

Cet article présente principalement des exemples d'utilisation de Python pour traiter MS Word. Maintenant, je le partage avec vous. Les amis dans le besoin peuvent s'y référer
Utiliser les outils Python pour lire et écrire MS. Fichiers Word (fichiers docx et doc), utilisant principalement le package python-docx. Cet article donne quelques opérations couramment utilisées et complète un exemple pour vous aider à démarrer rapidement.
Installation
pyhton doit utiliser le package python-docx pour traiter les fichiers docx. Il peut être facilement installé à l'aide de l'outil pip. L'outil pip est installé en python Dans le dossier Scripts sous le chemin
pip install python-docx
Bien entendu, vous pouvez également choisir d'utiliser easy_install ou l'installation manuelle
Écrire le contenu du fichier
Ici, nous donnons directement un exemple et extrayons le contenu utile en fonction de vos propres besoins
#coding=utf-8 from docx import Document from docx.shared import Pt from docx.shared import Inches from docx.oxml.ns import qn #打开文档 document = Document() #加入不同等级的标题 document.add_heading(u'MS WORD写入测试',0) document.add_heading(u'一级标题',1) document.add_heading(u'二级标题',2) #添加文本 paragraph = document.add_paragraph(u'我们在做文本测试!') #设置字号 run = paragraph.add_run(u'设置字号、') run.font.size = Pt(24) #设置字体 run = paragraph.add_run('Set Font,') run.font.name = 'Consolas' #设置中文字体 run = paragraph.add_run(u'设置中文字体、') run.font.name=u'宋体' r = run._element r.rPr.rFonts.set(qn('w:eastAsia'), u'宋体') #设置斜体 run = paragraph.add_run(u'斜体、') run.italic = True #设置粗体 run = paragraph.add_run(u'粗体').bold = True #增加引用 document.add_paragraph('Intense quote', style='Intense Quote') #增加无序列表 document.add_paragraph( u'无序列表元素1', style='List Bullet' ) document.add_paragraph( u'无序列表元素2', style='List Bullet' ) #增加有序列表 document.add_paragraph( u'有序列表元素1', style='List Number' ) document.add_paragraph( u'有序列表元素2', style='List Number' ) #增加图像(此处用到图像image.bmp,请自行添加脚本所在目录中) document.add_picture('image.bmp', width=Inches(1.25)) #增加表格 table = document.add_table(rows=1, cols=3) hdr_cells = table.rows[0].cells hdr_cells[0].text = 'Name' hdr_cells[1].text = 'Id' hdr_cells[2].text = 'Desc' #再增加3行表格元素 for i in xrange(3): row_cells = table.add_row().cells row_cells[0].text = 'test'+str(i) row_cells[1].text = str(i) row_cells[2].text = 'desc'+str(i) #增加分页 document.add_page_break() #保存文件 document.save(u'测试.docx')
Le style de document généré par ce code est le suivant

Remarque : j'ai un problème pas trouvé comment résoudre, c'est-à-dire comment le résoudre. Définir la limite du tableau. Si vous le savez, donnez-moi quelques conseils.
Lire le contenu du fichier
#coding=utf-8 from docx import Document #打开文档 document = Document(u'测试.docx') #读取每段资料 l = [ paragraph.text.encode('gb2312') for paragraph in document.paragraphs]; #输出并观察结果,也可以通过其他手段处理文本即可 for i in l: print i #读取表格材料,并输出结果 tables = [table for table in document.tables]; for table in tables: for row in table.rows: for cell in row.cells: print cell.text.encode('gb2312'),'\t', print print '\n'
Nous utilisons toujours le fichier que nous venons de générer fichier, vous pouvez voir que le résultat de sortie est
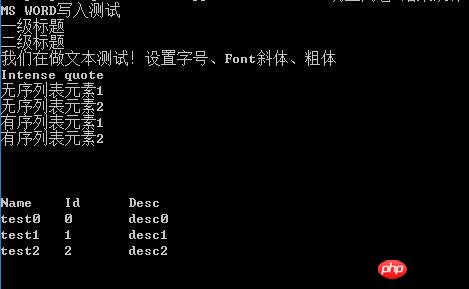
Remarque : Ici, nous utilisons l'encodage gb2312 pour lire, principalement c'est pour s'assurer que la lecture et l'écriture chinoises sont correctes. Généralement, le codage UTF-8 est utilisé. De plus, python-docx traite principalement les fichiers docx. Des problèmes peuvent survenir lors du chargement des fichiers doc. S'il existe un grand nombre de fichiers doc, il est recommandé de convertir d'abord par lots les fichiers doc en fichiers docx, par exemple en utilisant l'outil doc2doc<.>
Recommandations associées :Introduction à la méthode de traitement Python Excel xlrd
Explication détaillée d'exemples de traitement Python de fichiers CSV
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 outils de développement Python
outils de développement Python
 python emballé dans un fichier exécutable
python emballé dans un fichier exécutable
 Comment changer la couleur d'arrière-plan d'un mot en blanc
Comment changer la couleur d'arrière-plan d'un mot en blanc
 Comment supprimer la dernière page vierge dans Word
Comment supprimer la dernière page vierge dans Word
 ce que python peut faire
ce que python peut faire
 Pourquoi ne puis-je pas supprimer la dernière page vierge de Word ?
Pourquoi ne puis-je pas supprimer la dernière page vierge de Word ?
 Une seule page Word change l'orientation du papier
Une seule page Word change l'orientation du papier
 Comment utiliser le format en python
Comment utiliser le format en python








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



