

Cet article présente principalement la méthode Python de fusion de tous les fichiers PDF dans le même dossier, impliquant les compétences opérationnelles associées de Python pour lire, juger, déchiffrer, écrire et fusionner des fichiers PDF. Les amis qui en ont besoin peuvent s'y référer. 🎜>L'exemple de cet article décrit comment fusionner tous les fichiers PDF dans le même dossier en Python. Partagez-le avec tout le monde pour votre référence, les détails sont les suivants :
1. Description des exigencesJ'ai téléchargé le document pdf gratuit d'apprentissage en profondeur d'Andrew Ng depuis NetEase Cloud Classroom, mais chaque section est un PDF. Je mets ces documents PDF dans un dossier et j'espère les fusionner en un seul fichier PDF. J'ai donc écrit un programme python qui a très bien résolu ce problème.
2. Format des données
4. Implémentation du code Python
"D:Program FilesPython27python.exe" D :/PycharmProjects/learn2017/Fusionner plusieurs fichiers PDF.py
D:/course/C1W1L01 Welcome.pdf# -*- coding:utf-8*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import os
import os.path
from pyPdf import PdfFileReader,PdfFileWriter
import time
time1=time.time()
# 使用os模块walk函数,搜索出某目录下的全部pdf文件
######################获取同一个文件夹下的所有PDF文件名#######################
def getFileName(filepath):
file_list = []
for root,dirs,files in os.walk(filepath):
for filespath in files:
# print(os.path.join(root,filespath))
file_list.append(os.path.join(root,filespath))
return file_list
##########################合并同一个文件夹下所有PDF文件########################
def MergePDF(filepath,outfile):
output=PdfFileWriter()
outputPages=0
pdf_fileName=getFileName(filepath)
for each in pdf_fileName:
print each
# 读取源pdf文件
input = PdfFileReader(file(each, "rb"))
# 如果pdf文件已经加密,必须首先解密才能使用pyPdf
if input.isEncrypted == True:
input.decrypt("map")
# 获得源pdf文件中页面总数
pageCount = input.getNumPages()
outputPages += pageCount
print pageCount
# 分别将page添加到输出output中
for iPage in range(0, pageCount):
output.addPage(input.getPage(iPage))
print "All Pages Number:"+str(outputPages)
# 最后写pdf文件
outputStream=file(filepath+outfile,"wb")
output.write(outputStream)
outputStream.close()
print "finished"
if __name__ == '__main__':
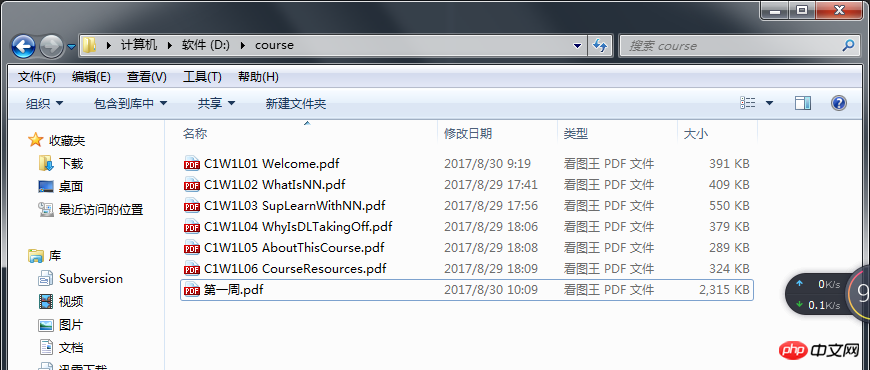
file_dir = r'D:/course/'
out=u"第一周.pdf"
MergePDF(file_dir,out)
time2 = time.time()
print u'总共耗时:' + str(time2 - time1) + 's'D:/course/C1W1L02 WhatIsNN.pdf
4D: / course/C1W1L03 SupLearnWithNN.pdf4
Méthode Python pour fusionner tous les fichiers txt dans le même dossier
D:/course/C1W1L04 WhyIsDLTakingOff.pdf
3
D:/course/C1W1L05 AboutThisCourse.pdf
3
D:/course / C1W1L06 CourseResources.pdf
3
Numéro de toutes les pages :20
terminé
Temps total pris : 0,128000020981s
Processus terminé avec le code de sortie 0
Recommandations associées :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



