

Cet article présente principalement les bases du traitement des données des pandas et des informations pertinentes sur le filtrage des données dans des lignes ou des colonnes spécifiées. Les amis dans le besoin peuvent s'y référer
Les deux principales structures de données des pandas sont : les séries ( équivalent à une structure de données dans une ligne ou une colonne) et DataFrame (équivalent à une structure de données tabulaire avec plusieurs lignes et colonnes).
Pour faciliter la compréhension, cet article fera une analogie avec les lignes ou colonnes d'exploitation Excel ou SQL
Réindexer : réindexer et ix
Comme introduit dans l'article précédent, l'index de ligne par défaut après la lecture des données est 0, 1, 2, 3... ces numéros de séquence. L'index de colonne est équivalent au nom du champ (c'est-à-dire que la première ligne de données signifie ici que vous pouvez remodifier l'index par défaut comme vous le souhaitez). Série 1.1Par exemple : data=Series([4,5,6],index=['a','b','c']), l'index de la ligne est une,b,c. Nous utilisons data.reindex(['a','c','d','e']) pour modifier l'index et le résultat est :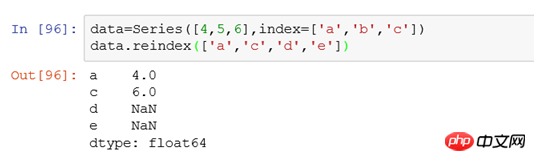
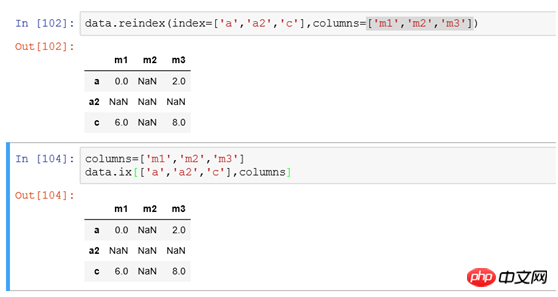
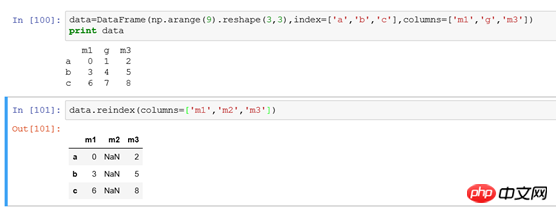 (3) Pour modifier les index de lignes et de colonnes en même temps, vous pouvez utiliser
(3) Pour modifier les index de lignes et de colonnes en même temps, vous pouvez utiliser
2. Déposez les colonnes sur le spécifié axe (en termes simples, supprimer des lignes ou des colonnes) :dropSélectionnez la ligne ou la colonne à supprimer par index
data.drop(['a','c']) 相当于delete table a where xid='a' or xid='c'
data.drop('m1',axis=1)相当于delete table a where yid='m1'
3. Sélection et filtrage (en termes simples, cela signifie filtrer les requêtes selon des conditions en SQL)Parce qu'il existe un index de ligne et de colonne en python, il sera plus pratique de filtrer les données
Série 3.1
(1) Sélectionnez en fonction de l'index de ligne tel que
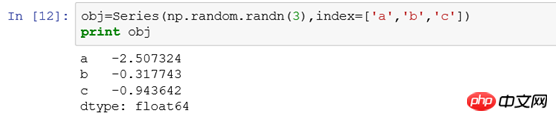 obj['b'] est équivalent à
obj['b'] est équivalent à
, et les résultats sont affichés dans l'ordre b, a, c C'est la différence avec sql La différence entre obj[. 0:1] et obj['a':'b'] est le suivant : select * from tb where xid='b'obj['b','a','c']select * from tb where xid in ('a','b','c')#Le premier n'inclut pas la fin, et le second inclut la fin
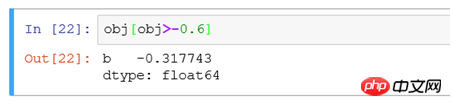
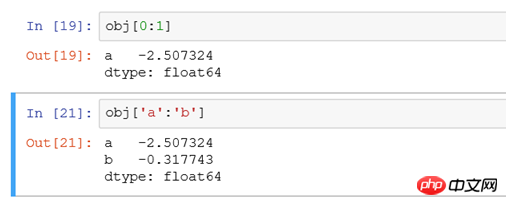 (2) Filtrer obj[obj>-0,6] en fonction de la taille de la valeur, ce qui équivaut aux données obj Rechercher les enregistrements avec une valeur supérieure à -0,6 pour l'affichage
(2) Filtrer obj[obj>-0,6] en fonction de la taille de la valeur, ce qui équivaut aux données obj Rechercher les enregistrements avec une valeur supérieure à -0,6 pour l'affichage
 3.2 DataFrame
3.2 DataFrame
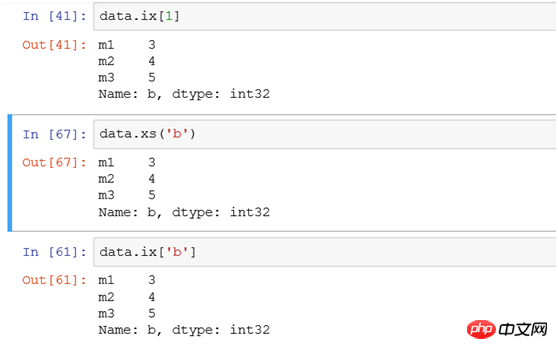
(1) Sélectionnez une seule ligne en utilisant ix ou xs :
Si vous filtrez l'enregistrement de ligne avec l'index b, utilisez les trois méthodes suivantes
 (2) Sélectionnez plusieurs lignes :
(2) Sélectionnez plusieurs lignes :
Filtrez l'index comme a, b La méthode d'enregistrement sur deux lignes
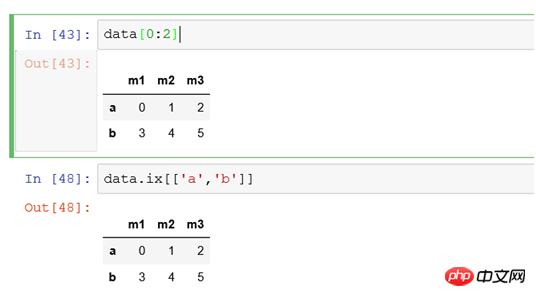 #Ce qui précède ne peut pas être écrit directement car data[['a','b']]
#Ce qui précède ne peut pas être écrit directement car data[['a','b']]
data[0:2 ] représente les enregistrements de la première ligne à la deuxième ligne. La première ligne commence à compter à partir de 0 par défaut, en excluant le 2 à la fin.
(3) Sélectionnez une seule colonne
Filtrez toutes les données d'enregistrement de ligne dans la colonne m1
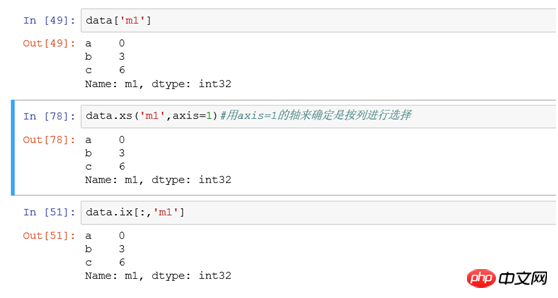 (4) Sélectionnez plusieurs colonnes
(4) Sélectionnez plusieurs colonnes
Filtrez les deux colonnes m1 et m3 et enregistrez les données dans toutes les lignes
 ix[:,['m1','m2']] devant of : signifie que toutes les lignes sont filtrées.
ix[:,['m1','m2']] devant of : signifie que toutes les lignes sont filtrées.
(5) Filtrer les lignes ou les colonnes en fonction de la condition de taille de la valeur
Par exemple, filtrer tous les enregistrements avec une valeur de colonne supérieure à 4 équivaut à sélectionner * from tb où colonne nom>4
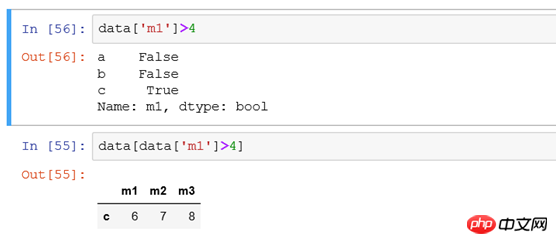
(6) Si vous filtrez tous les enregistrements avec une valeur de colonne supérieure à 4 et n'affichez que certaines colonnes
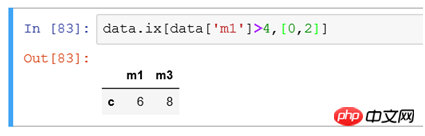
Utilisez les conditions pour filtrez les lignes et utilisez [0,2] pour filtrer les données dans les première et troisième colonnes
Recommandations associées :
python3 pandas pour lire les données MySQL et insérer
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mise à jour automatique de Windows
mise à jour automatique de Windows
 Solution à l'erreur de syntaxe lors de l'exécution de Python
Solution à l'erreur de syntaxe lors de l'exécution de Python
 Comment centrer la page Web dans Dreamweaver
Comment centrer la page Web dans Dreamweaver
 Comment Redis résout la cohérence des données
Comment Redis résout la cohérence des données
 Comment ouvrir php dans une page Web
Comment ouvrir php dans une page Web
 Que signifie la pièce MLM ? Combien de temps faut-il habituellement pour s'effondrer ?
Que signifie la pièce MLM ? Combien de temps faut-il habituellement pour s'effondrer ?
 Comment utiliser le curseur MySQL
Comment utiliser le curseur MySQL
 Comment démarrer le service SVN
Comment démarrer le service SVN








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



