
 développement back-end
Tutoriel Python
Extraction du squelette de traitement d'images numériques Python et algorithme de bassin versant
développement back-end
Tutoriel Python
Extraction du squelette de traitement d'images numériques Python et algorithme de bassin versant
Extraction du squelette de traitement d'images numériques Python et algorithme de bassin versant

Cet article présente principalement l'algorithme d'extraction de squelette et de bassin versant du traitement d'images numériques Python. Maintenant, je le partage avec vous et vous donne une référence. Jetons un coup d'oeil ensemble
L'extraction de squelette et l'algorithme de bassin versant appartiennent également à la catégorie du traitement morphologique, et sont placés dans le sous-module morphologie.
1. Extraction du squelette
Extraction du squelette, également appelée amincissement de l'image binaire. Cet algorithme peut affiner une région connectée en une largeur d'un pixel pour l'extraction de caractéristiques et la représentation de la topologie cible.
Le sous-module morphologie fournit deux fonctions pour l'extraction du squelette, à savoir la fonction Skeletonize() et la fonction medial_axis(). Regardons d'abord la fonction Skeletonize().
Le format est : skimage.morphologie.squelette(image)
L'entrée et la sortie sont toutes deux des images binaires.
Exemple 1 :
from skimage import morphology,draw import numpy as np import matplotlib.pyplot as plt #创建一个二值图像用于测试 image = np.zeros((400, 400)) #生成目标对象1(白色U型) image[10:-10, 10:100] = 1 image[-100:-10, 10:-10] = 1 image[10:-10, -100:-10] = 1 #生成目标对象2(X型) rs, cs = draw.line(250, 150, 10, 280) for i in range(10): image[rs + i, cs] = 1 rs, cs = draw.line(10, 150, 250, 280) for i in range(20): image[rs + i, cs] = 1 #生成目标对象3(O型) ir, ic = np.indices(image.shape) circle1 = (ic - 135)**2 + (ir - 150)**2 < 30**2 circle2 = (ic - 135)**2 + (ir - 150)**2 < 20**2 image[circle1] = 1 image[circle2] = 0 #实施骨架算法 skeleton =morphology.skeletonize(image) #显示结果 fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(8, 4)) ax1.imshow(image, cmap=plt.cm.gray) ax1.axis('off') ax1.set_title('original', fontsize=20) ax2.imshow(skeleton, cmap=plt.cm.gray) ax2.axis('off') ax2.set_title('skeleton', fontsize=20) fig.tight_layout() plt.show()
Générez une image de test avec trois objets cibles dessus et effectuez respectivement une extraction du squelette. Les résultats sont. comme suit :

Exemple 2 : Utilisation des propres images de chevaux du système pour l'extraction du squelette
from skimage import morphology,data,color import matplotlib.pyplot as plt image=color.rgb2gray(data.horse()) image=1-image #反相 #实施骨架算法 skeleton =morphology.skeletonize(image) #显示结果 fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(8, 4)) ax1.imshow(image, cmap=plt.cm.gray) ax1.axis('off') ax1.set_title('original', fontsize=20) ax2.imshow(skeleton, cmap=plt.cm.gray) ax2.axis('off') ax2.set_title('skeleton', fontsize=20) fig.tight_layout() plt.show()

medial_axis signifie l'axe médial. La méthode de transformation de l'axe médial est utilisée pour calculer la largeur de l'objet cible de premier plan (valeur 1). Le format est :
. skimage.morphologie. medial_axis(image,mask=None,return_distance=False)
masque : masque. La valeur par défaut est Aucun. Si un masque est donné, l'algorithme du squelette sera exécuté uniquement sur les valeurs de pixels à l'intérieur du masque.
return_distance : valeur bool, la valeur par défaut est False Si elle est True, en plus de renvoyer le squelette, la valeur de transformation de distance sera également renvoyée en même temps. La distance fait ici référence à la distance entre tous les points de l'axe central et le point d'arrière-plan.
import numpy as np import scipy.ndimage as ndi from skimage import morphology import matplotlib.pyplot as plt #编写一个函数,生成测试图像 def microstructure(l=256): n = 5 x, y = np.ogrid[0:l, 0:l] mask = np.zeros((l, l)) generator = np.random.RandomState(1) points = l * generator.rand(2, n**2) mask[(points[0]).astype(np.int), (points[1]).astype(np.int)] = 1 mask = ndi.gaussian_filter(mask, sigma=l/(4.*n)) return mask > mask.mean() data = microstructure(l=64) #生成测试图像 #计算中轴和距离变换值 skel, distance =morphology.medial_axis(data, return_distance=True) #中轴上的点到背景像素点的距离 dist_on_skel = distance * skel fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 4)) ax1.imshow(data, cmap=plt.cm.gray, interpolation='nearest') #用光谱色显示中轴 ax2.imshow(dist_on_skel, cmap=plt.cm.spectral, interpolation='nearest') ax2.contour(data, [0.5], colors='w') #显示轮廓线 fig.tight_layout() plt.show()
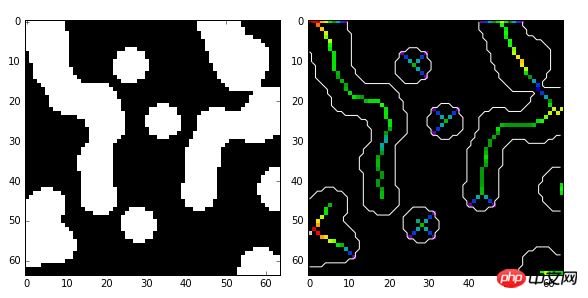
2. Algorithme de bassin versant
Un bassin versant fait référence à une crête en géographie. L'eau s'écoule généralement des deux côtés de la crête vers différents « bassins versants ». L'algorithme de bassin versant est un algorithme classique de segmentation d'images et une méthode de segmentation morphologique mathématique basée sur la théorie de la topologie. Si les objets cibles de l’image sont connectés entre eux, il sera plus difficile de segmenter. L’algorithme de partage des eaux est souvent utilisé pour résoudre de tels problèmes et permet généralement d’obtenir de meilleurs résultats.
L'algorithme de bassin versant peut être combiné avec la transformation de distance pour trouver des « bassins versants » et des « limites de bassin versant » pour segmenter les images. La transformation de distance d'une image binaire est la distance entre chaque pixel et le pixel non nul le plus proche. Nous pouvons utiliser le package scipy pour calculer la transformation de distance.
Dans l'exemple ci-dessous, deux cercles qui se chevauchent doivent être séparés. Nous calculons d'abord la transformation de distance de ces pixels blancs sur le cercle aux pixels de fond noir, sélectionnons la valeur maximale dans la transformation de distance comme point marqueur initial (s'il s'agit d'une couleur inversée, prenons la valeur minimale), à partir de ces marqueurs. points Les deux bassins versants s'agrandissent de plus en plus et se croisent finalement au niveau de la crête de la montagne. Déconnectés de la crête de la montagne, nous obtenons deux cercles distincts.
Exemple 1 : Segmentation d'image de crête de montagne basée sur la transformation de distance
import numpy as np
import matplotlib.pyplot as plt
from scipy import ndimage as ndi
from skimage import morphology,feature
#创建两个带有重叠圆的图像
x, y = np.indices((80, 80))
x1, y1, x2, y2 = 28, 28, 44, 52
r1, r2 = 16, 20
mask_circle1 = (x - x1)**2 + (y - y1)**2 < r1**2
mask_circle2 = (x - x2)**2 + (y - y2)**2 < r2**2
image = np.logical_or(mask_circle1, mask_circle2)
#现在我们用分水岭算法分离两个圆
distance = ndi.distance_transform_edt(image) #距离变换
local_maxi =feature.peak_local_max(distance, indices=False, footprint=np.ones((3, 3)),
labels=image) #寻找峰值
markers = ndi.label(local_maxi)[0] #初始标记点
labels =morphology.watershed(-distance, markers, mask=image) #基于距离变换的分水岭算法
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 8))
axes = axes.ravel()
ax0, ax1, ax2, ax3 = axes
ax0.imshow(image, cmap=plt.cm.gray, interpolation='nearest')
ax0.set_title("Original")
ax1.imshow(-distance, cmap=plt.cm.jet, interpolation='nearest')
ax1.set_title("Distance")
ax2.imshow(markers, cmap=plt.cm.spectral, interpolation='nearest')
ax2.set_title("Markers")
ax3.imshow(labels, cmap=plt.cm.spectral, interpolation='nearest')
ax3.set_title("Segmented")
for ax in axes:
ax.axis('off')
fig.tight_layout()
plt.show()
L'algorithme du bassin versant est également Il peut être combiné avec un dégradé pour réaliser une segmentation d'image. Généralement, les images dégradées ont des valeurs de pixels plus élevées sur les bords et des valeurs de pixels plus faibles ailleurs. Idéalement, les crêtes devraient être exactement sur les bords. Par conséquent, nous pouvons trouver des crêtes basées sur les gradients.
Exemple 2 : Segmentation d'images de bassin versant basée sur un dégradé
import matplotlib.pyplot as plt
from scipy import ndimage as ndi
from skimage import morphology,color,data,filter
image =color.rgb2gray(data.camera())
denoised = filter.rank.median(image, morphology.disk(2)) #过滤噪声
#将梯度值低于10的作为开始标记点
markers = filter.rank.gradient(denoised, morphology.disk(5)) <10
markers = ndi.label(markers)[0]
gradient = filter.rank.gradient(denoised, morphology.disk(2)) #计算梯度
labels =morphology.watershed(gradient, markers, mask=image) #基于梯度的分水岭算法
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(6, 6))
axes = axes.ravel()
ax0, ax1, ax2, ax3 = axes
ax0.imshow(image, cmap=plt.cm.gray, interpolation='nearest')
ax0.set_title("Original")
ax1.imshow(gradient, cmap=plt.cm.spectral, interpolation='nearest')
ax1.set_title("Gradient")
ax2.imshow(markers, cmap=plt.cm.spectral, interpolation='nearest')
ax2.set_title("Markers")
ax3.imshow(labels, cmap=plt.cm.spectral, interpolation='nearest')
ax3.set_title("Segmented")
for ax in axes:
ax.axis('off')
fig.tight_layout()
plt.show()
Recommandations associées :
Traitement morphologique avancé du traitement d'images numériques python
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Une formation efficace des modèles Pytorch sur les systèmes CentOS nécessite des étapes, et cet article fournira des guides détaillés. 1. Préparation de l'environnement: Installation de Python et de dépendance: le système CentOS préinstalle généralement Python, mais la version peut être plus ancienne. Il est recommandé d'utiliser YUM ou DNF pour installer Python 3 et Mettez PIP: sudoyuMupDatePython3 (ou sudodnfupdatepython3), pip3install-upradepip. CUDA et CUDNN (accélération GPU): Si vous utilisez Nvidiagpu, vous devez installer Cudatool
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Lors de la sélection d'une version Pytorch sous CentOS, les facteurs clés suivants doivent être pris en compte: 1. CUDA Version Compatibilité GPU Prise en charge: si vous avez NVIDIA GPU et que vous souhaitez utiliser l'accélération GPU, vous devez choisir Pytorch qui prend en charge la version CUDA correspondante. Vous pouvez afficher la version CUDA prise en charge en exécutant la commande nvidia-SMI. Version CPU: Si vous n'avez pas de GPU ou que vous ne souhaitez pas utiliser de GPU, vous pouvez choisir une version CPU de Pytorch. 2. Version Python Pytorch
 Miniopen Centos Compatibilité
Apr 14, 2025 pm 05:45 PM
Miniopen Centos Compatibilité
Apr 14, 2025 pm 05:45 PM
Minio Object Storage: Déploiement haute performance dans le système Centos System Minio est un système de stockage d'objets distribué haute performance développé sur la base du langage Go, compatible avec Amazons3. Il prend en charge une variété de langages clients, notamment Java, Python, JavaScript et GO. Cet article introduira brièvement l'installation et la compatibilité de Minio sur les systèmes CentOS. Compatibilité de la version CentOS Minio a été vérifiée sur plusieurs versions CentOS, y compris, mais sans s'y limiter: CentOS7.9: fournit un guide d'installation complet couvrant la configuration du cluster, la préparation de l'environnement, les paramètres de fichiers de configuration, le partitionnement du disque et la mini
 Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
CENTOS L'installation de Nginx nécessite de suivre les étapes suivantes: Installation de dépendances telles que les outils de développement, le devet PCRE et l'OpenSSL. Téléchargez le package de code source Nginx, dézippez-le et compilez-le et installez-le, et spécifiez le chemin d'installation AS / USR / LOCAL / NGINX. Créez des utilisateurs et des groupes d'utilisateurs de Nginx et définissez les autorisations. Modifiez le fichier de configuration nginx.conf et configurez le port d'écoute et le nom de domaine / adresse IP. Démarrez le service Nginx. Les erreurs communes doivent être prêtées à prêter attention, telles que les problèmes de dépendance, les conflits de port et les erreurs de fichiers de configuration. L'optimisation des performances doit être ajustée en fonction de la situation spécifique, comme l'activation du cache et l'ajustement du nombre de processus de travail.
