
 développement back-end
Tutoriel Python
Explication détaillée de la formation par lots PyTorch et de la comparaison des optimiseurs
développement back-end
Tutoriel Python
Explication détaillée de la formation par lots PyTorch et de la comparaison des optimiseurs
Explication détaillée de la formation par lots PyTorch et de la comparaison des optimiseurs

Cet article présente principalement l'explication détaillée de la formation par lots PyTorch et la comparaison des optimiseurs. Il présente en détail ce que sont la formation par lots PyTorch et l'optimiseur PyTorch. Il est d'une grande valeur pratique. Les amis dans le besoin peuvent s'y référer. 🎜 >
1. Formation par lots PyTorch
1. PrésentationPyTorch fournit un moyen de regrouper les données pour la formation par lots. Outil de formation - DataLoader. Lorsque nous l'utilisons, il nous suffit d'abord de convertir nos données sous la forme tensorielle de Torch, puis de les convertir dans un format d'ensemble de données que Torch peut reconnaître, puis de placer l'ensemble de données dans le DataLoader.
import torch
import torch.utils.data as Data
torch.manual_seed(1) # 设定随机数种子
BATCH_SIZE = 5
x = torch.linspace(1, 10, 10)
y = torch.linspace(0.5, 5, 10)
# 将数据转换为torch的dataset格式
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 将torch_dataset置入Dataloader中
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE, # 批大小
# 若dataset中的样本数不能被batch_size整除的话,最后剩余多少就使用多少
shuffle=True, # 是否随机打乱顺序
num_workers=2, # 多线程读取数据的线程数
)
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
print('Epoch:', epoch, '|Step:', step, '|batch_x:',
batch_x.numpy(), '|batch_y', batch_y.numpy())
'''''
shuffle=True
Epoch: 0 |Step: 0 |batch_x: [ 6. 7. 2. 3. 1.] |batch_y [ 3. 3.5 1. 1.5 0.5]
Epoch: 0 |Step: 1 |batch_x: [ 9. 10. 4. 8. 5.] |batch_y [ 4.5 5. 2. 4. 2.5]
Epoch: 1 |Step: 0 |batch_x: [ 3. 4. 2. 9. 10.] |batch_y [ 1.5 2. 1. 4.5 5. ]
Epoch: 1 |Step: 1 |batch_x: [ 1. 7. 8. 5. 6.] |batch_y [ 0.5 3.5 4. 2.5 3. ]
Epoch: 2 |Step: 0 |batch_x: [ 3. 9. 2. 6. 7.] |batch_y [ 1.5 4.5 1. 3. 3.5]
Epoch: 2 |Step: 1 |batch_x: [ 10. 4. 8. 1. 5.] |batch_y [ 5. 2. 4. 0.5 2.5]
shuffle=False
Epoch: 0 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 0 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
Epoch: 1 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 1 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
Epoch: 2 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 2 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
'''classtorch.utils.data.TensorDataset(data_tensor, target_tensor)
La classe TensorDataset est utilisée pour regrouper des échantillons et leurs étiquettes dans un data_tensor torch, et target_tensor sont tous deux des tenseurs.
3. DataLoader Le code est le suivant : classtorch.utils .data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,num_workers=0, collate_fn=
l'ensemble de données est L'objet Dataset Format de Torch ; batch_size est le nombre d'échantillons pour chaque lot de formation, la valeur par défaut est : shuffle indique si les échantillons doivent être prélevés de manière aléatoire ; num_workers indique le nombre de threads pour lire les échantillons.
2. L'optimiseur de PyTorch Dans cette expérience, construisez d'abord un ensemble d'ensembles de données, convertissez le format et placez-le dans le DataLoader. de rechange. Définissez un réseau neuronal par défaut avec une structure fixe, puis créez un réseau neuronal pour chaque optimiseur. La différence entre chaque réseau neuronal réside uniquement dans l'optimiseur. En enregistrant la valeur de perte pendant le processus de formation, le processus d'optimisation de chaque optimiseur est enfin présenté sur l'image.
Implémentation du code :
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1) # 设定随机数种子
# 定义超参数
LR = 0.01 # 学习率
BATCH_SIZE = 32 # 批大小
EPOCH = 12 # 迭代次数
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
#plt.scatter(x.numpy(), y.numpy())
#plt.show()
# 将数据转换为torch的dataset格式
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 将torch_dataset置入Dataloader中
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=2)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20)
self.predict = torch.nn.Linear(20, 1)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
# 为每个优化器创建一个Net
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
# 初始化优化器
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
# 定义损失函数
loss_function = torch.nn.MSELoss()
losses_history = [[], [], [], []] # 记录training时不同神经网络的loss值
for epoch in range(EPOCH):
print('Epoch:', epoch + 1, 'Training...')
for step, (batch_x, batch_y) in enumerate(loader):
b_x = Variable(batch_x)
b_y = Variable(batch_y)
for net, opt, l_his in zip(nets, optimizers, losses_history):
output = net(b_x)
loss = loss_function(output, b_y)
opt.zero_grad()
loss.backward()
opt.step()
l_his.append(loss.data[0])
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_history):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()Résultats expérimentaux :
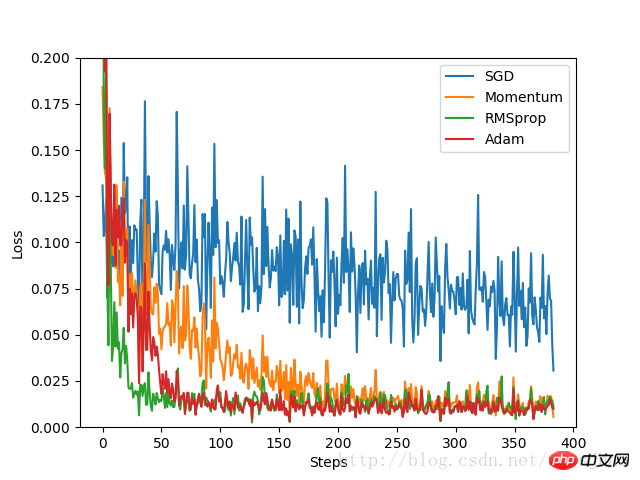 Par expérimentation Les résultats montrent que SGD a le pire effet d'optimisation et est très lent ; en tant que version améliorée de SGD, Momentum fonctionne bien mieux que RMSprop et Adam, la vitesse d'optimisation est très bonne ; Dans l'expérience, pour différents problèmes d'optimisation, les effets de différents optimiseurs ont été comparés avant de décider lequel utiliser.
Par expérimentation Les résultats montrent que SGD a le pire effet d'optimisation et est très lent ; en tant que version améliorée de SGD, Momentum fonctionne bien mieux que RMSprop et Adam, la vitesse d'optimisation est très bonne ; Dans l'expérience, pour différents problèmes d'optimisation, les effets de différents optimiseurs ont été comparés avant de décider lequel utiliser.
3. Autres suppléments
1. La fonction zip de Pythonla fonction zip accepte n'importe quel multiple. (y compris 0 et 1) les séquences sont prises comme paramètres et une liste de tuples est renvoyée.
x = [1, 2, 3] y = [4, 5, 6] z = [7, 8, 9] xyz = zip(x, y, z) print xyz [(1, 4, 7), (2, 5, 8), (3, 6, 9)] x = [1, 2, 3] x = zip(x) print x [(1,), (2,), (3,)] x = [1, 2, 3] y = [4, 5, 6, 7] xy = zip(x, y) print xy [(1, 4), (2, 5), (3, 6)]
Recommandations associées :
Introduction à l'exemple de classification mnist de PytorchCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment activer la fonction nfc sur Xiaomi Mi 14 Pro ?
Mar 19, 2024 pm 02:28 PM
Comment activer la fonction nfc sur Xiaomi Mi 14 Pro ?
Mar 19, 2024 pm 02:28 PM
De nos jours, les performances et les fonctions des téléphones mobiles deviennent de plus en plus puissantes. Presque tous les téléphones mobiles sont équipés de fonctions NFC pratiques pour faciliter le paiement mobile et l'authentification de l'identité des utilisateurs. Cependant, certains utilisateurs de Xiaomi 14Pro ne savent peut-être pas comment activer la fonction NFC. Ensuite, permettez-moi de vous le présenter en détail. Comment activer la fonction nfc sur Xiaomi 14Pro ? Étape 1 : Ouvrez le menu des paramètres de votre téléphone. Étape 2 : Recherchez et cliquez sur l'option « Connecter et partager » ou « Sans fil et réseaux ». Étape 3 : Dans le menu Connexion et partage ou Sans fil et réseaux, recherchez et cliquez sur « NFC et paiements ». Étape 4 : Recherchez et cliquez sur « NFC Switch ». Généralement, la valeur par défaut est désactivée. Étape 5 : Sur la page du commutateur NFC, cliquez sur le bouton du commutateur pour l'activer.
 Comment définir l'espacement des lignes dans WPS Word pour rendre le document plus soigné
Mar 20, 2024 pm 04:30 PM
Comment définir l'espacement des lignes dans WPS Word pour rendre le document plus soigné
Mar 20, 2024 pm 04:30 PM
WPS est notre logiciel bureautique couramment utilisé lors de l'édition d'articles longs, les polices sont souvent trop petites pour être clairement visibles, c'est pourquoi les polices et l'ensemble du document sont ajustés. Par exemple : ajuster l'espacement des lignes du document rendra l'ensemble du document très clair. Je suggère à tous les amis d'apprendre cette étape de l'opération. Je la partagerai avec vous aujourd'hui. Les étapes de l'opération spécifiques sont les suivantes, venez jeter un oeil ! Ouvrez le fichier texte WPS que vous souhaitez ajuster, recherchez la barre d'outils de configuration des paragraphes dans le menu [Démarrer] et vous verrez la petite icône de configuration de l'espacement des lignes (représentée par un cercle rouge dans l'image). 2. Cliquez sur le petit triangle inversé dans le coin inférieur droit du paramètre d'espacement des lignes et la valeur d'espacement des lignes correspondante apparaîtra. Vous pouvez choisir 1 à 3 fois l'espacement des lignes (comme indiqué par la flèche sur la figure). 3. Ou cliquez avec le bouton droit sur le paragraphe et il apparaîtra.
 Comment utiliser TikTok sur Huawei Pocket2 à distance ?
Mar 18, 2024 pm 03:00 PM
Comment utiliser TikTok sur Huawei Pocket2 à distance ?
Mar 18, 2024 pm 03:00 PM
Faire glisser l'écran dans les airs est une fonctionnalité de Huawei très appréciée dans la série Huawei mate60. Cette fonctionnalité utilise le capteur laser du téléphone et la caméra de profondeur 3D de la caméra frontale pour compléter une série de fonctions qui ne nécessitent pas de fonction. fonction de toucher l'écran, comme faire glisser TikTok depuis les airs, mais comment utiliser le Huawei Pocket 2 pour faire glisser TikTok depuis les airs ? Comment faire des captures d'écran depuis les airs avec Huawei Pocket2 ? 1. Ouvrez les paramètres de Huawei Pocket2. 2. Sélectionnez ensuite [Accessibilité]. 3. Cliquez pour ouvrir [Perception intelligente]. 4. Activez simplement les commutateurs [Air Swipe Screen], [Air Screenshot] et [Air Press]. 5. Lorsque vous l'utilisez, vous devez le tenir à 20 ~ 40 cm de l'écran, ouvrir votre paume et attendre que l'icône de la paume apparaisse sur l'écran.
 La différence et analyse comparative entre le langage C et PHP
Mar 20, 2024 am 08:54 AM
La différence et analyse comparative entre le langage C et PHP
Mar 20, 2024 am 08:54 AM
Différences et analyse comparative du langage C et de PHP Le langage C et PHP sont tous deux des langages de programmation courants, mais ils présentent des différences évidentes sur de nombreux aspects. Cet article procédera à une analyse comparative du langage C et de PHP et illustrera les différences entre eux à travers des exemples de code spécifiques. 1. Syntaxe et utilisation : Langage C : Le langage C est un langage de programmation orienté processus, principalement utilisé pour la programmation au niveau système et le développement embarqué. La syntaxe du langage C est relativement simple et de bas niveau, peut exploiter directement la mémoire, et est efficace et flexible. Le langage C met l'accent sur l'exhaustivité du programme pour le programmeur
 Explication détaillée de GQA, le mécanisme d'attention couramment utilisé dans les grands modèles, et l'implémentation du code Pytorch
Apr 03, 2024 pm 05:40 PM
Explication détaillée de GQA, le mécanisme d'attention couramment utilisé dans les grands modèles, et l'implémentation du code Pytorch
Apr 03, 2024 pm 05:40 PM
Grouped Query Attention (GroupedQueryAttention) est une méthode d'attention multi-requêtes dans les grands modèles de langage. Son objectif est d'atteindre la qualité du MHA tout en maintenant la vitesse du MQA. GroupedQueryAttention regroupe les requêtes et les requêtes au sein de chaque groupe partagent le même poids d'attention, ce qui permet de réduire la complexité de calcul et d'augmenter la vitesse d'inférence. Dans cet article, nous expliquerons l'idée de GQA et comment la traduire en code. GQA est dans le document GQA:TrainingGeneralizedMulti-QueryTransformerModelsfromMulti-HeadCheckpoint
 TrendX Research Institute : analyse du projet Merlin Chain et inventaire écologique
Mar 24, 2024 am 09:01 AM
TrendX Research Institute : analyse du projet Merlin Chain et inventaire écologique
Mar 24, 2024 am 09:01 AM
Selon les statistiques du 2 mars, la TVL totale du réseau de deuxième couche de Bitcoin, MerlinChain, a atteint 3 milliards de dollars. Parmi eux, les actifs écologiques Bitcoin représentaient 90,83 %, dont BTC d’une valeur de 1,596 milliard de dollars et les actifs BRC-20 d’une valeur de 404 millions de dollars. Le mois dernier, le TVL total de MerlinChain a atteint 1,97 milliard de dollars américains dans les 14 jours suivant le lancement des activités de jalonnement, dépassant Blast, qui a été lancé en novembre de l'année dernière et est également le plus récent et tout aussi accrocheur. Le 26 février, la valeur totale des NFT dans l'écosystème MerlinChain a dépassé 420 millions de dollars américains, devenant ainsi le projet de chaîne publique avec la valeur marchande NFT la plus élevée après Ethereum. Introduction du projet MerlinChain est un support OKX
 Comment utiliser l'extension d'image intelligente Xiaomi Mi 14 Ultra AI ?
Mar 16, 2024 pm 12:37 PM
Comment utiliser l'extension d'image intelligente Xiaomi Mi 14 Ultra AI ?
Mar 16, 2024 pm 12:37 PM
Le progrès des temps a rendu les revenus de nombreuses personnes de plus en plus élevés, et les téléphones mobiles qu'ils utilisent habituellement seront changés fréquemment. Le Xiaomi Mi 14 Ultra récemment lancé par Xiaomi doit être familier aux utilisateurs. La configuration des performances est très élevée, et elle. peut offrir aux utilisateurs plus Afin d'offrir une expérience confortable et fluide, les nouveaux téléphones mobiles rencontreront inévitablement de nombreuses fonctions qui ne sont pas utilisées. Par exemple, comment utiliser l'extension d'image intelligente Xiaomi 14UltraAI ? Venez jeter un oeil au tutoriel d'utilisation ci-dessous ! Comment utiliser l'extension d'image intelligente Xiaomi 14UltraAI ? Ouvrez d’abord Xiaomi 14Ultra, entrez dans l’album photo, sélectionnez l’image que vous souhaitez agrandir et entrez dans l’option d’édition de l’album photo. Cliquez sur Rotation de recadrage, cliquez sur Recadrer et cliquez sur Développement intelligent dans la sélection qui apparaît. Enfin, choisissez la manière d'agrandir l'image en fonction de vos propres besoins.
 Optimisation des programmes C++ : techniques de réduction de la complexité temporelle
Jun 01, 2024 am 11:19 AM
Optimisation des programmes C++ : techniques de réduction de la complexité temporelle
Jun 01, 2024 am 11:19 AM
La complexité temporelle mesure le temps d'exécution d'un algorithme par rapport à la taille de l'entrée. Les conseils pour réduire la complexité temporelle des programmes C++ incluent : le choix des conteneurs appropriés (tels que vecteur, liste) pour optimiser le stockage et la gestion des données. Utilisez des algorithmes efficaces tels que le tri rapide pour réduire le temps de calcul. Éliminez les opérations multiples pour réduire le double comptage. Utilisez des branches conditionnelles pour éviter les calculs inutiles. Optimisez la recherche linéaire en utilisant des algorithmes plus rapides tels que la recherche binaire.
