
Cette fois, je vais vous apporter une explication détaillée des étapes pour implémenter l'encodage/décodage Huffman en PHP. Quelles sont les précautions pour implémenter l'encodage/décodage Huffman en PHP. Voici des cas réels, prenons. un regard.
Cet article utilisera PHP pour pratiquer l'encodage et le décodage Huffman.
1. Encodage
Nombre de mots
La première étape de l'encodage Huffman consiste à compter l'occurrence de chaque caractère dans les heures du document, la fonction intégrée count_chars() de PHP peut faire :
$input = file_get_contents('input.txt'); $stat = count_chars($input, 1);
Construire un arbre de Huffman
Ensuite, l'arbre de Huffman est construit sur la base des résultats statistiques La méthode de construction est décrite en détail dans Wikipédia. Voici une version simple écrite en PHP :
$huffmanTree = [];
foreach ($stat as $char => $count) {
$huffmanTree[] = [
'k' => chr($char),
'v' => $count,
'left' => null,
'right' => null,
];
}
// 构造树的层级关系,思想见wiki:https://zh.wikipedia.org/wiki/%E9%9C%8D%E5%A4%AB%E6%9B%BC%E7%BC%96%E7%A0%81
$size = count($huffmanTree);
for ($i = 0; $i !== $size - 1; $i++) {
uasort($huffmanTree, function ($a, $b) {
if ($a['v'] === $b['v']) {
return 0;
}
return $a['v'] < $b['v'] ? -1 : 1;
});
$a = array_shift($huffmanTree);
$b = array_shift($huffmanTree);
$huffmanTree[] = [
'v' => $a['v'] + $b['v'],
'left' => $b,
'right' => $a,
];
}
$root = current($huffmanTree);Après calcul, $root pointera vers le nœud racine de l'arbre de Huffman
Générer un dictionnaire de codage basé sur l'arbre de Huffman arbre
Avec l'arbre de Huffman, vous pouvez générer un dictionnaire pour encoder :
function buildDict($elem, $code = '', &$dict) {
if (isset($elem['k'])) {
$dict[$elem['k']] = $code;
} else {
buildDict($elem['left'], $code.'0', $dict);
buildDict($elem['right'], $code.'1', $dict);
}
}
$dict = [];
buildDict($root, '', $dict);Écrire un fichier
Utiliser le dictionnaire pour encoder le contenu du fichier Encoder et écrire dans le fichier. Il y a plusieurs choses à prendre en compte lors de l'écriture de l'encodage Huffman dans un fichier :
Après avoir écrit le dictionnaire d'encodage et encodé le contenu ensemble dans le fichier, il est impossible de distinguer leurs limites, ils doivent donc être écrits à le début du fichier. Nombre d'octets occupés
La fonction fwrite() fournie par PHP peut écrire 8 bits (un octet) ou un multiple entier de 8 bits à la fois. Cependant, dans le codage Huffman, un caractère peut être représenté par seulement 1 bit, et PHP ne prend pas en charge l'opération d'écriture d'un seul bit dans le fichier. Par conséquent, nous devons épisser l’encodage nous-mêmes et écrire le fichier uniquement après l’obtention de 8 bits.
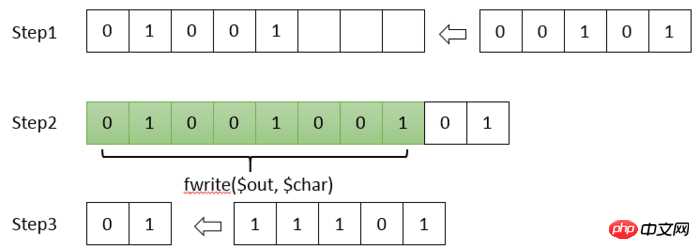
Écrivez toutes les données de 8 bits.
Semblable au deuxième élément, la taille finale du fichier doit être un multiple entier de 8 bits. Ainsi, si la taille de l'encodage total est de 8001 bits, il faut ajouter 7 0 à la fin
$dictString = serialize($dict);
// 写入字典和编码各自占用的字节数
$header = pack('VV', strlen($dictString), strlen($input));
fwrite($outFile, $header);
// 写入字典本身
fwrite($outFile, $dictString);
// 写入编码的内容
$buffer = '';
$i = 0;
while (isset($input[$i])) {
$buffer .= $dict[$input[$i]];
while (isset($buffer[7])) {
$char = bindec(substr($buffer, 0, 8));
fwrite($outFile, chr($char));
$buffer = substr($buffer, 8);
}
$i++;
}
// 末尾的内容如果没有凑齐 8-bit,需要自行补齐
if (!empty($buffer)) {
$char = bindec(str_pad($buffer, 8, '0'));
fwrite($outFile, chr($char));
}
fclose($outFile);Décodage
Le décodage de l'encodage Huffman est relativement simple : Lisez d'abord le dictionnaire de codage, puis décodez les caractères originaux selon le dictionnaire.
Il y a un problème qui doit être noté lors du processus de décodage : comme nous avons ajouté plusieurs bits 0 à la fin du fichier lors du processus d'encodage, si ces bits 0 s'avèrent être l'encodage de un certain caractère dans le dictionnaire, cela entraînera un décodage incorrect.
Ainsi, pendant le processus de décodage, lorsque le nombre de caractères décodés atteint la longueur du document, le décodage s'arrêtera.
<?php
$content = file_get_contents('a.out');
// 读出字典长度和编码内容长度
$header = unpack('VdictLen/VcontentLen', $content);
$dict = unserialize(substr($content, 8, $header['dictLen']));
$dict = array_flip($dict);
$bin = substr($content, 8 + $header['dictLen']);
$output = '';
$key = '';
$decodedLen = 0;
$i = 0;
while (isset($bin[$i]) && $decodedLen !== $header['contentLen']) {
$bits = decbin(ord($bin[$i]));
$bits = str_pad($bits, 8, '0', STR_PAD_LEFT);
for ($j = 0; $j !== 8; $j++) {
// 每拼接上 1-bit,就去与字典比对是否能解码出字符
$key .= $bits[$j];
if (isset($dict[$key])) {
$output .= $dict[$key];
$key = '';
$decodedLen++;
if ($decodedLen === $header['contentLen']) {
break;
}
}
}
$i++;
}
echo $output;Test
Nous avons enregistré le code HTML de la page Wiki de codage Huffman localement et effectué le test de codage Huffman. Les résultats du test :
Avant encodage : 418 504 octetsAprès encodage : 280 127 octetsL'espace est économisé de 33 %. Si le texte original a beaucoup de contenu répété, l'espace enregistré par l'encodage Huffman peut atteindre plus de 50 %.En plus du contenu textuel, nous essayons d'encoder Huffman un fichier binaire, tel que le programme d'installation f.lux. Les résultats des tests sont les suivants :
Avant encodage : 770,384 Octet après encodage : 773,076 Octetaprès encodage prend plus de place D'une part, c'est parce que quand on. stocker le dictionnaire, aucun traitement supplémentaire n'est effectué. En revanche, dans les fichiers binaires, la probabilité d'apparition de chaque caractère est relativement égale et les avantages du codage de Huffman ne peuvent pas être utilisés. Je pense que vous maîtrisez la méthode après avoir lu le cas dans cet article. Pour des informations plus intéressantes, veuillez prêter attention aux autres articles connexes sur le site Web chinois de php ! Lecture recommandée :
Explication détaillée des étapes d'utilisation de l'algorithme de tri rapide PHP
Explication détaillée de l'itérateur étapes implémentées par PHP basées sur SPL
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment ouvrir le fichier php
Comment ouvrir le fichier php
 Comment supprimer les premiers éléments d'un tableau en php
Comment supprimer les premiers éléments d'un tableau en php
 Que faire si la désérialisation php échoue
Que faire si la désérialisation php échoue
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Comment télécharger du HTML
Comment télécharger du HTML
 Comment résoudre les caractères tronqués en PHP
Comment résoudre les caractères tronqués en PHP
 Comment ouvrir des fichiers php sur un téléphone mobile
Comment ouvrir des fichiers php sur un téléphone mobile








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



