

Cet article présente principalement les questions d'entretien Redis et les clusters distribués. Il a une certaine valeur de référence. Maintenant, je le partage avec vous. Les amis dans le besoin peuvent s'y référer

(1) C'est rapide car les données sont stockées en mémoire, similaire à HashMap. L'avantage de HashMap est que la complexité temporelle de la recherche et de l'opération est O(1)
(2) Il prend en charge. types de données riches, prend en charge la chaîne, la liste, l'ensemble, l'ensemble trié, le hachage
(3) Prend en charge les transactions, les opérations sont atomiques, ce qu'on appelle l'atomicité signifie que toutes les modifications apportées aux données sont exécutées ou ne sont pas exécutées du tout. 🎜>(4) Fonctionnalités riches : peut être utilisé pour la mise en cache, la messagerie et le réglage du délai d'expiration par clé. Il sera automatiquement supprimé après l'expiration
Recommandation spéciale :2. Quels sont les avantages de redis par rapport à memcached ? (1) Toutes les valeurs de memcached sont des chaînes simples En remplacement, redis prend en charge des types de données plus riches
(2) redis est beaucoup plus rapide que memcached
( 3) redis peut conserver son contenu. data
(2) Si les données sont importantes, un esclave active la sauvegarde des données AOF et la politique est définie pour se synchroniser une fois par seconde
(3) Pour la vitesse de réplication maître-esclave et la stabilité de la connexion, le maître et l'esclave sont les meilleurs Dans le même LAN
(4) Essayez d'éviter d'ajouter des bases de données esclaves à la base de données maître qui est sous forte pression
(5) N'utilisez pas de structure graphique pour la réplication maître-esclave. Il est plus stable d'utiliser une structure graphique. Structure de liste chaînée unidirectionnelle, c'est-à-dire : Maître Une telle structure est pratique pour résoudre le problème du point de défaillance unique et réaliser le remplacement du Maître par l'Esclave . Si le maître raccroche, vous pouvez immédiatement activer Slave1 en tant que maître, laissant tout le reste inchangé.
volatile-random : sélectionnez aléatoirement les données à éliminer de l'ensemble de données (server.db[i].expires) avec un délai d'expiration défini
allkeys-lru : à partir de l'ensemble de données (server.db[i]. ] .dict) et éliminez les données les moins récemment utilisées
allkeys-random : sélectionnez arbitrairement les données dans l'ensemble de données (server.db[i].dict) pour éliminer
no-enviction ( eviction ) : Interdire l'expulsion des données
1), méthode de stockage
Memecache stocke toutes les données dans la mémoire. Il raccrochera après une panne de courant et les données ne pourront pas dépasser la taille de la mémoire.
Redis est partiellement stocké sur le disque dur, ce qui assure la persistance des données.
2), Types de prise en charge des données
La prise en charge par Memcache des types de données est relativement simple.
Redis a des types de données complexes.
3). Différents modèles sous-jacents sont utilisés
Les méthodes de mise en œuvre sous-jacentes et les protocoles d'application pour la communication avec les clients sont différents.
Redis a directement construit le mécanisme VM par lui-même, car si le système général appelle les fonctions système, il perdra un certain temps à se déplacer et à demander.
4), taille de la valeur
Redis peut atteindre un maximum de 1 Go, alors que Memcache ne fait que 1 Mo
1) Le maître écrit des instantanés de mémoire et la commande save planifie la fonction rdbSave, ce qui bloquera le travail du thread principal. Lorsque l'instantané est relativement volumineux, l'impact sur les performances sera très important et. le service sera suspendu par intermittence, donc Master est le meilleur. N'écrivez pas d'instantanés de mémoire.
2) Maîtrisez la persistance AOF. Si le fichier AOF n'est pas réécrit, cette méthode de persistance aura un impact minimal sur les performances, mais le fichier AOF continuera à croître si le fichier AOF est trop volumineux. affecter la récupération de la vitesse de redémarrage du maître. Il est préférable de ne pas effectuer de travail de persistance sur le maître, y compris les instantanés de mémoire et les fichiers journaux AOF. En particulier, n'activez pas les instantanés de mémoire pour la persistance. Si les données sont critiques, un esclave doit activer les données de sauvegarde AOF, et la stratégie est la suivante. pour synchroniser une fois par seconde.
3) Le maître appelle BGREWRITEAOF pour réécrire le fichier AOF qui occupera une grande quantité de ressources CPU et mémoire pendant la réécriture, ce qui entraînera une charge de service excessive et une suspension du service à court terme.
4). Problèmes de performances de la réplication maître-esclave Redis Pour la vitesse de réplication maître-esclave et la stabilité de la connexion, il est préférable que l'esclave et le maître soient dans le même LAN
Redis est le plus adapté à tous les scénarios de données en mémoire. Bien que Redis fournisse également des fonctions de persistance, il s'agit en fait davantage d'une fonction sauvegardée sur disque, ce qui est assez différent. de la persistance au sens traditionnel, alors vous pouvez avoir des questions. Il semble que Redis ressemble plus à une version améliorée de Memcached, alors quand utiliser Memcached et quand utiliser Redis
Si vous comparez simplement la différence entre Redis ? et Memcached, la plupart d'entre eux obtiendront le même résultat. Les points de vue suivants :
1 Redis prend non seulement en charge les données simples de type k/v, mais fournit également le stockage de structures de données telles que list, set, zset et. hacher.
2. Redis prend en charge la sauvegarde des données, c'est-à-dire la sauvegarde des données en mode maître-esclave.
3. Redis prend en charge la persistance des données, qui peut conserver les données en mémoire sur le disque et peut être rechargée pour être utilisée lors du redémarrage.
(1), Cache de session
L'un des scénarios les plus couramment utilisés pour utiliser Redis est le cache de session. L'avantage d'utiliser Redis pour mettre en cache les sessions par rapport à d'autres stockages (tels que Memcached) est que Redis assure la persistance. Lors de la maintenance d'un cache qui n'exige pas strictement de cohérence, la plupart des gens seraient mécontents si toutes les informations du panier d'achat de l'utilisateur étaient perdues. Le seraient-ils toujours ?
Heureusement, à mesure que Redis s'est amélioré au fil des années, il est facile de découvrir comment utiliser correctement Redis pour mettre en cache les documents de session. Même la célèbre plateforme commerciale Magento propose des plug-ins Redis.
(2), Full Page Cache (FPC)
En plus des jetons de session de base, Redis fournit également une plate-forme FPC très simple. Revenons au problème de cohérence, même si l'instance Redis est redémarrée, les utilisateurs ne verront pas de baisse de la vitesse de chargement des pages en raison de la persistance du disque. Il s'agit d'une grande amélioration, similaire au FPC local PHP.
En prenant à nouveau Magento comme exemple, Magento fournit un plugin pour utiliser Redis comme backend de cache pleine page.
De plus, pour les utilisateurs de WordPress, Pantheon dispose d'un très bon plug-in wp-redis, qui peut vous aider à charger le plus rapidement possible les pages que vous avez parcourues.
(3), Queue
L'un des grands avantages de Redis dans le domaine des moteurs de stockage en mémoire est qu'il fournit des opérations de liste et d'ensemble, ce qui permet à Redis d'être utilisé comme un bon message plateforme de file d'attente. Les opérations utilisées par Redis comme file d'attente sont similaires aux opérations push/pop de liste dans les langages de programmation locaux (tels que Python).
Si vous recherchez rapidement « Files d'attente Redis » dans Google, vous trouverez immédiatement un grand nombre de projets open source. Le but de ces projets est d'utiliser Redis pour créer de très bons outils back-end pour répondre à diverses files d'attente. besoins. . Par exemple, Celery a un backend qui utilise Redis comme courtier. Vous pouvez le visualiser à partir d'ici.
(4), classement/compteur
Redis implémente très bien l'opération d'incrémentation ou de décrémentation des nombres en mémoire. Les ensembles et les ensembles triés nous permettent également d'effectuer très simplement ces opérations. Redis fournit simplement ces deux structures de données. Nous voulons donc obtenir les 10 meilleurs utilisateurs de l'ensemble trié – appelons-les « user_scores », et nous devons simplement le faire comme ceci :
Bien sûr, cela suppose que vous triez par ordre croissant. sur les scores de vos utilisateurs. Si vous souhaitez renvoyer l'utilisateur et son score, vous devez l'exécuter comme ceci :
ZRANGE user_scores 0 10 WITHSCORES
Agora Games est un bon exemple, implémenté en Ruby, avec son liste de classement Il utilise Redis pour stocker les données, vous pouvez le voir ici.
(5), Publier/Abonnez-vous
Le dernier (mais certainement pas le moindre) est la fonction de publication/abonnement de Redis. Il existe en effet de nombreux cas d’usage pour la publication/abonnement. J'ai vu des gens l'utiliser dans les connexions de réseaux sociaux, comme déclencheur de scripts basés sur la publication/abonnement, et même pour créer des systèmes de discussion en utilisant la fonctionnalité de publication/abonnement de Redis ! (Non, c'est vrai, vous pouvez le vérifier).
De toutes les fonctionnalités proposées par Redis, j'estime que c'est celle que les gens aiment le moins, même si elle offre aux utilisateurs ce multi-fonction.
La haute disponibilité (haute disponibilité) signifie que lorsqu'un serveur cesse de servir, cela n'aura aucun impact sur l'entreprise et les utilisateurs. . La raison de l'arrêt du service peut être due à des raisons imprévisibles telles que des cartes réseau, des routeurs, des salles informatiques, une charge excessive du processeur, un débordement de mémoire, des catastrophes naturelles, etc. Dans de nombreux cas, on parle également de problème ponctuel.
(1) Il existe deux manières principales de résoudre les problèmes ponctuels :
Méthodes actives et de sauvegarde
Il s'agit généralement d'un hôte et d'une ou plusieurs machines de sauvegarde Dans des circonstances normales, L'hôte inférieur fournit des services au monde extérieur et synchronise les données avec la machine de secours. Lorsque la machine hôte tombe en panne, la machine de secours commence immédiatement à servir.
Keepalived est couramment utilisé dans Redis HA, ce qui permet aux machines hôtes et de sauvegarde de fournir la même adresse IP virtuelle au monde extérieur. Le client effectue des opérations de données via l'adresse IP virtuelle. Pendant les périodes normales, l'hôte fournit toujours des services à l'hôte. monde extérieur. Après un temps d'arrêt, le VIP dérive automatiquement vers la machine de secours à bord.
L'avantage est qu'il n'a aucun impact sur le client et fonctionne toujours en VIP.
Les défauts sont également évidents. La plupart du temps, la machine de sauvegarde n'est pas utilisée et est gaspillée.
Méthode maître-esclave
Cette méthode adopte un maître et plusieurs esclaves et synchronise les données entre les maîtres et les esclaves. Lorsque le maître tombe en panne, un nouveau maître est élu parmi l'esclave via l'algorithme d'élection (Paxos, Raft) pour continuer à fournir des services au monde extérieur. Une fois le maître rétabli, il rejoint le système en tant qu'esclave.
Un autre objectif du maître-esclave est de séparer la lecture et l'écriture. Il s'agit d'une solution générale lorsque la pression de lecture et d'écriture d'une seule machine est trop élevée. Son rôle d'hôte ne fournit que des opérations d'écriture ou une petite quantité de lecture, et décharge les requêtes de lecture redondantes vers un ou plusieurs serveurs esclaves via un algorithme d'équilibrage de charge.
L'inconvénient est qu'après la panne de l'hôte, bien que l'esclave soit élu comme nouveau maître, l'adresse du service IP fournie au monde extérieur a changé, ce qui signifie que cela affectera le client. La résolution de cette situation nécessite un travail supplémentaire. Lorsque l'adresse de l'hôte change, le client est averti à temps. Une fois que le client a reçu la nouvelle adresse, il utilise la nouvelle adresse pour continuer à envoyer de nouvelles demandes.
(2) Synchronisation des données
Qu'elle soit maître-esclave ou maître-esclave, cela implique la question de la synchronisation des données. Celle-ci se divise également en deux situations :
Méthode de synchronisation : Lorsque l'hôte reçoit le client Après l'opération d'écriture côté extrémité, les données sont synchronisées avec la machine esclave de manière synchrone. Lorsque la machine esclave écrit également avec succès, le maître renvoie le succès au client, ce que l'on appelle également une forte cohérence des données. . Évidemment, les performances de cette méthode seront considérablement réduites. Lorsqu'il y a plusieurs machines esclaves, il n'est pas nécessaire de synchroniser chacune d'entre elles. Une fois que le maître a synchronisé une certaine machine esclave, la machine esclave synchronise alors la distribution des données vers l'autre esclave. Machines, améliorant ainsi le partage des performances de la machine hôte. Cette configuration est supportée dans Redis, avec un maître et un esclave. En même temps, ce salve sert de maître aux autres esclaves.
Mode asynchrone : après avoir reçu l'opération d'écriture, l'hôte renvoie directement le succès, puis synchronise les données avec l'esclave en arrière-plan de manière asynchrone. Ce type de performances de synchronisation est relativement bon, mais il ne peut pas garantir l'intégrité des données. Par exemple, si l'hôte plante soudainement pendant le processus de synchronisation asynchrone, cette méthode est également appelée faible cohérence des données.
La synchronisation maître-esclave Redis utilise une méthode asynchrone, il existe donc un risque de perdre une petite quantité de données. Il existe également un cas particulier de cohérence faible appelé cohérence éventuelle. Veuillez vous référer au principe et au modèle de cohérence du CAP pour plus de détails.
(3) Sélection de la solution
La solution keepalived est simple à configurer et présente de faibles coûts de main-d'œuvre. Elle est recommandée lorsque la quantité de données est faible et que la pression est faible. Si la quantité de données est relativement importante et que vous ne souhaitez pas gaspiller trop de machines et que vous souhaitez également prendre des mesures personnalisées après le temps d'arrêt, telles que l'alarme, la journalisation, la migration des données, etc., il est recommandé de utilisez la méthode maître-esclave, car elle correspond à la méthode maître-esclave. Il existe généralement également un centre de gestion et de surveillance.
La notification des temps d'arrêt peut être intégrée au composant client ou séparée séparément. Redis Official Sentinel prend en charge le basculement automatique, les notifications, etc. Pour plus de détails, consultez Conception de solutions à faible coût et à haute disponibilité (4).
Schéma logique : 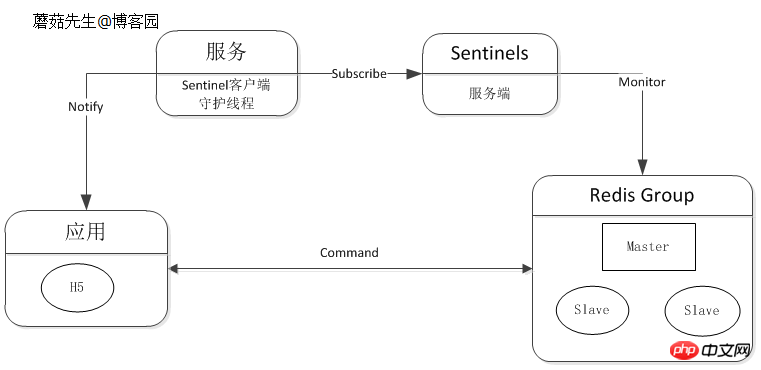
Distribué (distribué) signifie que lorsque le volume d'affaires et le volume de données augmentent, cela peut se faire via tout Augmentez ou diminuez le nombre de serveurs pour résoudre le problème.
Cluster Era
Déployer au moins deux serveurs Redis pour former un petit cluster, avec deux objectifs principaux :
Haute disponibilité : après le raccrochement de l'hôte, le basculement automatique rend le service front-end accessible à utilisateurs Aucun impact.
Séparation de lecture et d'écriture : déchargez la pression de lecture de l'hôte vers l'esclave.
L'équilibrage de charge peut être réalisé sur le composant client, et différentes proportions de pression de demande de lecture peuvent être partagées en fonction des conditions de fonctionnement des différents serveurs.
Schéma logique : 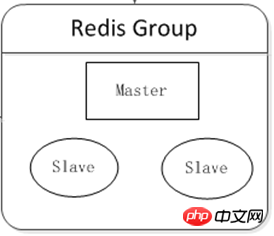
Lorsque la quantité de données mises en cache continue d'augmenter, la mémoire d'une seule machine n'est pas suffisante, et les données doivent être divisées en différentes parties et distribuées sur plusieurs serveurs.
Les données peuvent être fragmentées côté client. Pour plus de détails sur l’algorithme de fragmentation des données, consultez Explication détaillée du hachage cohérent C# et Fragmentation du compartiment virtuel C#.
Schéma logique : 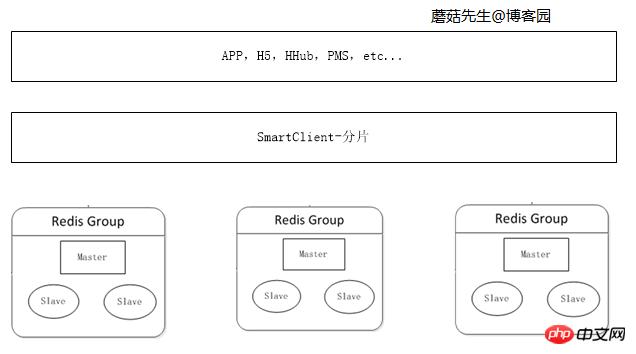
L'ère des clusters distribués à grande échelle
Lorsque la quantité de données continue d'augmenter, les applications peuvent demander une distribution distribuée correspondante en fonction de l'activité dans différents scénarios de cluster. La partie la plus critique est la gestion du cache, et la partie la plus importante est l’ajout de services proxy. L'application accède au vrai serveur Redis via un proxy pour la lecture et l'écriture. Les avantages de ceci sont :
Cela évite de plus en plus de clients d'accéder directement au serveur Redis, ce qui est difficile à gérer et entraîne des risques.
Des mesures de sécurité correspondantes peuvent être mises en œuvre au niveau du proxy, telles que la limitation de courant, l'autorisation et le partitionnement.
Évitez de plus en plus de codes logiques côté client, qui sont non seulement volumineux mais également difficiles à mettre à niveau.
La couche proxy est sans état et peut étendre les nœuds arbitrairement. Pour le client, accéder au proxy équivaut à accéder à Redis autonome.
Actuellement, la société d'hébergement utilise deux solutions : le composant client et le proxy, car l'utilisation d'un proxy affectera certaines performances. Les solutions correspondantes pour la mise en œuvre de proxy incluent Twemproxy de Twitter et codis de Wandoujia.
Schéma logique : 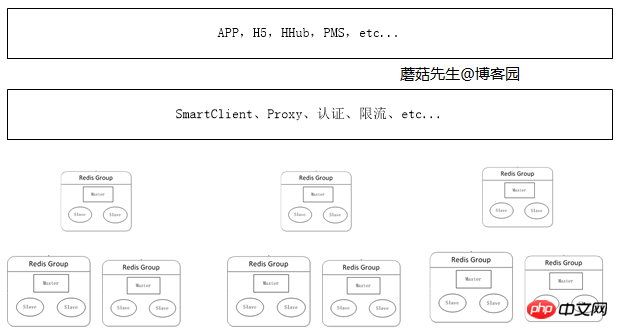
Le cache distribué est suivi du cache du service cloud, qui protège complètement les détails de l'utilisateur. Chaque application peut demander sa propre taille et son propre plan de trafic, comme le service cloud Taobao OCS. cache.
Les composants d'implémentation requis pour le cache distribué sont :
Un centre de surveillance, de migration et de gestion du cache.
Un composant client personnalisé, SmartClient dans l'image ci-dessus.
Un service proxy sans état.
N serveurs.
Recommandations d'apprentissage associées : Tutoriel vidéo Redis
Recommandations d'apprentissage associées : Tutoriel vidéo MySQL
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Ce qui est distribué
Ce qui est distribué
 La différence entre les services distribués et les microservices
La différence entre les services distribués et les microservices
 Logiciel de base de données couramment utilisé
Logiciel de base de données couramment utilisé
 Que sont les bases de données en mémoire ?
Que sont les bases de données en mémoire ?
 Lequel a une vitesse de lecture plus rapide, mongodb ou redis ?
Lequel a une vitesse de lecture plus rapide, mongodb ou redis ?
 Comment utiliser Redis comme serveur de cache
Comment utiliser Redis comme serveur de cache
 Comment Redis résout la cohérence des données
Comment Redis résout la cohérence des données
 Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ?
Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ?









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



