
 interface Web
js tutoriel
Méthode de mise en œuvre du serveur de ressources statiques Node manuscrit
interface Web
js tutoriel
Méthode de mise en œuvre du serveur de ressources statiques Node manuscrit
Méthode de mise en œuvre du serveur de ressources statiques Node manuscrit
Cet article présente principalement la méthode d'implémentation du serveur de ressources statiques Node manuscrit. Maintenant, je le partage avec vous et le donne comme référence.
Si nous voulons écrire un serveur de ressources statiques, nous devons d'abord savoir comment créer un serveur http et quel est son principe
Le serveur http est hérité du serveur TCP. Le protocole http est un protocole de couche application et est basé sur TCP. Le principe de
http est de regrouper la requête et la réponse. Lorsque le client se connecte, l'événement de connexion est déclenché en premier, puis la requête. peut être envoyé plusieurs fois. Chaque requête déclenchera l'événement de requête
let server = http.createServer();
let url = require('url');
server.on('connection', function (socket) {
console.log('客户端连接 ');
});
server.on('request', function (req, res) {
let { pathname, query } = url.parse(req.url, true);
let result = [];
req.on('data', function (data) {
result.push(data);
});
req.on('end', function () {
let r = Buffer.concat(result);
res.end(r);
})
});
server.on('close', function (req, res) {
console.log('服务器关闭 ');
});
server.on('error', function (err) {
console.log('服务器错误 ');
});
server.listen(8080, function () {
console.log('server started at http://localhost:8080');
});req représente la connexion du client. les informations sur la demande du client et les met sur req
res représente la réponse Si vous souhaitez répondre au client, vous devez transmettre res
. req et res proviennent tous deux du socket. Écoutez d'abord l'événement de données du socket, puis lorsque l'événement se produit, analysez-le, analysez l'objet d'en-tête de requête, créez l'objet de requête, puis créez l'objet de réponse basé sur l'objet de la requête
req.url Obtenir le chemin de la requête
req.headers objet d'en-tête de requête
Ensuite, nous expliquerons quelques fonctions de base
Compréhension approfondie et réaliser la compression et la décompression
Pourquoi compresser ? Quels sont les avantages ?
Vous pouvez utiliser le module zlib pour le traitement de compression et de décompression. Après avoir compressé le fichier, vous pouvez réduire la taille, accélérer la vitesse de transmission et économiser la bande passante.
Les objets de compression et de décompression sont des flux de conversion de transformation, hérités du flux duplex duplex, qui est un flux lisible et inscriptible- zlib.createGzip : renvoie l'objet flux Gzip et utilise le Algorithme Gzip pour compresser les données
- zlib.createGunzip : Renvoie l'objet flux Gzip, utilise l'algorithme Gzip pour décompresser les données compressées
- zlib .createDeflate : renvoie l'objet de flux Deflate, utilise Deflate L'algorithme compresse les données
- zlib.createInflate : renvoie l'objet de flux Deflate et utilise l'algorithme Deflate pour décompresser les données
Implémenter la compression et la décompression
Étant donné que le fichier compressé peut être volumineux ou petit, afin d'améliorer la vitesse de traitement, nous utilisons des flux pour y parvenirlet fs = require("fs");
let path = require("path");
let zlib = require("zlib");
function gzip(src) {
fs
.createReadStream(src)
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream(src + ".gz"));
}
gzip(path.join(__dirname,'msg.txt'));
function gunzip(src) {
fs
.createReadStream(src)
.pipe(zlib.createGunzip())
.pipe(
fs.createWriteStream(path.join(__dirname, path.basename(src, ".gz")))
);
}
gunzip(path.join(__dirname, "msg.txt.gz"));- la méthode gzip est utilisée pour implémenter la compression
- la méthode gunzip est utilisée pour implémenter décompression
- Le fichier msg.txt est un répertoire du même niveau
- Pourquoi faut-il écrire ceci : gzip(path.join (__dirname,'msg.txt'));
- Parce que console.log(process.cwd()); où se trouve le fichier. Si vous écrivez gzip('msg.txt'); comme ceci et que vous ne trouvez pas le fichier, une erreur sera signalée. basename obtient le nom du fichier. un chemin, incluant l'extension, vous pouvez passer un paramètre d'extension et supprimer l'extension
- extname obtient l'extension
- Le format compressé et le format décompressé doit correspondre, sinon une erreur sera signalée
- Parfois, la chaîne que nous obtenons n'est pas la même Stream, comment la résoudre
let zlib=require('zlib');
let str='hello';
zlib.gzip(str,(err,buffer)=>{
console.log(buffer.length);
zlib.unzip(buffer,(err,data)=>{
console.log(data.toString());
})
});L'effet de la compression du texte sera meilleur, car. il y a des règles
Ce qui suit implémente une telle fonction, comme indiqué dans la figure :
Lorsque le client initie une requête au serveur, il indiquera au serveur le format de décompression que je prends en charge via accept-encoding (par exemple : Accept-Encoding:gzip,default)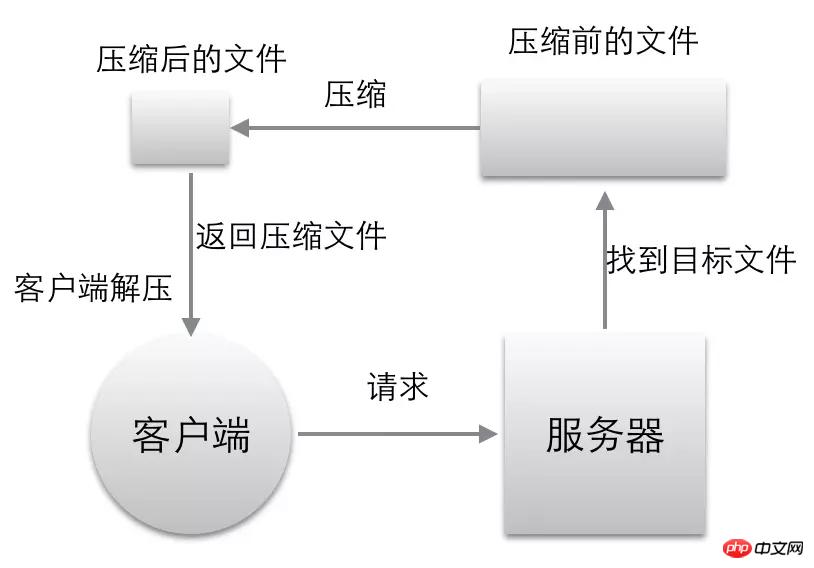
- Si le client Le serveur n'en a pas. le format dans Accept-Encoding dont le client a besoin et ne peut pas réaliser la compression
let http = require("http");
let path = require("path");
let url = require("url");
let zlib = require("zlib");
let fs = require("fs");
let { promisify } = require("util");
let mime = require("mime");
//把一个异步方法转成一个返回promise的方法
let stat = promisify(fs.stat);
http.createServer(request).listen(8080);
async function request(req, res) {
let { pathname } = url.parse(req.url);
let filepath = path.join(__dirname, pathname);
// fs.stat(filepath,(err,stat)=>{});现在不这么写了,异步的处理起来比较麻烦
try {
let statObj = await stat(filepath);
res.setHeader("Content-Type", mime.getType(pathname));
let acceptEncoding = req.headers["accept-encoding"];
if (acceptEncoding) {
if (acceptEncoding.match(/\bgzip\b/)) {
res.setHeader("Content-Encoding", "gzip");
fs
.createReadStream(filepath)
.pipe(zlib.createGzip())
.pipe(res);
} else if (acceptEncoding.match(/\bdeflate\b/)) {
res.setHeader("Content-Encoding", "deflate");
fs
.createReadStream(filepath)
.pipe(zlib.createDeflate())
.pipe(res);
} else {
fs.createReadStream(filepath).pipe(res);
}
} else {
fs.createReadStream(filepath).pipe(res);
}
} catch (e) {
res.statusCode = 404;
res.end("Not Found");
}
}- acceptEncoding : tous écrits en minuscules pour des raisons de compatibilité avec différents In. le navigateur, le nœud convertit tous les en-têtes de requête en minuscules
- filepath : obtenez le chemin absolu du fichier
- Après avoir démarré le service, visitez http ://localhost:8080/msg.txt pour voir les résultats
- Comprendre en profondeur et mettre en œuvre la mise en cache
Pourquoi avez-vous besoin de mettre en cache ? Quels sont les avantages de la mise en cache ?
Réduit la transmission de données redondante et économise les frais de réseau.- Réduit la charge sur le serveur et améliore considérablement les performances du site Web
- Accélére la vitesse de chargement des pages Web sur le client
- Catégories de mise en cache
Mise en cache forcée :
强制缓存,在缓存数据未失效的情况下,可以直接使用缓存数据
在没有缓存数据的时候,浏览器向服务器请求数据时,服务器会将数据和缓存规则一并返回,缓存规则信息包含在响应header中


对比缓存:
浏览器第一次请求数据时,服务器会将缓存标识与数据一起返回给客户端,客户端将二者备份至缓存数据库中
再次请求数据时,客户端将备份的缓存标识发送给服务器,服务器根据缓存标识进行判断,判断成功后,返回304状态码,通知客户端比较成功,可以使用缓存数据
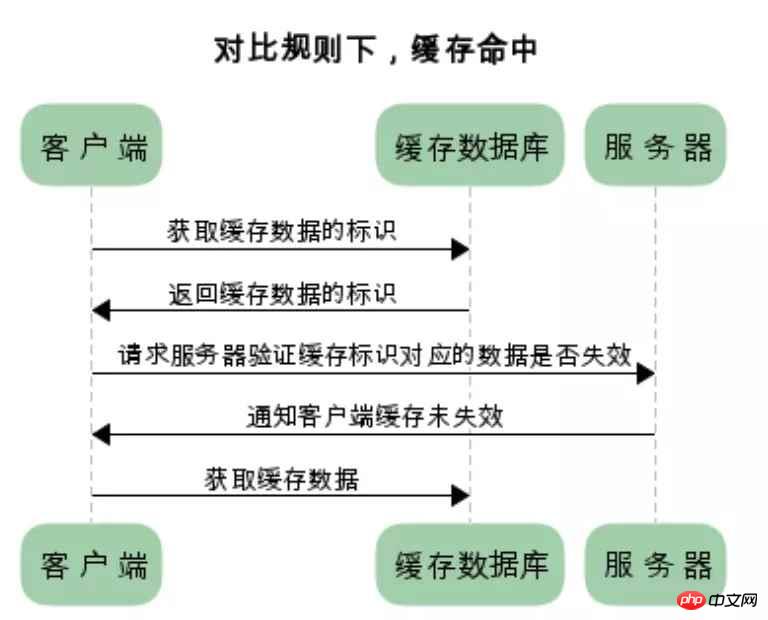
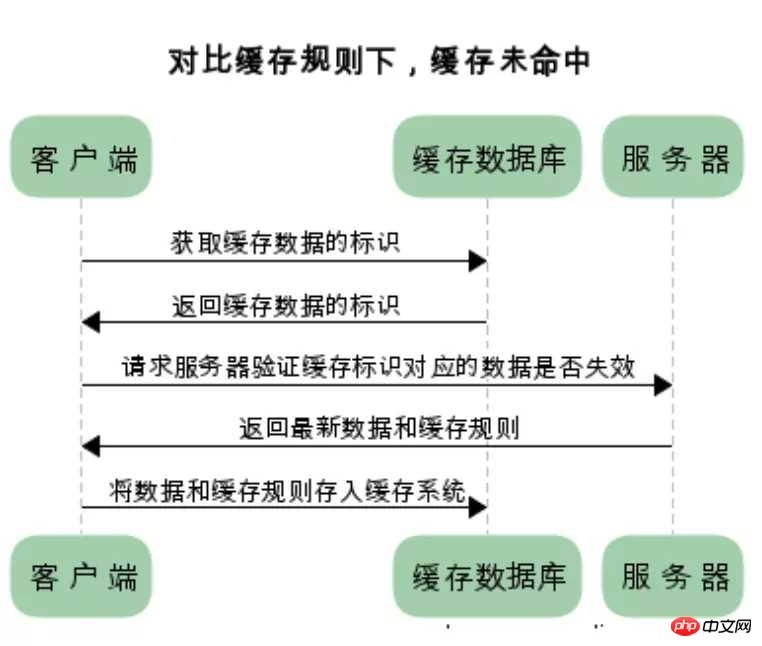
两类缓存的区别和联系
强制缓存如果生效,不需要再和服务器发生交互,而对比缓存不管是否生效,都需要与服务端发生交互
两类缓存规则可以同时存在,强制缓存优先级高于对比缓存,也就是说,当执行强制缓存的规则时,如果缓存生效,直接使用缓存,不再执行对比缓存规则
实现对比缓存
实现对比缓存一般是按照以下步骤:
第一次访问服务器的时候,服务器返回资源和缓存的标识,客户端则会把此资源缓存在本地的缓存数据库中。
第二次客户端需要此数据的时候,要取得缓存的标识,然后去问一下服务器我的资源是否是最新的。
如果是最新的则直接使用缓存数据,如果不是最新的则服务器返回新的资源和缓存规则,客户端根据缓存规则缓存新的数据
实现对比缓存一般有两种方式
通过最后修改时间来判断缓存是否可用
let http = require('http');
let url = require('url');
let path = require('path');
let fs = require('fs');
let mime = require('mime');
// http://localhost:8080/index.html
http.createServer(function (req, res) {
let { pathname } = url.parse(req.url, true);
//D:\vipcode\201801\20.cache\index.html
let filepath = path.join(__dirname, pathname);
fs.stat(filepath, (err, stat) => {
if (err) {
return sendError(req, res);
} else {
let ifModifiedSince = req.headers['if-modified-since'];
let LastModified = stat.ctime.toGMTString();
if (ifModifiedSince == LastModified) {
res.writeHead(304);
res.end('');
} else {
return send(req, res, filepath, stat);
}
}
});
}).listen(8080);
function sendError(req, res) {
res.end('Not Found');
}
function send(req, res, filepath, stat) {
res.setHeader('Content-Type', mime.getType(filepath));
//发给客户端之后,客户端会把此时间保存起来,下次再获取此资源的时候会把这个时间再发回服务器
res.setHeader('Last-Modified', stat.ctime.toGMTString());
fs.createReadStream(filepath).pipe(res);
}这种方式有很多缺陷
某些服务器不能精确得到文件的最后修改时间, 这样就无法通过最后修改时间来判断文件是否更新了
某些文件的修改非常频繁,在秒以下的时间内进行修改.Last-Modified只能精确到秒。
一些文件的最后修改时间改变了,但是内容并未改变。 我们不希望客户端认为这个文件修改了
如果同样的一个文件位于多个CDN服务器上的时候内容虽然一样,修改时间不一样
ETag
ETag是根据实体内容生成的一段hash字符串,可以标识资源的状态
资源发生改变时,ETag也随之发生变化。 ETag是Web服务端产生的,然后发给浏览器客户端
let http = require('http');
let url = require('url');
let path = require('path');
let fs = require('fs');
let mime = require('mime');
let crypto = require('crypto');
http.createServer(function (req, res) {
let { pathname } = url.parse(req.url, true);
let filepath = path.join(__dirname, pathname);
fs.stat(filepath, (err, stat) => {
if (err) {
return sendError(req, res);
} else {
let ifNoneMatch = req.headers['if-none-match'];
let out = fs.createReadStream(filepath);
let md5 = crypto.createHash('md5');
out.on('data', function (data) {
md5.update(data);
});
out.on('end', function () {
let etag = md5.digest('hex');
let etag = `${stat.size}`;
if (ifNoneMatch == etag) {
res.writeHead(304);
res.end('');
} else {
return send(req, res, filepath, etag);
}
});
}
});
}).listen(8080);
function sendError(req, res) {
res.end('Not Found');
}
function send(req, res, filepath, etag) {
res.setHeader('Content-Type', mime.getType(filepath));
res.setHeader('ETag', etag);
fs.createReadStream(filepath).pipe(res);
}客户端想判断缓存是否可用可以先获取缓存中文档的ETag,然后通过If-None-Match发送请求给Web服务器询问此缓存是否可用。
服务器收到请求,将服务器的中此文件的ETag,跟请求头中的If-None-Match相比较,如果值是一样的,说明缓存还是最新的,Web服务器将发送304 Not Modified响应码给客户端表示缓存未修改过,可以使用。
如果不一样则Web服务器将发送该文档的最新版本给浏览器客户端
实现强制缓存
把资源缓存在客户端,如果客户端再次需要此资源的时候,先获取到缓存中的数据,看是否过期,如果过期了。再请求服务器
如果没过期,则根本不需要向服务器确认,直接使用本地缓存即可
let http = require('http');
let url = require('url');
let path = require('path');
let fs = require('fs');
let mime = require('mime');
let crypto = require('crypto');
http.createServer(function (req, res) {
let { pathname } = url.parse(req.url, true);
let filepath = path.join(__dirname, pathname);
console.log(filepath);
fs.stat(filepath, (err, stat) => {
if (err) {
return sendError(req, res);
} else {
send(req, res, filepath);
}
});
}).listen(8080);
function sendError(req, res) {
res.end('Not Found');
}
function send(req, res, filepath) {
res.setHeader('Content-Type', mime.getType(filepath));
res.setHeader('Expires', new Date(Date.now() + 30 * 1000).toUTCString());
res.setHeader('Cache-Control', 'max-age=30');
fs.createReadStream(filepath).pipe(res);
}浏览器会将文件缓存到Cache目录,第二次请求时浏览器会先检查Cache目录下是否含有该文件,如果有,并且还没到Expires设置的时间,即文件还没有过期,那么此时浏览器将直接从Cache目录中读取文件,而不再发送请求
Expires是服务器响应消息头字段,在响应http请求时告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据
Cache-Control与Expires的作用一致,都是指明当前资源的有效期,控制浏览器是否直接从浏览器缓存取数据还是重新发请求到服务器取数据,如果同时设置的话,其优先级高于Expires
下面开始写静态服务器
首先创建一个http服务,配置监听端口
let http = require('http');
let server = http.createServer();
server.on('request', this.request.bind(this));
server.listen(this.config.port, () => {
let url = `http://${this.config.host}:${this.config.port}`;
debug(`server started at ${chalk.green(url)}`);
});下面写个静态文件服务器
先取到客户端想说的文件或文件夹路径,如果是目录的话,应该显示目录下面的文件列表
async request(req, res) {
let { pathname } = url.parse(req.url);
if (pathname == '/favicon.ico') {
return this.sendError('not found', req, res);
}
let filepath = path.join(this.config.root, pathname);
try {
let statObj = await stat(filepath);
if (statObj.isDirectory()) {
let files = await readdir(filepath);
files = files.map(file => ({
name: file,
url: path.join(pathname, file)
}));
let html = this.list({
title: pathname,
files
});
res.setHeader('Content-Type', 'text/html');
res.end(html);
} else {
this.sendFile(req, res, filepath, statObj);
}
} catch (e) {
debug(inspect(e));
this.sendError(e, req, res);
}
}
sendFile(req, res, filepath, statObj) {
if (this.handleCache(req, res, filepath, statObj)) return;
res.setHeader('Content-Type', mime.getType(filepath) + ';charset=utf-8');
let encoding = this.getEncoding(req, res);
let rs = this.getStream(req, res, filepath, statObj);
if (encoding) {
rs.pipe(encoding).pipe(res);
} else {
rs.pipe(res);
}
}支持断点续传
getStream(req, res, filepath, statObj) {
let start = 0;
let end = statObj.size - 1;
let range = req.headers['range'];
if (range) {
res.setHeader('Accept-Range', 'bytes');
res.statusCode = 206;
let result = range.match(/bytes=(\d*)-(\d*)/);
if (result) {
start = isNaN(result[1]) ? start : parseInt(result[1]);
end = isNaN(result[2]) ? end : parseInt(result[2]) - 1;
}
}
return fs.createReadStream(filepath, {
start, end
});
}支持对比缓存,通过etag的方式
handleCache(req, res, filepath, statObj) {
let ifModifiedSince = req.headers['if-modified-since'];
let isNoneMatch = req.headers['is-none-match'];
res.setHeader('Cache-Control', 'private,max-age=30');
res.setHeader('Expires', new Date(Date.now() + 30 * 1000).toGMTString());
let etag = statObj.size;
let lastModified = statObj.ctime.toGMTString();
res.setHeader('ETag', etag);
res.setHeader('Last-Modified', lastModified);
if (isNoneMatch && isNoneMatch != etag) {
return fasle;
}
if (ifModifiedSince && ifModifiedSince != lastModified) {
return fasle;
}
if (isNoneMatch || ifModifiedSince) {
res.writeHead(304);
res.end();
return true;
} else {
return false;
}
}支持文件压缩
getEncoding(req, res) {
let acceptEncoding = req.headers['accept-encoding'];
if (/\bgzip\b/.test(acceptEncoding)) {
res.setHeader('Content-Encoding', 'gzip');
return zlib.createGzip();
} else if (/\bdeflate\b/.test(acceptEncoding)) {
res.setHeader('Content-Encoding', 'deflate');
return zlib.createDeflate();
} else {
return null;
}
}编译模板,得到一个渲染的方法,然后传入实际数据数据就可以得到渲染后的HTML了
function list() {
let tmpl = fs.readFileSync(path.resolve(__dirname, 'template', 'list.html'), 'utf8');
return handlebars.compile(tmpl);
}这样一个简单的静态服务器就完成了,其中包含了静态文件服务,实现缓存,实现断点续传,分块获取,实现压缩的功能
上面是我整理给大家的,希望今后会对大家有帮助。
相关文章:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Comment résoudre le problème selon lequel la recherche eMule ne peut pas se connecter au serveur
Jan 25, 2024 pm 02:45 PM
Comment résoudre le problème selon lequel la recherche eMule ne peut pas se connecter au serveur
Jan 25, 2024 pm 02:45 PM
Solution : 1. Vérifiez les paramètres d'eMule pour vous assurer que vous avez entré l'adresse du serveur et le numéro de port corrects ; 2. Vérifiez la connexion réseau, assurez-vous que l'ordinateur est connecté à Internet et réinitialisez le routeur ; est en ligne. Si vos paramètres sont S'il n'y a pas de problème avec la connexion réseau, vous devez vérifier si le serveur est en ligne ; 4. Mettez à jour la version d'eMule, visitez le site officiel d'eMule et téléchargez la dernière version du logiciel eMule ; 5. Demandez de l'aide.
 Solution à l'impossibilité de se connecter au serveur RPC et à l'impossibilité d'accéder au bureau
Feb 18, 2024 am 10:34 AM
Solution à l'impossibilité de se connecter au serveur RPC et à l'impossibilité d'accéder au bureau
Feb 18, 2024 am 10:34 AM
Que dois-je faire si le serveur RPC est indisponible et n'est pas accessible sur le bureau Ces dernières années, les ordinateurs et Internet ont pénétré tous les recoins de nos vies. En tant que technologie de calcul centralisé et de partage de ressources, l'appel de procédure à distance (RPC) joue un rôle essentiel dans la communication réseau. Cependant, nous pouvons parfois rencontrer une situation dans laquelle le serveur RPC n'est pas disponible, ce qui entraîne l'impossibilité d'accéder au bureau. Cet article décrit certaines des causes possibles de ce problème et propose des solutions. Tout d’abord, nous devons comprendre pourquoi le serveur RPC n’est pas disponible. Le serveur RPC est un
 Explication détaillée du fusible d'installation CentOS et du serveur d'installation CentOS
Feb 13, 2024 pm 08:40 PM
Explication détaillée du fusible d'installation CentOS et du serveur d'installation CentOS
Feb 13, 2024 pm 08:40 PM
En tant qu'utilisateur LINUX, nous devons souvent installer divers logiciels et serveurs sur CentOS. Cet article présentera en détail comment installer Fuse et configurer un serveur sur CentOS pour vous aider à effectuer les opérations associées en douceur. Installation de CentOS fuseFuse est un cadre de système de fichiers en espace utilisateur qui permet aux utilisateurs non privilégiés d'accéder et de faire fonctionner le système de fichiers via un système de fichiers personnalisé. L'installation de Fuse sur CentOS est très simple, suivez simplement les étapes suivantes : 1. Ouvrez le terminal et connectez-vous en tant que. utilisateur root. 2. Utilisez la commande suivante pour installer le package fuse : ```yuminstallfuse3. Confirmez les invites pendant le processus d'installation et entrez `y` pour continuer. 4. Installation terminée
 Comment configurer Dnsmasq comme serveur relais DHCP
Mar 21, 2024 am 08:50 AM
Comment configurer Dnsmasq comme serveur relais DHCP
Mar 21, 2024 am 08:50 AM
Le rôle d'un relais DHCP est de transmettre les paquets DHCP reçus vers un autre serveur DHCP du réseau, même si les deux serveurs se trouvent sur des sous-réseaux différents. En utilisant un relais DHCP, vous pouvez déployer un serveur DHCP centralisé dans le centre réseau et l'utiliser pour attribuer dynamiquement des adresses IP à tous les sous-réseaux/VLAN du réseau. Dnsmasq est un serveur de protocole DNS et DHCP couramment utilisé qui peut être configuré en tant que serveur relais DHCP pour faciliter la gestion des configurations d'hôtes dynamiques sur le réseau. Dans cet article, nous allons vous montrer comment configurer Dnsmasq comme serveur relais DHCP. Sujets de contenu : Topologie du réseau Configuration d'adresses IP statiques sur un relais DHCP D sur un serveur DHCP centralisé
 Guide des meilleures pratiques pour créer des serveurs proxy IP avec PHP
Mar 11, 2024 am 08:36 AM
Guide des meilleures pratiques pour créer des serveurs proxy IP avec PHP
Mar 11, 2024 am 08:36 AM
Dans la transmission de données sur réseau, les serveurs proxy IP jouent un rôle important, aidant les utilisateurs à masquer leurs véritables adresses IP, à protéger la confidentialité et à améliorer la vitesse d'accès. Dans cet article, nous présenterons le guide des meilleures pratiques sur la façon de créer un serveur proxy IP avec PHP et fournirons des exemples de code spécifiques. Qu'est-ce qu'un serveur proxy IP ? Un serveur proxy IP est un serveur intermédiaire situé entre l'utilisateur et le serveur cible. Il agit comme une station de transfert entre l'utilisateur et le serveur cible, transmettant les demandes et les réponses de l'utilisateur. En utilisant un serveur proxy IP
 Que dois-je faire si je ne peux pas accéder au jeu lorsque le serveur Epic est hors ligne ? Solution pour laquelle Epic ne peut pas accéder au jeu hors ligne
Mar 13, 2024 pm 04:40 PM
Que dois-je faire si je ne peux pas accéder au jeu lorsque le serveur Epic est hors ligne ? Solution pour laquelle Epic ne peut pas accéder au jeu hors ligne
Mar 13, 2024 pm 04:40 PM
Que dois-je faire si je ne peux pas accéder au jeu lorsque le serveur Epic est hors ligne ? Ce problème a dû être rencontré par de nombreux amis. Lorsque cette invite apparaît, le jeu authentique ne peut pas être démarré. Ce problème est généralement dû à des interférences du réseau et du logiciel de sécurité. Alors, comment doit-il être résolu ? J'aimerais partager la solution avec vous, j'espère que le didacticiel logiciel d'aujourd'hui pourra vous aider à résoudre le problème. Que faire si le serveur Epic ne peut pas accéder au jeu lorsqu'il est hors ligne : 1. Il peut être interféré par un logiciel de sécurité. Fermez la plateforme de jeu et le logiciel de sécurité, puis redémarrez. 2. La seconde est que le réseau fluctue trop. Essayez de redémarrer le routeur pour voir s'il fonctionne. Si les conditions sont correctes, vous pouvez essayer d'utiliser le réseau mobile 5g pour fonctionner. 3. Alors il y en aura peut-être plus
 Enseignement du nœud PI: Qu'est-ce qu'un nœud PI? Comment installer et configurer le nœud PI?
Mar 05, 2025 pm 05:57 PM
Enseignement du nœud PI: Qu'est-ce qu'un nœud PI? Comment installer et configurer le nœud PI?
Mar 05, 2025 pm 05:57 PM
Explication détaillée et guide d'installation pour les nœuds de pignon Cet article introduira l'écosystème de pignon en détail - nœuds PI, un rôle clé dans l'écosystème de pignon et fournir des étapes complètes pour l'installation et la configuration. Après le lancement du réseau de test de la blockchain pèse, les nœuds PI sont devenus une partie importante de nombreux pionniers participant activement aux tests, se préparant à la prochaine version du réseau principal. Si vous ne connaissez pas encore Pinetwork, veuillez vous référer à ce qu'est Picoin? Quel est le prix de l'inscription? PI Utilisation, exploitation minière et sécurité. Qu'est-ce que Pinetwork? Le projet Pinetwork a commencé en 2019 et possède sa pièce exclusive de crypto-monnaie PI. Le projet vise à en créer un que tout le monde peut participer
 Comment trouver des ressources sur 115 disques réseau
Feb 23, 2024 pm 05:10 PM
Comment trouver des ressources sur 115 disques réseau
Feb 23, 2024 pm 05:10 PM
Il y aura beaucoup de ressources sur le disque réseau 115, alors comment trouver des ressources ? Les utilisateurs peuvent rechercher les ressources dont ils ont besoin dans le logiciel, puis accéder à l'interface de téléchargement, puis choisir de les enregistrer sur le disque réseau. Cette introduction à la méthode de recherche de ressources sur 115 disques réseau peut vous indiquer le contenu spécifique. Ce qui suit est une introduction détaillée, venez y jeter un œil. Comment trouver des ressources sur le disque réseau 115 ? Réponse : Recherchez le contenu dans le logiciel, puis cliquez pour enregistrer sur le disque réseau. Introduction détaillée : 1. Entrez d'abord les ressources souhaitées dans l'application. 2. Cliquez ensuite sur le lien mot-clé qui apparaît. 3. Entrez ensuite dans l'interface de téléchargement. 4. Cliquez sur Enregistrer sur le disque réseau à l'intérieur.
