
Cet article présente principalement les connaissances sur superagent et cheerio pour le premier essai du robot nodejs. Il est très bon et a une valeur de référence. Les amis dans le besoin peuvent s'y référer
Avant-propos.
J'entends parler des robots depuis longtemps. J'ai commencé à apprendre nodejs ces derniers jours et j'ai écrit un robot https://github.com/leichangchun/node-crawlers/tree. /master/superagent_cheerio_demo pour explorer la page d'accueil du parc de blogs Voici un bref résumé du titre de l'article, du nom de l'utilisateur, du nombre de lectures, du nombre de recommandations et de l'avatar de l'utilisateur.
Utilisez ces points :
1. Le module principal du nœud - système de fichiers
2. Le module tiers utilisé pour les requêtes http - superagent
3. Un module tiers pour analyser le DOM --cheerio
Pour des explications détaillées et les API de plusieurs modules, veuillez vous référer à chaque lien. Il n'y a que des utilisations simples dans la démo.
Préparation
Utilisez npm pour gérer les dépendances, et les informations sur les dépendances seront stockées dans package.json
//安装用到的第三方模块 cnpm install --save superagent cheerio
Introduction Modules fonctionnels requis
//引入第三方模块,superagent用于http请求,cheerio用于解析DOM const request = require('superagent'); const cheerio = require('cheerio'); const fs = require('fs');
Request + Parse Page
Si vous souhaitez explorer le contenu de la page d'accueil du parc de blogs , vous devez d'abord demander l'adresse de la page d'accueil et obtenir le code HTML renvoyé. Ici, le superagent est utilisé pour effectuer des requêtes http. La méthode d'utilisation de base est la suivante :
request.get(url)
.end(error,res){
//do something
}Lancez une demande d'obtention à l'URL spécifiée. Lorsque la requête est incorrecte, une erreur sera renvoyée (non En cas d'erreur, l'erreur est nulle ou indéfinie), et res sont les données renvoyées.
Après avoir obtenu le contenu HTML, pour obtenir les données souhaitées, nous devons utiliser Cheerio pour analyser le DOM dont Cheerio a besoin pour charger d'abord le code HTML cible, puis l'analyser. L'API est très similaire à jquery. API. , familier avec jquery et prise en main très rapidement. Regardez directement l'exemple de code
//目标链接 博客园首页
let targetUrl = 'https://www.cnblogs.com/';
//用来暂时保存解析到的内容和图片地址数据
let content = '';
let imgs = [];
//发起请求
request.get(targetUrl)
.end( (error,res) => {
if(error){ //请求出错,打印错误,返回
console.log(error)
return;
}
// cheerio需要先load html
let $ = cheerio.load(res.text);
//抓取需要的数据,each为cheerio提供的方法用来遍历
$('#post_list .post_item').each( (index,element) => {
//分析所需要的数据的DOM结构
//通过选择器定位到目标元素,再获取到数据
let temp = {
'标题' : $(element).find('h3 a').text(),
'作者' : $(element).find('.post_item_foot > a').text(),
'阅读数' : +$(element).find('.article_view a').text().slice(3,-2),
'推荐数' : +$(element).find('.diggnum').text()
}
//拼接数据
content += JSON.stringify(temp) + '\n';
//同样的方式获取图片地址
if($(element).find('img.pfs').length > 0){
imgs.push($(element).find('img.pfs').attr('src'));
}
});
//存放数据
mkdir('./content',saveContent);
mkdir('./imgs',downloadImg);
})Données de stockage
Après avoir analysé le DOM ci-dessus, le contenu des informations requises a été épissé et obtenu. L'URL de l'image est stockée maintenant, le contenu est stocké dans un fichier txt dans le répertoire spécifié et l'image est téléchargée dans le répertoire spécifié
Créez d'abord le répertoire et utilisez le fichier core nodejs. system
//创建目录
function mkdir(_path,callback){
if(fs.existsSync(_path)){
console.log(`${_path}目录已存在`)
}else{
fs.mkdir(_path,(error)=>{
if(error){
return console.log(`创建${_path}目录失败`);
}
console.log(`创建${_path}目录成功`)
})
}
callback(); //没有生成指定目录不会执行
}Une fois que vous avez le répertoire spécifié, vous pouvez écrire des données. Le contenu du fichier txt est déjà là. Utilisez writeFile()
//将文字内容存入txt文件中
function saveContent() {
fs.writeFile('./content/content.txt',content.toString());
}. pour obtenir le lien vers l'image, vous devez donc l'utiliser à nouveau. Le superagent télécharge les images et les stocke localement. Superagent peut renvoyer directement un flux de réponse, puis coopérer avec le pipeline nodejs pour écrire directement le contenu de l'image à l'endroit local
//下载爬到的图片
function downloadImg() {
imgs.forEach((imgUrl,index) => {
//获取图片名
let imgName = imgUrl.split('/').pop();
//下载图片存放到指定目录
let stream = fs.createWriteStream(`./imgs/${imgName}`);
let req = request.get('https:' + imgUrl); //响应流
req.pipe(stream);
console.log(`开始下载图片 https:${imgUrl} --> ./imgs/${imgName}`);
} )
}Effet
Exécutez la démo et voyez l'effet. les données ont été explorées normalement
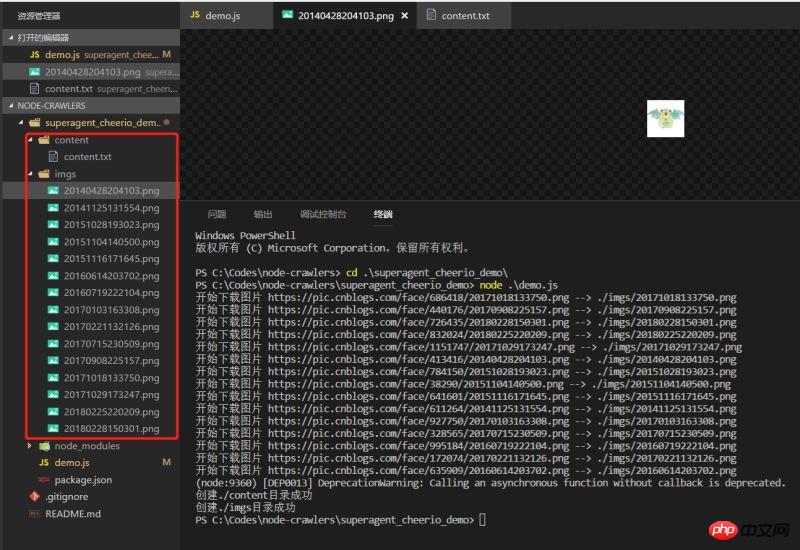
Une démo très simple, qui n'est peut-être pas si rigoureuse, mais c'est toujours le premier petit pas vers node.
Ce qui précède est ce que j'ai compilé pour vous. J'espère que cela vous sera utile à l'avenir.
Articles connexes :
Exemples de redirection dynamique de routage et de garde de navigation de Vue
Résoudre le problème d'échec après avoir utilisé le routage vue.js
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



