

Implémentation PHP d'un exemple de programme voleur
本篇文章主要介绍了PHP实现小偷程序实例,实现了抓取网页咨询和商品信息的功能,具有一定的参考价值,感兴趣的小伙伴们可以参考一下。
为什么使用“小偷程序”?
远程抓取文章资讯或商品信息是很多企业要求程序员实现的功能,也就是俗说的小偷程序。其最主要的优点是:解决了公司网编繁重的工作,大大提高了效率。只需要一运行就能快速的抓取别人网站的信息。
“小偷程序”在哪里运行?
“小偷程序” 应该在 Windows 下的 DOS或 Linux 下通过 PHP 命令运行为最佳,因为,网页运行会超时。
比如图(Windows 下 DOS 为例):
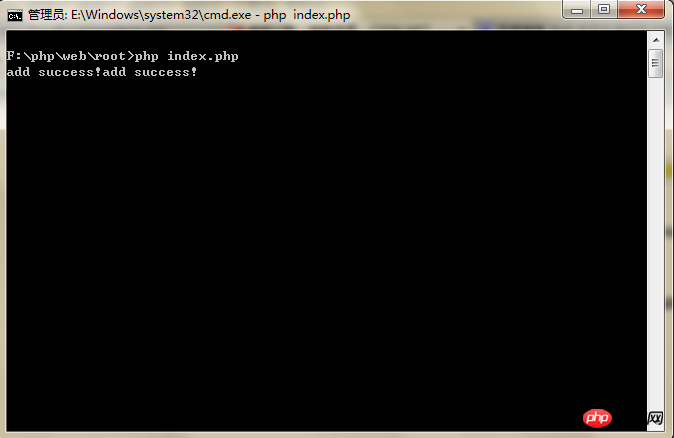
“小偷程序”的实现
这里主要通过一个实例来讲解,我们来抓取下“华强电子网”的资讯信息,请先看观察这个链接 http://www.hqew.com/info-c10.html,当您打开这个页面的时候发现这个页面会发现一些现象:
1、资讯列表有 500 页(2012-01-03);
2、每页的 url 链接都有规律,比如:第1页为http://www.hqew.com/info-c10-1.html;第2页为http://www.hqew.com/info-c10-2.html;……第500页为http://www.hqew.com/info-c10-500.html;
3、由第二点就可以知道,“华强电子网” 的资讯是伪静态或者是生成的静态页面
其实,基本上大部分的网站都有这样的规律,比如:中关村在线、慧聪网、新浪、淘宝……。
这样,我们可以通过这样的思路来实现页面内容的抓取:
1、先获取文章列表页内容;
2、根据文章列表页内容循环获取文章的 url 地址;
3、根据文章的 url 地址获取文章的详细内容
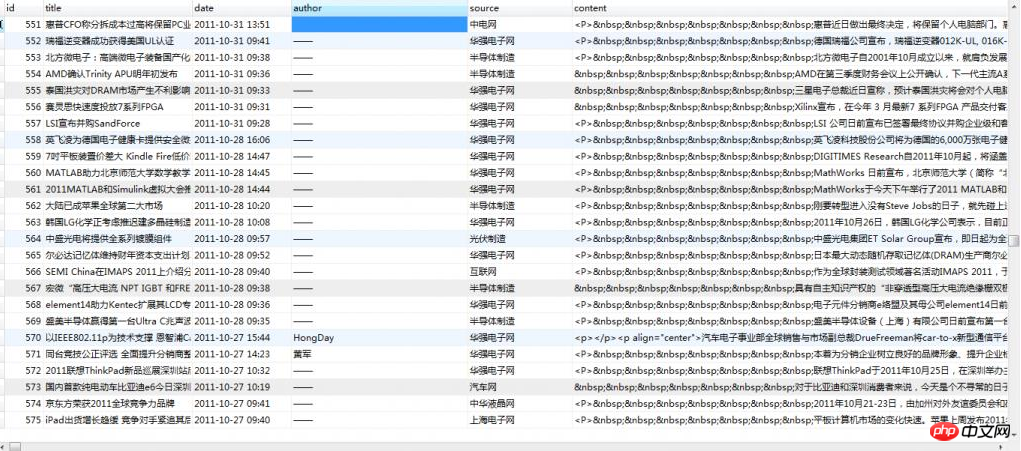
这里,我们主要抓取资讯页里面的:标题(title)、发布如期(date)、作者(author)、来源(source)、内容(content)
“华强电子网”资讯抓取
首先,先建数据表结构,如下所示:
CREATE TABLE `article`.`article` ( `id` MEDIUMINT( 8 ) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY , `title` VARCHAR( 255 ) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `date` VARCHAR( 50 ) NOT NULL , `author` VARCHAR( 100 ) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `source` VARCHAR( 100 ) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `content` TEXT NOT NULL ) ENGINE = MYISAM CHARACTER SET utf8 COLLATE utf8_general_ci;
抓取程序:
<?php
/**
* 抓取“华强电子网”资讯程序
* author Lee.
* Last modify $Date: 2012-1-3 15:39:35 $
*/
header('Content-Type:text/html;Charset=utf-8');
$mysqli = new mysqli('localhost', 'root', '1715544', 'article'); # 数据库连接,请手动修改您自己的数据库信息
$mysqli->set_charset('UTF8'); # 设置数据库编码
function data($url) {
global $mysqli;
$result = file_get_contents($url); # $result 获取 url 链接内容(注意:这里是文章列表链接)
$pattern = '/<li><span class="box_r">.+<\/span><a href="([^"]+)" title=".+" >.+<\/a><\/li>/Usi'; # 取得文章 url 的匹配正则
preg_match_all($pattern, $result, $arr); # 把文章列表 url 分配给数组$arr(二维数组)
foreach ($arr[1] as $val) {
$val = 'http://www.hqew.com' . $val; # 真实文章 url 地址
$re = file_get_contents($val); # $re 为文章 url 的内容
$pa = '/<p id="article">\s+<h1>(.+)<\/h1>\s+<p id="article\_extinfo">\s+发布:\s+(.+)\s+\|\s+作者:\s+(.+)\s+\|\s+来源:\s+(.*?)\s+<span style="display:none" >.+<p id="article_body">\s*(.+)\s+<\/p>\s+<\/p><!--article end-->/Usi'; # 取得文章内容的正则
preg_match_all($pa, $re, $array); # 把取到的内容分配到数组 $array
$content = trim($array[5][0]);
$con = array(
'title'=>mysqlString($array[1][0]),
'date'=>mysqlString($array[2][0]),
'author'=>mysqlString(stripAuthorTag($array[3][0])),
'source'=>mysqlString($array[4][0]),
'content'=>mysqlString(stripContentTag($content))
);
$sql = "INSERT INTO article(title,date,author,source,content) VALUES ('{$con['title']}','{$con['date']}','{$con['author']}','{$con['source']}','{$con['content']}')";
$row = $mysqli->query($sql); # 添加到数据库
if ($row) {
echo 'add success!';
} else {
echo 'add failed!';
}
}
}
/**
* stripOfficeTag($v) 对文章内容进行过滤,比如:去掉文章中的链接,过滤掉没用的 HTML 标签……
* @param string $v
* @return string
*/
function stripContentTag($v){
$v = str_replace('<p> </p>', '', $v);
$v = str_replace('<p />', '', $v);
$v = preg_replace('/<a href=".+" target="\_blank"><strong>(.+)<\/strong><\/a>/Usi', '\1', $v);
$v = preg_replace('%(<span\s*[^>]*>(.*)</span>)%Usi', '\2', $v);
$v = preg_replace('%(\s+class="Mso[^"]+")%si', '', $v);
$v = preg_replace('%( style="[^"]*mso[^>]*)%si', '', $v);
$v = preg_replace('/<b><\/b>/', '', $v);
return $v;
}
/**
* stripTitleTag($title) 对文章标题进行过滤
* @param string $v
* @return string
*/
function stripAuthorTag($v) {
$v = preg_replace('/<a href=".+" target="\_blank">(.+)<\/a>/Usi', '\1', $v);
return $v;
}
/**
* mysqlString($str) 过滤数据
* @param string $str
* @return string
*/
function mysqlString($str) {
return addslashes(trim($str));
}
/**
* init($min, $max) 入口程序方法,从 $min 页开始取,到 $max 页结束
* @param int $min 从 1 开始
* @param int $max
* @return string 返回 URL 地址
*/
function init($min=1, $max) {
for ($i=$min; $i<=$max; $i++) {
data("http://www.hqew.com/info-c10-{$i}.html");
}
}
init(1, 500); // 程序入口,从第一页开始抓,抓取500页
?>通过上面的程序,就可以实现抓取华强电子网的资讯信息。
入口方法 init($min, $max) 如果想抓取 1-500 页面内容,那么 init(1, 500) 即可!这样,用不了多长时间,华强电子网的资讯就会全部抓取到数据库里面了。^_^
执行界面:
数据库:
以上就是本文的全部内容,希望对大家的学习有所帮助。
相关推荐:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Guide d'installation et de mise à niveau de PHP 8.4 pour Ubuntu et Debian
Dec 24, 2024 pm 04:42 PM
Guide d'installation et de mise à niveau de PHP 8.4 pour Ubuntu et Debian
Dec 24, 2024 pm 04:42 PM
PHP 8.4 apporte plusieurs nouvelles fonctionnalités, améliorations de sécurité et de performances avec une bonne quantité de dépréciations et de suppressions de fonctionnalités. Ce guide explique comment installer PHP 8.4 ou mettre à niveau vers PHP 8.4 sur Ubuntu, Debian ou leurs dérivés. Bien qu'il soit possible de compiler PHP à partir des sources, son installation à partir d'un référentiel APT comme expliqué ci-dessous est souvent plus rapide et plus sécurisée car ces référentiels fourniront les dernières corrections de bogues et mises à jour de sécurité à l'avenir.
 7 fonctions PHP que je regrette de ne pas connaître auparavant
Nov 13, 2024 am 09:42 AM
7 fonctions PHP que je regrette de ne pas connaître auparavant
Nov 13, 2024 am 09:42 AM
Si vous êtes un développeur PHP expérimenté, vous aurez peut-être le sentiment d'y être déjà allé et de l'avoir déjà fait. Vous avez développé un nombre important d'applications, débogué des millions de lignes de code et peaufiné de nombreux scripts pour réaliser des opérations.
 Comment configurer Visual Studio Code (VS Code) pour le développement PHP
Dec 20, 2024 am 11:31 AM
Comment configurer Visual Studio Code (VS Code) pour le développement PHP
Dec 20, 2024 am 11:31 AM
Visual Studio Code, également connu sous le nom de VS Code, est un éditeur de code source gratuit – ou environnement de développement intégré (IDE) – disponible pour tous les principaux systèmes d'exploitation. Avec une large collection d'extensions pour de nombreux langages de programmation, VS Code peut être c
 Expliquez les jetons Web JSON (JWT) et leur cas d'utilisation dans les API PHP.
Apr 05, 2025 am 12:04 AM
Expliquez les jetons Web JSON (JWT) et leur cas d'utilisation dans les API PHP.
Apr 05, 2025 am 12:04 AM
JWT est une norme ouverte basée sur JSON, utilisée pour transmettre en toute sécurité des informations entre les parties, principalement pour l'authentification de l'identité et l'échange d'informations. 1. JWT se compose de trois parties: en-tête, charge utile et signature. 2. Le principe de travail de JWT comprend trois étapes: la génération de JWT, la vérification de la charge utile JWT et l'analyse. 3. Lorsque vous utilisez JWT pour l'authentification en PHP, JWT peut être généré et vérifié, et les informations sur le rôle et l'autorisation des utilisateurs peuvent être incluses dans l'utilisation avancée. 4. Les erreurs courantes incluent une défaillance de vérification de signature, l'expiration des jetons et la charge utile surdimensionnée. Les compétences de débogage incluent l'utilisation des outils de débogage et de l'exploitation forestière. 5. L'optimisation des performances et les meilleures pratiques incluent l'utilisation des algorithmes de signature appropriés, la définition des périodes de validité raisonnablement,
 Comment analysez-vous et traitez-vous HTML / XML dans PHP?
Feb 07, 2025 am 11:57 AM
Comment analysez-vous et traitez-vous HTML / XML dans PHP?
Feb 07, 2025 am 11:57 AM
Ce tutoriel montre comment traiter efficacement les documents XML à l'aide de PHP. XML (Language de balisage extensible) est un langage de balisage basé sur le texte polyvalent conçu à la fois pour la lisibilité humaine et l'analyse de la machine. Il est couramment utilisé pour le stockage de données et
 Programme PHP pour compter les voyelles dans une chaîne
Feb 07, 2025 pm 12:12 PM
Programme PHP pour compter les voyelles dans une chaîne
Feb 07, 2025 pm 12:12 PM
Une chaîne est une séquence de caractères, y compris des lettres, des nombres et des symboles. Ce tutoriel apprendra à calculer le nombre de voyelles dans une chaîne donnée en PHP en utilisant différentes méthodes. Les voyelles en anglais sont a, e, i, o, u, et elles peuvent être en majuscules ou en minuscules. Qu'est-ce qu'une voyelle? Les voyelles sont des caractères alphabétiques qui représentent une prononciation spécifique. Il y a cinq voyelles en anglais, y compris les majuscules et les minuscules: a, e, i, o, u Exemple 1 Entrée: String = "TutorialSpoint" Sortie: 6 expliquer Les voyelles dans la chaîne "TutorialSpoint" sont u, o, i, a, o, i. Il y a 6 yuans au total
 Expliquez la liaison statique tardive en PHP (statique: :).
Apr 03, 2025 am 12:04 AM
Expliquez la liaison statique tardive en PHP (statique: :).
Apr 03, 2025 am 12:04 AM
Liaison statique (statique: :) implémente la liaison statique tardive (LSB) dans PHP, permettant à des classes d'appel d'être référencées dans des contextes statiques plutôt que de définir des classes. 1) Le processus d'analyse est effectué au moment de l'exécution, 2) Recherchez la classe d'appel dans la relation de succession, 3) il peut apporter des frais généraux de performance.
 Quelles sont les méthodes PHP Magic (__construct, __ destruct, __ call, __get, __set, etc.) et fournir des cas d'utilisation?
Apr 03, 2025 am 12:03 AM
Quelles sont les méthodes PHP Magic (__construct, __ destruct, __ call, __get, __set, etc.) et fournir des cas d'utilisation?
Apr 03, 2025 am 12:03 AM
Quelles sont les méthodes magiques de PHP? Les méthodes magiques de PHP incluent: 1. \ _ \ _ Construct, utilisé pour initialiser les objets; 2. \ _ \ _ Destruct, utilisé pour nettoyer les ressources; 3. \ _ \ _ Appel, gérer les appels de méthode inexistants; 4. \ _ \ _ GET, Implémentez l'accès à l'attribut dynamique; 5. \ _ \ _ SET, Implémentez les paramètres d'attribut dynamique. Ces méthodes sont automatiquement appelées dans certaines situations, améliorant la flexibilité et l'efficacité du code.
