
 développement back-end
Tutoriel Python
Comment TensorFlow met en œuvre l'entraînement aléatoire et l'entraînement par lots
développement back-end
Tutoriel Python
Comment TensorFlow met en œuvre l'entraînement aléatoire et l'entraînement par lots
Comment TensorFlow met en œuvre l'entraînement aléatoire et l'entraînement par lots

Cet article présente principalement la méthode de TensorFlow pour implémenter l'entraînement aléatoire et l'entraînement par lots. Maintenant, je le partage avec vous et le donne comme référence. Venez jeter un œil ensemble
TensorFlow met à jour les variables du modèle. Il peut fonctionner sur un point de données à la fois ou sur de grandes quantités de données à la fois. Opérer sur un seul exemple de formation peut conduire à un processus d'apprentissage « original », mais la formation avec de gros lots peut être coûteuse en termes de calcul. Le type de formation choisi est très critique pour la convergence de l’algorithme d’apprentissage automatique.
Pour que TensorFlow puisse calculer des gradients variables pour que la rétropropagation fonctionne, nous devons mesurer la perte sur un ou plusieurs échantillons.
L'entraînement aléatoire échantillonnera de manière aléatoire les données d'entraînement et ciblera les paires de données à la fois pour terminer l'entraînement. Une autre option consiste à faire la moyenne de la perte pour le calcul du gradient dans une formation par lots importants, et la taille de la formation par lots peut être étendue à l'ensemble des données en même temps. Nous montrons ici comment étendre l'exemple précédent d'un algorithme de régression - en utilisant un entraînement aléatoire et un entraînement par lots.
La formation par lots et la formation aléatoire diffèrent par leurs méthodes d'optimisation et leur convergence.
# 随机训练和批量训练
#----------------------------------
#
# This python function illustrates two different training methods:
# batch and stochastic training. For each model, we will use
# a regression model that predicts one model variable.
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.python.framework import ops
ops.reset_default_graph()
# 随机训练:
# Create graph
sess = tf.Session()
# 声明数据
x_vals = np.random.normal(1, 0.1, 100)
y_vals = np.repeat(10., 100)
x_data = tf.placeholder(shape=[1], dtype=tf.float32)
y_target = tf.placeholder(shape=[1], dtype=tf.float32)
# 声明变量 (one model parameter = A)
A = tf.Variable(tf.random_normal(shape=[1]))
# 增加操作到图
my_output = tf.multiply(x_data, A)
# 增加L2损失函数
loss = tf.square(my_output - y_target)
# 初始化变量
init = tf.global_variables_initializer()
sess.run(init)
# 声明优化器
my_opt = tf.train.GradientDescentOptimizer(0.02)
train_step = my_opt.minimize(loss)
loss_stochastic = []
# 运行迭代
for i in range(100):
rand_index = np.random.choice(100)
rand_x = [x_vals[rand_index]]
rand_y = [y_vals[rand_index]]
sess.run(train_step, feed_dict={x_data: rand_x, y_target: rand_y})
if (i+1)%5==0:
print('Step #' + str(i+1) + ' A = ' + str(sess.run(A)))
temp_loss = sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y})
print('Loss = ' + str(temp_loss))
loss_stochastic.append(temp_loss)
# 批量训练:
# 重置计算图
ops.reset_default_graph()
sess = tf.Session()
# 声明批量大小
# 批量大小是指通过计算图一次传入多少训练数据
batch_size = 20
# 声明模型的数据、占位符
x_vals = np.random.normal(1, 0.1, 100)
y_vals = np.repeat(10., 100)
x_data = tf.placeholder(shape=[None, 1], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
# 声明变量 (one model parameter = A)
A = tf.Variable(tf.random_normal(shape=[1,1]))
# 增加矩阵乘法操作(矩阵乘法不满足交换律)
my_output = tf.matmul(x_data, A)
# 增加损失函数
# 批量训练时损失函数是每个数据点L2损失的平均值
loss = tf.reduce_mean(tf.square(my_output - y_target))
# 初始化变量
init = tf.global_variables_initializer()
sess.run(init)
# 声明优化器
my_opt = tf.train.GradientDescentOptimizer(0.02)
train_step = my_opt.minimize(loss)
loss_batch = []
# 运行迭代
for i in range(100):
rand_index = np.random.choice(100, size=batch_size)
rand_x = np.transpose([x_vals[rand_index]])
rand_y = np.transpose([y_vals[rand_index]])
sess.run(train_step, feed_dict={x_data: rand_x, y_target: rand_y})
if (i+1)%5==0:
print('Step #' + str(i+1) + ' A = ' + str(sess.run(A)))
temp_loss = sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y})
print('Loss = ' + str(temp_loss))
loss_batch.append(temp_loss)
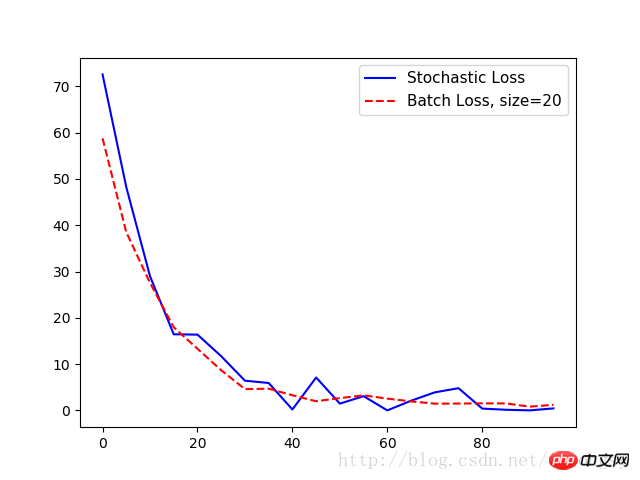
plt.plot(range(0, 100, 5), loss_stochastic, 'b-', label='Stochastic Loss')
plt.plot(range(0, 100, 5), loss_batch, 'r--', label='Batch Loss, size=20')
plt.legend(loc='upper right', prop={'size': 11})
plt.show()Sortie :
Étape #5 A = [ 1.47604525]
Perte = [ 72.55678558]
Étape n°10 A = [ 3.01128507]
Perte = [ 48.22986221]
Étape n°15 A = [ 4.27042341]
Perte = [ 28.97912598]
Étape n°20 A = [ 5.2984333]
Perte = [ 16.44779968]
Étape #25 A = [ 6.17473984]
Perte = [ 16.373312]
Étape #30 A = [ 6.89866304]
Perte = [ 11.71054649]
Étape #35Un = [ 7.39849901]
Perte = [ 6.42773056]
Étape #40 A = [ 7.84618378]
Perte = [ 5.92940331]
Étape #45 A = [ 8.15709782]
Perte = [ 0 . 2142024]
Étape #50 A = [ 8.54818344]
Perte = [ 7.11651039]
Étape #55 A = [ 8.82354641]
Perte = [ 1.47823763]
Étape #60 A = [ .07896614 ]
Perte = [ 3.08244276]
Étape #65 A = [ 9.24868107]
Perte = [ 0.01143846]
Étape #70 A = [ 9.36772251]
Perte = [ ]
Étape #75 A = [ 9.49171734]
Perte = [ 3.90913701]
Étape #80 A = [ 9.6622715]
Perte = [ 4.80727625]
Étape #85 A = [ 9.73786926]
Perte = [ 0,39915398]
Étape n°90 A = [ 9,81853104]
Perte = [ 0,14876099]
Étape n°95 A = [ 9,90371323]
Perte = [ 0,01657014]
Étape n°10 0A = [ 9.86669159 ]
Perte = [ 0.444787]
Étape #5 A = [[ 2.34371352]]
Perte = 58.766
Étape #10 A = [[ 3.74766445]]
Perte = 38.48 75
Étape #15 A = [[ 4.88928795]]
Perte = 27.5632
Étape #20 A = [[ 5.82038736]]
Perte = 17.9523
Étape #25 A = [[ 6.58999157]]
Perte = 13,3245
Étape n°30 A = [[ 7,20851326]]
Perte = 8,68099
Étape n°35 A = [[ 7,71694899]]
Perte = 4,60659
Étape n°40 A = [[8.1296711]]
Perte = 4.70107
Étape #45 A = [[8.47107315]
Perte = 3.28318
Étape #50 A = [[8.74283409]]
Perte = 1.99057
Étape #55 A = [[ 8.98811722]]
Perte = 2.66906
Étape #60 A = [[ 9.18062305]]
Perte = 3.26207
Étape #65 A = [[ 9.3165 5025 ]]
Perte = 2,55459
Étape #70 A = [[ 9,43130589]]
Perte = 1,95839
Étape #75 A = [[ 9,55670166]]
Perte = 1,46504
Étape #80 A = [[ 9.6354847]]
Perte = 1.49021
Étape #85 A = [[ 9.73470974]]
Perte = 1.53289
Étape #90 A = [[ 9.77956581]]
Perte = 1,52173
Étape #95 A = [[ 9,83666706]]
Perte = 0,819207
Étape #100 A = [[ 9,85569191]]
Perte = 1,2197
| 训练类型 | 优点 | 缺点 |
|---|---|---|
| 随机训练 | 脱离局部最小 | 一般需更多次迭代才收敛 |
| 批量训练 | 快速得到最小损失 | 耗费更多计算资源 |
Recommandations associées :
Une brève discussion sur la sauvegarde et la restauration du modèle Tensorflow
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Tongyi Qianwen est à nouveau open source, Qwen1.5 propose six modèles de volume et ses performances dépassent GPT3.5
Feb 07, 2024 pm 10:15 PM
Tongyi Qianwen est à nouveau open source, Qwen1.5 propose six modèles de volume et ses performances dépassent GPT3.5
Feb 07, 2024 pm 10:15 PM
À temps pour la Fête du Printemps, la version 1.5 du modèle Tongyi Qianwen (Qwen) est en ligne. Ce matin, la nouvelle de la nouvelle version a attiré l'attention de la communauté IA. La nouvelle version du grand modèle comprend six tailles de modèle : 0,5B, 1,8B, 4B, 7B, 14B et 72B. Parmi eux, les performances de la version la plus puissante surpassent GPT3.5 et Mistral-Medium. Cette version inclut le modèle de base et le modèle Chat et fournit une prise en charge multilingue. L'équipe Tongyi Qianwen d'Alibaba a déclaré que la technologie pertinente avait également été lancée sur le site officiel de Tongyi Qianwen et sur l'application Tongyi Qianwen. De plus, la version actuelle de Qwen 1.5 présente également les points forts suivants : prend en charge une longueur de contexte de 32 Ko ; ouvre le point de contrôle du modèle Base+Chat ;
 Abandonnez l'architecture codeur-décodeur et utilisez le modèle de diffusion pour la détection des contours avec de meilleurs résultats. L'Université nationale de technologie de la défense a proposé DiffusionEdge.
Feb 07, 2024 pm 10:12 PM
Abandonnez l'architecture codeur-décodeur et utilisez le modèle de diffusion pour la détection des contours avec de meilleurs résultats. L'Université nationale de technologie de la défense a proposé DiffusionEdge.
Feb 07, 2024 pm 10:12 PM
Les réseaux actuels de détection des contours profonds adoptent généralement une architecture d'encodeur-décodeur, qui contient des modules d'échantillonnage ascendant et descendant pour mieux extraire les fonctionnalités à plusieurs niveaux. Cependant, cette structure limite le réseau à produire des résultats de détection de contour précis et détaillés. En réponse à ce problème, un article sur AAAI2024 propose une nouvelle solution. Titre de la thèse : DiffusionEdge : DiffusionProbabilisticModelforCrispEdgeDetection Auteurs : Ye Yunfan (Université nationale de technologie de la défense), Xu Kai (Université nationale de technologie de la défense), Huang Yuxing (Université nationale de technologie de la défense), Yi Renjiao (Université nationale de technologie de la défense), Cai Zhiping (Université nationale de technologie de la défense) Lien vers l'article : https ://ar
 Les grands modèles peuvent également être découpés, et Microsoft SliceGPT augmente considérablement l'efficacité de calcul de LAMA-2.
Jan 31, 2024 am 11:39 AM
Les grands modèles peuvent également être découpés, et Microsoft SliceGPT augmente considérablement l'efficacité de calcul de LAMA-2.
Jan 31, 2024 am 11:39 AM
Les grands modèles de langage (LLM) comportent généralement des milliards de paramètres et sont formés sur des milliards de jetons. Cependant, ces modèles sont très coûteux à former et à déployer. Afin de réduire les besoins de calcul, diverses techniques de compression de modèles sont souvent utilisées. Ces techniques de compression de modèles peuvent généralement être divisées en quatre catégories : distillation, décomposition tensorielle (y compris la factorisation de bas rang), élagage et quantification. Les méthodes d'élagage existent depuis un certain temps, mais beaucoup nécessitent un réglage fin de la récupération (RFT) après l'élagage pour maintenir les performances, ce qui rend l'ensemble du processus coûteux et difficile à faire évoluer. Des chercheurs de l'ETH Zurich et de Microsoft ont proposé une solution à ce problème appelée SliceGPT. L'idée principale de cette méthode est de réduire l'intégration du réseau en supprimant des lignes et des colonnes dans la matrice de pondération.
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
