
var_dump($ids);$user = User::find()->where(['name'=>'test'])->one();
$user->delete();
$result = User::deleteAll(['age'=>'30']);
$result = User::deleteByPk(1);
/**
* @param $files 字段
* @param $values 值
* @return int 影响行数
*/ public function del($field,$values){
//
$res = $this->find()->where(['in', "$files", $values])->deleteAll();
$res=$this->deleteAll(['in', "$field", "$values"]);
return $res;
}[php] view plain copy
$user = User::find()->where(['name'=>'test'])->one(); //获取name等于test的模型
$user->age = 40; //修改age属性值
$user->save(); //保存
[php] view plain copy
$result = User::model()->updateAll(['age'=>40],['name'=>'test']);
/** * @param $data 修改数据 * @param $where 修改条件 * @return int 影响行数 */ public function upda($data,$where){ $result = $this->updateAll($data,$where); // return $this->id; return $result; }Customer::find()->one();
此方法返回一条数据;
Customer::find()->all();
此方法返回所有数据;
Customer::find()->count();
此方法返回记录的数量;
Customer::find()->average();
此方法返回指定列的平均值;
Customer::find()->min();
此方法返回指定列的最小值 ;
Customer::find()->max();
此方法返回指定列的最大值 ;
Customer::find()->scalar();
此方法返回值的第一行第一列的查询结果;
Customer::find()->column();
此方法返回查询结果中的第一列的值;
Customer::find()->exists();
此方法返回一个值指示是否包含查询结果的数据行;
Customer::find()->batch(10);
每次取10条数据
Customer::find()->each(10);
每次取10条数据,迭代查询
//根据sql语句查询:查询name=test的客户 Customer::model()->findAllBySql("select * from customer where name = test");
//根据主键查询:查询主键值为1的数据 Customer::model()->findByPk(1);
//根据条件查询(该方法是根据条件查询一个集合,可以是多个条件,把条件放到数组里面)
Customer::model()->findAllByAttributes(['username'=>'admin']);
//子查询 $subQuery = (new Query())->select('COUNT(*)')->from('customer');
// SELECT `id`, (SELECT COUNT(*) FROM `customer`) AS `count` FROM `customer` $query = (new Query())->select(['id', 'count' => $subQuery])->from('customer');
//关联查询:查询客户表(customer)关联订单表(orders),条件是status=1,客户id为1,从查询结果的第5条开始,查询10条数据 $data = (new Query())
->select('*')
->from('customer')
->join('LEFT JOIN','orders','customer.id = orders.customer_id')
->where(['status'=>'1','customer.id'=>'1'])
->offset(5) ->limit(10) ->all()[php] view plain copy
/**
*客户表Model:CustomerModel
*订单表Model:OrdersModel
*国家表Model:CountrysModel
*首先要建立表与表之间的关系
*在CustomerModel中添加与订单的关系
*/
Class CustomerModel extends \yii\db\ActiveRecord
{
...
//客户和订单是一对多的关系所以用hasMany
//此处OrdersModel在CustomerModel顶部别忘了加对应的命名空间
//id对应的是OrdersModel的id字段,order_id对应CustomerModel的order_id字段
public function getOrders()
{
return $this->hasMany(OrdersModel::className(), ['id'=>'order_id']);
}
//客户和国家是一对一的关系所以用hasOne
public function getCountry()
{
return $this->hasOne(CountrysModel::className(), ['id'=>'Country_id']);
}
....
}
// 查询客户与他们的订单和国家
CustomerModel::find()->with('orders', 'country')->all();
// 查询客户与他们的订单和订单的发货地址(注:orders 与 address都是关联关系)
CustomerModel::find()->with('orders.address')->all();
// 查询客户与他们的国家和状态为1的订单
CustomerModel::find()->with([
'orders' => function ($query) {
$query->andWhere('status = 1');
},
'country',
])->all();yii2 rbac 详解
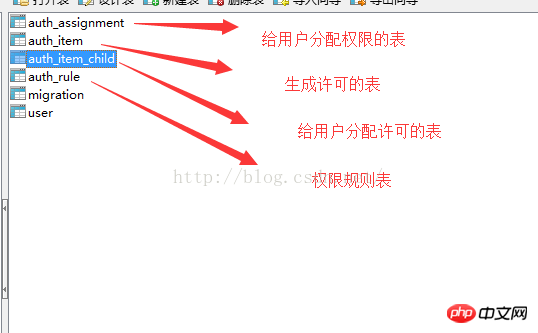 <br/><br/> 4. Utilisez yii rbac pour les opérations (chaque opération que vous effectuez exploitera les données dans les 4 tables de rbac pour vérifier si les autorisations pertinentes ont été établies. Vous pouvez entrer directement dans ces tables pour afficher) <br/>Enregistrez un permission : (les données seront générées dans la table d'autorisation décrite ci-dessus) public function createPermission($item) { $auth = Yii::$app->authManager;<br/> $createPost = $auth-> ); $createPost->description = 'Créé' . $item 'Autorisation'; $auth->add($createPost); ><br/>public function createRole($item) { $auth = Yii::$app->authManager; $role = $auth->createRole($item); $role- >description = ' Créé' . $item . 'Role'; $auth->add($role); }Attribuer des autorisations aux rôles<br/>public function createEmpowerment($items) { $ auth = Yii::$ app->authManager; $parent = $auth->createRole($items['name']); $child = $auth->createPermission($items['description' ]);<br/> $auth->addChild($parent, $child); }<br/>Ajouter une règle à une autorisation : <br/><br/>La règle consiste à ajouter des rôles et des autorisations Contraintes supplémentaires. Une règle est qu'une classe s'étendant de <br/> doit implémenter la méthode .
<br/><br/> 4. Utilisez yii rbac pour les opérations (chaque opération que vous effectuez exploitera les données dans les 4 tables de rbac pour vérifier si les autorisations pertinentes ont été établies. Vous pouvez entrer directement dans ces tables pour afficher) <br/>Enregistrez un permission : (les données seront générées dans la table d'autorisation décrite ci-dessus) public function createPermission($item) { $auth = Yii::$app->authManager;<br/> $createPost = $auth-> ); $createPost->description = 'Créé' . $item 'Autorisation'; $auth->add($createPost); ><br/>public function createRole($item) { $auth = Yii::$app->authManager; $role = $auth->createRole($item); $role- >description = ' Créé' . $item . 'Role'; $auth->add($role); }Attribuer des autorisations aux rôles<br/>public function createEmpowerment($items) { $ auth = Yii::$ app->authManager; $parent = $auth->createRole($items['name']); $child = $auth->createPermission($items['description' ]);<br/> $auth->addChild($parent, $child); }<br/>Ajouter une règle à une autorisation : <br/><br/>La règle consiste à ajouter des rôles et des autorisations Contraintes supplémentaires. Une règle est qu'une classe s'étendant de <br/> doit implémenter la méthode . yiirbacRuleSur la hiérarchie, le personnage author que nous avons créé précédemment ne peut pas éditer ses propres articles, réparons cela. <br/>Nous avons d'abord besoin d'une règle pour vérifier que l'utilisateur est l'auteur de cet article : <br/>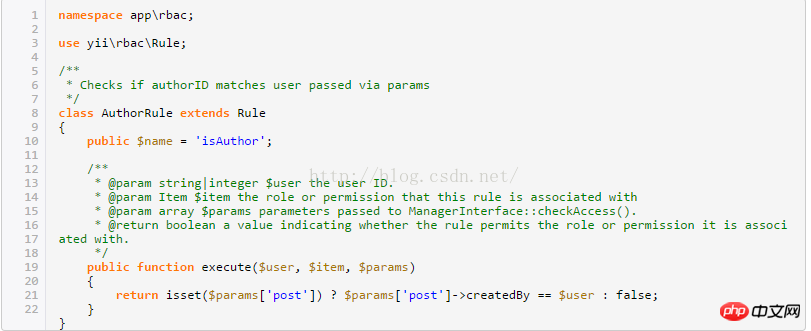 <br/> <br/>Remarque : dans l'exécution de la méthode ci-dessus, $user provient de l'ID utilisateur après la connexion de l'utilisateur<br/>
<br/> <br/>Remarque : dans l'exécution de la méthode ci-dessus, $user provient de l'ID utilisateur après la connexion de l'utilisateur<br/>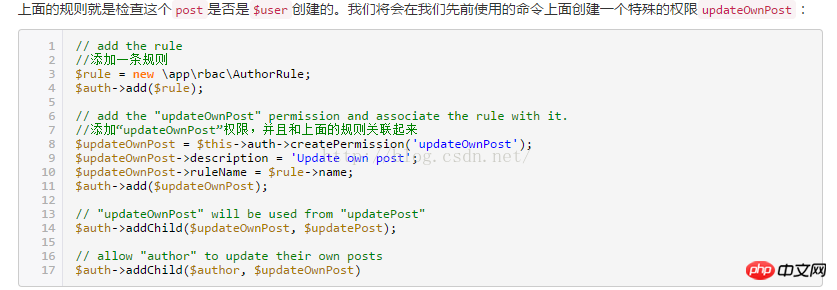 <br/>Déterminer les autorisations de l'utilisateur après sa connexion
<br/>Déterminer les autorisations de l'utilisateur après sa connexion <br/><br/>Lien pour référencer l'article : http://www.360us.net/article/13.html http://www.open-open.com/lib/view/open1424832085843.html<br/>
<br/><br/>Lien pour référencer l'article : http://www.360us.net/article/13.html http://www.open-open.com/lib/view/open1424832085843.html<br/>4. 在微信里调支付宝
 <br/>
<br/>
$returnUrl = 'http://域名/user/h5_alipay/return_url.php'; //付款成功后的 同步回调地址,可直接设置为会员中心的地址 $notifyUrl = 'http://域名/notify_url.php'; //付款成功后的异回调地址,如果你的回调地址中包含&符号,最好把回调直接放根目录
$orderName=iconv("GB2312//IGNORE","UTF-8",'支付宝充值');

密钥管理->开放平台密钥,填写添加了电脑网站支付的应用的APPID
$notifyUrl = 'http://域名/user/h5_alipay/notify_url.php';
//付款成功后的异步回调地址支付宝以post的方式回调
$returnUrl = 'http://域名/user/pay_chongzhi.php';
//付款成功后,支付宝以 get同步的方式回调给发起支付方
$sj=date("Y-m-d H:i:s");
$userid=returnuserid($_SESSION["SHOPUSER"]);
$ddbh=$bh="h5_ali_".time()."_".$userid;
//订单编号
$uip=$_SERVER["REMOTE_ADDR"];
//ip地址 $money1=$_POST[t1];
//bz备注,ddzt与alipayzt及ifok表示订单状态,
intotable("yjcode_dingdang","bh,ddbh,userid,sj,uip,money1,ddzt,alipayzt,bz,ifok","'".$bh."','".$ddbh."',".$userid.",'".$sj."','".$uip."',".$money1.",'等待买家付款','','支付宝充值',0");
//订单入库
//die(mysql_error());
//数据库错误
//订单名称
$orderName=iconv("GB2312//IGNORE","UTF-8",'支付宝充值');
//注意编码
$body = $orderName=iconv("GB2312//IGNORE","UTF-8",'支付宝充值');
$outTradeNo = $ddbh;
//你自己的商品订单号
$payAmount = $money1;
//付款金额,单位:元
$signType = 'RSA2';
//签名算法类型,支持RSA2和RSA,推荐使用RSA2
$saPrivateKey='这里填2048位的私钥';
//私钥
$aliPay = new AlipayService($appid,$returnUrl,$notifyUrl,$saPrivateKey);
$payConfigs = $aliPay->doPay($payAmount,$outTradeNo,$orderName,$returnUrl,$notifyUrl);
class AlipayService {
protected $appId;
protected $returnUrl;
protected $notifyUrl;
protected $charset;
//私钥值
protected $rsaPrivateKey;
public function __construct($appid, $returnUrl, $notifyUrl,$saPrivateKey) {
$this->appId = $appid;
$this->returnUrl = $returnUrl;
$this->notifyUrl = $notifyUrl;
$this->charset = 'UTF-8';
$this->rsaPrivateKey=$saPrivateKey;
}
/**
* 发起订单
* @param float $totalFee 收款金额 单位元
* @param string $outTradeNo 订单号
* @param string $orderName 订单名称
* @param string $notifyUrl 支付结果通知url 不要有问号
* @param string $timestamp 订单发起时间
* @return array
*/
public function doPay($totalFee, $outTradeNo, $orderName, $returnUrl,$notifyUrl)
{
//请求参数
$requestConfigs = array( 'out_trade_no'=>$outTradeNo, 'product_code'=>'QUICK_WAP_WAY', 'total_amount'=>$totalFee,
//单位 元 'subject'=>$orderName, //订单标题 );
$commonConfigs = array(
//公共参数
'app_id' => $this->appId, 'method' => 'alipay.trade.wap.pay',
//接口名称 'format' => 'JSON',
'return_url' => $returnUrl, 'charset'=>$this->charset, 'sign_type'=>'RSA2',
'timestamp'=>date('Y-m-d H:i:s'), 'version'=>'1.0', 'notify_url' => $notifyUrl,
'biz_content'=>json_encode($requestConfigs), );
$commonConfigs["sign"] = $this->generateSign($commonConfigs, $commonConfigs['sign_type']);
return $commonConfigs;
}
public function generateSign($params, $signType = "RSA") {
return $this->sign($this->getSignContent($params), $signType);
}
protected function sign($data, $signType = "RSA") {
$priKey=$this->rsaPrivateKey;
$res = "-----BEGIN RSA PRIVATE KEY-----\n" .
wordwrap($priKey, 64, "\n", true) .
"\n-----END RSA PRIVATE KEY-----";
($res) or die('您使用的私钥格式错误,请检查RSA私钥配置');
if ("RSA2" == $signType) {
openssl_sign($data, $sign, $res, version_compare(PHP_VERSION,'5.4.0', '<') ? SHA256 : OPENSSL_ALGO_SHA256);
//OPENSSL_ALGO_SHA256是php5.4.8以上版本才支持
} else {
openssl_sign($data, $sign, $res);
}
$sign = base64_encode($sign);
return $sign;
}
/**
* 校验$value是否非空
* if not set ,return true;
* if is null , return true;
**/
protected function checkEmpty($value) {
if (!isset($value))
return true;
if ($value === null)
return true;
if (trim($value) === "")
return true;
return false;
}
public function getSignContent($params) {
ksort($params);
$stringToBeSigned = "";
$i = 0;
foreach ($params as $k => $v) {
if (false === $this->checkEmpty($v) && "@" != substr($v, 0, 1)) {
// 转换成目标字符集
$v = $this->characet($v, $this->charset);
if ($i == 0) {
$stringToBeSigned .= "$k" . "=" . "$v";
} else {
$stringToBeSigned .= "&" . "$k" . "=" . "$v";
}
$i++;
}
}
unset ($k, $v);
return $stringToBeSigned;
}
/**
* 转换字符集编码
* @param $data
* @param $targetCharset
* @return string
*/
function characet($data, $targetCharset) {
if (!empty($data)) {
$fileType = $this->charset;
if (strcasecmp($fileType, $targetCharset) != 0) {
$data = mb_convert_encoding($data, $targetCharset, $fileType);
}
}
return $data;
} }
function isWeixin(){
if ( strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessenger') !== false ) {
return true;
}
return false;
}
$queryStr = http_build_query($payConfigs); if(isWeixin()):
//注意下面的ap.js ,文件的存在目录,如果不确定.可以写绝对地址.否则可能微信中没法弹出提示窗口,
?>
<script>
var gotoUrl = 'https://openapi.alipaydev.com/gateway.do?<?=$queryStr?>';
//注意上面及下面的alipaydev.com,用的是沙箱接口,去掉dev表示正式上线
_AP.pay(gotoUrl); </script> <?php
header('Content-type:text/html; Charset=GB2312');
//支付宝公钥,账户中心->密钥管理->开放平台密钥,找到添加了支付功能的应用,根据你的加密类型,查看支付宝公钥
$alipayPublicKey=''; $aliPay = new AlipayService($alipayPublicKey);
//验证签名,如果签名失败,注意编码问题.特别是有中文时,可以换成英文,再测试
$result = $aliPay->rsaCheck($_POST,$_POST['sign_type']);
if($result===true){
//处理你的逻辑,例如获取订单号
$_POST['out_trade_no'],订单金额$_POST['total_amount']等
//程序执行完后必须打印输出“success”(不包含引号)。
如果商户反馈给支付宝的字符不是success这7个字符,支付宝服务器会不断重发通知,直到超过24小时22分钟。
一般情况下,25小时以内完成8次通知(通知的间隔频率一般是:4m,10m,10m,1h,2h,6h,15h);
$out_trade_no = $_POST['out_trade_no'];
//支付宝交易号
$trade_no = $_POST['trade_no'];
//交易状态
$trade_status = $_POST['trade_status'];
switch($trade_status){
case "WAIT_BUYER_PAY";
$nddzt="等待买家付款";
break;
case "TRADE_FINISHED": case "TRADE_SUCCESS"; $nddzt="交易成功";
break;
}
if(empty($trade_no)){echo "success";exit;}
//注意,这里的查询不能 强制用户登录,则否支付宝没法进入本页面.没法通知成功
$sql="select ifok,jyh from yjcode_dingdang where ifok=1 and jyh='".$trade_no."'";mysql_query("SET NAMES 'GBK'");$res=mysql_query($sql);
//支付宝生成的流水号
if($row=mysql_fetch_array($res)){echo "success";exit;
}
$sql="select * from yjcode_dingdang where ddbh='".$out_trade_no."' and ifok=0 and ddzt='等待买家付款'";
mysql_query("SET NAMES 'GBK'");
$res=mysql_query($sql);
if($row=mysql_fetch_array($res)){
if(1==$row['ifok']){
echo "success";exit;
}
if($trade_status=="TRADE_SUCCESS" || $trade_status=="TRADE_FINISHED"){
if($row['money1']== $_POST['total_fee'] ){
$sj=time();$uip=$_SERVER["REMOTE_ADDR"];
updatetable("yjcode_dingdang","sj='".$sj."',uip='".$uip."',alipayzt='".$trade_status."',ddzt='".$nddzt."',ifok=1,jyh='".$trade_no."' where id=".$row[id]);
$money1=$row["money1"];
//修改订单状态为成功付款
PointIntoM($userid,"支付宝充值".$money1."元",$money1);
//会员余额增加 echo "success";exit;
}
}
}
//——请根据您的业务逻辑来编写程序(以上代码仅作参考)——
echo 'success';exit();
}
echo 'fail';exit();
class AlipayService {
//支付宝公钥
protected $alipayPublicKey;
protected $charset;
public function __construct($alipayPublicKey) {
$this->charset = 'utf8';
$this->alipayPublicKey=$alipayPublicKey;
}
/** * 验证签名 **/
public function rsaCheck($params) {
$sign = $params['sign'];
$signType = $params['sign_type'];
unset($params['sign_type']);
unset($params['sign']);
return $this->verify($this->getSignContent($params), $sign, $signType);
}
function verify($data, $sign, $signType = 'RSA') {
$pubKey= $this->alipayPublicKey;
$res = "-----BEGIN PUBLIC KEY-----\n" .
wordwrap($pubKey, 64, "\n", true) .
"\n-----END PUBLIC KEY-----";
($res) or die('支付宝RSA公钥错误。请检查公钥文件格式是否正确');
//调用openssl内置方法验签,返回bool值
if ("RSA2" == $signType) {
$result = (bool)openssl_verify($data, base64_decode($sign), $res, version_compare(PHP_VERSION,'5.4.0', '<') ? SHA256 : OPENSSL_ALGO_SHA256);
} else {
$result = (bool)openssl_verify($data, base64_decode($sign), $res);
} // if(!$this->checkEmpty($this->alipayPublicKey)) { //
//释放资源 //
openssl_free_key($res);
// }
return $result;
}
/** * 校验$value是否非空 * if not set ,return true; * if is null , return true; **/
protected function checkEmpty($value) {
if (!isset($value))
return true;
if ($value === null)
return true;
if (trim($value) === "")
return true;
return false;
}
public function getSignContent($params) {
ksort($params);
$stringToBeSigned = "";
$i = 0;
foreach ($params as $k => $v) {
if (false === $this->checkEmpty($v) && "@" != substr($v, 0, 1)) {
// 转换成目标字符集
$v = $this->characet($v, $this->charset);
if ($i == 0) {
$stringToBeSigned .= "$k" . "=" . "$v";
} else {
$stringToBeSigned .= "&" . "$k" . "=" . "$v";
}
$i++;
}
}
unset ($k, $v);
return $stringToBeSigned;
}
/** * 转换字符集编码 * @param $data * @param $targetCharset * @return string */
function characet($data, $targetCharset) {
if (!empty($data)) {
$fileType = $this->charset;
if (strcasecmp($fileType, $targetCharset) != 0) {
$data = mb_convert_encoding($data, $targetCharset, $fileType);
//$data = iconv($fileType, $targetCharset.'//IGNORE', $data);
}
}
return $data;
}
}<?php
define('PHPS_PATH', dirname(__FILE__).DIRECTORY_SEPARATOR);
//$_POST['trade_no']=1; if($_POST['trade_no']){ $alipayPublicKey='MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAyg8BC9UffA4ZoMl12zz';
//RSA公钥,与支付时的私钥对应
$aliPay = new AlipayService2($alipayPublicKey);
//验证签名
$result = $aliPay->rsaCheck($_POST,$_POST['sign_type']);
//file_put_contents('333.txt',$_POST);
if($result===true){
//处理你的逻辑,例如获取订单号
$_POST['out_trade_no'],订单金额$_POST['total_amount']等
$out_trade_no = $_POST['out_trade_no'];
//$out_trade_no = '2018022300293843964';
//支付宝交易号
$trade_no = $_POST['trade_no'];
//交易状态
$trade_status = $_POST['trade_status'];
//$trade_status='';
$userinfo = array();
if($trade_status=="TRADE_SUCCESS" || $trade_status=="TRADE_FINISHED"){
//ini_set('display_errors',1);
//错误信息
//ini_set('display_startup_errors',1);
//php启动错误信息
//error_reporting(-1);
//打印出所有的 错误信息
$mysql_user=include(PHPS_PATH.'/caches/configs/database.php');
$username=$mysql_user['default']['username'];
$password=$mysql_user['default']['password'];
$tablepre=$mysql_user['default']['tablepre'];
$database=$mysql_user['default']['database'];
$con = mysqli_connect($mysql_user['default']['hostname'],$username,$password); mysqli_select_db($con,$database);
$sql = ' SELECT * FROM '.$tablepre."pay_account where trade_sn='".$out_trade_no."'";
$result2=mysqli_query($con,$sql);
$orderinfo=mysqli_fetch_array($result2);;
$uid=$orderinfo['userid'];
$sql2 = ' SELECT * FROM '.$tablepre."member where userid=".$uid;
$result1=mysqli_query($con,$sql2); $userinfo=mysqli_fetch_array($result1);;
if($orderinfo){
if($orderinfo['status']=='succ'){
//file_put_contents('31.txt',1);
echo 'success';
mysqli_close($con);
exit();
}else{
// if($orderinfo['money']== $_POST['total_amount'] ){
$money = $orderinfo['money'];
$amount = $userinfo['amount'] + $money;
$sql3 = ' update '.$tablepre."member set amount= ".$amount." where userid=".$uid;
$result3=mysqli_query($con,$sql3);
$sql4 = ' update '.$tablepre."pay_account set status= 'succ' where userid=".$uid ." and trade_sn='".$out_trade_no."'";
$result4=mysqli_query($con,$sql4);
//file_put_contents('1.txt',$result4);
echo 'success';
mysqli_close($con);
exit();
// }
}
} else {
echo 'success';exit();
}
}
echo 'success';exit();
} echo 'fail';exit();
} class AlipayService2 {
//支付宝公钥
protected $alipayPublicKey;
protected $charset;
public function __construct($alipayPublicKey) {
$this->charset = 'utf8';
$this->alipayPublicKey=$alipayPublicKey;
}
/** * 验证签名 **/
public function rsaCheck($params) {
$sign = $params['sign'];
$signType = $params['sign_type'];
unset($params['sign_type']);
unset($params['sign']);
return $this->verify($this->getSignContent($params), $sign, $signType);
}
function verify($data, $sign, $signType = 'RSA') {
$pubKey= $this->alipayPublicKey;
$res = "-----BEGIN PUBLIC KEY-----\n" .
wordwrap($pubKey, 64, "\n", true) .
"\n-----END PUBLIC KEY-----";
($res) or die('支付宝RSA公钥错误。请检查公钥文件格式是否正确');
//调用openssl内置方法验签,返回bool值
if ("RSA2" == $signType) {
$result = (bool)openssl_verify($data, base64_decode($sign), $res, version_compare(PHP_VERSION,'5.4.0', '<') ? SHA256 : OPENSSL_ALGO_SHA256);
} else {
$result = (bool)openssl_verify($data, base64_decode($sign), $res);
}
// if(!$this->checkEmpty($this->alipayPublicKey)) {
//
//释放资源 //
openssl_free_key($res); //
}
return $result;
}
/** * 校验$value是否非空 * if not set ,return true; * if is null , return true; **/
protected function checkEmpty($value) {
if (!isset($value))
return true;
if ($value === null)
return true;
if (trim($value) === "")
return true;
return false;
}
public function getSignContent($params) {
ksort($params);
$stringToBeSigned = "";
$i = 0;
foreach ($params as $k => $v) {
if (false === $this->checkEmpty($v) && "@" != substr($v, 0, 1)) {
// 转换成目标字符集
$v = $this->characet($v, $this->charset);
if ($i == 0) {
$stringToBeSigned .= "$k" . "=" . "$v";
} else {
$stringToBeSigned .= "&" . "$k" . "=" . "$v";
}
$i++;
}
}
unset ($k, $v);
return $stringToBeSigned;
} /** * 转换字符集编码 * @param $data * @param $targetCharset * @return string */
function characet($data, $targetCharset) {
if (!empty($data)) {
$fileType = $this->charset;
if (strcasecmp($fileType, $targetCharset) != 0) {
$data = mb_convert_encoding($data, $targetCharset, $fileType);
//$data = iconv($fileType, $targetCharset.'//IGNORE', $data);
}
}
return $data;
}
}
?>5. 抓包
常用抓包工具
6. https / http
7. comme l'efficacité
8. gauche, droite, rejoindre, résoudre le produit cartésien
union SQL, intersection, sauf instruction
9. oop封装、继承、多态
php面向对象之继承、多态、封装简介
作者:PHP中文网2018-03-02 09:49:15
interface InterAnimal{
public function speak();
public function name($name);
}//接口实现 class cat implements InterAnimal{
public function speak(){
echo "speak";
}
public function name($name){
echo "My name is ".$name;
}
}<br/>class Computer {
private $_name = '联想';
public function __get($_key) {
return $this->$_key;
}
public function run() {
echo '父类run方法';
}}class NoteBookComputer extends Computer {}$notebookcomputer = new NoteBookComputer ();
$notebookcomputer->run ();
//继承父类中的run()方法echo $notebookcomputer->_name;
//通过魔法函数__get()获得私有字段<br/>class Computer {
public $_name = '联想';
protected function run() {
echo '我是父类';
}}//重写其字段、方法class NoteBookComputer extends Computer {
public $_name = 'IBM';
public function run() {
echo '我是子类';
}}<br/>abstract class Computer {
abstract function run();
}
final class NotebookComputer extends Computer {
public function run() {
echo '抽象类的实现';
}
}<br/>interface Computer {
public function version();
public function work();
}class NotebookComputer implements Computer {
public function version() {
echo '联想<br>';
}
public function work() {
echo '笔记本正在随时携带运行!';
}}class desktopComputer implements Computer {
public function version() {
echo 'IBM';
}
public function work() {
echo '台式电脑正在工作站运行!';
}}class Person {
public function run($type) {
$type->version ();
$type->work ();
}}
$person = new Person ();
$desktopcomputer = new desktopComputer ();
$notebookcomputer = new NoteBookComputer ();
$person->run ( $notebookcomputer );<br/> Objet d'identification orienté objet PHP
Objet d'identification orienté objet PHP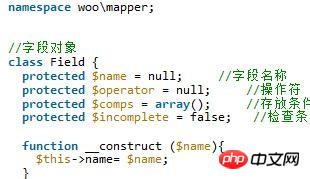 Explication détaillée de l'instance d'objet d'identification orientée objet PHP
Explication détaillée de l'instance d'objet d'identification orientée objet PHP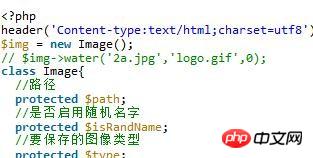 Partage de code d'encapsulation PHP pour la classe de filigrane d'image
Partage de code d'encapsulation PHP pour la classe de filigrane d'image Explication détaillée de la classe d'opération Mysql d'encapsulation PHP
Explication détaillée de la classe d'opération Mysql d'encapsulation PHP10 mvc

1. Chargement de ressources à partir de plusieurs noms de domaine
1. Le « premier kilomètre » fait référence au premier point de vente du trafic du World Wide Web à transmettre aux utilisateurs. Il s'agit du lien permettant au serveur du site Web d'accéder à Internet. Cette bande passante de sortie détermine la vitesse d'accès et les visites simultanées qu'un site Web peut offrir aux utilisateurs. Lorsque les demandes des utilisateurs dépassent la bande passante de sortie du site Web, une congestion se produit à la sortie.
2. "Le dernier kilomètre", le dernier lien par lequel le trafic du World Wide Web est transmis aux utilisateurs, c'est-à-dire le lien par lequel les utilisateurs accèdent à Internet. La bande passante de l'accès d'un utilisateur affecte la capacité de l'utilisateur à recevoir du trafic. Avec le développement vigoureux des opérateurs de télécommunications, la bande passante d'accès des utilisateurs a été considérablement améliorée et le problème du « dernier kilomètre » a été pratiquement résolu. Processus de base
 <br/>1. L'utilisateur saisit le nom de domaine auquel il doit accéder dans le navigateur. <br/>2. Le navigateur demande au serveur DNS de résoudre le nom de domaine. <br/>3. Le serveur DNS renvoie l'adresse IP du nom de domaine au navigateur. <br/>4. Le navigateur utilise l'adresse IP pour demander du contenu au serveur. <br/>5. Le serveur renvoie le contenu demandé par l'utilisateur au navigateur.
<br/>1. L'utilisateur saisit le nom de domaine auquel il doit accéder dans le navigateur. <br/>2. Le navigateur demande au serveur DNS de résoudre le nom de domaine. <br/>3. Le serveur DNS renvoie l'adresse IP du nom de domaine au navigateur. <br/>4. Le navigateur utilise l'adresse IP pour demander du contenu au serveur. <br/>5. Le serveur renvoie le contenu demandé par l'utilisateur au navigateur.  <br/>1. L'utilisateur saisit le nom de domaine auquel il doit accéder dans le navigateur. <br/>2. Le navigateur demande au serveur DNS de résoudre le nom de domaine. Étant donné que le CDN ajuste la résolution du nom de domaine, le serveur DNS finira par céder les droits de résolution du nom de domaine au serveur DNS dédié du CDN pointé par le CNAME. <br/>3. Le serveur DNS du CDN renvoie l’adresse IP du périphérique d’équilibrage de charge du CDN à l’utilisateur. <br/>4. L'utilisateur initie une demande d'accès à l'URL du contenu au dispositif d'équilibrage de charge du CDN. <br/>5. Le dispositif d'équilibrage de charge CDN sélectionnera un serveur de cache approprié pour fournir des services aux utilisateurs. <br/>La base de sélection comprend : déterminer quel serveur est le plus proche de l'utilisateur en fonction de l'adresse IP de l'utilisateur ; déterminer quel serveur possède le contenu dont l'utilisateur a besoin en fonction du nom de contenu porté dans l'URL demandée par l'utilisateur qui interroge le contenu ; de chaque situation de charge du serveur, déterminez quel serveur a la charge la plus faible. <br/>Sur la base de l'analyse complète de ce qui précède, les paramètres d'équilibrage de charge renverront l'adresse IP du serveur de cache à l'utilisateur. <br/>6. L'utilisateur fait une requête au serveur de cache. <br/>7. Le serveur de cache répond aux demandes des utilisateurs et fournit le contenu requis par l'utilisateur. <br/>Si ce serveur de cache n'a pas le contenu souhaité par l'utilisateur et que le périphérique d'équilibrage de charge l'alloue toujours à l'utilisateur, alors ce serveur demandera le contenu à son serveur de cache de niveau supérieur jusqu'à ce qu'il soit retracé jusqu'au site Web Le serveur d'origine extrait le contenu localement.
<br/>1. L'utilisateur saisit le nom de domaine auquel il doit accéder dans le navigateur. <br/>2. Le navigateur demande au serveur DNS de résoudre le nom de domaine. Étant donné que le CDN ajuste la résolution du nom de domaine, le serveur DNS finira par céder les droits de résolution du nom de domaine au serveur DNS dédié du CDN pointé par le CNAME. <br/>3. Le serveur DNS du CDN renvoie l’adresse IP du périphérique d’équilibrage de charge du CDN à l’utilisateur. <br/>4. L'utilisateur initie une demande d'accès à l'URL du contenu au dispositif d'équilibrage de charge du CDN. <br/>5. Le dispositif d'équilibrage de charge CDN sélectionnera un serveur de cache approprié pour fournir des services aux utilisateurs. <br/>La base de sélection comprend : déterminer quel serveur est le plus proche de l'utilisateur en fonction de l'adresse IP de l'utilisateur ; déterminer quel serveur possède le contenu dont l'utilisateur a besoin en fonction du nom de contenu porté dans l'URL demandée par l'utilisateur qui interroge le contenu ; de chaque situation de charge du serveur, déterminez quel serveur a la charge la plus faible. <br/>Sur la base de l'analyse complète de ce qui précède, les paramètres d'équilibrage de charge renverront l'adresse IP du serveur de cache à l'utilisateur. <br/>6. L'utilisateur fait une requête au serveur de cache. <br/>7. Le serveur de cache répond aux demandes des utilisateurs et fournit le contenu requis par l'utilisateur. <br/>Si ce serveur de cache n'a pas le contenu souhaité par l'utilisateur et que le périphérique d'équilibrage de charge l'alloue toujours à l'utilisateur, alors ce serveur demandera le contenu à son serveur de cache de niveau supérieur jusqu'à ce qu'il soit retracé jusqu'au site Web Le serveur d'origine extrait le contenu localement. Résumé
12. équilibrage de charge nginx
13. Mise en cache (sept niveaux de description)
Répertoire
Le titre de cet article est "Une brève analyse du cache Web haute performance". Tout d'abord, il faut préciser que la "simple analyse" n'est pas modeste, mais vraiment une analyse "simple". En tant que jeune diplômé, je viens de lancer mon premier système formel en tant que programmeur une semaine avant d'écrire cet article. Tout le contenu de l'article provient de mes propres lectures et peut être différent de celui-ci. l'environnement de production réel. Si vous avez des questions, n'hésitez pas à m'éclairer. Tout d'abord, parlons brièvement de la mise en cache. L'idée de la mise en cache existe depuis longtemps. Il s'agit de sauvegarder les résultats de calculs qui prennent beaucoup de temps et de les utiliser directement en cas de besoin. l'avenir pour éviter des calculs répétés. Dans les systèmes informatiques, les applications de cache sont nombreuses, telles que la structure de stockage à trois niveaux de l'ordinateur et le cache dans les services Web. Cet article traite principalement de l'utilisation du cache dans l'environnement Web, notamment le cache du navigateur, le cache du serveur, le cache proxy inverse et le cache distribué. et d'autres aspects. 1. Mise en cache de contenu dynamique Les sites Web modernes fournissent un contenu plus dynamique, tel que des pages Web dynamiques, des images dynamiques, des services Web, etc. Ils sont généralement calculés côté serveur Web, génèrent HTML et retour. Dans le processus de génération de pages HTML, un grand nombre de calculs CPU et d'opérations d'E/S sont impliqués, tels que les calculs CPU et les E/S disque du serveur de base de données, ainsi que les E/S réseau pour la communication avec le serveur de base de données. Ces opérations prendront beaucoup de temps. Cependant, dans la plupart des cas, les résultats des pages Web dynamiques sont presque les mêmes lorsqu'elles sont demandées plusieurs fois. Vous pouvez alors envisager de supprimer cette partie du temps grâce à la mise en cache. 1.1 Cache de page Pour les pages Web dynamiques, nous mettons en cache le code HTML généré, appelé Page Cache. Pour d'autres contenus dynamiques tels que les images dynamiques et les données XML dynamiques, nous pouvons également mettre en cache leur contenu. résultats dans leur ensemble en utilisant la même stratégie. 1.1.1 Méthode de stockage
1.1.2 Contrôle d'expiration
1.1.3 Local sans cache
1.2 Contenu statique
2. Cache du navigateur
2.1 Implémentation
2.1.1 缓存协商
header("Last-Modified: " . gmdate("D, d M Y H:i:s") . " GMT");Last-Modified: Fri, 9 Dec 2014 23:23:23 GMT
If-Modified-Since: Fri, 9 Dec 2014 23:23:23 GMT
HTTP/1.1 304 Not Modified
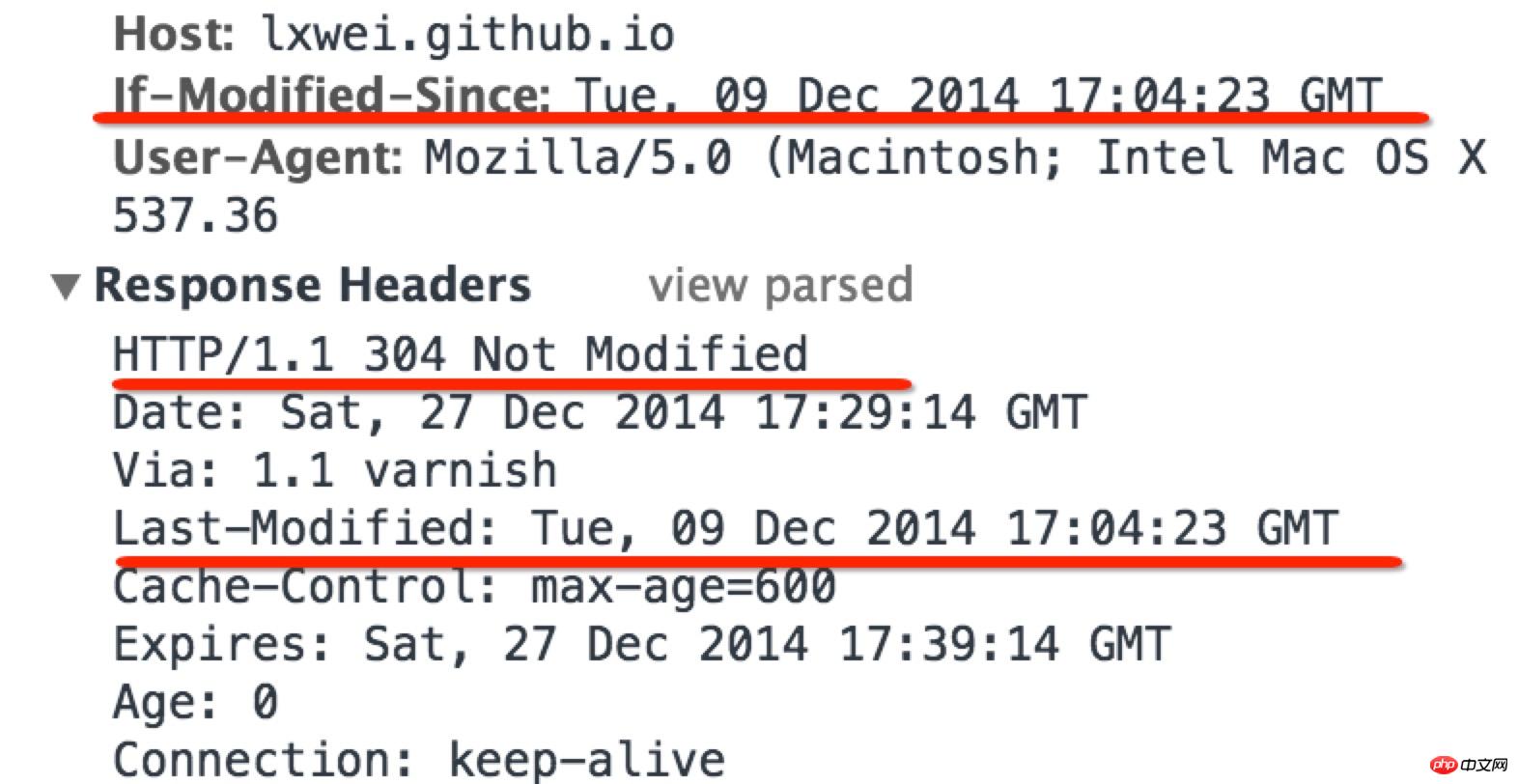
If-None-Match: "87665-c-090f0adfadf"
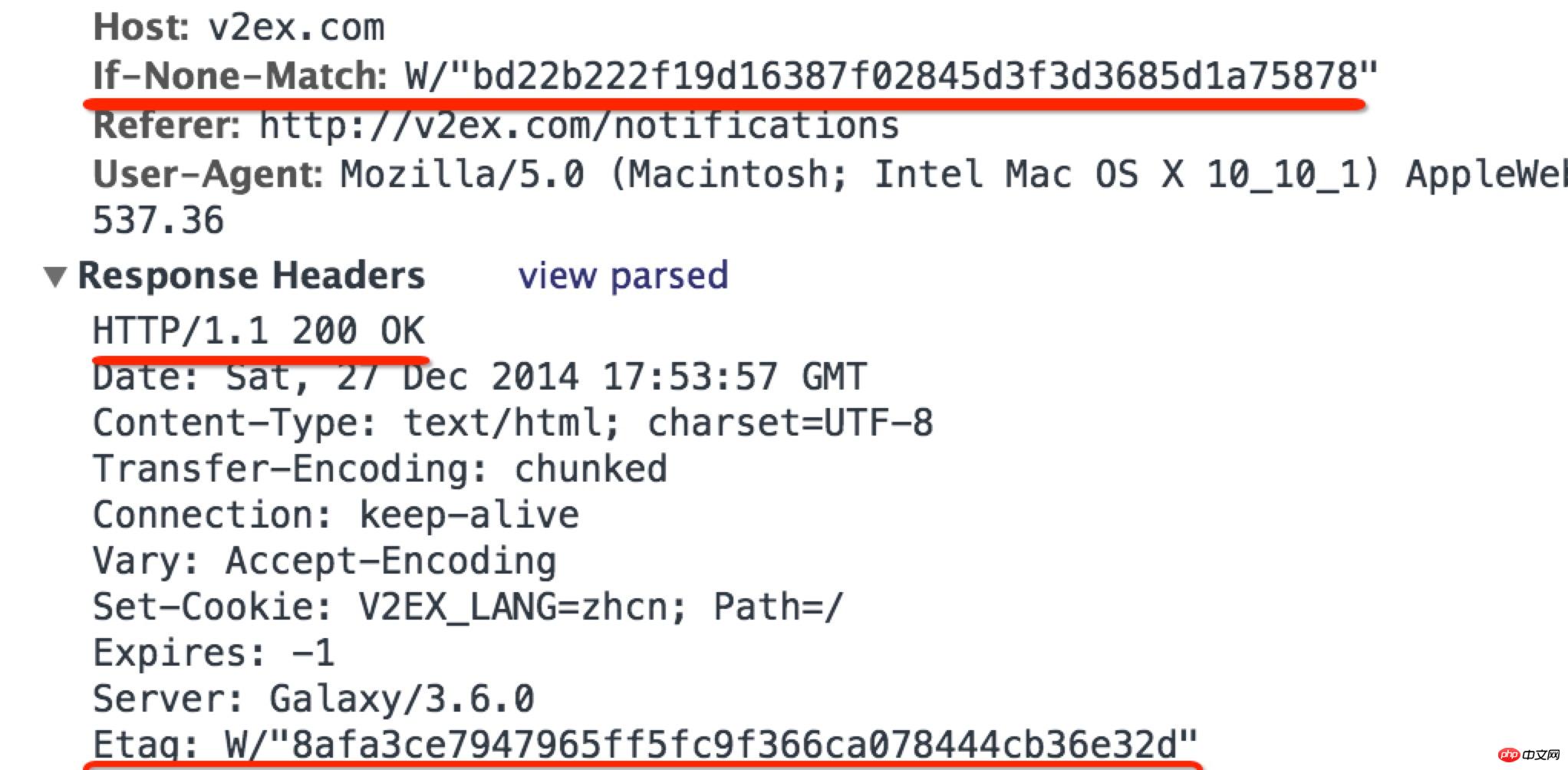
2.1.2 性能
2.2 彻底消灭请求
2.2.1 Expires 标记
Expires标记,告诉浏览器该内容何时过期,在内容过期前不需要再询问服务器,直接使用本地缓存即可。2.2.2 请求页面方式
Last-Modified Expires Ctrl + F5 无效 无效 F5 有效 无效 转到 有效 有效 2.2.3 适应过期时间
max-age 指定缓存过期的相对时间,单位是秒,相对时间指相对浏览器本地时间。目前,当 HTTP 响应中同时含有 Expires 和 Cache-Control 时,浏览器会优先使用 Cache-Control。2.3 总结
3. Web 服务器缓存
3.1 简介
Expires 标记,如果希望不缓存某个动态内容,那么最简单的办法就是使用:header("Expires: 0");Last-Modified来实现,具体方法不再叙述。3.2 取代动态内容缓存
3.3 缓存文件描述符
4. 反向代理缓存
4.1 反向代理简介
4.2 Cache proxy inverse
4.2.1 Modifier les règles de mise en cache
4.2.2 Vider le cache
5. Mise en cache distribuée
5.1 memcached
5.2 Cache de lecture et d'écriture
5.3 Surveillance du cache
5.4 Extension du cache
14. Détournement de contenu, statique cms
1.Pourquoi devrait-il être statique ? Les informations sont désynchronisées. Ce n'est qu'en régénérant la page HTML que les informations peuvent être synchronisées.
Article de référence : "Partage de plusieurs méthodes courantes de staticisation de page" La compréhension simple de PHP statique consiste à afficher les pages générées par le site Web devant les visiteurs sous forme de HTML statique. PHP static est divisé en
statique pur Grands sites Web (trafic élevé, concurrence élevée), si s'il s'agit d'un site Web statique, vous pouvez étendre suffisamment de serveurs Web pour prendre en charge un accès simultané à très grande échelle.
La raison pour laquelle les grands sites Web statiques peuvent répondre rapidement et avec une concurrence élevée est qu'ils
font de leur mieux pour js, css, img et autres ressources, le serveur fusionne et renvoie
Pages statiques15. spirit css Est-ce que plus c'est gros, mieux c'est ?
Quand utiliser : commençons par le principe. Lorsque notre volume de requêtes est particulièrement important et que les données de la requête sont petites, nous pouvons regrouper plusieurs petites images en une seule grande image et y parvenir grâce à positionnement ; Si le graphique est relativement grand, vous devez utiliser la découpe de graphique pour réduire les ressources ; de cette manière, plusieurs requêtes sont fusionnées en une seule, consommant moins de ressources réseau et optimisant l'accès frontal. <br/>

<p>
<p>
<b class="N1 n10"></b>
<em class="First small_up1"></em>
<span class="A1 up1"></span>
<span class="A2 up1"></span>
<span class="A3 down1"></span>
<span class="A4 down1"></span>
<span class="B1 up1"></span>
<span class="B2 down1"></span>
<span class="C1 up1"></span>
<span class="C2 up1"></span>
<span class="C3 down1"></span>
<span class="C4 down1"></span>
<em class="Last small_down1"></em>
<b class="N2 n10_h"></b>
</p>
</p>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>制作一幅扑克牌--黑桃10</title>
<style type="text/css"><!--
.card{width:125px;height:170px; position:absolute;overflow:hidden;border:1px #c0c0c0 solid;}
/*中间图片通用设置*/
span{display:block;width:20px;height:21px; position:absolute;background:url(http://www.blueidea.com//articleimg/2009/02/6382/00.gif) no-repeat;}
/*小图片通用设置*/
b{display:block;width:15px;height:10px; position:absolute;font-size:10pt;text-align:center;font-weight:bold;background:url(http://www.blueidea.com//articleimg/2009/02/6382/00.gif) no-repeat; overflow:hidden;}
/*数字通用设置*/
em{display:block;width:15px;height:10px; position:absolute;font-size:10pt;text-align:center;font-weight:bold;background:url(http://www.blueidea.com//articleimg/2009/02/6382/00.gif) no-repeat;overflow:hidden;}
/*各坐标点位置*/
.N1{left:1px;top:8px;}
.First{left:5px;top:20px;}
.A1{left:20px;top:20px;}
.A2{left:20px;top:57px;}
.A3{left:20px;top:94px;}
.A4{left:20px;top:131px;}
.B1{left:54px;top:38px;}
.B2{left:54px;top:117px;}
.C1{left:86px;top:20px;}
.C2{left:86px;top:57px;}
.C3{left:86px;top:94px;}
.C4{left:86px;top:131px;}
.Last{bottom:20px;right:0px;}
.N2{bottom:8px;right:5px;
}
/*大图标黑红梅方四种图片-上方向*/
.up1{background-position:0 1px;}/*黑桃*/
/*大图标黑红梅方四种图片-下方向*/
.down1{background-position:0 -19px;}/*黑桃*/
/*小图标黑红梅方四种图片-上方向*/
.small_up1{background-position:0 -40px;}/*黑桃*/
/*小图标黑红梅方四种图片-下方向*/
.small_down1{background-position:0 -51px;}/*黑桃*/
/*A~k数字图片-左上角*/
.n10{background-position:-191px 0px;left:-4px;width:21px;}
/*A~k数字图片-右下角*/
.n10_h{background-position:-191px -22px;right:3px;width:21px;}
/*A~k数字图片-左上角红色字*/
.n10_red{background-position:-191px 0px;}
/*A~k数字图片-右下角红色字*/
.n10_h_red{background-position:-191px -33px;}
-->
</style>
</head>
<body>
<!--10字符-->
<p>
<p>
<b class="N1 n10"></b>
<em class="First small_up1"></em>
<span class="A1 up1"></span>
<span class="A2 up1"></span>
<span class="A3 down1"></span>
<span class="A4 down1"></span>
<span class="B1 up1"></span>
<span class="B2 down1"></span>
<span class="C1 up1"></span>
<span class="C2 up1"></span>
<span class="C3 down1"></span>
<span class="C4 down1"></span>
<em class="Last small_down1"></em>
<b class="N2 n10_h"></b>
</p>
</p>
</body>
</html>16. 反向代理/正向代理
正向代理与反向代理【总结】

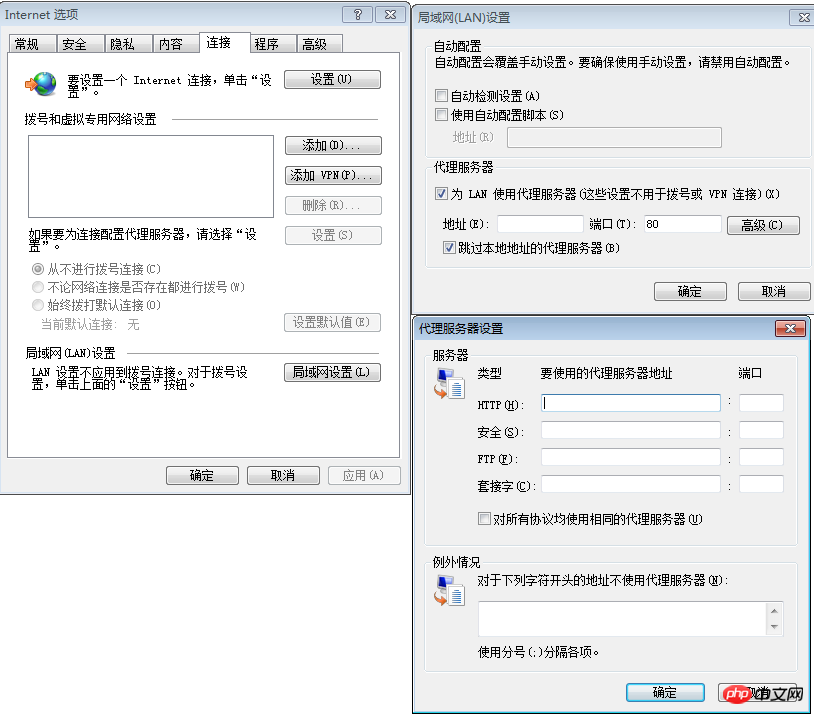

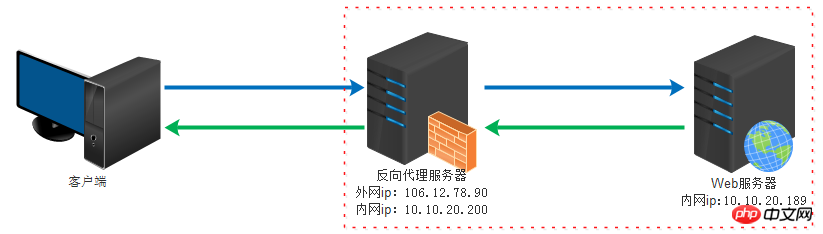
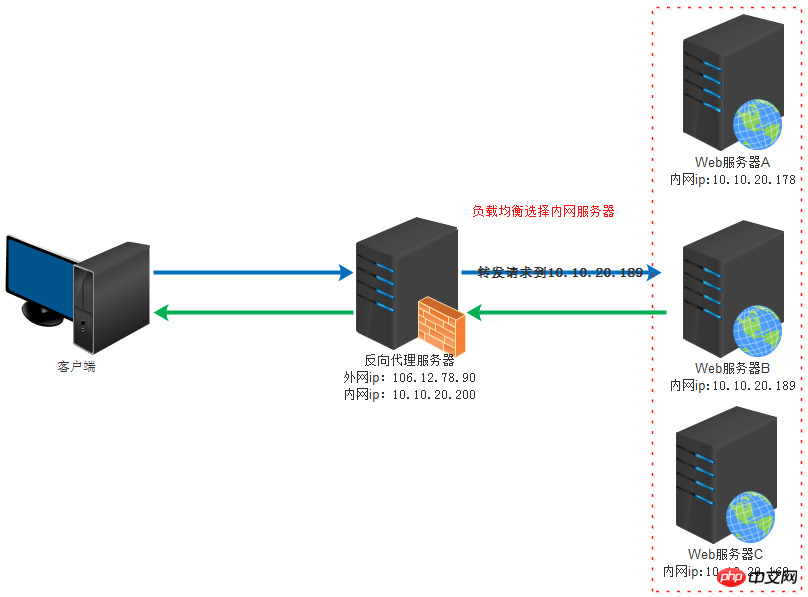 4. La différence entre les deux
4. La différence entre les deux 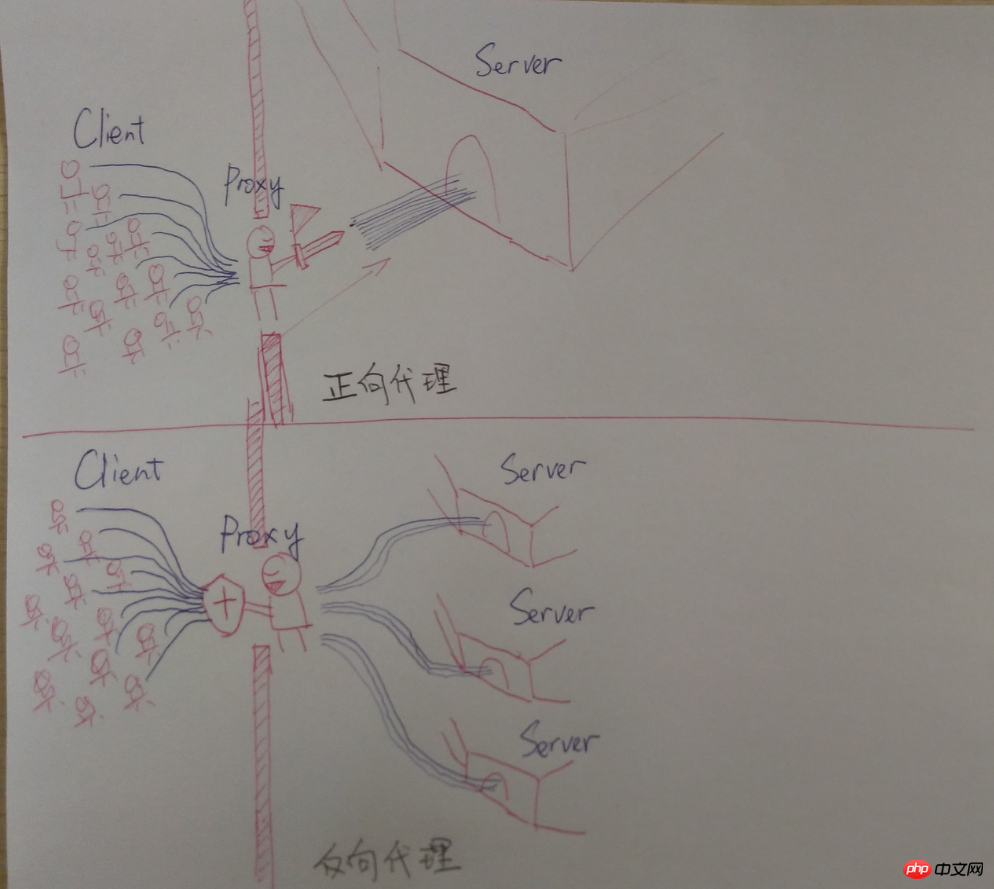
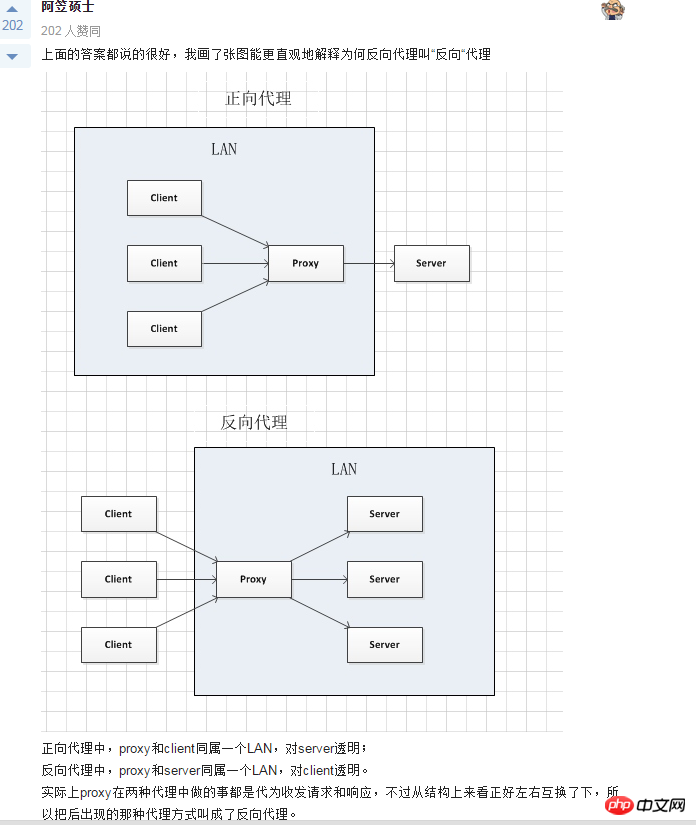 5. Proxy inverse nginx
5. Proxy inverse nginx 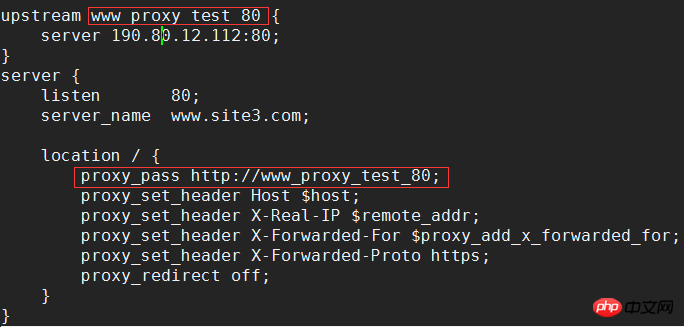
Proxy de transfert
Le client envoie un message normal à la demande de proxy inverse, puis le proxy inverse transférera la demande au serveur d'origine et renverra le contenu obtenu au client, comme si le contenu. était à l'origine le sien.
met en cache les données du serveur d'origine pour réduire la pression d'accès du serveur d'origine. 🎜>
Proxy transparentLa différence entre le proxy direct et le proxy inverse
ObjectifProcureur direct L'utilisation typique consiste à fournir un accès à Internet aux clients LAN à l'intérieur du pare-feu.
Utilisez les fonctionnalités de mise en mémoire tampon pour réduire l'utilisation du réseau.
Proxy inverse
Sécurité
Proxy inverséIl est transparent pour le monde extérieur et les visiteurs ne savent pas qu'ils visitent un proxy.
La différence entre le proxy inverse et le CDNEn termes simples, CDN est une
, et le proxy inverse est technologie qui transmet les requêtes des utilisateurs au serveur backend.
17. Optimisation maître-esclave mysql
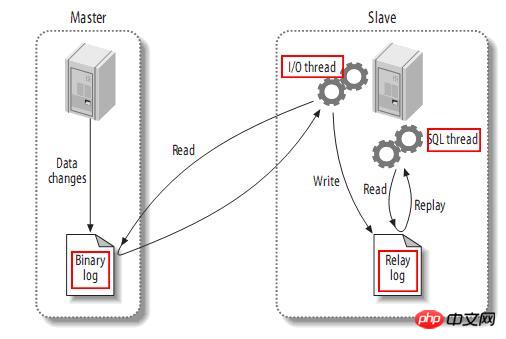
18. sécurité Web
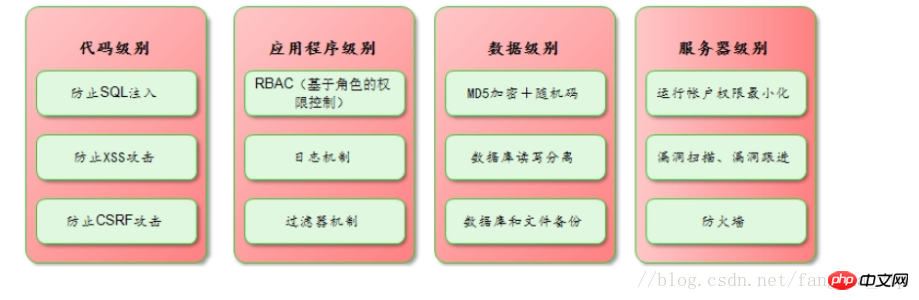 <br/>
<br/>20. La différence entre memcached et redis
21. La différence entre Apache et Nginx
1. Définition :
1. Le serveur Apache
Mêmes points :
2. Comparaison entre Nginx et Apache
1) nginx par rapport à Avantages d'Apache
Apacheapache par rapport à > réécrire est plus puissant que nginx
Complexe
Port, processus1. Utilisez lsof
lsof -i:port number pour vérifier si un port est occupé  <br/><br/><br/>Pour plus d'informations, vous pouvez cliquer ici : http://www.findme.wang/blog/detail/id/1.html
<br/><br/><br/>Pour plus d'informations, vous pouvez cliquer ici : http://www.findme.wang/blog/detail/id/1.html
23. 性能优化
分布式缓存
缓存的基本原理
缓存是指将数据存储在相对较高访问速度的存储介质中。
(1)访问速度快,减少数据访问时间;
(2)如果缓存的数据进过计算处理得到的,那么被缓存的数据无需重复计算即可直接使用。
缓存的本质是一个内存Hash表,以一对Key、Value的形式存储在内存Hash表中,读写时间复杂度为O(1)。
合理使用缓存
不合理使用缓存非但不能提高系统的性能,还会成为系统的累赘,甚至风险。
频繁修改的数据
如果缓存中保存的是频繁修改的数据,就会出现数据写入缓存后,应用还来不及读取缓存,数据就已经失效,徒增系统负担。一般来说,数据的读写比在2:1以上,缓存才有意义。
没有热点的访问
如果应用系统访问数据没有热点,不遵循二八定律,那么缓存就没有意义。
数据不一致与脏读
一般会对缓存的数据设置失效时间,一旦超过失效时间,就要从数据库中重新加载。因此要容忍一定时间的数据不一致,如卖家已经编辑了商品属性,但是需要过一段时间才能被买家看到。还有一种策略是数据更新立即更新缓存,不过这也会带来更多系统开销和事务一致性问题。
缓存可用性
缓存会承担大部分数据库访问压力,数据库已经习惯了有缓存的日子,所以当缓存服务崩溃时,数据库会因为完全不能承受如此大压力而宕机,导致网站不可用。
这种情况被称作缓存雪崩,发生这种故障,甚至不能简单地重启缓存服务器和数据库服务器来恢复。
实践中,有的网站通过缓存热备份等手段提高缓存可用性:当某台缓存服务器宕机时,将缓存访问切换到热备服务器上。
但这种设计有违缓存的初衷,**缓存根本就不应该当做一个可靠的数据源来使用**。
通过分布式缓存服务器集群,将缓存数据分布到集群多台服务器上可在一定程度上改善缓存的可用性。
当一台缓存服务器宕机时,只有部分缓存数据丢失,重新从数据库加载这部分数据不会产生很大的影响。
缓存预热
缓存中的热点数据利用LRU(最近最久未用算法)对不断访问的数据筛选淘汰出来,这个过程需要花费较长的时间。
那么最好在缓存系统启动时就把热点数据加载好,这个缓存预加载手段叫缓存预热。
缓存穿透
如果因为不恰当的业务、或者恶意攻击持续高并发地请求某个不存在的数据,由于缓存没有保存该数据,所有的请求都会落到数据库上,会对数据库造成压力,甚至崩溃。
**一个简单的对策是将不存在的数据也缓存起来(其value为null)** 。分布式缓存架构
分布式缓存指缓存部署在多个服务器组成的集群中,以集群方式提供缓存服务,其架构方式有两种,一种是以JBoss Cache为代表的需要更新同步的分布式缓存,一种是以Memcached为代表的不互相通信的分布式缓存。 JBoss Cache在集群中所有服务器中保存相同的缓存数据,当某台服务器有缓存数据更新,就会通知其他机器更新或清除缓存数据。 它通常将应用程序和缓存部署在同一台服务器上,但受限于单一服务器的内存空间;当集群规模较大的时候,缓存更新需要同步到所有机器,代价惊人。因此这种方案多见于企业应用系统中。 Memcached采用一种集中式的缓存集群管理(互不通信的分布式架构方式)。缓存与应用分离部署,缓存系统部署在一组专门的服务器上,应用程序通过一致性Hash等路由算法选择缓存服务器远程访问数据,缓存服务器之间不通信,集群规模可以很容易地实现扩容,具有良好的伸缩性。 (1)简单的通信协议。Memcached使用TCP协议(UDP也支持)通信; (2)丰富的客户端程序。 (3)高性能的网络通信。Memcached服务端通信模块基于Libevent,一个支持事件触发的网络通信程序库,具有稳定的长连接。 (4)高效的内存管理。 (5)互不通信的服务器集群架构。
异步操作
使用消息队列将调用异步化(生产者--消费者模式),可改善网站的扩展性,还可以改善系统的性能。
在不使用消息队列的情况下,用户的请求数据直接写入数据库,在高并发的情况下,会对数据库造成巨大压力,使得响应延迟加剧。
在使用消息队列后,用户请求的数据发送给消息队列后立即返回,再由消息队列的消费者进程(通常情况下,该进程独立部署在专门的服务器集群上)从消息队列中获取数据,
异步写入数据库。由于消息队列服务器处理速度远快于服务器(消息队列服务器也比数据库具有更好的伸缩性)。
消息队列具有很好的削峰作用--通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。
需要注意的是,由于数据写入消息队列后立即返回给用户,数据在后续的业务校验、写数据库等操作可能失败,因此在使用消息队列进行业务异步处理后,
需要适当修改业务流程进行配合,如订单提交后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完后,
甚至商品出库后,再通过电子邮件或SMS消息通知用户订单成功,以免交易纠纷。
使用集群
在网站高并发访问的场景下,使用负载均衡技术为一个应用构建一个由多台服务器组成的服务器集群,将并发访问请求分发到多台服务器上处理。
代码优化
多线程
从资源利用的角度看,使用多线程的原因主要有两个:IO阻塞与多CPU。
当前线程进行IO处理的时候,会被阻塞释放CPU以等待IO操作完成,由于IO操作(不管是磁盘IO还是网络IO)通常都需要较长的时间,这时CPU可以调度其他的线程进行处理。
理想的系统Load是既没有进程(线程)等待也没有CPU空闲,利用多线程IO阻塞与执行交替进行,可最大限度利用CPU资源。
使用多线程的另一个原因是服务器有多个CPU。
简化启动线程估算公式:
启动线程数 = [任务执行时间 / (任务执行时间 - IO等待时间)]*CPU内核数 多线程编程一个需要注意的问题是线程安全问题,即多线程并发对某个资源进行修改,导致数据混乱。
所有的资源---对象、内存、文件、数据库,乃至另一个线程都可能被多线程并发访问。
编程上,解决线程安全的主要手段有:
(1)将对象设计为无状态对象。
所谓无状态对象是指对象本身不存储状态信息(对象无成员变量,或者成员变量也是无状态对象),不过从面向对象设计的角度看,无状态对象是一种不良设计。
(2)使用局部对象。
即在方法内部创建对象,这些对象会被每个进入该方法的线程创建,除非程序有意识地将这些对象传递给其他线程,否则不会出现对象被多线程并发访问的情形。
(3)并发访问资源时使用锁。
即多线程访问资源的时候,通过锁的方式使多线程并发操作转化为顺序操作,从而避免资源被并发修改。
资源复用
1系统运行时,要尽量减少那些开销很大的系统资源的创建和销毁,比如数据库连接、网络通信连接、线程、复杂对象等。
2从编程角度,资源复用主要有两种模式:单例(Singleton)和对象池(Object Pool)。
3单例虽然是GoF经典设计模式中较多被诟病的一个模式,但由于目前Web开发中主要使用贫血模式,从Service到Dao都是些无状态对象,无需重复创建,使用单例模式也就自然而然了。
4对象池模式通过复用对象实例,减少对象创建和资源消耗。
5对于数据库连接对象,每次创建连接,数据库服务端都需要创建专门的资源以应对,因此频繁创建关闭数据库连接,对数据库服务器是灾难性的,
同时频繁创建关闭连接也需要花费较长的时间。
6因此实践中,应用程序的数据库连接基本都使用连接池(Connection Pool)的方式,数据库连接对象创建好以后,
将连接对象放入对象池容器中,应用程序要连接的时候,就从对象池中获取一个空闲的连接使用,使用完毕再将该对象归还到对象池中即可,不需要创建新的连接。
数据结构
早期关于程序的一个定义是,程序就是数据结构+算法,数据结构对于编程的重要性不言而喻。
在不同场景中合理使用数据结构,灵活组合各种数据结构改善数据读写和计算特性可极大优化程序的性能。
垃圾回收
理解垃圾回收机制有助于程序优化和参数调优,以及编写内存安全的代码。
24. 支付
手机网站支付接口
产品简介
申请条件
配置
查看PID

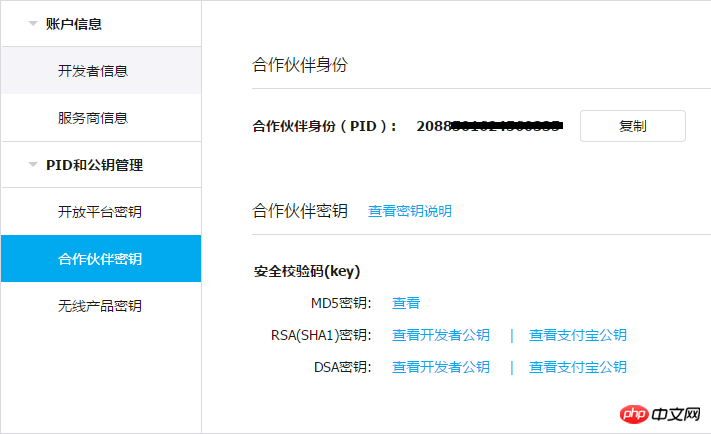
配置密钥
应用环境
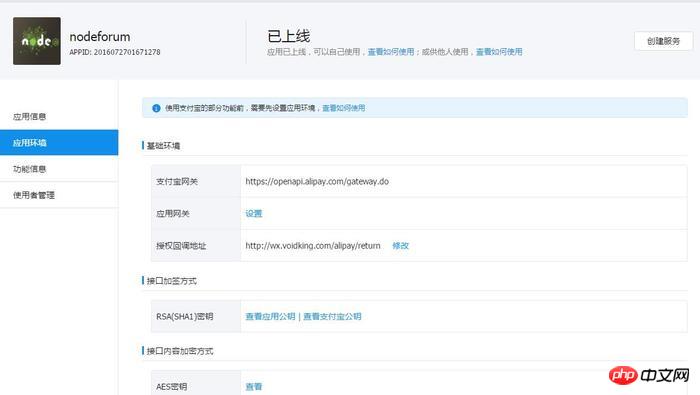 <br/>
<br/>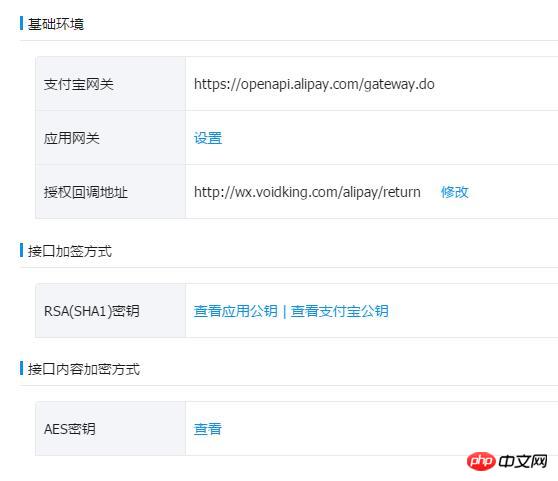 <br/>上图是我的应用配置选项,公司账号也许会有所不同。具体哪些参数需要配置?请参照接口参数说明,需要什么就配置什么。
<br/>上图是我的应用配置选项,公司账号也许会有所不同。具体哪些参数需要配置?请参照接口参数说明,需要什么就配置什么。交互
Node端发起支付请求
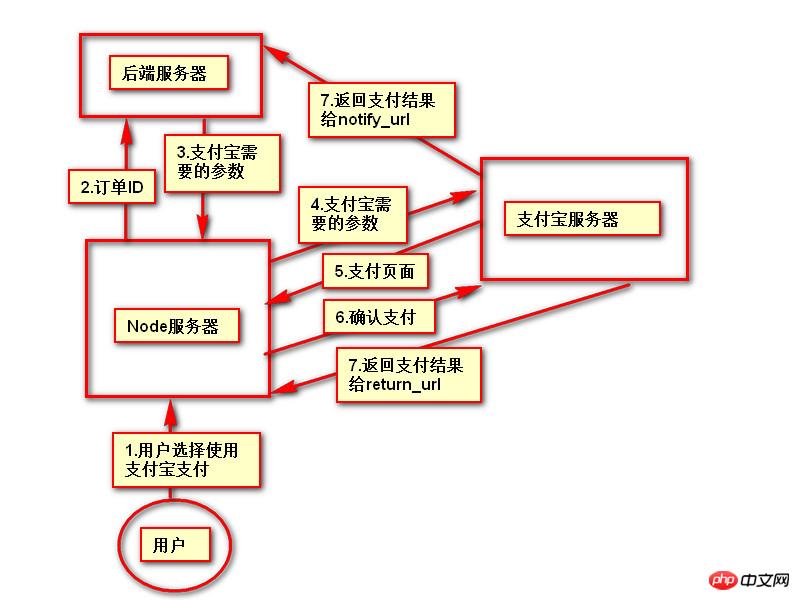 <br/>我们公司采用的,就是这种方式,步骤3中Node端获取到的支付宝参数,包括sign。其实,sign的计算工作也可以放在Node端,只不过支付宝没有给出Node的demo,实现起来需要耗费多一点时间。
<br/>我们公司采用的,就是这种方式,步骤3中Node端获取到的支付宝参数,包括sign。其实,sign的计算工作也可以放在Node端,只不过支付宝没有给出Node的demo,实现起来需要耗费多一点时间。后端发起支付请求
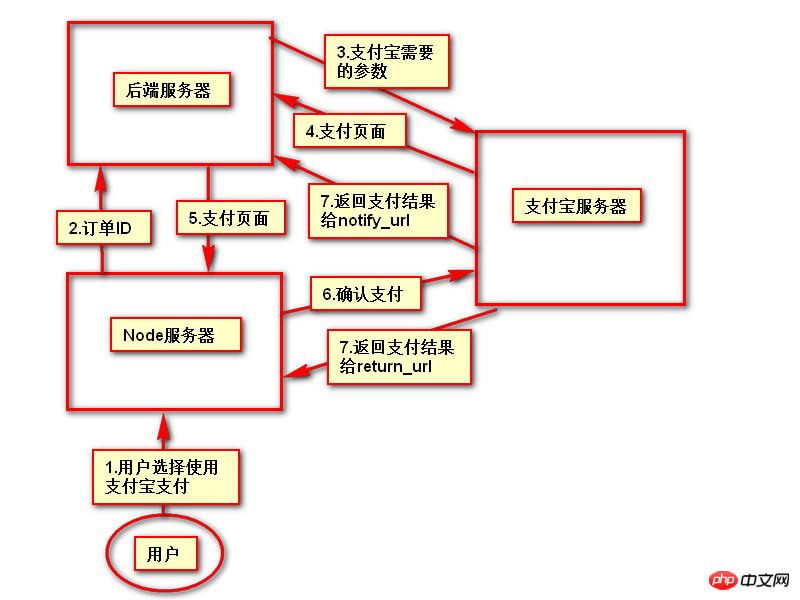 <br/>这种方式也很好,而且,步骤4中后端获取到支付页面,也可以不传给Node端,自己显示出来。这样,整个流程就更加简单。
<br/>这种方式也很好,而且,步骤4中后端获取到支付页面,也可以不传给Node端,自己显示出来。这样,整个流程就更加简单。return_url和notify_url
Node端详解
request发起请求
// 通过orderId向后端请求获取支付宝支付参数alidata var alipayUrl = 'https://mapi.alipay.com/gateway.do?'+ alidata; request.get({url: alipayUrl},function(error, response, body){ res.send(response.body); });
request.get({url: alipayUrl},function(error, response, body){
var str = response2.body;
str = str.replace(/gb2312/, "utf-8");
res.setHeader('content-type', 'text/html;charset=utf-8');
res.send(str);
});表单提交请求
Node端
// node端 // 通过orderId向后端请求获取支付宝支付参数alidata function getArg(str,arg) { var reg = new RegExp('(^|&)' + arg + '=([^&]*)(&|$)', 'i'); var r = str.match(reg); if (r != null) { return unescape(r[2]); } return null; } var alipayParam = { _input_charset: getArg(alidata,'_input_charset'), body: getArg(alidata,'body'), it_b_pay: getArg(alidata, 'it_b_pay'), notify_url: getArg(alidata, 'notify_url'), out_trade_no: getArg(alidata, 'out_trade_no'), partner: getArg(alidata, 'partner'), payment_type: getArg(alidata, 'payment_type'), return_url: getArg(alidata, 'return_url'), seller_id: getArg(alidata, 'seller_id'), service: getArg(alidata, 'service'), show_url: getArg(alidata, 'show_url'), subject: getArg(alidata, 'subject'), total_fee: getArg(alidata, 'total_fee'), sign_type: getArg(alidata, 'sign_type'), sign: getArg(alidata, 'sign'), app_pay: getArg(alidata, 'app_pay') }; res.render('artist/alipay',{ // 其他参数 alipayParam: alipayParam });html
<!--alipay.html-->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>支付宝支付</title> </head> <body>
<form id="ali-form" action="https://mapi.alipay.com/gateway.do" method="get">
<input type="hidden" name="_input_charset" value="<%= alipayParam._input_charset%>">
<input type="hidden" name="body" value="<%= alipayParam.body%>">
<input type="hidden" name="it_b_pay" value="<%= alipayParam.it_b_pay%>">
<input type="hidden" name="notify_url" value="<%= alipayParam.notify_url%>">
<input type="hidden" name="out_trade_no" value="<%= alipayParam.out_trade_no%>">
<input type="hidden" name="partner" value="<%= alipayParam.partner%>">
<input type="hidden" name="payment_type" value="<%= alipayParam.payment_type%>">
<input type="hidden" name="return_url" value="<%= alipayParam.return_url%>">
<input type="hidden" name="seller_id" value="<%= alipayParam.seller_id%>">
<input type="hidden" name="service" value="<%= alipayParam.service%>">
<input type="hidden" name="show_url" value="<%= alipayParam.show_url%>">
<input type="hidden" name="subject" value="<%= alipayParam.subject%>">
<input type="hidden" name="total_fee" value="<%= alipayParam.total_fee%>">
<input type="hidden" name="sign_type" value="<%= alipayParam.sign_type%>">
<input type="hidden" name="sign" value="<%= alipayParam.sign%>">
<input type="hidden" name="app_pay" value="<%= alipayParam.app_pay%>">
</form> <% include ../bootstrap.html %> <script type="text/javascript" src="<%= dist %>/js/business-modules/artist/alipay.js?v=2016052401"></script>
</body>
</html>
js
// alipay.js seajs.use(['zepto'],function($){
var index = {
init:function(){
var self = this;
this.bindEvent();
},
bindEvent:function(){
var self = this;
$('#ali-form').submit();
}
}
index.init();
});小结
 <br/>选择支付宝支付后,成功跳转到了支付宝支付页面,nice!看来这种方案很靠谱。
<br/>选择支付宝支付后,成功跳转到了支付宝支付页面,nice!看来这种方案很靠谱。错误排查
 <br/>值得点赞的是,支付宝给的错误代码很明确,一看就懂。上面这个错误,签名不对。因为我给alipayParam私自加了个app_pay属性,没有经过签名。
<br/>值得点赞的是,支付宝给的错误代码很明确,一看就懂。上面这个错误,签名不对。因为我给alipayParam私自加了个app_pay属性,没有经过签名。微信屏蔽支付宝
问题描述

完美解决办法
Node端
res.render('artist/alipay',{ alipayParam: alipayParam, param: urlencode(alidata) });html
<input type="hidden" id="param" value="<%= param%>"> <iframe id="payFrame" name="mainIframe" src="" frameborder="0" scrolling="auto" ></iframe>
js
var iframe = document.getElementById('payFrame'); var param = $('#param').val(); iframe.src='https://mapi.alipay.com/gateway.do?'+param;
报错
官方解决办法
html
<!--alipay.html--> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>支付宝支付</title> </head> <body> <form id="ali-form" action="https://mapi.alipay.com/gateway.do" method="get"> <input type="hidden" name="_input_charset" value="<%= alipayParam._input_charset%>"> <input type="hidden" name="body" value="<%= alipayParam.body%>"> <input type="hidden" name="it_b_pay" value="<%= alipayParam.it_b_pay%>"> <input type="hidden" name="notify_url" value="<%= alipayParam.notify_url%>"> <input type="hidden" name="out_trade_no" value="<%= alipayParam.out_trade_no%>"> <input type="hidden" name="partner" value="<%= alipayParam.partner%>"> <input type="hidden" name="payment_type" value="<%= alipayParam.payment_type%>"> <input type="hidden" name="return_url" value="<%= alipayParam.return_url%>"> <input type="hidden" name="seller_id" value="<%= alipayParam.seller_id%>"> <input type="hidden" name="service" value="<%= alipayParam.service%>"> <input type="hidden" name="show_url" value="<%= alipayParam.show_url%>"> <input type="hidden" name="subject" value="<%= alipayParam.subject%>"> <input type="hidden" name="total_fee" value="<%= alipayParam.total_fee%>"> <input type="hidden" name="sign_type" value="<%= alipayParam.sign_type%>"> <input type="hidden" name="sign" value="<%= alipayParam.sign%>"> <p class="wrapper buy-wrapper" style="max-width:90%"> <a href="javascript:void(0);" class="J-btn-submit btn mj-submit btn-strong btn-larger btn-block">确认支付</a> </p> </form> <input type="hidden" id="param" value="<%= param%>"> <% include ../bootstrap.html %> <script type="text/javascript" src="<%= dist %>/js/business-modules/artist/ap.js"></script> <script> var btn = document.querySelector(".J-btn-submit"); btn.addEventListener("click", function (e) { e.preventDefault(); e.stopPropagation(); e.stopImmediatePropagation(); var queryParam = ''; Array.prototype.slice.call(document.querySelectorAll("input[type=hidden]")).forEach(function (ele) { queryParam += ele.name + "=" + encodeURIComponent(ele.value) + '&'; }); var gotoUrl = document.querySelector("#ali-form").getAttribute('action') + '?' + queryParam; _AP.pay(gotoUrl); return false; }, false); btn.click(); </script> </body> </html>
后记
Signet
25. Concurrence élevée, trafic important
<br/>
26. La différence entre mysql et nosql
NoSQL ou base de données relationnelle
27. Servitisation de la structure backend
Aperçu
Modèle de données :
Classification des données
Données semi-structurées
Données structurées
Données non structurées
Données semi-structurées
储存方式
化解为结构化数据
用XML格式来组织并保存到CLOB字段中
28. 单链表翻转
单链表反转总结篇
1 定义
class ListNode {
int val;
ListNode next;
ListNode(int x) {
val = x;
next = null;
}
}2 方法1:就地反转法
2.1 思路
2.2 解释
1初始状态
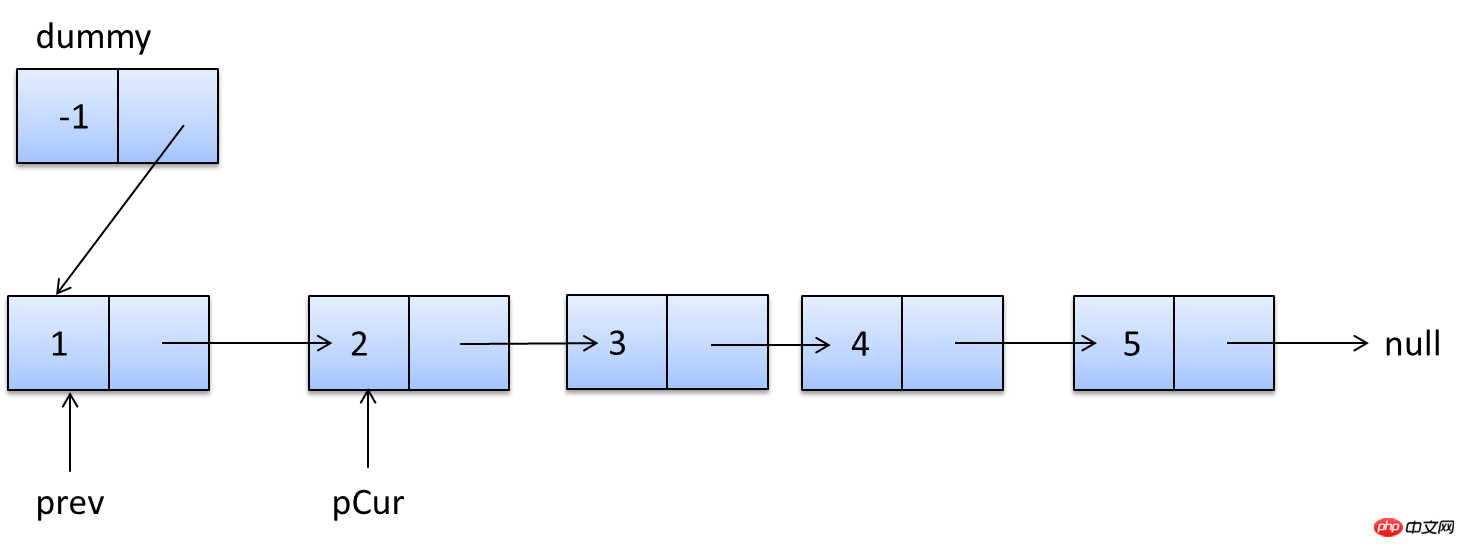
2 过程
1 prev.next = pCur.next;
2 pCur.next = dummy.next;
3 dummy.next = pCur;
4 pCur = prev.next;
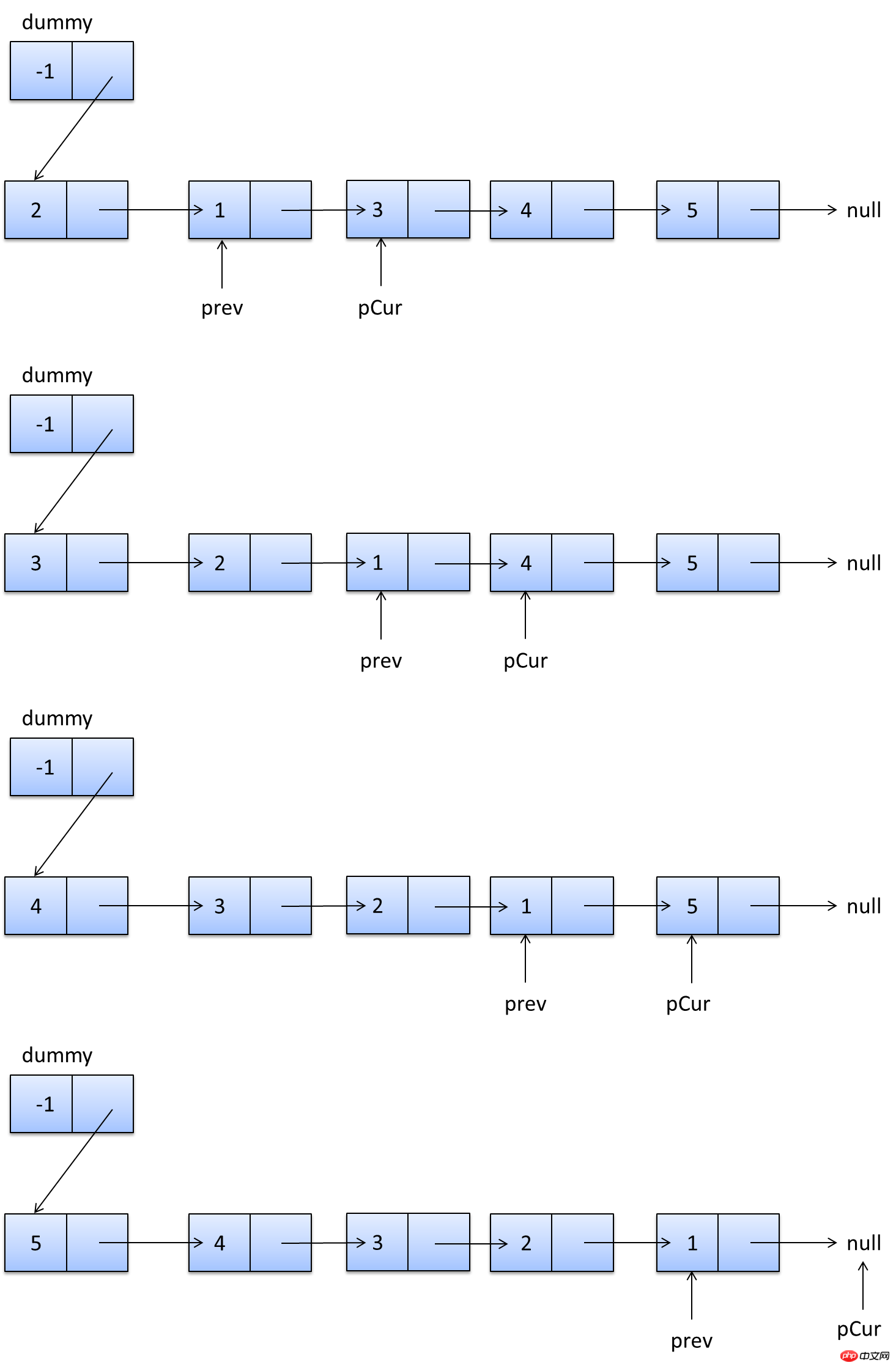
3 循环条件
pCur is not null
2.3 代码
1 // 1.就地反转法
2 public ListNode reverseList1(ListNode head) {
3 if (head == null)
4 return head;
5 ListNode dummy = new ListNode(-1);
6 dummy.next = head;
7 ListNode prev = dummy.next;
8 ListNode pCur = prev.next;
9 while (pCur != null) {
10 prev.next = pCur.next;
11 pCur.next = dummy.next;
12 dummy.next = pCur;
13 pCur = prev.next;
14 }
15 return dummy.next;
16 }2.4 总结
3 方法2:新建链表,头节点插入法
3.1 思路
3.2 解释
1 初始状态
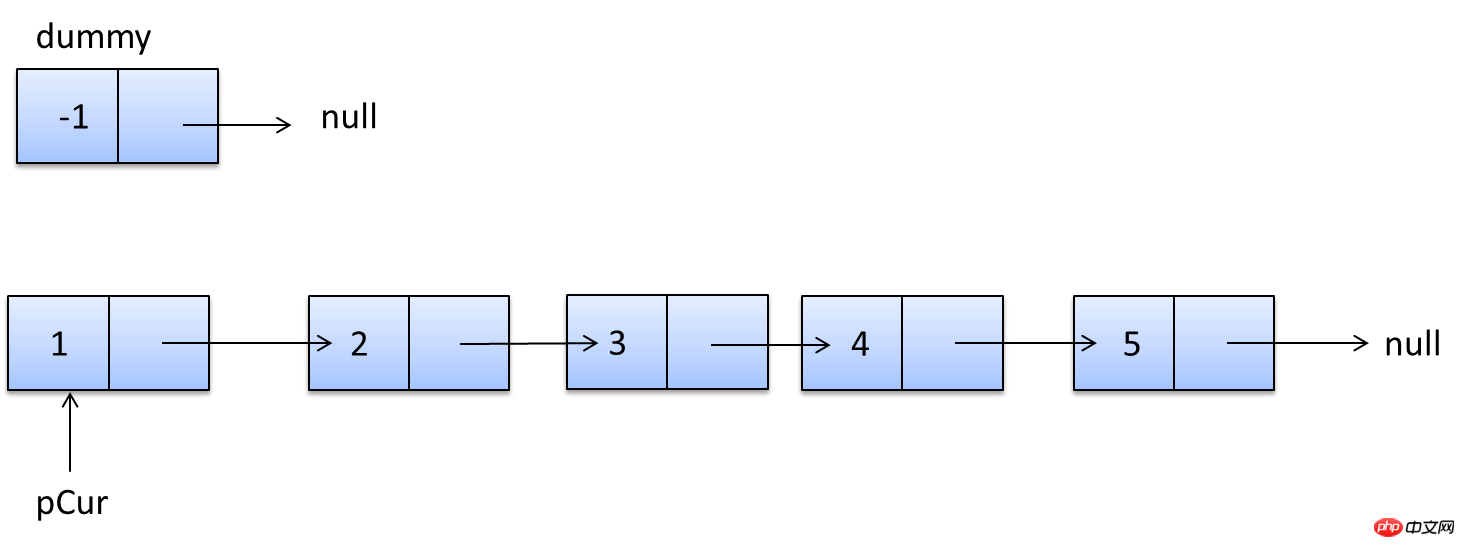
2 过程
1 pNex = pCur.next
2 pCur.next = dummy.next
3 dummy.next = pCur
4 pCur = pNex
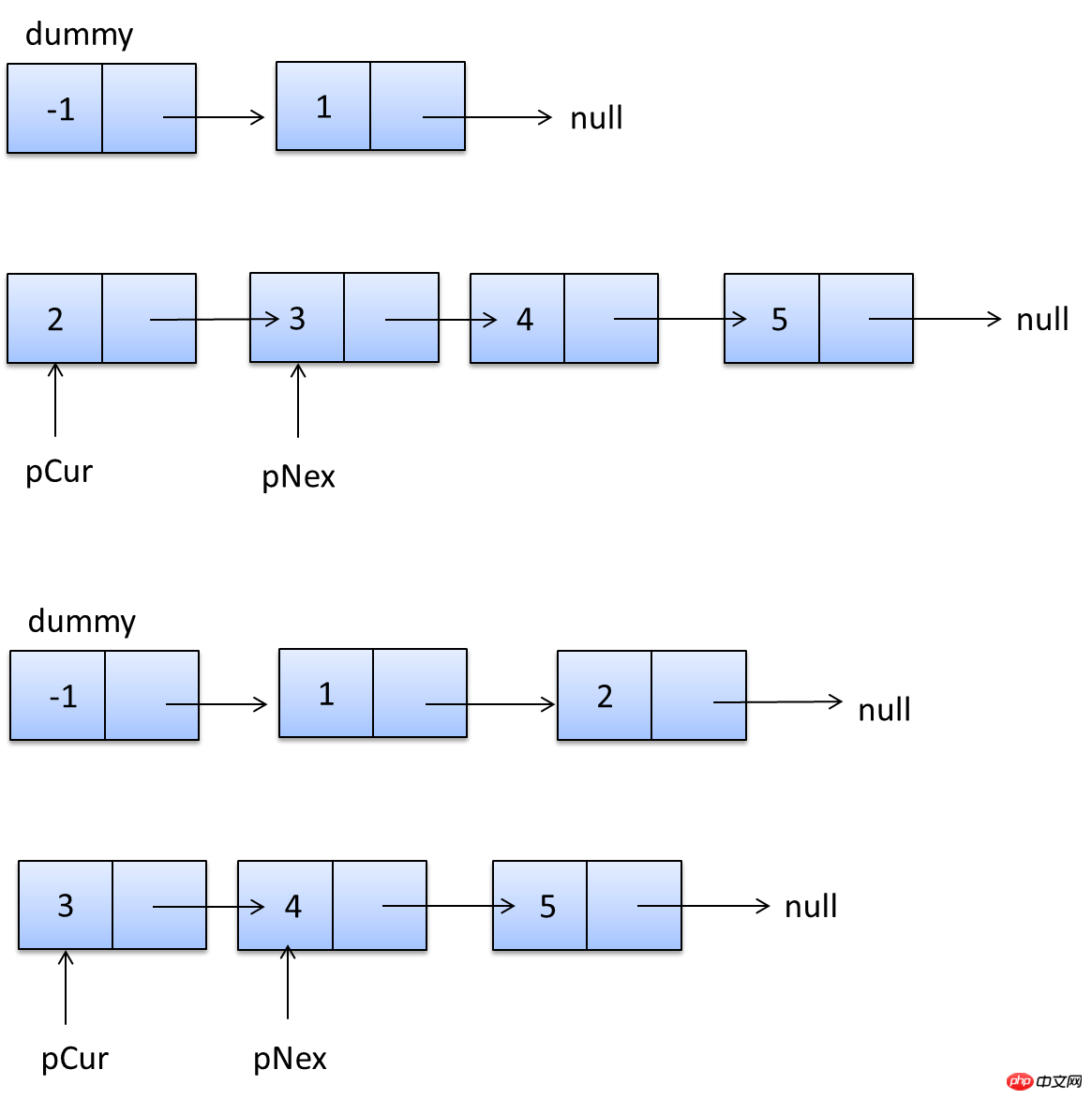
3 循环条件
pCur is not null
3.3 代码
1 // 2.新建链表,头节点插入法
2 public ListNode reverseList2(ListNode head) {
3 ListNode dummy = new ListNode(-1);
4 ListNode pCur = head;
5 while (pCur != null) {
6 ListNode pNex = pCur.next;
7 pCur.next = dummy.next;
8 dummy.next = pCur;
9 pCur = pNex;
10 }
11 return dummy.next;
12 }<br/>29. 最擅长的php
30. 索引
MySQL索引优化
一、索引类型
CREATE TABLE index_table (
id BIGINT NOT NULL auto_increment COMMENT '主键',
NAME VARCHAR (10) COMMENT '姓名',
age INT COMMENT '年龄',
phoneNum CHAR (11) COMMENT '手机号',
PRIMARY KEY (id) ) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
下图是Col2为索引列,记录与B树结构的对应图,仅供参考:
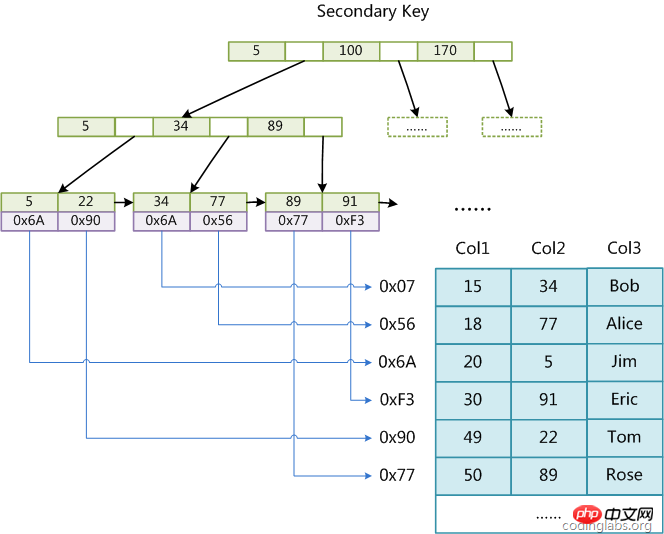
1、普通索引
------直接创建索引 create index index_name on index_table(name);
2、唯一索引
---------直接创建唯一索引 create UNIQUE index index_phoneNum on index_table(phoneNum);
3、主键
4、多列索引
-------直接创建组合索引 create index index_union on index_table(name,age,phoneNum);
二、索引优化
1、选择索引列
SELECT age----不使用索引 FROM index_union WHERE NAME = 'xiaoming'---考虑使用索引 AND phoneNum = '18668247687';---考虑使用索引
2、最左前缀原则
3、like的使用
4、不能使用索引说明
5、order by
1 select test_index where id = 3 order by id desc;1 select test_index where id = 3 order by name desc;31. Structure du centre commercial
1. Raisons des cas de commerce électronique
大型门户一般是新闻类信息,可以使用CDN,静态化等方式优化, 开心网等交互性比较多,可能会引入更多的NOSQL,分布式缓存,使用高性能的通信框架等. Les sites Web de commerce électronique présentent les caractéristiques des deux catégories ci-dessus, 比如产品详情可以采用CDN,静态化,交互性高的需要采用NOSQL等技术. Par conséquent, nous utilisons les sites Web de commerce électronique comme argument d’analyse. 2 besoins du site Web de commerce électronique
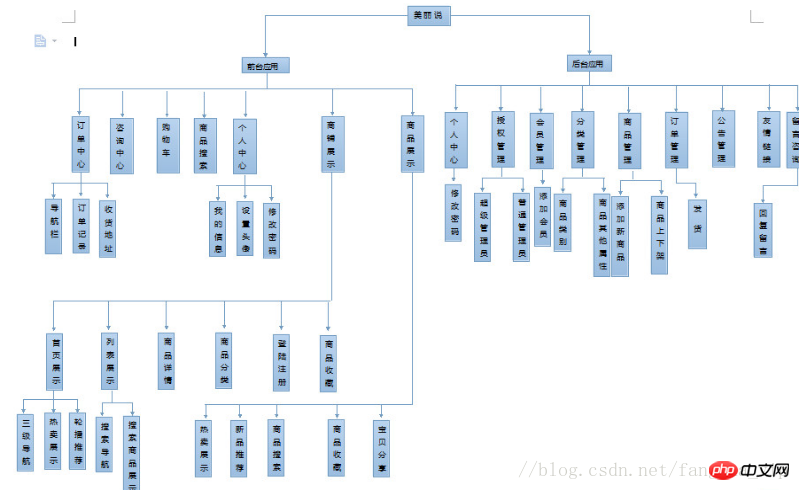
. La matrice de demande de ce site Web de commerce électronique est la suivante : 推荐大家使用需求功能矩阵,进行需求描述
 3 Architecture principale du site Web
3 Architecture principale du site Web 
一般都会采用集群的方式,进行高可用设计 (1) Utiliser des clusters pour des serveurs d'applications redondants pour atteindre une haute disponibilité (un équipement d'équilibrage de charge peut être déployé avec l'application)
(1) Utiliser des clusters pour des serveurs d'applications redondants pour atteindre une haute disponibilité (un équipement d'équilibrage de charge peut être déployé avec l'application)
Étapes d'estimation :
Estimation du serveur : (prenons le serveur Tomcat comme exemple)
Selon l'estimation ci-dessus, il existe plusieurs problèmes : Un grand nombre de serveurs doivent être déployés, et les calculs pendant les périodes de pointe peuvent nécessiter le déploiement de 30 serveurs Web. De plus, ces trente serveurs ne sont utilisés que lors de ventes flash et d'événements, ce qui représente beaucoup de gaspillage. 系统CPU一般维持在70%左右的水平,高峰期达到90%的水平,是不浪费资源,并比较稳定的
Business split , divisé en sous-système de produit, sous-système d'achat, sous-système de paiement, sous-système d'avis, sous-système de service client et sous-système d'interface (interconnexion avec des systèmes externes tels que l'achat, la vente, l'inventaire, les SMS, etc.).
, peut être divisé en système principal et système non principal. Système central : sous-système de produits, sous-système d'achat, sous-système de paiement ; non central : sous-système d'examen, sous-système de service client, sous-système d'interface. 根据业务属性进行垂直切分根据业务子系统进行等级定义业务拆分作用Schéma d'architecture divisée : 等级定义作用
 (2) Le système principal et le système non principal sont déployés en combinaison
(2) Le système principal et le système non principal sont déployés en combinaison
Exigences de haute disponibilité pour les sites Web de commerce électronique, chaque application doit être Déployez au moins deux serveurs pour le déploiement de cluster ; 分布式部署:集群部署: Schéma d'architecture après déploiement du cluster : 
6.3 Cache multi-niveaux
一般可分为两类本地缓存和分布式缓存. Ce cas utilise la méthode du cache de deuxième niveau pour concevoir le cache. Le cache de premier niveau est un cache local et le cache de deuxième niveau est un cache distribué. (Il existe également la mise en cache des pages, la mise en cache des fragments, etc., qui sont des divisions plus fines) 一级缓存,缓存数据字典,和常用热点数据等基本不可变/有规则变化的信息,二级缓存缓存需要的所有缓存. Lorsque le cache de premier niveau expire ou n'est pas disponible, les données du cache de deuxième niveau sont accessibles. S'il n'y a pas de cache de deuxième niveau, la base de données est accédée. 
6.4 Authentification unique (session distribuée)
一般可采用Session同步,Cookies,分布式Session方式. Les sites Web de commerce électronique sont généralement mis en œuvre à l’aide de sessions distribuées. 
6.5 Cluster de bases de données (séparation de la lecture et de l'écriture, sous-base de données et sous-table)
高可用,高性能一般采用冗余的方式进行系统设计. 一般有两种方式读写分离和分库分表读写分离:一般解决读比例远大于写比例的场景,可采用一主一备,一主多备或多主多备方式。
(1) Après la division de l'activité : chaque sous-système nécessite une bibliothèque distincte (2) Si une bibliothèque distincte Si ; elle est trop volumineuse, elle peut à nouveau être divisée en bases de données en fonction des caractéristiques de l'entreprise, telles que la base de données de classification des produits et la base de données des produits (3) Une fois la base de données divisée, s'il y a une grande quantité de données ; dans le tableau, il sera divisé en tableaux. Généralement, les tableaux peuvent être divisés en fonction de l'ID, de l'heure, etc. ; (L'utilisation avancée est un hachage cohérent) (4) Sur la base de la base de données et de la division des tables. , la séparation en lecture et en écriture est effectuée
Le middleware associé peut faire référence à Cobar (Alibaba, actuellement plus en maintenance), TDDL (Alibaba), Atlas (Qihoo 360), MyCat (basé sur Cobar, il y a beaucoup de gens talentueux en Chine et il est connu comme le premier projet open source du pays). Les problèmes avec les séquences, JOIN et les transactions après le partitionnement des bases de données et des tables seront introduits dans le partage thématique des bases de données et des tables de partitionnement. 6.6 Servitisation 将多个子系统公用的功能/模块,进行抽取,作为公用服务使用
消息队列可以解决子系统/模块之间的耦合,实现异步,高可用,高性能的系统 (1) Une fois que l'utilisateur a passé une commande, écrivez-la dans la file d'attente des messages, puis renvoyez-la directement au client (2) Sous-système d'inventaire : lisez la file d'attente des messages ; informations et terminer la réduction des stocks ; (3) Sous-système de livraison : lire les informations sur la file d'attente des messages et livrer
 ;
;建议可以研究下Rabbit MQ。6.8 其他架构(技术)
应用集群,多级缓存,单点登录,数据库集群,服务化,消息队列外。还有CDN,反向代理,分布式文件系统,大数据处理等系统。7 架构总结

32. app
34. AB
前沿
--PV(访问量):Page View, 即页面浏览量或点击量,用户每次刷新即被计算一次。 --UV(独立访客):Unique Visitor,访问您网站的一台电脑客户端为一个访客。00:00-24:00内相同的客户端只会被计算一次。 --IP(独立IP):指独立IP数。00:00-24:00内相同IP地址之被计算一次。
安装
ab的基本参数
-c 并发的请求数 -n 要执行的请求总数 -k 启用keep-alive功能(开启的话,请求会快一些) -H 一个使用冒号分隔的head报文头的附加信息 -t 执行这次测试所用的时间
ab基本语法
ab -c 5 -n 60 -H "Referer: http://baidu.com" -H "Connection: close" http://blog.csdn.net /XXXXXX/article/details/XXXXXXX
ab -c 100 -n 100 -H "User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:3 8.0) Gecko/20100101 Firefox/38.0" -e "E:\ab.csv" http://blog.csdn.net/uxxxxx/artic le/details/xxxx
ab执行结果分析

总结
linux 下ab压力测试
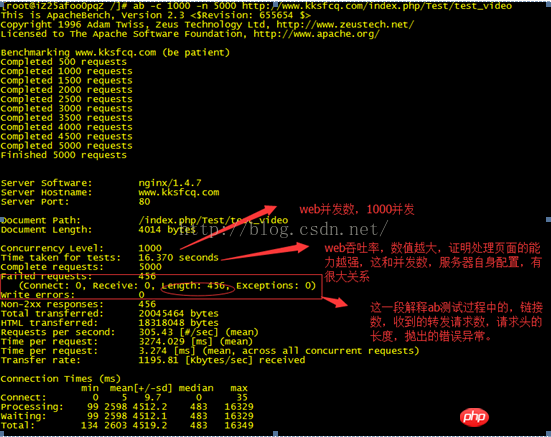
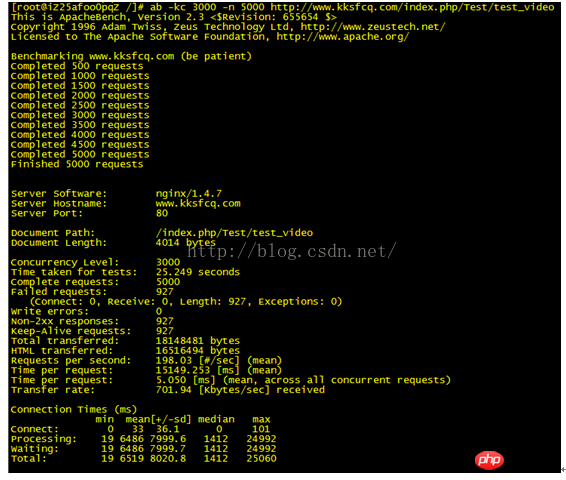 <br/>
<br/>35. Requête lente
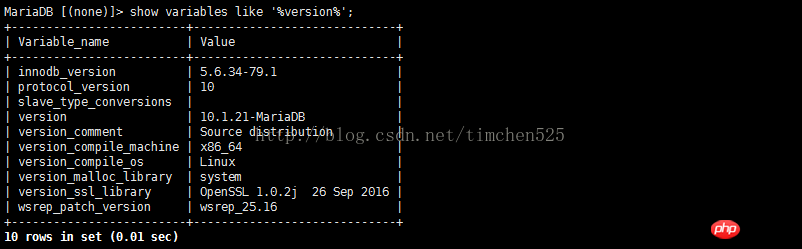 <br/>
<br/> <br/>
<br/> <br/>
<br/> <br/>
<br/>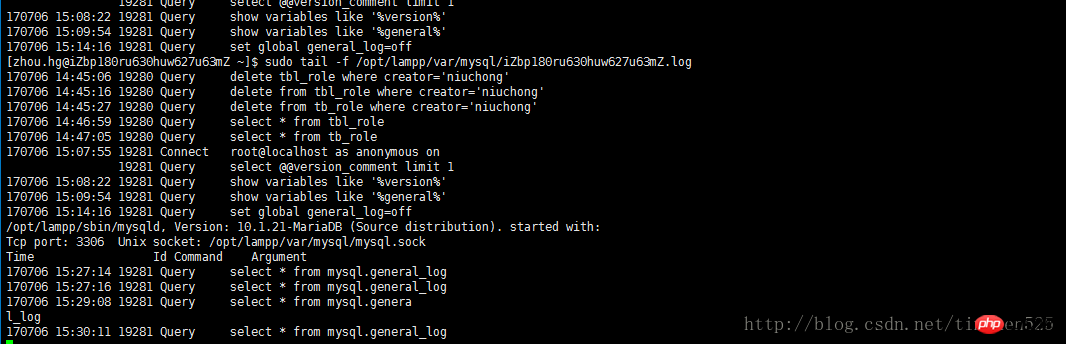 <br/>
<br/>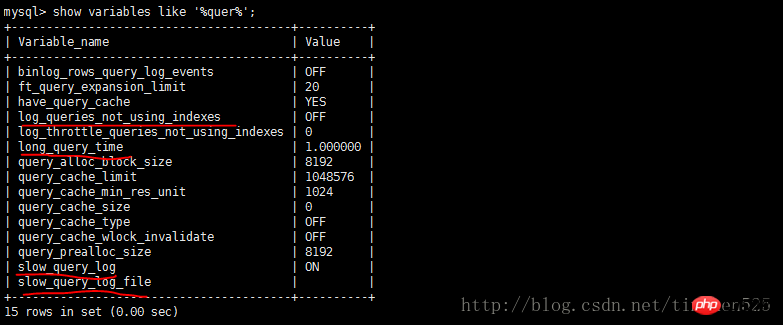 <br/>
<br/> <br/>
<br/> <br/>
<br/>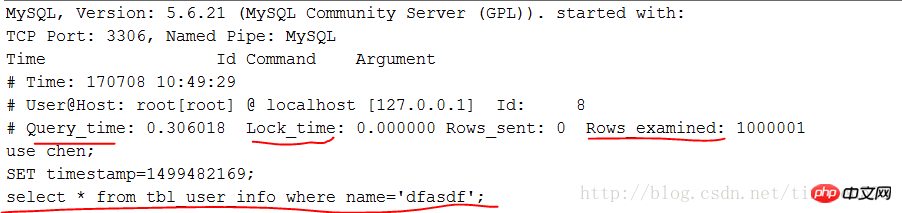 <br/>
<br/>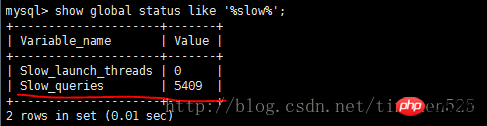 <br/>
<br/> <br/>
<br/>36. Framework
Framework open source (TP, CI, Laravel, Yii)
37. 命名空间
PHP命名空间 namespace 及导入 use 的用法
<?php
echo 111;
//由于namespace前有代码而报错
namespace Teacher;
class Person{
function __construct(){
echo 'Please study!';
}
}<?php
namespace Newer;
require_once './1.php';
new Person();
//报错,找不到Person;
new \Person();
//输出 I am tow!;
<?php
namespace New;
require_once './2.php';
new Person();
//报错,(当前空间)找不到
Person; new \Person();
//报错,(公共空间)找不到
Person; new \Two\Person();
//输出 I am tow!;
namespace School\Parents;
class Man{
function __construct(){
echo 'Listen to teachers!<br/>';
}
}
namespace School\Teacher;
class Person{
function __construct(){
echo 'Please study!<br/>';
}
}
namespace School\Student;
class Person{
function __construct(){
echo 'I want to play!<br/>';
}
}
new Person();
//输出I want to play!
new \School\Teacher\Person();
//输出Please study!
new Teacher\Person();
//报错 ----------
use School\Teacher;
new Teacher\Person();
//输出Please study! ----------
use School\Teacher as Tc;
new Tc\Person();
//输出Please study! ----------
use \School\Teacher\Person;
new Person();
//报错 ----------
use \School\Parent\Man;
new Man();
//报错
 Comment ouvrir le fichier php
Comment ouvrir le fichier php
 Comment supprimer les premiers éléments d'un tableau en php
Comment supprimer les premiers éléments d'un tableau en php
 Que faire si la désérialisation php échoue
Que faire si la désérialisation php échoue
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Comment télécharger du HTML
Comment télécharger du HTML
 Comment résoudre les caractères tronqués en PHP
Comment résoudre les caractères tronqués en PHP
 Comment ouvrir des fichiers php sur un téléphone mobile
Comment ouvrir des fichiers php sur un téléphone mobile








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



